




背景
PolarDB-X 中使用 MySQL 作为数据节点(DN),并依赖 MySQL 提供的外部 XA 事务机制实现了分布式事务。MySQL是一个支持多存储引擎架构的数据库,InnoDB 是目前比较常用的存储引擎之一。InnoDB 支持了多种事务隔离级别,并通过 MVCC 的并发控制策略提供了快照读的能力。快照读指的是,存储引擎可以在的情况下,读取满足较高隔离级别(SI 或 RR)的数据但不需要持有读锁,能大幅提升数据库的吞吐能力。然而在 PolarDB-X 1.0 分布式事务的模式下,为了保证不同分库之间的一致性,我们不得不放弃 InnoDB 快照读的能力,完全使用基于锁的读取模式进行并发控制。具体来说,我们需要给事务中的每条 SELECT 语句加上 LOCK IN SHARE MODE,这样大大限制了 PolarDB-X 的并发吞吐能力。详情可以参考 PolarDB-X 分布式事务的实现(一)。
为了解决上面这个问题,我们为 PolarDB-X 2.0 的 InnoDB 引擎中添加了 CTS(Commit Timestamp)扩展。在具体介绍这个扩展之前,我们先看一下在分布式事务模式下如果使用快照读会带来什么问题。
在一个分布式事务中,往往会有多个分库的参与,这些分库通常也不在一个数据节点(DN)上。一个分布式事务在不同 DN 执行 XA COMMIT 的时间不同,而一个分布式事务的读请求在不同 DN 进行快照读的时间也不同,这意味着事务 T1 发起一个跨 DN 的读请求时,可能在部分 DN 上读到另一个跨 DN 分布式事务 T2 的已提交数据,而在另一个 DN 上却没有读到 T2 提交的数据,这样读到的数据不是一个全局的一致性视图(Snapshot)。这个问题在我们引入 GSI(全局二级索引)以后更加明显。GSI 是 PolarDB-X 2.0 中的一个重要 feature,会把二级索引全局打散到不同的 DN,我们可以看一个例子:

假设我们有一张表 t_order,有主键 id 和 seller_id 两个字段,其中我们为 seller_id 构建了全局二级索引,同时数据表和索引表都基于主键作为哈希键分散在两个 DN 上。那么当 User1 尝试将 id 为 0 的数据表中的 seller_id 从 2 变为 1 时,我们会涉及在两个DN上的三个操作:
- 更新 DN 1 上的数据表 t_order_0 中 id = 0 记录的 seller_id 字段
- 删除 DN 1 上的索引表 t_order_seller_id_0 中 seller_id = 1 的字段
- 插入 DN 2 上的索引表 t_order_seller_id_1,添加 seller_id = 2,id = 0 的字段
如果在事务的 Commit 阶段,有一个并行的新的读请求使用 seller_id 的 GSI 扫描 t_order,那么可能出现非常不符合预期的情况,如图所示,这个读请求在 DN 1 读到了更新后的数据,所以并没有读到 t_order_seller_id_0 中已删除的记录,而在 DN 2 上又只能读到更新前的数据,依然没有读到 t_order_seller_id_1中新增加的记录。id = 1 的记录从这次扫描结果中消失了!事实上,这 4 个并行的请求可能产生 16 种执行顺序,而只有其中 4 种能获得预期的结果,剩下的都会产生一一些不同的非预期现象,包括记录消失或者同一条记录出现了多次,这对用户来说是不可接受的。
我们如果想实现分布式事务的快照读,最重要的是需要为所有事务的提交和快照读确定一个全局唯一的顺序。对于每个分布式事务,我们定义了两个序号,一个是事务启动时的序号 snapshot_seq(用于快照读),一个是事务提交的序号 commit_seq。这个序号需要保证全局唯一且单调递增,为此我们也在 PolarDB-X 2.0 引入了一个新的节点 TSO(Timestamp Oracle),TSO 可以发放全局唯一且递增的时间戳作为序号,TSO 实现的细节我们会在后续的文章介绍。同时我们也扩展了 InnoDB 支持基于全局提交时间戳(CTS)的可见性判断,本文会重点介绍 InnoDB 中 CTS 的实现。
实现细节
语法支持
第一个需要解决的问题是如何将 snapshot_seq 和 commit_seq 在正常事务的流程中传给 MySQL,为了减小对 MySQL 的修改,我们通过两个系统变量来传递参数:
SET innodb_snapshot_seq = 6770711951572992000; # 快照读 SELECT * FROM test; INSERT INTO test VALUES (1), (2); XA BEGIN "trx1"; XA END "trx1"; XA PREPARE "trx1"; set innodb_commit_seq = 6770711989321728000; XA COMMIT "trx1";复制
这两个系统变量会被绑定到 THD 的结构体中,并传递给引擎层的 InnoDB。这种支持方式会增加物理 SQL 的数量,影响性能,因此我们在生产环境中支持通过私有协议直接传递 snapshot_seq 和 commit_seq。
为了保证数据恢复回放和备库同步时也能读到正确的数据,set *_seq 语句也会通过我们添加的 Sequence_event 保存在 binlog 中。
可见性判断
由于涉及了对可见性判断的修改,我们首先需要研究一下 InnoDB 原先的实现。在 InnoDB 中,使用一个 ReadView 的结构体来代表一个快照读,用 trx_t 来代表一个事务。
class ReadView { //... /** The read should not see any transaction with trx id >= this value. In other words, this is the "high water mark". */ trx_id_t m_low_limit_id; /** The read should see all trx ids which are strictly smaller (<) than this value. In other words, this is the low water mark". */ trx_id_t m_up_limit_id; /** trx id of creating transaction, set to TRX_ID_MAX for free views. */ trx_id_t m_creator_trx_id; /** Set of RW transactions that was active when this snapshot was taken */ ids_t m_ids; // ... } struct trx_t { trx_id_t id; /*!< transaction id */ // ... }复制
每个 trx 的 id 是由 trx_sys 的一个变量分配的单调递增的唯一 id,而 m_low_limit_id 则是创建 ReadView 时系统分配的最大 trx_id —— 这意味着任何大于 m_low_limit_id 的事务都是在 ReadView 之后创建的,一定对这个 ReadView 不可见。而 m_up_limit_id 则是创建 ReadView 时最小的活跃事务 id,更小的事务已经完成该提交,对这个 ReadView 来说一定可见。同时 ReadView 也保存了创建时的活跃事务列表。

那么可见性的判断规则是很显然的,一个事务 trx 对一个 ReadView view 是否可见,如果 trx->id 在上下两个水位线的之间,那么就遍历 view->m_ids 来判断 —— 如果 trx->id 在创建 ReadView 时已经是活跃事务,那么它一定对 view 可见。一个特例是每个 trx 可以读到自己的修改,所以 ReadView 中也存了 m_creator_trx_id 来判断这种情况。
对于分布式事务来说,这套实现就不可能复用了。在分布式场景下,维护活跃事务列表的难度非常大,因此我们实现了一套完全基于时间戳的判断规则。

我们在 trx_sys 中添加了一些关键变量:
- commit_seq_cache:array<commit_seq_t>,一个 ring buffer,保存最近 CACHE_SIZE 个事务的状态或 commit_seq
- commit_seq_evicted_map:unordered_map<trx_id_t, commit_seq_t> 保存 evicted 事务的状态或 commit_seq
- max_evicted_trx_id: commit_seq_cache 和 commit_seq_evicted_map 的边界
- snapshot_seq_lower_bound: purge 的边界,更早的 snapshot 无法创建,后文会解释
- max_sequence: 用与 sequence 的持久化与恢复
- max_commit_sequence: 用于 Learner 一致性读有关,后文会解释
commit_seq_cache 和 commit_seq_evicted_map 是同样的目的,就是保存每个 trx_id 到 commit_seq 的映射。由于在我们的设计中,读是非常高频的操作,我们使用了一个 ring buffer commit_seq_cache 来保存比较新的事务 sequence,同时对 cache 的读也是 lock free 的实现。只有超过 CACHE_SIZE 之前的事务,才会被 evict 到 commit_seq_evicted_map 进行读取。
为了尽可能减少对 InnoDB 内核代码的影响,我们将相关的逻辑都抽到了独立的结构体 ReadViewCTS 和 TransactionCTS 中,对之前的代码仅做少量 hook:
class TransactionCTS { // 上文解释过的变量 std::unique_ptr<std::atomic<transaction::sequence_number_t>[]> m_commit_seq_cache; EvictedMap m_evicted_map; std::atomic<trx_id_t> m_max_evicted_trx_id; std::atomic<transaction::sequence_number_t> m_snapshot_seq_lower_bound; std::atomic<transaction::sequence_number_t> m_max_sequence; std::atomic<transaction::sequence_number_t> m_max_commit_sequence; // 新事务创建,更新 CTS 中事务的状态为 RUNNING void insert(trx_id_t trx_id); // 在事务 prepare 前调用,更新为 CTS 中事务的状态为 PREPARED void prepare_pre(trx_id_t trx_id, transaction::sequence_number_t snapshot_seq); // 在事务 prepare 成功后调用 void prepare_post(trx_id_t trx_id); // 在事务 commit 前调用,更新为 CTS 中事务的状态为 COMMITTED,并保存 commit_seq bool commit_pre(trx_id_t trx_id, transaction::sequence_number_t commit_seq); // 在事务 commit 后调用,通知被该事务阻塞的 ReadView void commit_post(trx_id_t trx_id); // 事务回滚,更新 CTS 中事务的状态为 ROLLBACKING void rollback(trx_id_t trx_id); } class ReadViewCTS { transaction::sequence_number_t m_snapshot_seq; // 基于 CTS 的可见性判断 bool changes_visible(trx_id_t id) { auto state_or_seq = find_seq_in_cache_or_evicted_map(id); // 兼容非分布式事务,默认返回可见 if (state_or_seq == COMMIT_SEQ_EMPTY) return true; // 回滚中的事务不可见 if (state_or_seq == COMMIT_SEQ_ROLLBACKING) return false; // 活跃事务不可见 if (state_or_seq == COMMIT_SEQ_RUNNING) return false; // PREPARED 中的事务需要等待 if (state_or_seq == COMMIT_SEQ_PREPARED) { // 阻塞等待,然后重试 block_until_commit_or_rollback(); return changes_visible(id); } // 事务已提交,state_or_seq 就是 commit_seq return state_or_seq <= m_snapshot_seq; } }复制
Purge
MVCC 的实现往往需要 purge 线程来回收历史版本,在 InnoDB 原本的实现中,purge 线程会定期 clone 当前 ReadView 列表里创建最早的 ReadView 作为 purge_view,凡是 purge_view 不可见的都是可以回收的版本。但在 CTS 模式下,这个结论就不成立了。一个创建很早的事务(snapshot_seq 较低)可能在比较晚的时候才第一次访问某个 DN 节点,这在大规模扫描备份数据的场景中很常见,如果按照原本的 purge 逻辑,这时候新创建的 ReadView 但 snapshot_seq 较小,应该读到的数据已经被 purge 了。
为此我们也修改了 purge 的逻辑,通过一个预先配置好的变量 innodb_purge_history 来定义允许每个版本存活的时间,并且修改了 purge_view 的 snapshot_seq,让它对 innodb_purge_history 内的修改全部可见,这样数据就不会被提前回收了。purge_view 的 snapshot_seq 会记录在上文提到过的 snapshot_seq_lower_bound,小于 lower_bound 的 ReadView 就不允许再被创建了。
Learner 一致性读
PolarDB-X 的 DN 节点是基于 X-Paxos 同步 binlog 作为 consensus log 保障数据安全的,那么通过 CTS 的能力,我们也可以在非 Leader 节点上也读到一致的数据,降低 Leader 的压力。
我们修改后的 binlog 是以如下形式组织事务的,加入了 Sequence Event 来同步 commit_seq:

事实上,一个事务可能由很多 event 组成,但只会原子地记录两次 binlog,一次是事务的修改操作到 Prepare 的过程,一次是 Commit 的过程(Sequence + Commit)。那么进行 Learner 读的时候,我们就要面临一个问题:如果我们使用 snapshot_seq = R1 对 Learner 进行读取的时候,有某个事务 T1 的 commit_seq C1 < R,但是 prepare 事件还没同步到 Learner(如果同步到了就会阻塞等到 commit,是安全的实现),Learner 完全不知道 T1 的存在,那么 R1 就会忽略本来应该读到的 T1 的修改,产生和主库不一样的结果(如上图中的事务 4)。
在常见的 Learner 一致性读方案中,通常是先通过 Leader 获取一次 consensus log 的 index,确保 Learner 同步到对应位置以后才进行读取。我们观察到 binlog 中最重要事件是 Prepare -> Sequence -> Commit,同一个事务的这三个事件在 binlog 中一定是有序的。在我们的实现中,我们在在 trx_sys 中为每个节点维护 max_commit_seq,对于小于 max_commit_seq 的快照读请求。基于三个事件的顺序,我们可以确定对于未来 commit_seq > max_commit_seq 的事务,在这个阶段一定已经完成了 Prepare 的操作,因此可以直接在 Learner 进行读取。如果不满足这个条件,就阻等待或者 fallback 到基础策略。这种实现方式降低了延迟,也保证了备库的一致性读请求不会对主库造成任何性能影响。
总结
背景
PolarDB-X 中使用 MySQL 作为数据节点(DN),并依赖 MySQL 提供的外部 XA 事务机制实现了分布式事务。MySQL是一个支持多存储引擎架构的数据库,InnoDB 是目前比较常用的存储引擎之一。InnoDB 支持了多种事务隔离级别,并通过 MVCC 的并发控制策略提供了快照读的能力。快照读指的是,存储引擎可以在的情况下,读取满足较高隔离级别(SI 或 RR)的数据但不需要持有读锁,能大幅提升数据库的吞吐能力。然而在 PolarDB-X 1.0 分布式事务的模式下,为了保证不同分库之间的一致性,我们不得不放弃 InnoDB 快照读的能力,完全使用基于锁的读取模式进行并发控制。具体来说,我们需要给事务中的每条 SELECT 语句加上 LOCK IN SHARE MODE,这样大大限制了 PolarDB-X 的并发吞吐能力。详情可以参考 PolarDB-X 分布式事务的实现(一)。
为了解决上面这个问题,我们为 PolarDB-X 2.0 的 InnoDB 引擎中添加了 CTS(Commit Timestamp)扩展。在具体介绍这个扩展之前,我们先看一下在分布式事务模式下如果使用快照读会带来什么问题。
在一个分布式事务中,往往会有多个分库的参与,这些分库通常也不在一个数据节点(DN)上。一个分布式事务在不同 DN 执行 XA COMMIT 的时间不同,而一个分布式事务的读请求在不同 DN 进行快照读的时间也不同,这意味着事务 T1 发起一个跨 DN 的读请求时,可能在部分 DN 上读到另一个跨 DN 分布式事务 T2 的已提交数据,而在另一个 DN 上却没有读到 T2 提交的数据,这样读到的数据不是一个全局的一致性视图(Snapshot)。这个问题在我们引入 GSI(全局二级索引)以后更加明显。GSI 是 PolarDB-X 2.0 中的一个重要 feature,会把二级索引全局打散到不同的 DN,我们可以看一个例子:
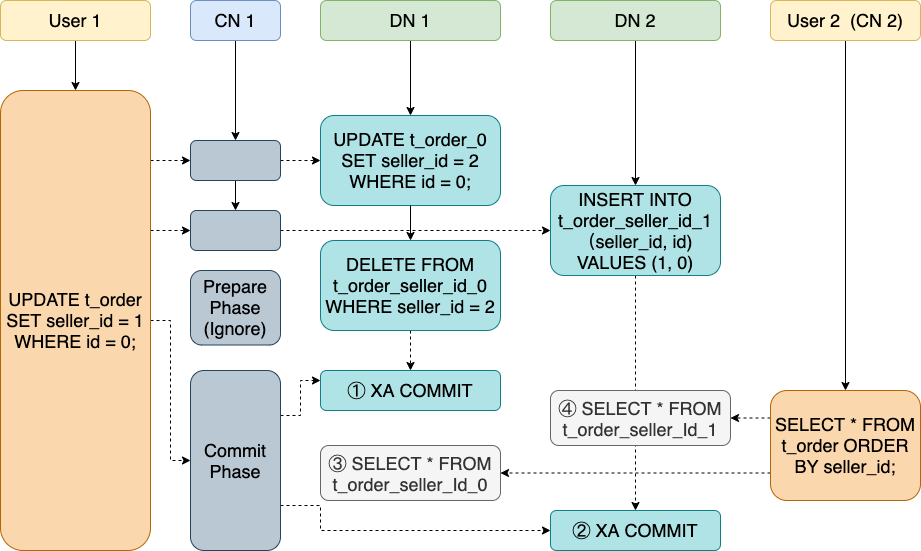
假设我们有一张表 t_order,有主键 id 和 seller_id 两个字段,其中我们为 seller_id 构建了全局二级索引,同时数据表和索引表都基于主键作为哈希键分散在两个 DN 上。那么当 User1 尝试将 id 为 0 的数据表中的 seller_id 从 2 变为 1 时,我们会涉及在两个DN上的三个操作:
- 更新 DN 1 上的数据表 t_order_0 中 id = 0 记录的 seller_id 字段
- 删除 DN 1 上的索引表 t_order_seller_id_0 中 seller_id = 1 的字段
- 插入 DN 2 上的索引表 t_order_seller_id_1,添加 seller_id = 2,id = 0 的字段
如果在事务的 Commit 阶段,有一个并行的新的读请求使用 seller_id 的 GSI 扫描 t_order,那么可能出现非常不符合预期的情况,如图所示,这个读请求在 DN 1 读到了更新后的数据,所以并没有读到 t_order_seller_id_0 中已删除的记录,而在 DN 2 上又只能读到更新前的数据,依然没有读到 t_order_seller_id_1中新增加的记录。id = 1 的记录从这次扫描结果中消失了!事实上,这 4 个并行的请求可能产生 16 种执行顺序,而只有其中 4 种能获得预期的结果,剩下的都会产生一一些不同的非预期现象,包括记录消失或者同一条记录出现了多次,这对用户来说是不可接受的。
我们如果想实现分布式事务的快照读,最重要的是需要为所有事务的提交和快照读确定一个全局唯一的顺序。对于每个分布式事务,我们定义了两个序号,一个是事务启动时的序号 snapshot_seq(用于快照读),一个是事务提交的序号 commit_seq。这个序号需要保证全局唯一且单调递增,为此我们也在 PolarDB-X 2.0 引入了一个新的节点 TSO(Timestamp Oracle),TSO 可以发放全局唯一且递增的时间戳作为序号,TSO 实现的细节我们会在后续的文章介绍。同时我们也扩展了 InnoDB 支持基于全局提交时间戳(CTS)的可见性判断,本文会重点介绍 InnoDB 中 CTS 的实现。
实现细节
语法支持
第一个需要解决的问题是如何将 snapshot_seq 和 commit_seq 在正常事务的流程中传给 MySQL,为了减小对 MySQL 的修改,我们通过两个系统变量来传递参数:
SET innodb_snapshot_seq = 6770711951572992000; # 快照读 SELECT * FROM test; INSERT INTO test VALUES (1), (2); XA BEGIN "trx1"; XA END "trx1"; XA PREPARE "trx1"; set innodb_commit_seq = 6770711989321728000; XA COMMIT "trx1";复制
这两个系统变量会被绑定到 THD 的结构体中,并传递给引擎层的 InnoDB。这种支持方式会增加物理 SQL 的数量,影响性能,因此我们在生产环境中支持通过私有协议直接传递 snapshot_seq 和 commit_seq。
为了保证数据恢复回放和备库同步时也能读到正确的数据,set *_seq 语句也会通过我们添加的 Sequence_event 保存在 binlog 中。
可见性判断
由于涉及了对可见性判断的修改,我们首先需要研究一下 InnoDB 原先的实现。在 InnoDB 中,使用一个 ReadView 的结构体来代表一个快照读,用 trx_t 来代表一个事务。
class ReadView { //... /** The read should not see any transaction with trx id >= this value. In other words, this is the "high water mark". */ trx_id_t m_low_limit_id; /** The read should see all trx ids which are strictly smaller (<) than this value. In other words, this is the low water mark". */ trx_id_t m_up_limit_id; /** trx id of creating transaction, set to TRX_ID_MAX for free views. */ trx_id_t m_creator_trx_id; /** Set of RW transactions that was active when this snapshot was taken */ ids_t m_ids; // ... } struct trx_t { trx_id_t id; /*!< transaction id */ // ... }复制
每个 trx 的 id 是由 trx_sys 的一个变量分配的单调递增的唯一 id,而 m_low_limit_id 则是创建 ReadView 时系统分配的最大 trx_id —— 这意味着任何大于 m_low_limit_id 的事务都是在 ReadView 之后创建的,一定对这个 ReadView 不可见。而 m_up_limit_id 则是创建 ReadView 时最小的活跃事务 id,更小的事务已经完成该提交,对这个 ReadView 来说一定可见。同时 ReadView 也保存了创建时的活跃事务列表。
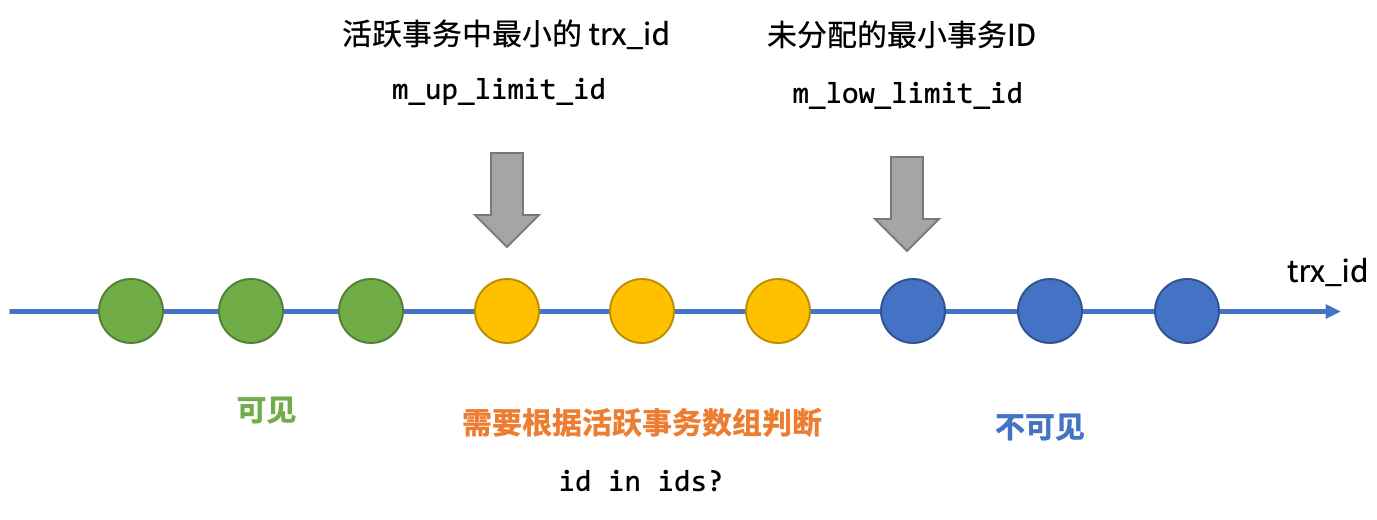
那么可见性的判断规则是很显然的,一个事务 trx 对一个 ReadView view 是否可见,如果 trx->id 在上下两个水位线的之间,那么就遍历 view->m_ids 来判断 —— 如果 trx->id 在创建 ReadView 时已经是活跃事务,那么它一定对 view 可见。一个特例是每个 trx 可以读到自己的修改,所以 ReadView 中也存了 m_creator_trx_id 来判断这种情况。
对于分布式事务来说,这套实现就不可能复用了。在分布式场景下,维护活跃事务列表的难度非常大,因此我们实现了一套完全基于时间戳的判断规则。

我们在 trx_sys 中添加了一些关键变量:
- commit_seq_cache:array<commit_seq_t>,一个 ring buffer,保存最近 CACHE_SIZE 个事务的状态或 commit_seq
- commit_seq_evicted_map:unordered_map<trx_id_t, commit_seq_t> 保存 evicted 事务的状态或 commit_seq
- max_evicted_trx_id: commit_seq_cache 和 commit_seq_evicted_map 的边界
- snapshot_seq_lower_bound: purge 的边界,更早的 snapshot 无法创建,后文会解释
- max_sequence: 用与 sequence 的持久化与恢复
- max_commit_sequence: 用于 Learner 一致性读有关,后文会解释
commit_seq_cache 和 commit_seq_evicted_map 是同样的目的,就是保存每个 trx_id 到 commit_seq 的映射。由于在我们的设计中,读是非常高频的操作,我们使用了一个 ring buffer commit_seq_cache 来保存比较新的事务 sequence,同时对 cache 的读也是 lock free 的实现。只有超过 CACHE_SIZE 之前的事务,才会被 evict 到 commit_seq_evicted_map 进行读取。
为了尽可能减少对 InnoDB 内核代码的影响,我们将相关的逻辑都抽到了独立的结构体 ReadViewCTS 和 TransactionCTS 中,对之前的代码仅做少量 hook:
class TransactionCTS { // 上文解释过的变量 std::unique_ptr<std::atomic<transaction::sequence_number_t>[]> m_commit_seq_cache; EvictedMap m_evicted_map; std::atomic<trx_id_t> m_max_evicted_trx_id; std::atomic<transaction::sequence_number_t> m_snapshot_seq_lower_bound; std::atomic<transaction::sequence_number_t> m_max_sequence; std::atomic<transaction::sequence_number_t> m_max_commit_sequence; // 新事务创建,更新 CTS 中事务的状态为 RUNNING void insert(trx_id_t trx_id); // 在事务 prepare 前调用,更新为 CTS 中事务的状态为 PREPARED void prepare_pre(trx_id_t trx_id, transaction::sequence_number_t snapshot_seq); // 在事务 prepare 成功后调用 void prepare_post(trx_id_t trx_id); // 在事务 commit 前调用,更新为 CTS 中事务的状态为 COMMITTED,并保存 commit_seq bool commit_pre(trx_id_t trx_id, transaction::sequence_number_t commit_seq); // 在事务 commit 后调用,通知被该事务阻塞的 ReadView void commit_post(trx_id_t trx_id); // 事务回滚,更新 CTS 中事务的状态为 ROLLBACKING void rollback(trx_id_t trx_id); } class ReadViewCTS { transaction::sequence_number_t m_snapshot_seq; // 基于 CTS 的可见性判断 bool changes_visible(trx_id_t id) { auto state_or_seq = find_seq_in_cache_or_evicted_map(id); // 兼容非分布式事务,默认返回可见 if (state_or_seq == COMMIT_SEQ_EMPTY) return true; // 回滚中的事务不可见 if (state_or_seq == COMMIT_SEQ_ROLLBACKING) return false; // 活跃事务不可见 if (state_or_seq == COMMIT_SEQ_RUNNING) return false; // PREPARED 中的事务需要等待 if (state_or_seq == COMMIT_SEQ_PREPARED) { // 阻塞等待,然后重试 block_until_commit_or_rollback(); return changes_visible(id); } // 事务已提交,state_or_seq 就是 commit_seq return state_or_seq <= m_snapshot_seq; } }复制
Purge
MVCC 的实现往往需要 purge 线程来回收历史版本,在 InnoDB 原本的实现中,purge 线程会定期 clone 当前 ReadView 列表里创建最早的 ReadView 作为 purge_view,凡是 purge_view 不可见的都是可以回收的版本。但在 CTS 模式下,这个结论就不成立了。一个创建很早的事务(snapshot_seq 较低)可能在比较晚的时候才第一次访问某个 DN 节点,这在大规模扫描备份数据的场景中很常见,如果按照原本的 purge 逻辑,这时候新创建的 ReadView 但 snapshot_seq 较小,应该读到的数据已经被 purge 了。
为此我们也修改了 purge 的逻辑,通过一个预先配置好的变量 innodb_purge_history 来定义允许每个版本存活的时间,并且修改了 purge_view 的 snapshot_seq,让它对 innodb_purge_history 内的修改全部可见,这样数据就不会被提前回收了。purge_view 的 snapshot_seq 会记录在上文提到过的 snapshot_seq_lower_bound,小于 lower_bound 的 ReadView 就不允许再被创建了。
Learner 一致性读
PolarDB-X 的 DN 节点是基于 X-Paxos 同步 binlog 作为 consensus log 保障数据安全的,那么通过 CTS 的能力,我们也可以在非 Leader 节点上也读到一致的数据,降低 Leader 的压力。
我们修改后的 binlog 是以如下形式组织事务的,加入了 Sequence Event 来同步 commit_seq:

事实上,一个事务可能由很多 event 组成,但只会原子地记录两次 binlog,一次是事务的修改操作到 Prepare 的过程,一次是 Commit 的过程(Sequence + Commit)。那么进行 Learner 读的时候,我们就要面临一个问题:如果我们使用 snapshot_seq = R1 对 Learner 进行读取的时候,有某个事务 T1 的 commit_seq C1 < R,但是 prepare 事件还没同步到 Learner(如果同步到了就会阻塞等到 commit,是安全的实现),Learner 完全不知道 T1 的存在,那么 R1 就会忽略本来应该读到的 T1 的修改,产生和主库不一样的结果(如上图中的事务 4)。
在常见的 Learner 一致性读方案中,通常是先通过 Leader 获取一次 consensus log 的 index,确保 Learner 同步到对应位置以后才进行读取。我们观察到 binlog 中最重要事件是 Prepare -> Sequence -> Commit,同一个事务的这三个事件在 binlog 中一定是有序的。在我们的实现中,我们在在 trx_sys 中为每个节点维护 max_commit_seq,对于小于 max_commit_seq 的快照读请求。基于三个事件的顺序,我们可以确定对于未来 commit_seq > max_commit_seq 的事务,在这个阶段一定已经完成了 Prepare 的操作,因此可以直接在 Learner 进行读取。如果不满足这个条件,就阻等待或者 fallback 到基础策略。这种实现方式降低了延迟,也保证了备库的一致性读请求不会对主库造成任何性能影响。
总结
本文介绍了 PolaraDB-X 对 InnoDB 的改造,通过 CTS 的支持摆脱了分布式事务在中间件模式的局限性。基于 InnoDB CTS 扩展,PolarDB-X 提供了高性能的全局一致分布式事务支持。本文介绍了 PolaraDB-X 对 InnoDB 的改造,通过 CTS 的支持摆脱了分布式事务在中间件模式的局限性。基于 InnoDB CTS 扩展,PolarDB-X 提供了高性能的全局一致分布式事务支持。
