




Apache Cloudberry™ (Incubating) 是 Apache 软件基金会孵化项目,由 Greenplum 和 PostgreSQL 衍生而来,作为领先的开源 MPP 数据库,可用于建设企业级数据仓库,并适用于大规模分析和 AI/ML 工作负载。
GitHub: https://github.com/apache/cloudberry
01 Cloudberry 与 PostgreSQL 并行化比较
在并行化方面,PostgreSQL 与 Cloudberry 有不同的设计。PostgreSQL 支持动态设置并行度,采用一个 leader 节点来设置多个 worker 节点的内存参数和配置。这种设计适用于单机环境。
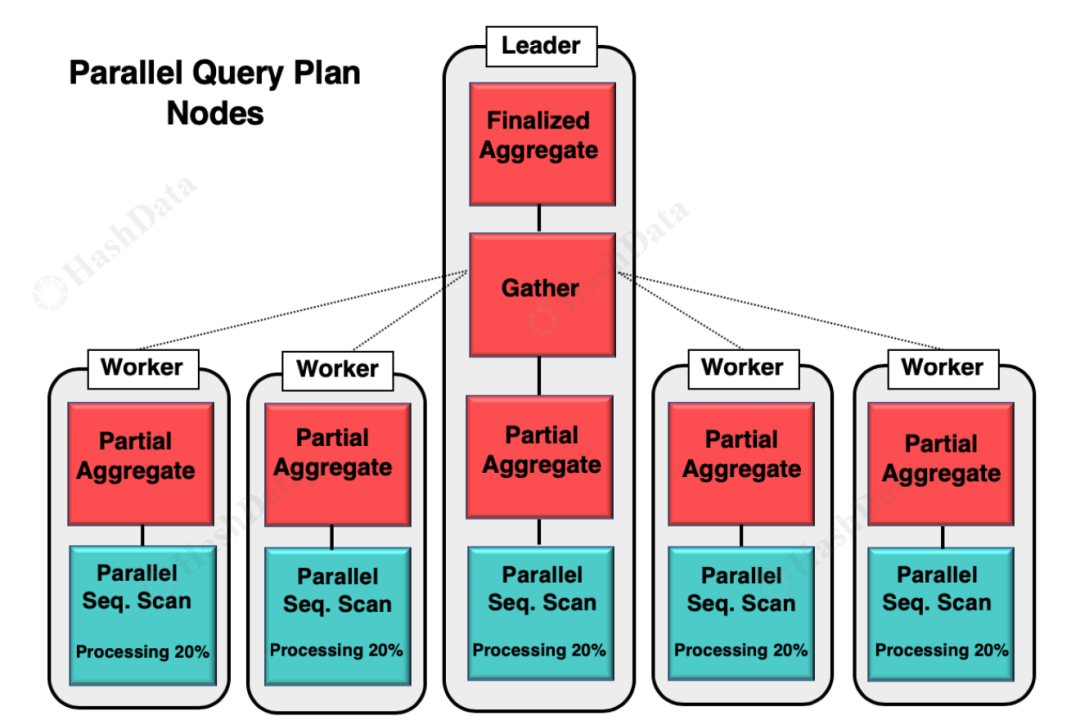
PostgreSQL 并行化架构
而 Cloudberry 则在设计上进行了一些创新。在 Cloudberry 中,主节点(Coordinator)保持不变,但每个 segment 节点上都会虚拟出 Query Executor(QE)。这种设计的演化解决了传统分布式数据库扩容困难的问题,虚拟出更多的 QE 节点相当于动态扩容,极大提高了扩展的灵活性。
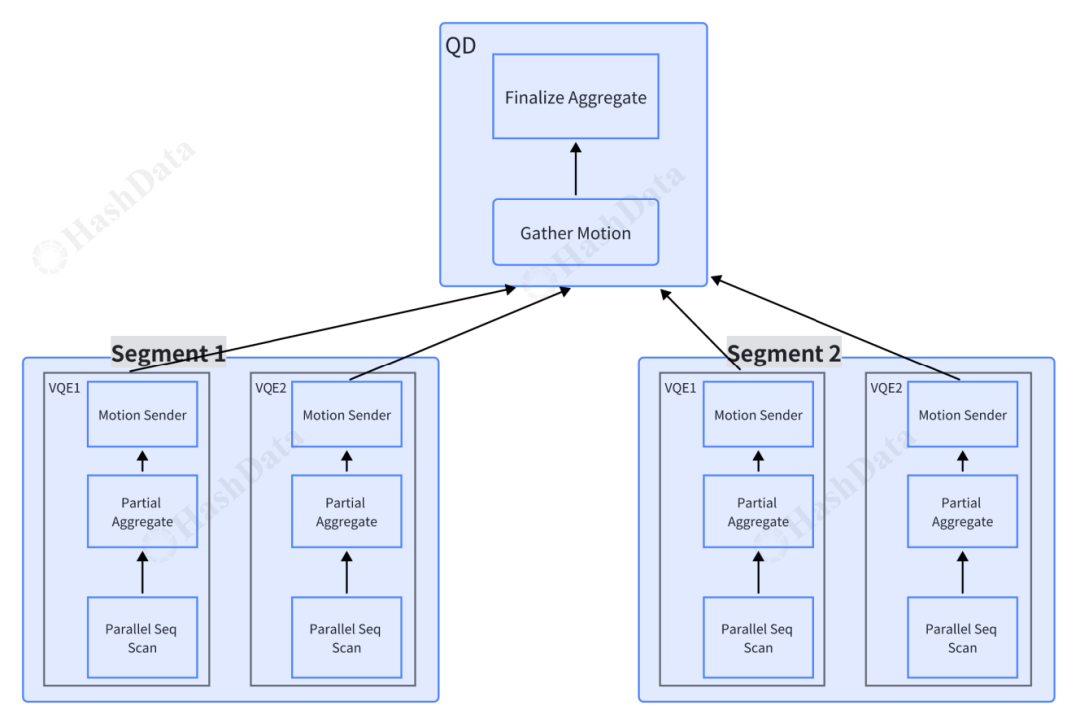
执行计划的变化
在并行化之前和并行化之后的执行计划有显著不同。例如,在 TPCH 10GB 测试中,启用并行查询后,哈希连接的执行时间从 4322 ms 降至 2747 ms(提升约 36%)。
测试参数:max_parallel_workers_per_gather=2
。
非并行计划示例
create table t1(c1 int, c2 int) with(parallel_workers = 3) distributed by(c1);insert into t1 select i, i+1 from generate_series(1, 6000000) I;explain(costs off) select count(*) from t1 a join t1 b on a.c2 = b.c2;QUERY PLAN------------------------------------------------------------------------------Finalize Aggregate-> Gather Motion 3:1 (slice1; segments: 3)-> Partial Aggregate-> Hash JoinHash Cond: (a.c2 = b.c2)-> Redistribute Motion 3:3 (slice2; segments: 3)Hash Key: a.c2-> Seq Scan on t1 a-> Hash-> Redistribute Motion 3:3 (slice3; segments: 3)Hash Key: b.c2-> Seq Scan on t1 bOptimizer: Postgres query optimizer(13 rows)select count(*) from t1 a join t1 b on a.c2 = b.c2;count---------6000000(1 row)Time: 4322.593 ms (00:04.323)
并行计划示例
set enable_parallel=on;explain(costs off) select count(*) from t1 a join t1 b on a.c2 = b.c2;QUERY PLAN------------------------------------------------------------------------------Finalize Aggregate-> Gather Motion 6:1 (slice1; segments: 6)-> Partial Aggregate-> Parallel Hash JoinHash Cond: (a.c2 = b.c2)-> Redistribute Motion 6:6 (slice2; segments: 6)Hash Key: a.c2Hash Module: 3-> Parallel Seq Scan on t1 a-> Parallel Hash-> Redistribute Motion 6:6 (slice3; segments: 6)Hash Key: b.c2Hash Module: 3-> Parallel Seq Scan on t1 bOptimizer: Postgres query optimizer(15 rows)select count(*) from t1 a join t1 b on a.c2 = b.c2;count---------6000000(1 row)Time: 2747.075 ms (00:02.747)02 Cloudberry 并行化算子优化
并行扫描(Parallel Scan)
Cloudberry 支持多种并行扫描方式,覆盖不同存储格式:
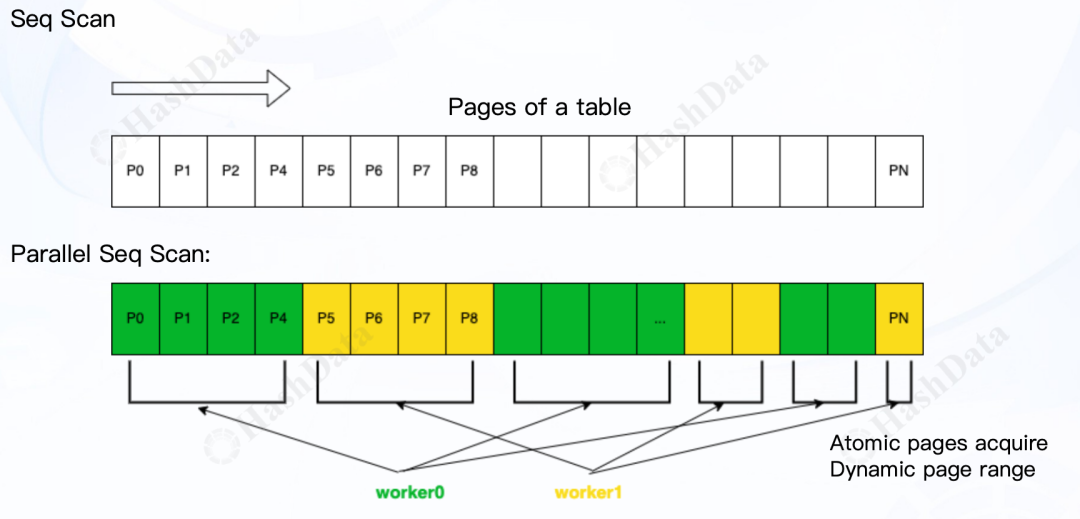
并行顺序扫描(Parallel Seq Scan):按动态页范围分配任务,原子化获取数据页。
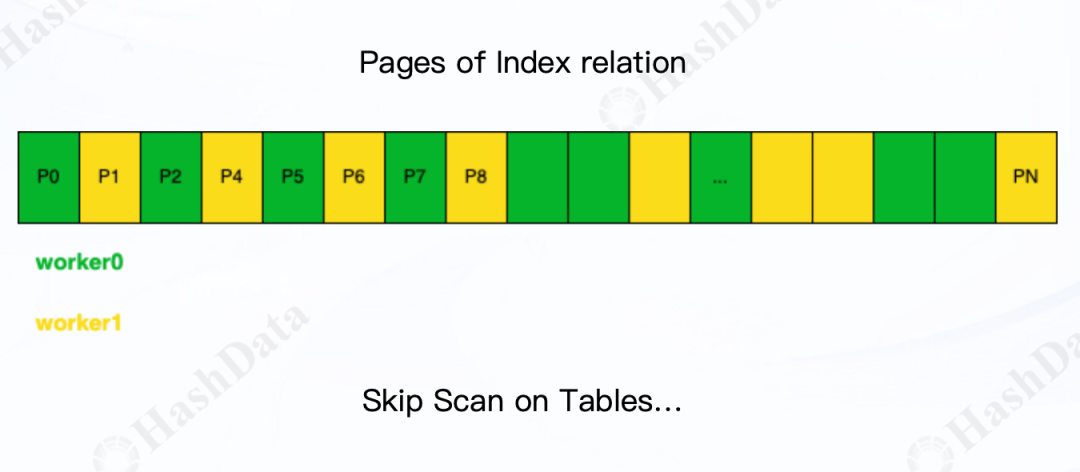
并行索引扫描(Parallel Index(Only) Scan):每个工作进程独立扫描索引页,支持 Skip Scan 优化。
并行位图堆扫描(Parallel Bitmap Heap Scan):由单个工作进程生成位图索引,其他线程并行扫描表数据。
并行连接(Parallel Join)
Join 算子的并行化改造也是并行化过程中的重要部分,Cloudberry 支持四种并行连接模式,每种模式均针对特定场景进行深度优化:
explain(costs off) select * from t1 join t2 on t1.c1 = t2.c1;QUERY PLAN------------------------------------------------------------------Gather Motion 6:1 (slice1; segments: 6)-> Merge JoinMerge Cond: (t1.c1 = t2.c1)-> SortSort Key: t1.c1-> Redistribute Motion 6:6 (slice2; segments: 6)Hash Key: t1.c1Hash Module: 3-> Parallel Seq Scan on t1-> SortSort Key: t2.c1-> Redistribute Motion 3:6 (slice3; segments: 3)Hash Key: t2.c1Hash Module: 3-> Seq Scan on t2Optimizer: Postgres query optimizer(16 rows)
explain(costs off) select * from t1 join t2 on t1.c1 = t2.c1;QUERY PLAN------------------------------------------------------------------Gather Motion 9:1 (slice1; segments: 9)-> Nested LoopJoin Filter: (t1.c1 = t2.c1)-> Redistribute Motion 9:9 (slice2; segments: 9)Hash Key: t1.c1Hash Module: 3-> Parallel Seq Scan on t1-> Materialize-> Redistribute Motion 3:9 (slice3; segments: 3)Hash Key: t2.c1Hash Module: 3-> Seq Scan on t2Optimizer: Postgres query optimizer(13 rows)
explain(costs off) select * from t1 join t2 on t1.c1 = t2.c1;QUERY PLAN------------------------------------------------------------------Gather Motion 6:1 (slice1; segments: 6)-> Hash JoinHash Cond: (t1.c1 = t2.c1)-> Redistribute Motion 6:6 (slice2; segments: 6)Hash Key: t1.c1Hash Module: 3-> Parallel Seq Scan on t1-> Hash-> Redistribute Motion 3:6 (slice3; segments: 3)Hash Key: t2.c1Hash Module: 3-> Seq Scan on t2Optimizer: Postgres query optimizer(13 rows)
explain(costs off) select * from t1 join t2 on t1.c1 = t2.c1;QUERY PLAN------------------------------------------------------------------Gather Motion 6:1 (slice1; segments: 6)-> Parallel Hash JoinHash Cond: (t1.c1 = t2.c1)-> Parallel Seq Scan on t1-> Parallel Hash-> Redistribute Motion 6:6 (slice2; segments: 6)Hash Key: t2.c1Hash Module: 3-> Parallel Seq Scan on t2Optimizer: Postgres query optimizer(10 rows)
03 Cloudberry 数据分布与优化
在并行查询场景中,数据分布策略直接影响任务的执行效率和资源的利用率。Cloudberry 在 Greenplum 原有数据分布模型的基础上,针对并行化架构进行了深度重构,通过动态数据分布策略和智能数据调度,有效解决了传统分布式数据库在扩展性和网络开销上的瓶颈问题。
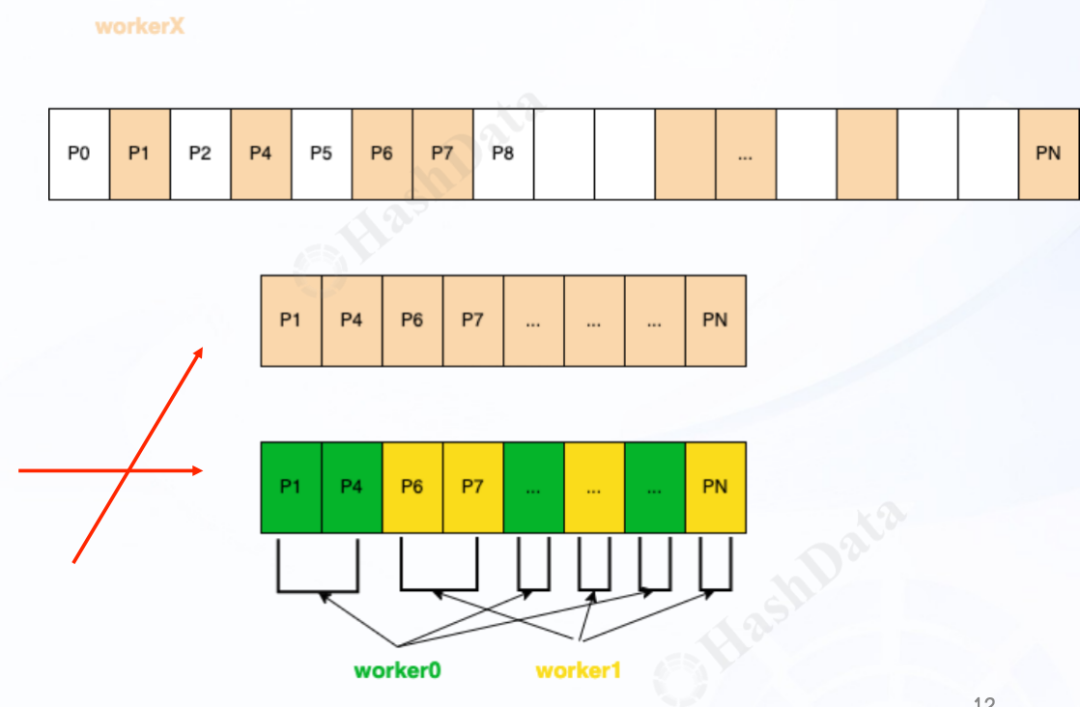
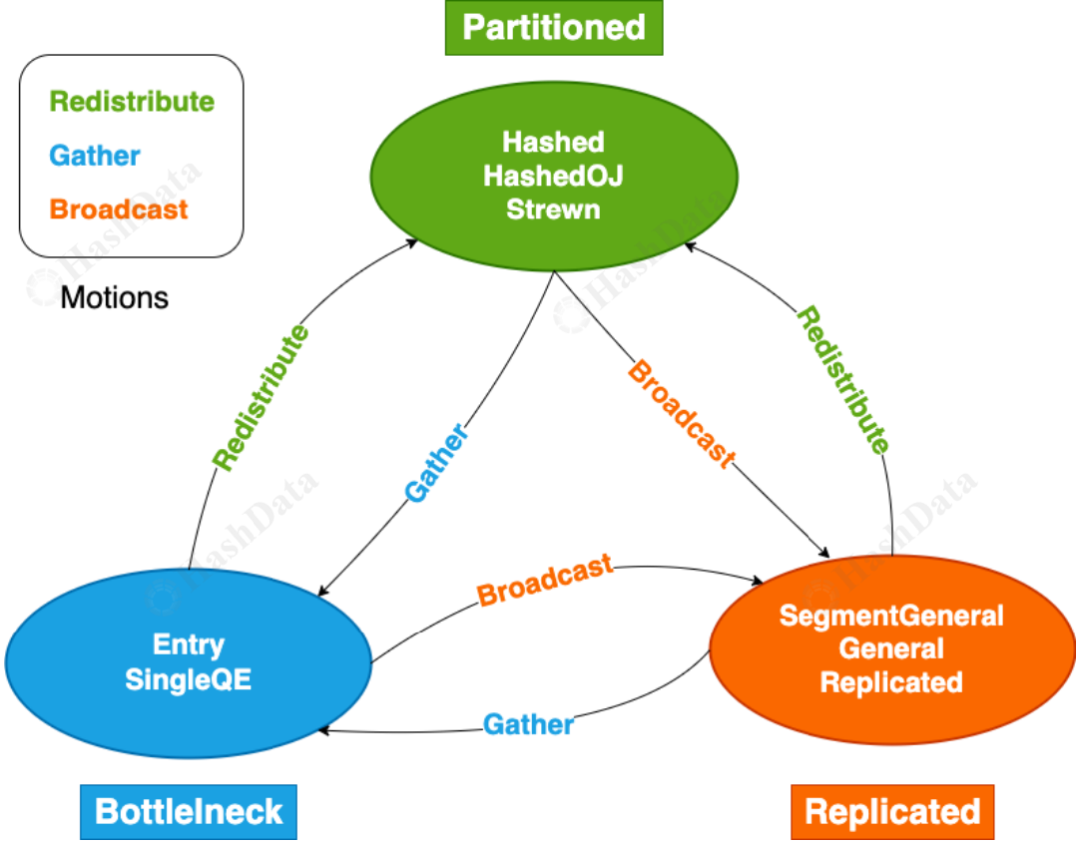
在 Cloudberry 中,我们通过 Locus 来定义数据的分布策略,包括 HashedWorkers、SegmentGeneralWorkers 等。Locus 的目的是确保并行任务间的数据局部性,从而优化查询效率。为了使 Locus 与并行执行计划兼容,我们采用了 Motion 机制,允许在不同的任务之间进行数据重新分布、广播等操作,确保数据能够合理地在多个节点间传递。
假设我们有一个查询计划,涉及 rt4 表和 t2 表的连接操作。以下是该查询计划的执行细节,展示了如何通过 Locus 和 Motion 优化数据的分布与传输:
QUERY PLAN--------------------------------------------Gather Motion 6:1 (slice1; segments: 6)Locus: Entry-> Hash JoinLocus: HashedWorkersParallel Workers: 2Hash Cond: (rt4.b = t2.b)-> Parallel Seq Scan on rt4Locus: SegmentGeneralWorkersParallel Workers: 2-> HashLocus: Hashed-> Seq Scan on t2Locus: HashedOptimizer: Postgres query optimizer(14 rows)
在这个执行计划中,数据通过 HashedWorkers 分布,两个并行 worker 分别负责对 rt4 和 t2 表进行哈希连接。并行扫描和哈希操作通过 SegmentGeneralWorkers 和 Hashed 的 Locus 进行了优化,确保了数据的局部性和高效的任务执行。
04 Cloudberry 并行框架
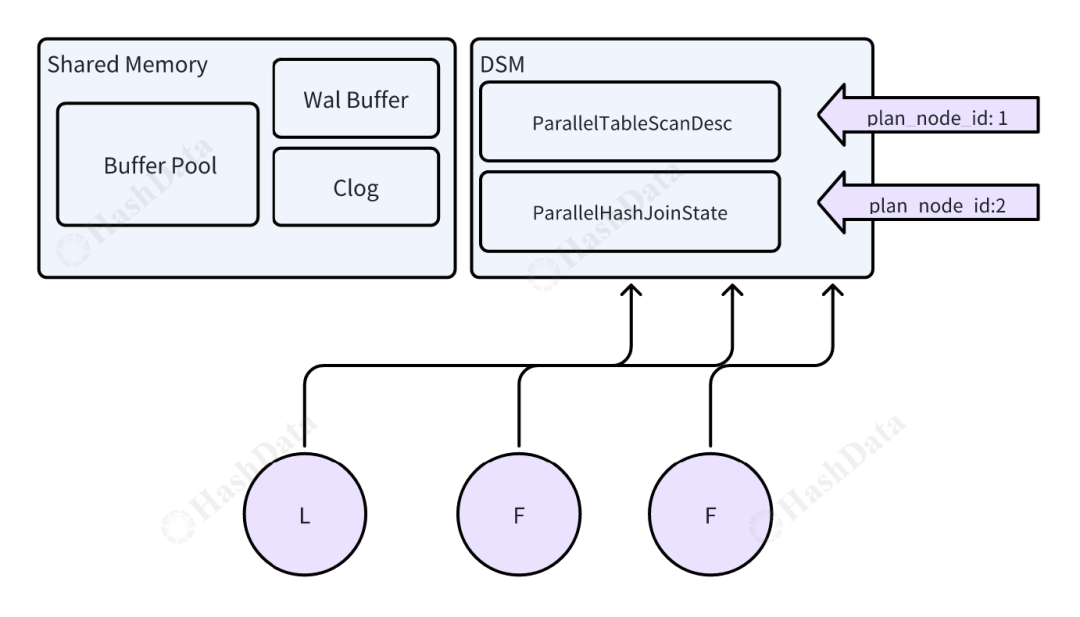
Cloudberry 的并行化框架设计中,主节点和 worker 节点的内存分配需要协调配合。系统采用了动态共享内存(Dynamic Shared Memory,DSM)来实现这一功能。
动态共享内存(Dynamic Shared Memory)
通过 DSM,Cloudberry 能够实现工作进程之间的高效通信与同步,同时减少了传统领导节点(Leader Node)所带来的协调开销。在并行任务执行过程中,DSM 确保了每个 worker 可以灵活、高效地进行内存访问和数据共享。
Barrier 同步机制
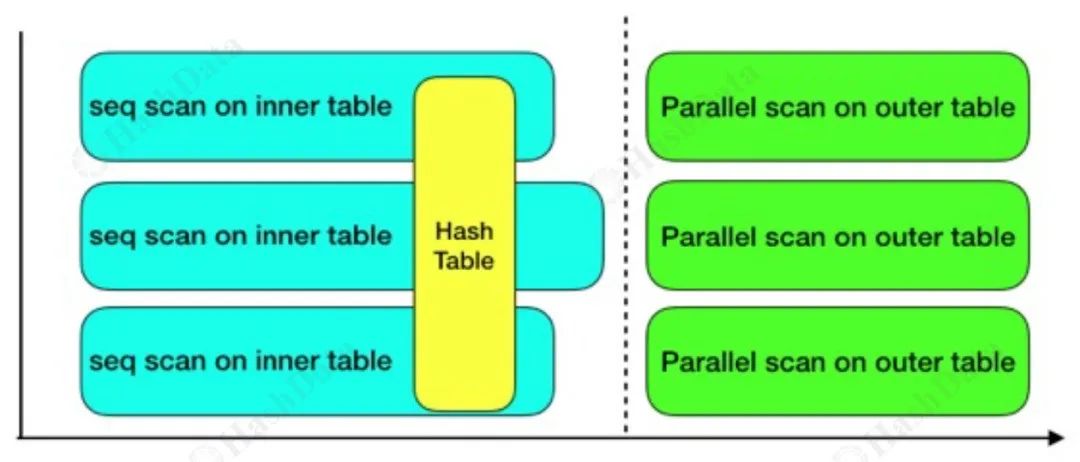
在并行框架中,Cloudberry 引入了一个关键的同步机制——barrier。该机制确保所有节点在特定阶段同步执行,以防止某些节点提前执行,从而导致系统状态不一致。特别是在执行哈希连接(hash join)操作时,内表(inner table)需要完全构建哈希表后,才能与外表(outer table)进行连接。如果没有同步机制,某些 worker 可能会在内表构建完成之前就开始与外表进行连接,导致错误结果。barrier 机制正是用来保证所有 worker 在继续下一步操作之前都完成了必需的工作。
JOIN Barrier
在并行执行 JOIN 操作时,inner plan 会被多个 worker 并行执行,并且所有 worker 共同构建一个共享的哈希表。为了确保在执行连接操作前哈希表已经构建完成,所有 worker 必须等待其他 worker 完成它们的任务才能继续下一步。图示中的虚线代表了所有 worker 进程的 barrier 点,只有当所有 worker 达到此点后,才能继续执行后续操作。
05 Cloudberry 并行化效果
通过一个实际的例子来展示 Cloudberry 并行化的效果。( Example in https://github.com/apache/cloudberry/pull/30)
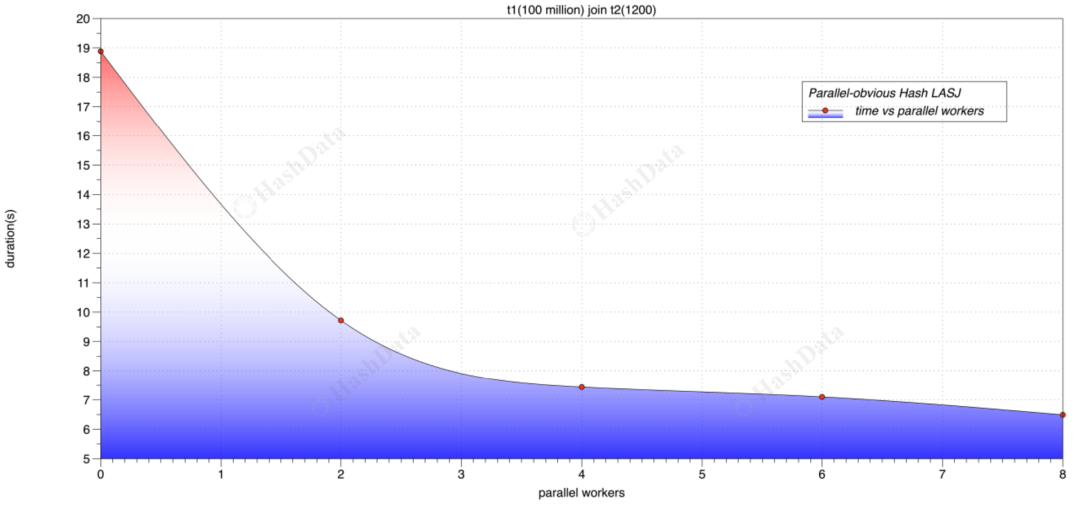
该例子涉及 T1 表和 T2 表的 join 操作,随着 worker 数的增加,性能有所提升。然而,当 worker 数增加到一定程度(如 4 个 worker)时,性能趋于稳定。即使增加更多的 worker,性能的提升也非常有限,这表明并行化的效果会受到硬件资源(如 IO 或 CPU)的限制。因此,在实际应用中,建议根据具体情况将并行度设置为 2 到 4 之间,以获得最佳性能。
06 结 语
Apache Cloudberry 通过深度重构 PostgreSQL 的并行框架,在分布式执行、数据局部性优化、动态资源管理等方面展现了显著优势。当然,Cloudberry 的并行化特性还存在一些不足之处,比如目前还不支持更多的算子以及 ORCA 优化器等。
在未来的发展中,我们将继续完善这些功能,并结合资源组控制等技术来进一步提升 Cloudberry 的性能和稳定性。同时,我们也欢迎大家加入 Apache Cloudberry 社区,共同为社区的发展和优化贡献自己的力量。
推荐阅读
👇🏻️扫码加入 Apache Cloudberry 交流群👇🏻️

