




(十)正则函数
使用正则表达式的内置函数叫做正则函数。在讲解正则函数之前需要熟悉正则表达式。
0、正则表达式
- 正则的功能
(1) 校验数据有效性
(2) 查找符合要求的文本内容
(3) 对文本进行切割,替换等操作 - 元字符的概念
(1) 正则表达式是由一系列元字符组成的匹配字串;
(2) 元字符是正则表达式中具有特殊意义的专用字符;
(3) 构成正则表达式的基本元件。 - 元字符的构成
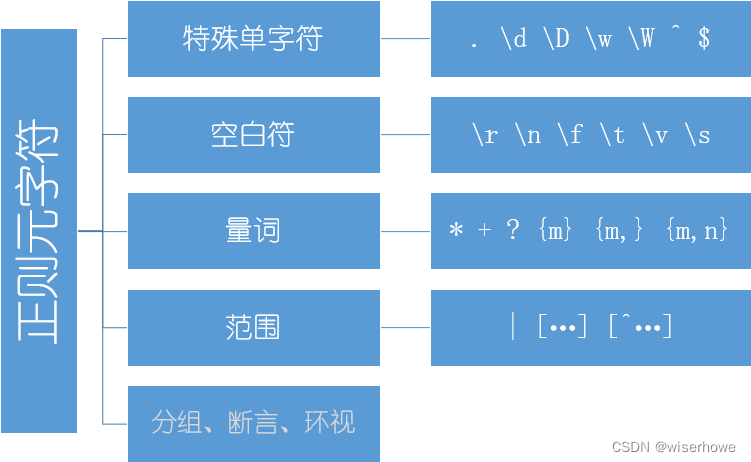
(1) 特殊单字符
| 字符 | 描述 |
|---|---|
| . | 匹配除 “\n” 之外的任何单个字符。要匹配包括 ‘\n’ 在内的任何字符,请使用象 ‘[.\n]’ 的模式。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \w | 匹配包括下划线的任何单词字符。等价于’[A-Za-z0-9_]’。 |
| \W | 匹配任何非单词字符。等价于 ‘[^A-Za-z0-9_]’。 将下一个字符标记为一个特殊字符、或一个原义字符、或一个 后向引用、或一个八进制转义符。例如,‘n’ 匹配字符 “n”。’\n’ 匹配一个换行符。序列 ‘\’ 匹配 “” |
| ^ | 匹配输入字符串的开始位置。 |
| $ | 匹配输入字符串的结束位置。 |
(2) 空白符
| 字符 | 描述 |
|---|---|
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘er\b’ 可以匹配"never" 中的 ‘er’,但不能匹配 “verb” 中的 ‘er’。 |
| \B | 匹配非单词边界。‘er\B’ 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
(3) 量词
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。 * 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,‘zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,“do(es)?” 可以匹配 “do” 或 “does” 中的"do" 。? 等价于 {0,1}。 |
| {n} | n 是自然数。匹配确定的 n 次。例如,‘o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o。 |
| {n,} | n 是自然数。至少匹配n 次。例如,‘o{2,}’ 不能匹配 “Bob” 中的 ‘o’,但能匹配 “foooood” 中的所有 o。‘o{1,}’ 等价于 ‘o+’。‘o{0,}’ 则等价于 ‘o*’。 |
| {n,m} | m 和 n 均为自然数,n <= m。最少匹配 n 次且最多匹配 m 次。刘, “o{1,3}” 将匹配 “fooooood” 中的前三个 o。‘o{0,1}’ 等价于 ‘o?’。请注意在逗号和两个数之间不能有空格。 |
(4) 范围
| 字符 | 描述 |
|---|---|
| | | 表示“或”的关系。比如 (http?|ftp):\/\/ |
| [a-z] | 表示匹配 26 个小写字母之一 |
| [^a-z] | 取反,匹配 26 个小写字母之外的某个字符 |
1、REGEXP_LIKE (source_char, pattern [, match_paramater])
功能:正则匹配,使用正则表达式匹配源字符串。
| 参数 | 说明 |
|---|---|
| source_char | 源字符串。该参数支持的数据类型与replace函数的src参数一致。 |
| pattern | 正则表达式。仅支持字符串,最多可包含512个字节 |
| match_paramater | i:大小写不敏感; c:大小写敏感; n:点号(.)匹配换行符号; m:多行模式; x:扩展模式,忽略正则表达式中的空白字符 |
- REGEXP_LIKE 练习
测试表 test_reg 的数据
| id | value |
|---|---|
| 1 | 1234560 |
| 2 | I can swim |
| 3 | 1b3b560 |
| 4 | abc |
| 5 | abcde |
| 6 | ADREasx |
| 7 | 123 45 |
| 8 | adc de |
| 9 | adc,.de |
| 10 | 1B |
| 10 | abcbvbnb |
| 11 | 11114560 |
| 11 | 11124560 |
(1) 查询value中以1开头60结束的记录并且长度是7位
select * from test_reg where value like '1____60'; # 使用 like,结果是正确的。每个“_”表示一个字符。
select * from test_reg where regexp_like(value,'1.{4}60'); # 贪婪模式造成多匹配出两个记录。贪婪模式是最大长度匹配,只要1到60之间找到4个字符,即为匹配。
select * from test_reg where regexp_like(value,'^1.{4}60$'); # 这是符合需求的最精确的正则。非贪婪模式,1到60之间存在且只有4个字符,才能匹配。“^”表示匹配开始,“$”表示匹配结束。
复制(2) 查询value中以1开头60结束的记录并且长度是7位并且全部是数字的记录;
select * from test_reg where regexp_like(value,'^1[0-9]{4}60$');
select * from test_reg where regexp_like(value,'^1[\\d]{4}60$'); # \d 匹配一个数字字符
select * from test_reg where regexp_like(value,'^1[[:digit:]]{4}60$');-- 也可以使用字符集
复制(3) 查询value中不是纯数字的记录
select * from test_reg where not regexp_like(value,'^[[:digit:]]+$');
# “[[:digit:]]” 是 PHP 正则表达式的通用字符簇,表示任何数字
复制(4) 查询value中不包含任何数字的记录
select * from test_reg where regexp_like(value,'^[^[:digit:]]+$');
# “[[:digit:]]” 是 PHP 正则表达式的通用字符簇,表示任何数字。该表达式匹配到不存在数字的源字串
复制(5) 查询以12或者1b开头的记录.不区分大小写
select * from test_reg where regexp_like(value,'^1[2b]','i'); # 不区分大小写
/*
id value
1 1234560
3 1b3b560
7 123 45
10 1B
*/
复制(6) 查询以12或者1b开头的记录.区分大小写
select * from test_reg where regexp_like(value,'^1[2B]');
/*
id value
1 1234560
7 123 45
10 1B
*/
复制(7) 查询数据中包含空白的记录
select * from test_reg where regexp_like(value,'[[:space:]]');
# “[[:space:]]” 是 PHP 正则表达式的通用字符簇,表示任意空白字符(空格、制表符、回车、换行)
复制(8) 查询所有包含小写字母或者数字的记录
select * from test_reg where regexp_like(value,'^([a-z]+|[0-9]+)$');
# 注意 “[a-z]+” 和 “[0-9]+” 之间 有 “|” 表示或的关系
复制(9) 查询任何包含标点符号的记录
select * from test_reg where regexp_like(value,'[[:punct:]]');
# “[[:punct:]]” 是 PHP 正则表达式的通用字符簇,表示任何标点符号
复制2、REGEXP_REPLACE (source_char,pattern[,replace_string[,position [,occurrence[match_option]]]])
功能:正则替换,用指定的字符串替换源字符串中与指定正则表达式相匹配的字符串。
| 参数 | 说明 |
|---|---|
| source_char | 源字符串。该参数支持的数据类型与replace函数的src参数一致。 |
| pattern | 正则表达式。每个正则表达式最多可包含512个字节。 |
| replace_string | 替换字符串。替换字符串可以包含反向引用的数字表达式(\n,n的取值范围是[1,9]) |
| position | 开始匹配的位置,如果不指定默认为1,即从source_char的第一个字符开始匹配。position 为一个正整数。 |
| occurrence | 正则匹配的序数。是一个非负的整数,默认值为0。0,表示替换所有匹配到的出现;正整数,替换第n次匹配到的出现; |
| match_paramater | c:大小写敏感;n:点号(.)不匹配换行符号;m:多行模式;x:扩展模式,忽略正则表达式中的空白字符。 |
- REGEXP_REPLACE 练习
# 1、替换数字为字母 Q
select value, REGEXP_REPLACE (value,'[0-9]+','Q') AS Result from test_reg
# 2、替换第三个单词为 READ
#update test_reg set value='I can swim' where id=2
select value, REGEXP_REPLACE(value,'\\w+','READ', 1, 3) Result
from test_reg
where id=2
复制3、REGEXP_INSTR (source_char,pattern[,position[,occurrence[,return_opt[,match_parameter[,subexpr]]]]])
功能:正则搜索,获得匹配字符串的位置。
| 参数 | 说明 |
|---|---|
| source_char | 源字符串。该参数支持的数据类型与replace函数的src参数一致。 |
| pattern | 正则表达式。仅支持字符串,每个正则表达式最多可包含512个字节。 |
| position | 开始匹配的位置。默认值为1,即从source_char的第一个字符开始匹配。 |
| occurrence | 正则匹配的序数。正整数,默认值为1,找到第N次匹配到的出现。 |
| return_opt | 返回值的类型,非负整数默认值为0。0,返回值为匹配位置的第一个字符的位置。n,返回匹配的字符串后紧跟着的第一个字符的位置。match_paramater |
| subexpr | 对于含有子表达式的正则表达式,表示正则表达式中的第几个子串是函数目标。该参数值域范围是0~9,超过9,函数返回0。默认为0。0,返回与正则表达式匹配的字符的位置,全匹配上返回1,不匹配返回0;大于0,返回指定的子串的位置。该值大于子串个数时,返回0;源字符串中有括号时,按照正则支持的转义处理。 |
subexpr 参数不常用,本文不在赘述。
- REGEXP_INSTR 练习
# 1、搜索数字第一次出现的位置
select value, REGEXP_INSTR (value,'[0-9]+') AS Result from test_reg
# 2、找数字(从第一个字母开始匹配,找第1个匹配项目的紧跟着的第一个字符的位置)
select value, REGEXP_INSTR (value,'[0-9]+', 1, 1, 1) AS Result from test_reg
# position=1 表示从 value 字符串的第一个位置开始搜索;occurrence=1 表示找到第一次出现的位置;return_opt=1 表示匹配字符的下一个位置
# 3、找到第三个单词的位置
select value, REGEXP_INSTR(value,'\\w+', 1, 3) Result
from test_reg
where id=2
复制4、REGEXP_SUBSTR (source_char,pattern[,position[,occurrence]])
功能:获得匹配到的字符串。
| 参数 | 说明 |
|---|---|
| source_char | 源字符串。该参数支持的数据类型与replace函数的src参数一致。 |
| pattern | 正则表达式。仅支持字符串,每个正则表达式最多可包含512个字节。 |
| position | 开始匹配的位置。默认值为1,即从source_char的第一个字符开始匹配。 |
| occurrence | 正则匹配的序数。正整数,默认值为1,找到第N次匹配到的出现。 |
- REGEXP_SUBSTR 练习
# 1、搜索第一次出现的数字
select value, REGEXP_SUBSTR (value,'[0-9]+') AS Result from test_reg
# 2、找到第三个单词的内容
select value, REGEXP_SUBSTR(value,'\\w+', 1, 3) Result
from test_reg
where id=2
复制(十一)信息函数
1、Database():返回当前数据库名字,比如
courseware复制
2、User():返回当前用户名,比如
root@127.0.0.1复制
3、Version():返回当前系统版本,比如
9.5.2.39.126761复制
4、CHARSET(<字符串>):返回字符串参数使用的字符集
| 函数调用 | 返回值 |
|---|---|
| charset(‘南大通用’) | utf8 |
(十二)函数与性能
1、函数不要用在字段上:
【优化前】select Sid, Sname, Sage from Student
where to_char(Sage,‘YYYY’) >= 2013;
【优化后】select Sid, Sname, Sage from Student
where Sage >= ‘2013-01-01’;
小贴士:函数使用在字段上,每一行字段数据都会执行函数,智能索引失效;函数使用在值上,则只执行一次,还能利用智能索引。
2、避免使用无必要的转换函数:
【优化前】select Sid, Sname, Sage from Student
where Sage >= to_date(‘2010-08-06’, ‘YYYY-MM-DD’);
【优化后】select Sid, Sname, Sage from Student
where Sage >= ‘2010-08-06’;
小贴士:WHERE 子句中,表达式的比对数值能用隐式转换就不使用数据类型转换函数。
3、超大数据量不能使用 NOT EXISTS:
【优化前】select * from Student where NOT EXISTS(select 1 from
score where SId=Student.SId)
【优化后】select * from Student where SId not in(select SId from score where SId is not null)
小贴士:需要量表关联,但是关联表字段不同值很少,表数据量较大,NOT EXISTS 会导致产生大量临时文件。改成 not in 后效率会有较大提高,但是需要加上关联字段不为空的条件。
4、巧用 COUNT( DISTINCT):
【优化前】select count(DISTINCT CId),count(DISTINCT TId) from course;
【优化后】select * from(select count(DISTINCT CId) from course)T1
join (select count(DISTINCT TId) from course)T2;
小贴士:对多列去重计数,当前执行计划先在各节点对参与 count(distinct) 的列进行分组去重,结果再汇总到一个节点进行 count(distinct) 运算。当 count(distinct) 列很多时,参与 group by 运算的列也很多,去重效果不理想,导致大量数据要拉到一个节点进行 count(distinct) 运算,拉表和汇总计算耗时非常长。优化的方法是各列分别计算 count(distinct),提高去重效果,然后对结果集进行拼接。
5、简单的模糊匹配不要使用正则匹配函数:
【优化前】select * from test_reg where REGEXP_LIKE(value, ‘^1.{4}60$’);
【优化后】select * from test_reg where value LIKE ‘1____60’
小贴士:正则匹配函数应用场景是复杂的模糊匹配,功能强大的同时,资源耗费肯定高于原生的 LIKE。



