




一分钟吃透 spark 之 driver
driver 是驱动的意思, 也就是整个系统启动之后, 整个系统的运转时靠 driver 来驱动的, 用户自己的作业也是通过 driver 来分解和调度运行的。
spark driver 是运行在 主节点上的一个 jvm 进程, jvm 为每个spark 应用维护一个 sparkcontext, driver 管理着整个分布式系统的运行, 是总指挥, 当然他也是 靠着 DAGScheduler 和 Task Scheduler 来指挥打仗的。 同时 driver 提供 UI 的portal 给用户来查看整个作业的运转情况,
在正常分布式系统运转中, driver 把task 进行分解, 然后把分解后的 task 调度到 多个 executors上去执行, 同时收集运行完的结果, 对结果进行汇总, 如果作业还没有运行完, 如果还有下一个阶段, 然后推动继续分发汇总。
整个过程就像, 工地上工头把一堆砖头, 分成多份, 然后找几个码农搬砖,从 A地搬到B地, 每人负责搬一份, 如果谁搬完了, 就喊一声汇报一下, 工头等到全部砖头都搬到 B地, 然后再考虑要不要搬到 C地。
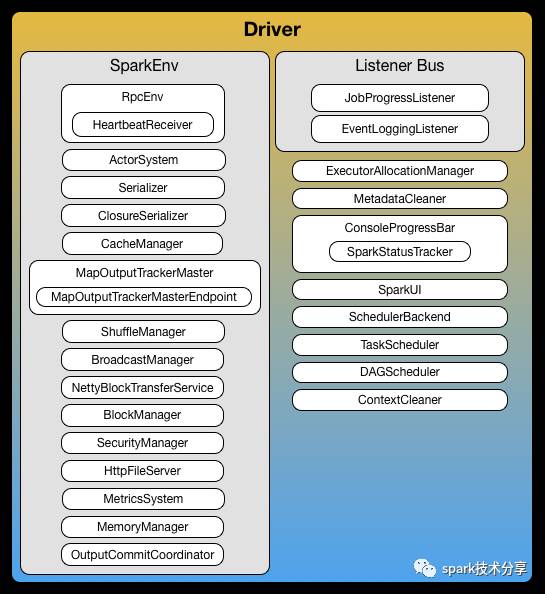
从上图中 我们能看到 driver 包括了那些组件, 单打独斗是不行的, 各个组件要积极一致相互配合, 才能玩得转, 下面我们来介绍一下这些组件在整个系统中都起了什么作用。
| 组件 | 作用 |
|---|---|
| SparkEnv | SparkEnv 负责创建所有的 公用的组件, 并且把各个组件组合起来,提供一个运行时环境, 这样各个组件互相调用的时候, 就能统一从 SparkEnv 中找到其他组件, 当然 SparkEnv 在 driver 和 executor 上是不一样的, 因为有可能 driver 上包含的组件是个 master 而在 executor 上包含的组件是一个 slave |
| RpcEnv | RpcEnv 提供一个 互相通信的 环境, 让 master 和 slave 之间可以通畅的进行通信, 管理着 RpcEndpoints 的整个生命周期, 启动 和注册 RpcEndpoints, 路由消息到 RpcEndpoints, stop RpcEndpoints 等 |
| ActorSystem | ActorSystem 这个是早期 spark 使用的远程调用方式, 现在已经废弃 |
| listenerBus | listenerBus负责 spark 的事件体系,假设我们要提交一个任务集。这个动作可能会很多人关心,我就是使用listenerBus把Event发出去,listenerBus里已经注册了很多监听者,我们叫listener,通常listenerBus 会启动一个线程异步的调用这些listener去消费这个Event。而所谓的消费,其实就是触发事先设计好的回调函数来执行譬如信息存储等动作。这就是整个listenerBus的工作方式。这里我们看到,其实类似于埋点,这是有侵入性的,每个你需要关注的地方,如果想让人知晓,就都需要发出一个特定的Event。 |
| Serializer | Serializer负责序列化, 默认是 JavaSerializer, 可以选择 KryoSerializer,对性能来讲,作用还是很大的, 主要是对 Shuffle数据, rdd cache 数据进行序列化, 减少网络传输的成本 |
| ClosureSerializer | ClosureSerializer主要负责 Task的序列化, 目前使用的是 JavaSerializer, 是闭包的方式,相当于把 task 执行的环境, 打包到 executor 上去执行 |
| CacheManager | CacheManager主要负责 缓存, 如果 用户把一个分区的 RDD 数据 cache了, 下次再用到了这份数据, 就直接可以从 缓存中获取, CacheManager 底层存储 用的是 BlockManager, CacheManager负责维护 缓存的元信息和协调 |
| MapOutputTrackerMaster | MapOutputTrackerMaster主要是维护shuffle 过程中数据的元信息, shuffle write 的时候,每个 ShuffleMapTask 完成时会将 FileSegment 的存储位置信息汇报给 MapOutputTrackerMaster。 然后下个阶段, reducer 在 shuffle read 的时候是要去 driver 里面的 MapOutputTrackerMaster 询问 ShuffleMapTask 输出的数据位置的 |
| ShuffleManager | ShuffleManager负责帮助在 shuffle 过程中传递数据, getWriter和getReader是它的主要接口, 上一个阶段 task把数据 通过 writer 写出, 下一个阶段 task 通过 reader 读取数据, 目前官方默认使用的是 SortShuffleManager, 优势就是把所有临时文件 merge 成一个磁盘文件, 下一个stage 在拉取自己数据的时候, 只要根据元信息中的索引找到磁盘文件中属于自己的那部分数据 |
| BroadcastManager | BroadcastManager主要维护广播变量, BroadcastManager 负责维护广播变量的元信息, 底层存储也是使用的 BlockManger, 数据通过 nextBroadcastId 标识, broadcast 就是将数据从一个节点发送到其他各个节点上去。这样的场景很多,比如 driver 上有一张表,其他节点上运行的 task 需要 lookup 这张表,那么 driver 可以先把这张表 copy 到这些节点,这样 task 就可以在本地查表了, 目前默认使用的都是 TorrentBroadcast |
| NettyBlockTransferService | NettyBlockTransferService主要负责大文件在不同的 executor 中间进行传输, NettyBlockTransferService 自己是一个服务端,提供数据下载服务, 同时它也是Client,为本地其他模块暴露fetchBlocks的接口,支持通过host/port拉取任何Executor上的一组的Blocks。 |
| BlockManager | BlockManager 是一个分布式 key value 存储系统,BlockManager 对本地和远程提供一致的 get 和set 数据块接口, BlockManager 本身使用不同的存储方式来存储这些数据, 包括 memory, disk, off-heap。是 spark 中比较底层基础的公共服务组件 |
| SecurityManager | SecurityManager 主要负责 Spark对于认证授权的实现 |
| HttpFileServer | HttpFileServer可以提供HTTP服务的Server。当前主要用于Executor端下载jar 包, |
| MetricsSystem | MetricsSystem 指标系统, 俗话说, 没有指标监控的调优都是耍流氓, 只有对当前系统的运转情况一清二楚, 我们才能做到有的放矢, |
| MemoryManager | MemoryManager 是 spark 自己的内存管理器, spark 不仅使用堆内内存, 也使用堆外内存 ,缓存 RDD 和 广播数据 使用的是 Storage 内存, shuffle 的时候使用的 是 执行(Execution)内存, 1.6 之前使用的是静态内存管理 方式, 通过配置对内存空间进行分配,Spark 1.6 之后引入的统一内存管理机制,与静态内存管理的区别在于存储内存和执行内存共享同一块空间,可以动态占用对方的空闲区域 |
| OutputCommitCoordinator | OutputCommitCoordinator 是spark 结果输出的管理器, 输出的时候分为多个阶段, 比如结果输出到一个 hdfs 文件,第一个阶段 先写一个临时文件, 任务完成时,会调用canCommit方法来判断是否可以提交,如果可以提交, 就 rename 到目标文件名, 如果失败, 就回滚 把临时文件 remove 掉 |
我们可以使用一些参数对 driver 来进行控制, 注意这里的参数是控制 driver jvm 进程的,
spark.driver.blockManager.port 顾名思义, blockManager 在driver 启动时候使用的端口
spark.driver.host 运行 driver 的 host
spark.driver.port 运行 driver 的端口
spark.driver.memory driver jvm 使用内存的大小
spark.driver.cores driver jvm 使用的核数
spark.driver.extraLibraryPath driver jvm 启动时候 jar 包路径
spark.driver.extraJavaOptions+ driver jvm 启动时候 java 的 options
spark.driver.appUIAddress spark on yarn的时候才会使用, 按照 yarn 的协议, app master 要把 track 的地址汇报给 resourceManager, 用来监控。
