




etcd的基本概念
etcd是Google公司使用Go语言开发的开源、高可用的分布式key-value存储系统,可以用于配置共享和服务的注册和发现。具有以下属性:
完全复制:集群中的每个节点都可以使用完整的存档
高可用性:Etcd可用于避免硬件的单点故障或网络问题
一致性:每次读取都会返回跨多主机的最新写入
简单:包括一个定义良好、面向用户的API(gRPC)
快速:每秒10000次写入的基准速度
可靠:使用Raft算法实现强一致性、高可用服务存储目录
etcd在K8S架构中的定位
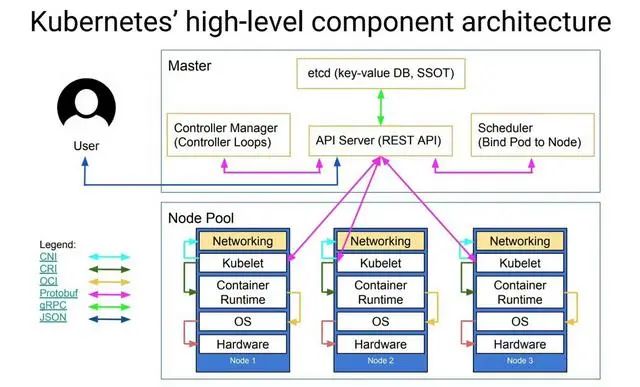
k8s所有的元数据都在etcd中进行存储,这里是最重要的,那接下来,我们就来进行etcd理论的最佳实践。
etcd 具备的优势
etcd运行时规划
etcd集群节点成员为奇数 etcd是一个以leader为基础的分布式系统 IO对于etcd集群的性能和稳定性都非常重要,保证资源的最优配置尤为重要。 etcd集群的稳定和流畅对于K8S集群正常运行不言而喻非常重要。一般情况下,我们需要单独部署etcd集群。 在版本选择上,一般建议是当前最新稳定版。
etcd配置文件参数的优化
时间
在大集群的etcd中,鉴于网络环境的复杂度,所以etcd本身的分布式共识协议,将会受到很大的影响,主要依赖于两个参数:
1.1 Heartbeat Interval。领导者将以此频率通知关注者它仍然是领导者。为了获得最佳实践,应围绕成员之间的往返时间设置参数。默认情况下,etcd 使用 100ms 心跳间隔。
1.2 Election Timeout。此超时时间是指跟随者节点在尝试成为领导者之前要等待多长时间而不会听到心跳信号。默认情况下,etcd 使用 1000ms 选举超时。
以上两个参数可以通过以下命令来进行调整:
$ etcd --heartbeat-interval=100 --election-timeout=500
# Environment variables:
$ ETCD_HEARTBEAT_INTERVAL=100 ETCD_ELECTION_TIMEOUT=500 etcd复制
快照
etcd 将所有关键更改追加到日志文件系统中。此日志将会一直增长,完整的历史记录适用于轻度使用的集群,但是频繁使用的集群将携带大量日志。
为了避免有大量日志,etcd 会进行定期快照。这些快照为 etcd 提供了一种通过保存系统当前状态并删除旧日志来压缩日志的方法。
使用 V2 后端创建快照可能会很昂贵,因此仅在对 etcd 进行给定数量的更改后才能创建快照。默认情况下,每 10000 次更改后将创建快照。如果 etcd 的内存使用量和磁盘使用量过高,请尝试通过在命令行上设置以下内容来降低快照阈值:
$ etcd --snapshot-count=5000
# Environment variables:
$ ETCD_SNAPSHOT_COUNT=5000 etcd复制
磁盘
etcd 集群对磁盘延迟非常敏感。由于 etcd 必须将建议持久保存到其日志中,因此其他进程的磁盘活动可能会导致较长的 fsync 延迟。etcd 可能会错过心跳,从而导致请求超时和临时领导者丢失。当给予较高的磁盘优先级时,etcd 服务器有时可以与这些进程一起稳定运行。
在 Linux 上,可以使用以下命令配置 etcd 的磁盘优先级 ionice:
$ sudo ionice -c2 -n0 -p `pgrep etcd`复制
网络 如果 etcd 领导者处理大量并发的客户端请求,由于网络拥塞,可能会延迟处理跟随者对等体请求。这表现为在跟随者节点上的发送缓冲区错误消息:
dropped MsgProp to 247ae21ff9436b2d since streamMsg's sending buffer is full
dropped MsgAppResp to 247ae21ff9436b2d since streamMsg's sending buffer is full复制
通过将 etcd 的对等流量优先于其客户端流量,可以解决这些错误。在 Linux 上,可以使用流量控制机制来确定对等流量的优先级:
tc qdisc add dev eth0 root handle 1: prio bands 3
tc filter add dev eth0 parent 1: protocol ip prio 1 u32 match ip sport 2380 0xffff flowid 1:1
tc filter add dev eth0 parent 1: protocol ip prio 1 u32 match ip dport 2380 0xffff flowid 1:1
tc filter add dev eth0 parent 1: protocol ip prio 2 u32 match ip sport 2379 0xffff flowid 1:1
tc filter add dev eth0 parent 1: protocol ip prio 2 u32 match ip dport 2379 0xffff flowid 1:1复制
内存
etcd 默认的存储大小限制为 2GB,可使用--quota-backend-bytes 标志进行配置。建议在正常环境下使用 8GB 的最大大小,如果配置的值超过该值,etcd 会在启动时发出警告。请求体
etcd 被设计用于元数据的小键值对的处理。较大的请求将工作的同时,可能会增加其他请求的延迟。默认情况下,任何请求的最大大小为 1.5 MiB。这个限制可以通过--max-request-bytesetcd 服务器的标志来配置。key 的历史记录压缩 ETCD 会存储多版本数据,随着写入的主键增加,历史版本将会越来越多,并且 ETCD 默认不会自动清理历史数据。数据达到 --quota-backend-bytes 设置的配额值时就无法写入数据,必须要压缩并清理历史数据才能继续写入。
--auto-compaction-mode
--auto-compaction-retention复制
所以,为了避免配额空间耗尽的问题,在创建集群时候建议默认开启历史版本清理 功能。
3.3.0 之前的版本,只能按周期 periodic 来压缩。比如设置 --auto-compaction-retention=72h,那么就会每 72 小时进行一次数据压缩。
3.3.0 之后的版本,可以通过 --auto-compaction-mode 设置压缩模式,可以选择 revision 或者 periodic 来压缩数据,默认为 periodic。
etcd集群数据的备份
所有Kubernetes资源对象都存储在etcd数据库上,所以定期备份etcd集群的数据对于在灾难场景下,恢复Kubernetes集群至关重要。快照文件包含了所有Kubernetes状态和关键的元数据信息。为了保证敏感的Kubernetes数据的安全,可以对快照文件进行加密。备份etcd集群可以通过两种方式完成: 自身的内置快照和卷快照。
内置快照
etcd 支持内置快照,因此备份 etcd 集群很容易。快照可以从使用 etcdctl snapshot save 命令的活动成员中获取,也可以通过从 etcd 数据目录复制 member/snap/db 文件,该 etcd 数据目录目前没有被 etcd 进程使用。获取快照通常不会影响成员的性能。
下面通过一个示例,用于获取 $ENDPOINT 所提供的键空间的快照到文件 snapshotdb:
ETCDCTL_API=3 etcdctl --endpoints $ENDPOINT snapshot save snapshotdb
# exit 0
# verify the snapshot
ETCDCTL_API=3 etcdctl --write-out=table snapshot status snapshotdb
+----------+----------+------------+------------+
| HASH | REVISION | TOTAL KEYS | TOTAL SIZE |
+----------+----------+------------+------------+
| fe01cf57 | 10 | 7 | 2.1 MB |
+----------+----------+------------+------------+复制
卷快照
如果 etcd 运行在支持备份的存储卷(如 Amazon Elastic Block 存储)上,则可以通过获取存储卷的快照来备份 etcd 数据。
etcd集群数据恢复还原
etcd支持从major.minor或其他不同补丁版本的etcd进程中获取的快照,用来进行恢复操作。恢复操作常用于恢复失败情况下集群的数据。
在启动恢复还原操作之前,我们得必须有一个snapshot快照文件。这个文件可以是历史备份操作的快照文件,也可以是当前剩余数据目录的快照文件。
如果还原的集群的访问地址与之前的集群不同,那么需要相应地重新配置 Kubernetes API 服务器。在我们的这个例子中,可使用选项--etcd-servers=$NEW_ETCD_CLUSTER
而不是这个选项--etcd-servers=$OLD_ETCD_CLUSTER
来重新启动Kubernetes api的服务。使用相应的IP地址替换$NEW_ETCD_CLUSTER
以及 $OLD_ETCD_CLUSTER
。如果在etcd集群使用了负载均衡策略,那需要更新为负载均衡的连接地址。
如果多数etcd集群的成员出现失败情况,那么etcd集群是不可用的。在这种情况下,Kubernetes不能对其当前状态进行任何更改。虽然已调度的pod可能可以继续正常运行,但是新的pod则无法进行调度,所以这样我们恢复etcd 集群并可能需要重新配置Kubernetes API服务来修复出现的异常。
注意:如果集群中正在运行任何Kubernetes api服务,那么不能强制还原 etcd集群的数据,而是按照以下方式来进行etcd集群数据的恢复还原:
stop掉所有kube-apiserver的服务 将集群中所有的etcd服务节点都恢复让其正常运行,然后加入到集群 restart 所有的kube-apiserver服务
当然,我还是建议大家重启所有组件,包括kube-scheduler、kube-controller-manager、kubelet这些组件,从而确保它们不会依赖一些过时的缓存或者其他数据。其实,在实际的还原过程中会耗费一定的时间,还有就是在恢复过程中,其他关键的组件将丢失leader锁并自行restart。
概括
etcd是kubernetes的存储基础,想用好kubernetes,需要更深入的去了解和使用etcd,才有能力以及知识储备,让跑在kubernetes上的服务,保障它们更稳定更安全的持续运行。
👇👇👇点击关注,更多内容持续更新...

