




"飞驰的列车缩短了你我的距离,优美的风景伴随我们一路同行,欢迎乘坐。。。",刚攒了一天年假就被用掉了,凑了凑休个小假期,鸽是不可能鸽的,趁着坐车有段时间赶紧更了,省着周末就没空打脸 早上差点没赶上车,好久没这么极限了,下了地铁还剩10min开车,一路疾跑加闪现,真是一分钟也没浪费。转眼间又开学了,鸳都一别竟有二七,春风秋月杨柳依依。毕业后愈发怀念那些逃课去实验室看似慌中带急实则稳重带皮的日子,一年前做老师承接的项目时遇到一条sql查询很慢,甲方大哥说不行啊,得优化啊,当时感觉sql优化离我们非常遥远。从网上搜了搜执行了下面一句sql,其实也没执行sql就是在客户端点点点。。
早上差点没赶上车,好久没这么极限了,下了地铁还剩10min开车,一路疾跑加闪现,真是一分钟也没浪费。转眼间又开学了,鸳都一别竟有二七,春风秋月杨柳依依。毕业后愈发怀念那些逃课去实验室看似慌中带急实则稳重带皮的日子,一年前做老师承接的项目时遇到一条sql查询很慢,甲方大哥说不行啊,得优化啊,当时感觉sql优化离我们非常遥远。从网上搜了搜执行了下面一句sql,其实也没执行sql就是在客户端点点点。。
ALTER TABLE `table_name` ADD INDEX index_name (`column`)复制
快是快了,为啥快不知道,网上这么说的我们就这么干,
今天就整理一下索引是啥,为啥能加速查询。简单说,索引就是索引的出现其实就是为了提高数据查询的效率,就像新华词典的目录一样。这么厚的词典,你要想快速找到其中的某个字,在不借助目录的情况下,需要找老一会,数据越多相当于词典越厚找的越慢,所以,对于数据库的表而言,索引其实就是查找时的“目录”。
常见的索引模型
目录总得有个结构,可能是线性的,也可能是树形的。
hash索引:hash索引还是很好理解的,毕竟都用过HashMap,以键-值(key-value)存储数据的结构,我们只要输入待查找的值即key,就可以找到其对应的值即Value。哈希的思路很简单,把值放在数组里,用一个哈希函数把key换算成一个确定的位置,然后把value放在数组的这个位置。那hash碰撞了怎么办,那就采用拉链法,在后面维护一个链表,然后遍历链表找到正确的对应的值。等值查询的时候看起来好像没有啥毛病,那范围查询怎么办呢,那就得全部扫描一遍了。所以一般运用在Memcached等Nosql数据库引擎
二叉搜索树:它来了,它还是来了,想我上城大一当年金戈铁马南征北战,看谁都比我菜。打完比赛让数据结构捶到自闭,怀疑自己是智障。

回学校半个月不想碰键盘。导致我现在还有阴影,不过数据结构该学还是要学,二叉树算是比较简单的基础结构了。二叉树的特点很明显,每个节点的左儿子小于父节点,父节点又小于右儿子。这样如果你要查某个数据不是走左边就是走右面,这个时间复杂度就是logn,为了维持logn的查找就要保证这是棵平衡二叉树,那更新的时候也是先查找对应的位置,复杂度也是logn。那问题就来了,数据越多这棵树的高度就越高,高起来看着都费劲别说找了,假如表中有100w数据,用二叉树做模型,树高20(2^20=1048576),每层树都是一个数据库,每次往下找都会花费一次io时间,在机械硬盘时代,从磁盘随机读一个数据块需要10 ms左右的寻址时间。也就是说,单独访问一个行可能需要20个10 ms。既然二叉不够那就N叉树呗。
Innodb索引模型
innodb中采用B+树作为索引模型,每一个索引都对应着一刻B+树,至于B+树的结构就不讲了,我也是看了很久才整明白。假设有一句建表语句
create table T(id int primary key,k int not null,name varchar(16),index (k))engine=InnoDB;复制
id作为主键索引创建一棵树,k字段作为普通索引创建一棵树,插入表数据R1~R5(ID,k)值分别为(100,1)、(200,2)、(300,3)、(500,5)和(600,6),那么主键索引和普通索引的结构就不一样了。
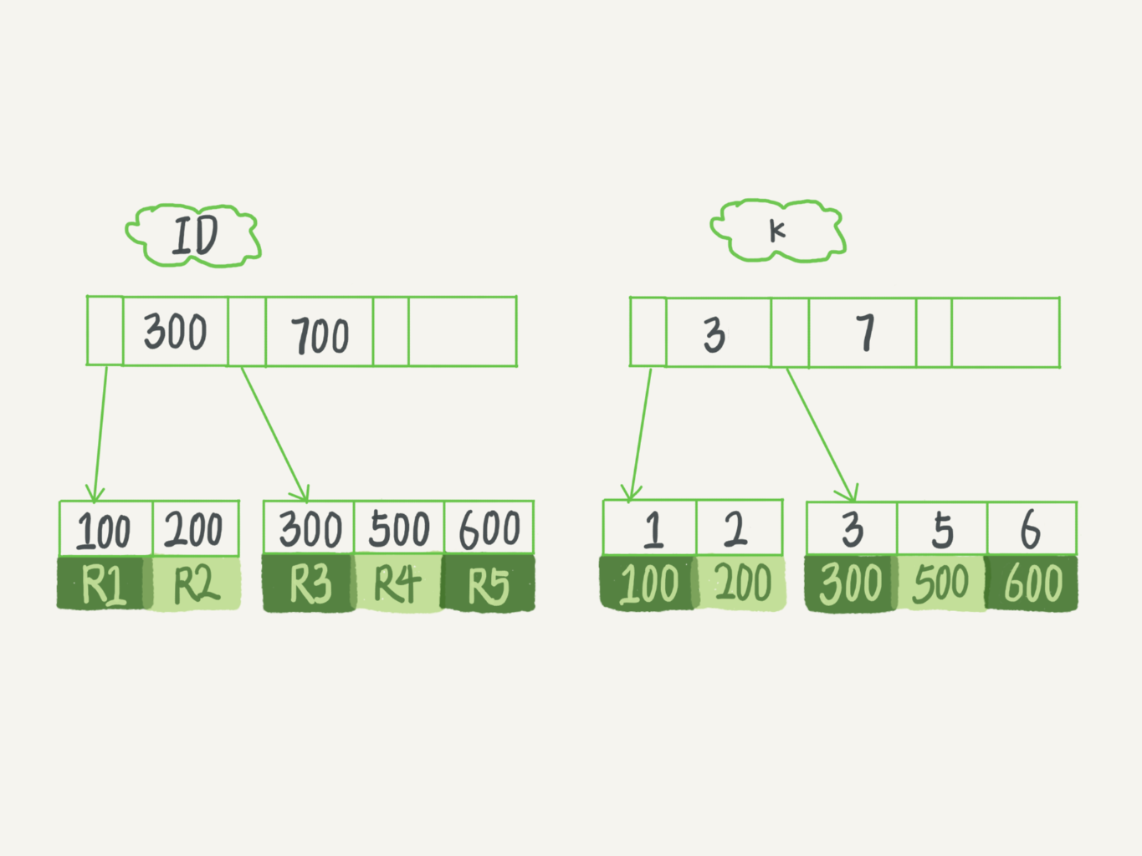
怎么说,主键索引的叶子节点里存的是整行的数据,而普通索引的叶子节点存的是主键。也就是说你用主键索引查询直接就拿到了数据,而用普通索引还需要拿到主键再到主键的树里重新查一遍,这个操作就叫做回表。像数据与索引存储在一块的就叫聚簇索引,反之就是非聚簇索引
索引维护:
B+树为了维护索引有序性,在插入新值的时候需要做必要的维护。以上面这个图为例,如果插入新的行ID值为700,则只需要在R5的记录后面插入一个新记录。如果新插入的ID值为400,需要逻辑上挪动后面的数据,空出位置。
如果R5所在的数据页已经满了,这时候需要申请一个新的数据页,然后挪动部分数据过去。这个过程称为页分裂。在这种情况下,性能自然会受影响。
除了性能外,页分裂操作还影响数据页的利用率。原本放在一个页的数据,现在分到两个页中,整体空间利用率降低大约50%。
当然有分裂就有合并。当相邻两个页由于删除了数据,利用率很低之后,会将数据页做合并。
好了,先说到这里吧,从北京南一路写到济南东,不写了收拾收拾准备开始度假。
