




1、PG概述
PostgreSQL是一个功能非常强大的、源代码开放的客户/服务器关系型数据库管理系统(RDBMS)。PostgreSQL最初设想于1986年,当时被叫做Berkley Postgres Project。该项目一直到1994年都处于演进和修改中,直到开发人员Andrew Yu和Jolly Chen在Postgres中添加了一个SQL(Structured Query Language,结构化查询语言)翻译程序,该版本叫做Postgres95,在开放源代码社区发放。
1996年,再次对Postgres95做了较大的改动,并将其作为PostgresSQL6.0版发布。该版本的Postgres提高了后端的速度,包括增强型SQL92标准以及重要的后端特性(包括子选择、默认值、约束和触发器)。
PostgreSQL是一个非常健壮的软件包,有很多在大型商业RDBMS中所具有的特性,包括事务、子选择、触发器、视图、外键引用完整性和复杂锁定功能。另一方面,PostgreSQL也缺少商业数据库中某些可用的特性,如用户定义的类型、继承性和规则。
2020-05-21,PostgreSQL全球开发组宣布PostgreSQL13的第一个Beta版本正式提供下载。这个版本包含将来PostgreSQL 13正式版本中的所有特性和功能,当然一些功能的细节在正式版本发布时可能会有些变化。
鉴于PG版本的稳定性和使用广泛性,我们选择PG11--postgresql-11.7这个版本。
2、高可用架构概述
Patroni+ ZooKeeper 方案:
健壮性:使用分布式文件系统作为数据存储,主节点故障时进行主节点重新选举,具有很强的健壮性。
支持多种复制方式: 基于内置流复制,支持同步流复制、异步流复制、级联复制。
支持主备延迟设置:可以设置备库延迟主库WAL的字节数,当备库延迟大于指定值时不做故障切换。
自动化程度高: 1)支持自动化初始PostgreSQL实例并部署流复制; 2)当备库实例关闭后,支持自动拉起; 3)当主库实例关闭后,首先会尝试自动拉起; 4)支持switchover命令,能自动将老的主库进行角色转换。
避免脑裂: 数据库信息记录到ZOOKEEPER 中,通过优化部署策略(多机房部署、增加实例数)可以避免脑裂。
2.1. Patroni简介
Patroni基于Python开发的模板,结合DCS(例如ZooKeeper, ETCD, Consul )可以定制PostgreSQL高可用方案。
Patroni并不是一套拿来即用的PostgreSQL高可用组件,涉及较多的配置和定制工作。
Patroni接管PostgreSQL数据库的启停,同时监控本地的PostgreSQL数据库,并将本地的PostgreSQL数据库信息写入DCS。
Patroni的主备端是通过是否能获得leader key 来控制的,获取到了leader key的Patroni为主节点,其它的为备节点。
2.2. ZooKeeper简介
ZooKeeper是一款基于FastPaxos算法和协议开发的,Zookeeper 分布式服务框架是Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。Patroni监控本地的PostgreSQL状态,并将相关信息写入ZooKeeper,每个Patroni都能读写ZooKeeper上的key,从而获取外地PostgreSQL数据库信息。
当ZooKeeper的leader节点不可用时,ZooKeeper会一致性的选择一个合适的节点作为主节点,新的ZooKeeper主节点将获取leader key,因此建议ZooKeeper集群为三个以上且为奇数的节点,不建议部署在同一个机房,有条件话尽量部署在三个机房。
一个标准的3节点ZooKeeper集群,最大容许1个节点故障。
3、读写分离和虚拟IP
3.1. HAProxy
HAProxy提供高可用性、负载均衡以及基于TCP和HTTP应用的代理,支持虚拟主机,它是免费、快速并且可靠的一种解决方案。HAProxy特别适用于那些负载特大的web站点, 这些站点通常又需要会话保持或七层处理。HAProxy运行在当前的硬件上,完全可以支持数以万计的并发连接。并且它的运行模式使得它可以很简单安全的整合进当前的架构中,同时可以保护你的web服务器不被暴露到网络上。
HAProxy做数据库读写分离,主要是通过限制访问的端口号来实现,例如访问5000端口是主数据库,可读可写;访问5001端口连接的是从数据库,做只读查询。
3.2. Keepalive
通过keepalive 来实现 PostgreSQL 数据库的主从自动切换,以达到高可用,当主节点宕机时,从节点可自动切换为主节点,继续对外提供服务,同时为了保证 keepalived 不会出现单点故障,所以keepalived 也搭建主备节点,防止单点故障。
同时,可以使用keepalive虚拟出来的IP进行数据库访问,结合HAProxy的读写分离功能,进行实现可高可用下的读写分离。
4、实施方案目标
4.1. 实施方案总体拓扑
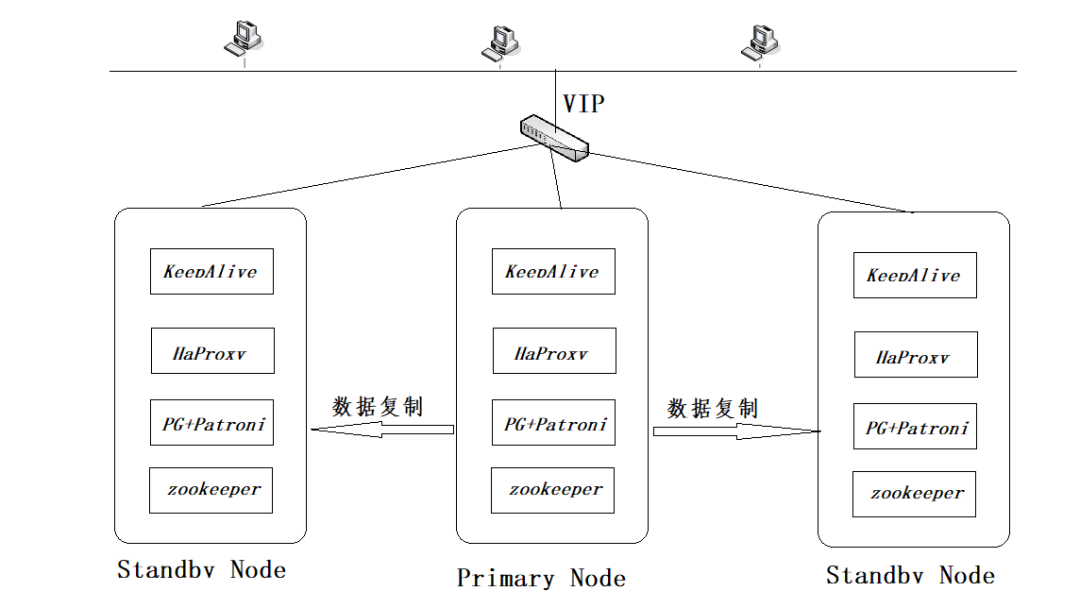
4.2. 实施方案拓扑说明
技术方案主要目的是:
Ø 利用zookeeper将节点做成分布式架构;
Ø 将postgresql 数据库和patroni软件结合,完成数据库的主从复制;
Ø 利用haproxy进行主库和从库的读写分离;
Ø 利用keepalive做节点间的高可用,并利用虚拟IP地址对外提供服务。
关键点是整合上述的各自功能,实现架构可自动切换的高可用功能。上述拓扑实施完成后,主要带来以下收益:
5、项目实施控制
数据库系统项目通常都是以循序渐进的方式推进,构建新的数据库平台。
6、实施环境准备
为了能让客户完成数据库整合项目,在项目实施前需要具备以下条件:
6.1. 主机
由于数据库整合项目,需要先构建三个数据库整合平台,因此必须有9台主机来建立数据库平台:
主机升级改造 | ||||
硬件名称 | 规格 | 数量 | 说明 | 其他 |
服务器 | CPU:24cpu MEM:64G 硬盘:服务可用存储空间不低于2T | 3 | 构建基于PG数据库的高可用平台 | 建议五台服务器,三台服务器用于做分布式主从复制,两台做高可用读写分离和VIP |
6.2. 存储
PG数据库的高可用平台可以使用本地磁盘空间,也可以单独挂载高性能存储设备。如果单独挂载存储设备,空间需求如下:
存储升级改造 | ||||
硬件名称 | 规格 | 数量 | 说明 | 其他 |
生产存储 | 10T容量 | 1台 | 用于生产存储,存储可以使用现有存储设备具体容量和需求以实际为主 | Raid 1+0 10T为可用空间 |
备份存储 | 20T容量 | 1台 | 用于备份存储,备份存储可以使用现有存储设备具体容量和需求以实际为主 | Raid 5 |
SAN交换机 | 6口 | 2台 | 用于搭建san环境 | 如存在,则忽略 |
6.3. 软件系统
如果对于软件有正版化需求,则需要额外购买正版化的Postgres,linux软件授权.
操作系统升级改造 | ||||
软件名称 | 规格 | 数量 | 说明 | 其他 |
PostgreSQL | 3套 | PG数据库的高可用平台 | ||
Patroni | 3套 | PG数据库的高可用平台 | ||
zookeeper | 3套 | PG数据库的高可用平台 | ||
haproxy | 3套 | PG数据库的高可用平台 | ||
keepalive | 3套 | PG数据库的高可用平台 | ||
RHEL 7.6 x64 | 企业版 | 3套 | 用于PG数据库的高可用平台操作系统 |
6.4. IP地址
实施过程中,对应很多软件都是开源的,安装相对繁琐复杂,因此建议打开互联网连接,能够和对应的安装源通信。
资源升级改造 | ||||
软件名称 | 规格 | 数量 | 说明 | 其他 |
公有IP地址 | 生产段 | 3 | 用于PG数据库的高可用平台公用IP,日常管理 | 开放5432关口 |
虚拟IP地址 | 生产段 | 1 | 用于PG数据库的高可用平台虚拟IP,集群高可用 | 开放5000和5001端口 |
7、实施方案
7.1. 规划
7.1.1. 软件版本
POSTGRES数据库集中平台: | |
项目 | 版本 |
操作系统 | Redhat Linux AS 7.6 64bit |
数据库软件版本 | PostgreSQL 11.7 |
7.1.2. 存储规划
生产存储数据库部分存储容量规划如下:
数据库名 | raid级别 | LUN | 可用容量(GB) | 用途 |
TWXPDS | 随操作系统 | LUN1:100G | 1T | 主要用于数据库存储, 暂时分配1T空间,Linux LVM方式,方便后面空的动态扩展 |
备份存储容量规划如下:
系统名称 | raid级别 | LUN | 可用容量(GB) | 用途 |
TWXPDS | 随操作系统 | LUN2:600G | 600G | 主要用于数据库备份,暂时分配600G空间,Linux LVM方式,方便后面空的动态扩展 |
WALS归档存储容量规划如下:
数据库名 | raid级别 | LUN | 可用容量(GB) | 用途 |
TWXPDS | 随操作系统 | LUN3:300G | 300G | 主要用于WALS归档,暂时分配300G空间,Linux LVM方式,方便后面空的动态扩展 |
7.1.3. 数据库命名约定
POSTGRES数据库集中平台: | |
项目 | 取值 |
群集名 | pg_micky |
主机名 | micky1、micky2、micky3 |
数据库名 | TWXPDS |
字符集 | UTF8 |
参数要求 | max_connections: 500 shared_buffers: 16000MB work_mem: 32MB maintenance_work_mem: 512MB synchronous_commit: on max_wal_size: 1GB min_wal_size: 80MB listen_addresses: '*' port: 5432 |
安装组 | groupadd -g 1000 postgres |
安装用户 | useradd -u 1000 -g postgres postgres |
软件目录 | mkdir -p /pgdata/data mkdir -p /backup mkdir -p /archive_wals mkdir -p /scripts
chown -R postgres.postgres /backup chown -R postgres.postgres /archive_wals chown -R postgres.postgres /scripts chown -R postgres.postgres /pgdata/data |
表空间命名 | TWXPDS |
7.1.4. 数据库网络规划
项目 | 取值 |
PUB IP | 192.168.24.140.X/255.255.254.0 |
VIP | 192.168.140.X |
网关 | 192.168.140.1 |
监听端口 | 5432 |
7.2. 数据库集中平台创建
7.2.1. 基础环境准备
1) 创建用户、组
以root身份运行以下命令:
groupadd -g 1001 postgres
useradd -u 1000 -g postgres postgres
设置postgres账户的密码:
passwd postgres
Changing password for user postgres.
New UNIX password: password
retype new UNIX password: password
passwd: all authentication tokens updatedsuccessfully.
2) IP规划(具体以实际为准)
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.140.74 micky1
192.168.140.75 micky2
192.168.140.76 micky3
3) 创建相关目录
数据库存放位置:
mkdir -p /pgdata/data
---存放pg数据库
mkdir -p /backup
---备份pg数据库
mkdir -p /archive_wals
---WALS归档
mkdir -p /scripts
---特殊脚本部署位置
授权给psotgres账户:
chown -R postgres.postgres/backup
chown -R postgres.postgres /archive_wals
chown -R postgres.postgres /scripts
chown -R postgres.postgres /pgdata/data
chown -R postgres:postgres /usr/local/postgresql
4) 共享存储规划(以实际需求为准):
/dev/mapper/pgbackup-pgbackup: 645.3 GB
/dev/mapper/pgdata-pgdata: 1099.5 GB
/dev/mapper/pgwals-pgwals: 322.1 GB
5) LVM相关操作
[root@micky1 ~]# vgcreate pgdata /dev/sdb2
Volume group"pgdata" successfully created
[root@micky1 ~]# vgcreate pgwals /dev/sdb3
Volume group"pgwals" successfully created
[root@micky1 ~]# vgcreate pgbackup/dev/sdb4
Volume group"pgbackup" successfully created
[root@micky1 ~]# lvcreate -l 100%VG -npgdata pgdata
Logicalvolume "pgdata" created.
[root@micky1 ~]# lvcreate -l 100%VG -npgwals pgwals
Logicalvolume "pgwals" created.
[root@micky1 ~]# lvcreate -l 100%VG -npgbackup pgbackup
Logicalvolume "pgbackup" created.
、
6) 创建用户Profile
创建 所有 用户环境文件:
export PATH=/usr/local/postgresql/bin:$PATH
exportLD_LIBRARY_PATH=/usr/local/postgresql/lib:$LD_LIBRARY_PATH
export ZKHOME=/u01/apache-zookeeper-3.6.1
PATH=$PATH:$HOME/bin:$ZKHOME/bin
创建 postgres 用户环境文件:
export PGHOME=/usr/local/postgresql
export PGDATA=/pgdata/data
7) 安全设置
关闭防火墙:
[root@micky3 ~]# systemctl stop firewalld.service
[root@micky3 ~]# systemctl disablefirewalld.service
设置SELinux:
[root@micky3 ~]# vi /etc/selinux/config
# This file controls the state of SELinux on thesystem.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled- No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of three values:
# targeted- Targeted processes are protected,
# minimum- Modification of targeted policy. Only selected processes are protected.
# mls -Multi Level Security protection.
SELINUXTYPE=targeted
8) 安装依赖包
rpm -ivh https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
yum -y install libffi-devel
wget -chttps://www.python.org/ftp/python/3.8.2/Python-3.8.2.tar.xz
cd Python-3.8.2
./configure --with-ssl
make && make install
创建Python软连接:
rm -f /usr/bin/python
ln -s /usr/local/bin/python3 /usr/bin/python
7.2.2. 软件安装
tarzxvf postgresql-11.7.tar.gz
cdpostgresql-11.7
./configure--prefix=/usr/local/postgresql
#编译安装
makeworld && make install-world
……
make[2]:Leaving directory `/root/postgresql-11.7/contrib/unaccent'
make-C vacuumlo install
make[2]:Entering directory `/root/postgresql-11.7/contrib/vacuumlo'
/usr/bin/mkdir-p '/usr/local/postgresql/bin'
/usr/bin/install-c vacuumlo '/usr/local/postgresql/bin'
make[2]:Leaving directory `/root/postgresql-11.7/contrib/vacuumlo'
make[1]:Leaving directory `/root/postgresql-11.7/contrib'
PostgreSQL,contrib, and documentation installation complete.
7.2.3. 初始化数据库
Step1初始化并启动数据库
#初始化数据库
initdb-D /pgdata/data
#启动服务
pg_ctl-D /pgdata/data -l /pgdata/data/logfile start
Step2修改参数并重启数据库
#修改postgresql.conf 文件
vi/pgdata/data/postgresql.conf
#修改为如下:
listen_addresses= '*'
port =5432
#--------------------允许远程连接---------------------------
#修改客户端认证配置文件pg_hba.conf,将需要远程访问数据库的IP地址或地址段加入该文件
vi/pgdata/data/pg_hba.conf
#在文件的最下方加上下面的这句话(出于安全考虑,不建议这样配置)
host all all 0.0.0.0/0 trust
host replication repuser 192.168.140.74/32 md5
host replication repuser 192.168.140.75/32 md5
host replication repuser 192.168.140.76/32 md5
pg_ctl-D /pgdata/data -l /pgdata/data/logfile stop
pg_ctl-D /pgdata/data -l /pgdata/data/logfile start
7.2.4. 配置主从同步
Step1主库创建Replication专有用户
主库创建Replication专有用户
CREATEUSER repuser REPLICATION ENCRYPTED PASSWORD 'postgres';
Step2配置主库postgresql.conf参数
altersystem set wal_level = replica;
altersystem set archive_mode = on;
altersystem set archive_command = '/bin/true';
altersystem set max_wal_senders = 10;
altersystem set wal_keep_segments = 512;
altersystem set hot_standby = on;
altersystem set synchronous_commit = on;
altersystem set synchronous_standby_names = 'pg_micky01,pg_micky02,pg_micky03'; srvctlstart alter system set archive_timeout = '30s';
altersystem set archive_command = 'cp %p /archive_wals/%f';
重启数据库:
pg_ctl-D /pgdata/data -l /pgdata/data/logfile stop
pg_ctl-D /pgdata/data -l /pgdata/data/logfile start
Step3备库上使用pg_basebackup从主库同步数据
[postgres@micky2 data]$ pg_basebackup -D /pgdata/data-Fp -Xs -v -P -h 192.168.140.74 -p 5432 -U repuser
Password:
pg_basebackup:initiating base backup, waiting for checkpoint to complete
pg_basebackup:checkpoint completed
pg_basebackup:write-ahead log start point: 0/2000060 on timeline 1
pg_basebackup:starting background WAL receiver
pg_basebackup:created temporary replication slot "pg_basebackup_81452"
23831/23831kB (100%), 1/1 tablespace
pg_basebackup:write-ahead log end point: 0/2000130
pg_basebackup:waiting for background process to finish streaming ...
pg_basebackup:base backup completed
Step4配置备库recovery.conf
cp/usr/local/postgresql/share/recovery.conf.sample /pgdata/data/recovery.conf
vi/pgdata/data/recovery.conf
#节点micky2
recovery_target_timeline= 'latest'
standby_mode= on
primary_conninfo= 'host=192.168.140.74 port=5432 user=repuser password=postgresapplication_name=pg_atj02'
#节点micky3
recovery_target_timeline= 'latest'
standby_mode= on
primary_conninfo= 'host=192.168.140.74 port=5432 user=repuser password=postgresapplication_name=pg_atj03'
重启备库
pg_ctl-D /pgdata/data -l /pgdata/data/logfile stop
pg_ctl-D /pgdata/data -l /pgdata/data/logfile start
Step5查看配置是否生效
postgres=#SELECT usename,application_name,client_addr,sync_state FROM pg_stat_replication;
usename | application_name | client_addr | sync_state
---------+------------------+---------------+------------
repuser | pg_micky02 | 192.168.140.74 | sync
repuser | pg_micky03 | 192.168.140.75 | potential
(2rows)
Step6插入数据查看同步情况
#创建测试数据库
createdatabase micky;
#切换到micky 数据库
\cmicky
#创建测试表
createtable micky (id integer, name text);
#插入测试数据
insertinto micky values (1,'micky');
#选择数据
select* from micky ;
备库查询:
micky=# select * frommicky ;
id | name
----+-------
1 | micky
(1 row)
