




随着LLM基座的不断成熟和生态的不断完善,越来越多的企业开始在自身业务场景的应用探索,以实现降本增效。然而,在这一过程中,企业不得不面对两种AI应用形态的选择:
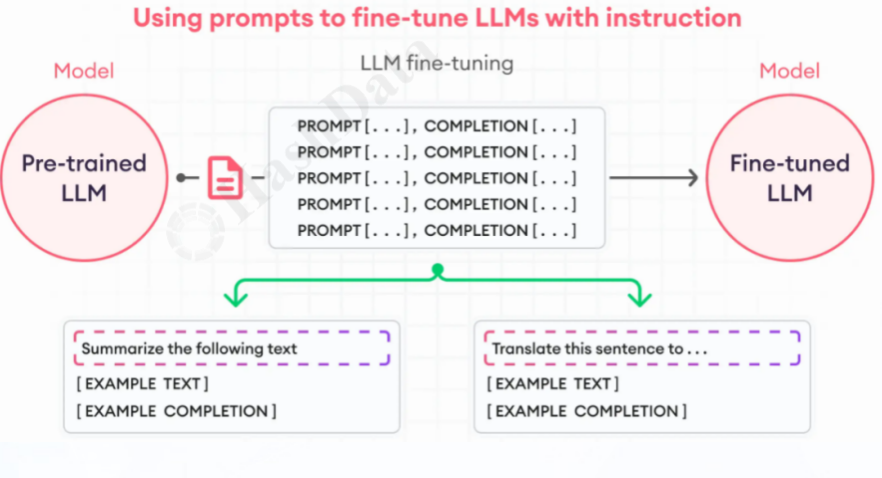
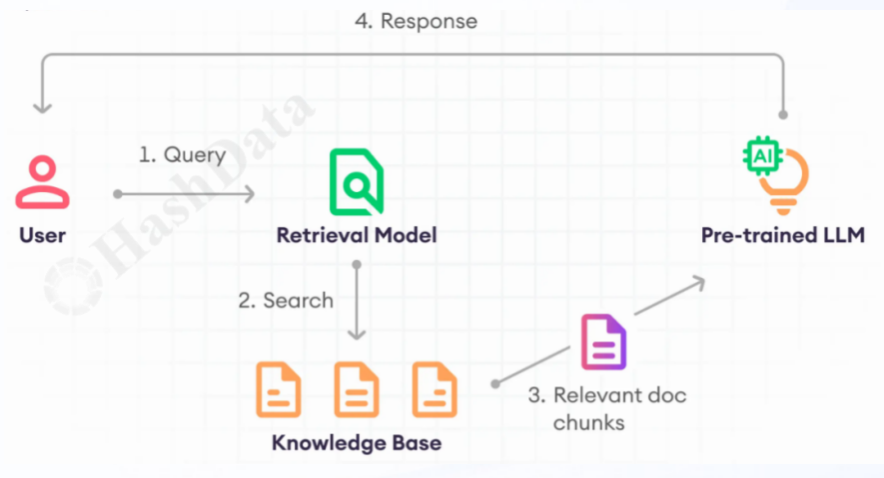
图1.大模型微调方式
图2.RAG知识增强方式
一种应用方式是基于大模型微调。这种方式需要将预先训练好的基座大模型,结合场景语料进行微调,从而获得具备行业知识的垂类模型应用。微调过程是精细而复杂的工作,不仅需要在保证语料质量的基础上进行梳理编排,而且还需要定期针对更新的语料重新进行模型微调训练。只有这样,微调后模型才会有更好的性能和泛化能力,从而提供更加准确和高效的推理结果。 另一种应用方式是通过RAG(检索增强生成)方式,在大模型基础上建立行业知识库。这种方式可以弥补大模型在特定行业知识方面的不足。知识库的建设同样需要精心准备和规范化的管理,确保知识的正确性和规范性。只有这样,大模型进行检索时才能获得准确、相关的知识提示,从而引导大模型生成更符合需求的答案。
无论是基于微调还是RAG方式的AI应用,企业都需要建立完善的语料数据管理系统,为大模型微调训练提供高质量的语料输入,为RAG提供高质量知识库支持。由此,催生了企业对非结构化多模态语料数据管理的迫切诉求。
非结构化数据管理流程及技术挑战

然而,非结构化多模态语料数据不仅类型多样,而且体量巨大,给传统的数据处理方式带来了前所未有的挑战。
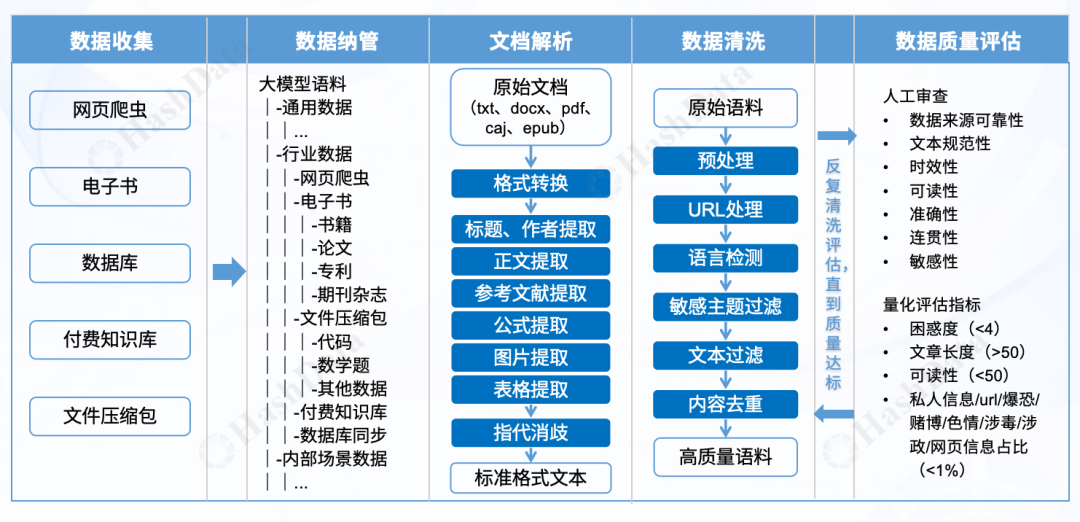
数据收集:这是整个流程的起点,涉及从各种来源获取数据。这些数据可能来自网络、第三方电子书库、企业内部数据库、外部购买的知识库、同行业分享的文件等。这些数据格式各异,包括文本、图像、音频、视频等。 数据纳管:收集到的数据需要被统一管理,并建立一个清晰的资产目录,以确保数据的可访问性和可维护性。随着模型训练的不断迭代,语料数据会不断增加,因此需要一个统一的维度来管理这些数据,以确保其质量和精选性。
文档解析:对收集到的文档进行解析,提取出关键信息,这些信息将被整合成一个标准格式的文档,便于后续处理和分析。
数据清洗:清洗过程旨在去除原始语料中的噪声和无关信息,包括去重、处理空格、非法字符、URL替换、语言类型检测以及敏感数据的过滤等,以确保数据的唯一性和准确性。
数据质量评估:在将清洗后的语料用于模型训练之前,需要对其进行质量评估。这可以从人工审查和量化评估指标两个维度进行。只有当数据在各个指标上表现良好时,才能被用于模型训练。
HashData湖仓一体思考
在这样的背景下,HashData湖仓一体架构提出了新的思考。
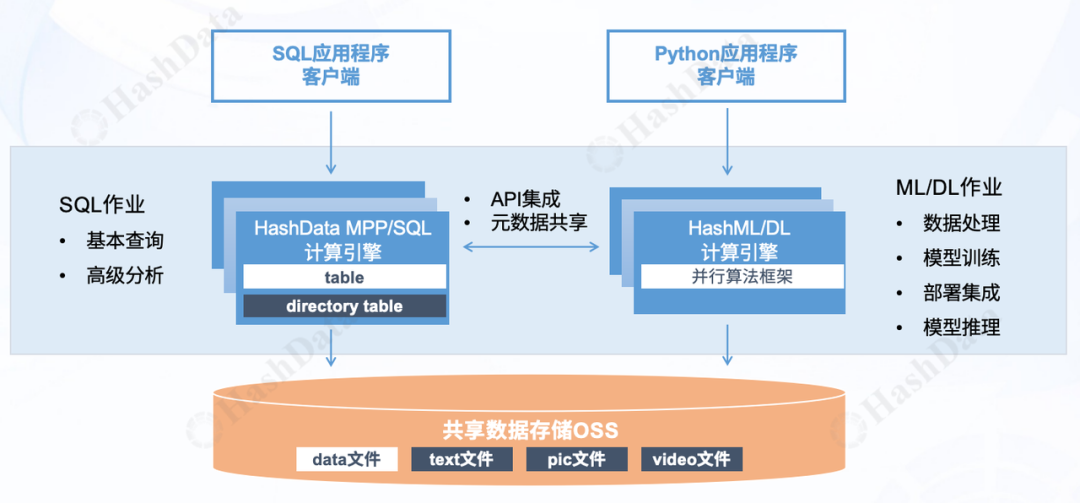
如上图所示,HashData湖仓一体架构主要由两大引擎组成:一是用于提供分析能力的HashData SQL数据库引擎,二是具备深度学习和机器学习能力HashML/DL算法引擎。这两大引擎共享一套数据湖对象存储OSS层,这个数据层可以实现结构化数据和非结构化数据的统一存储管理。
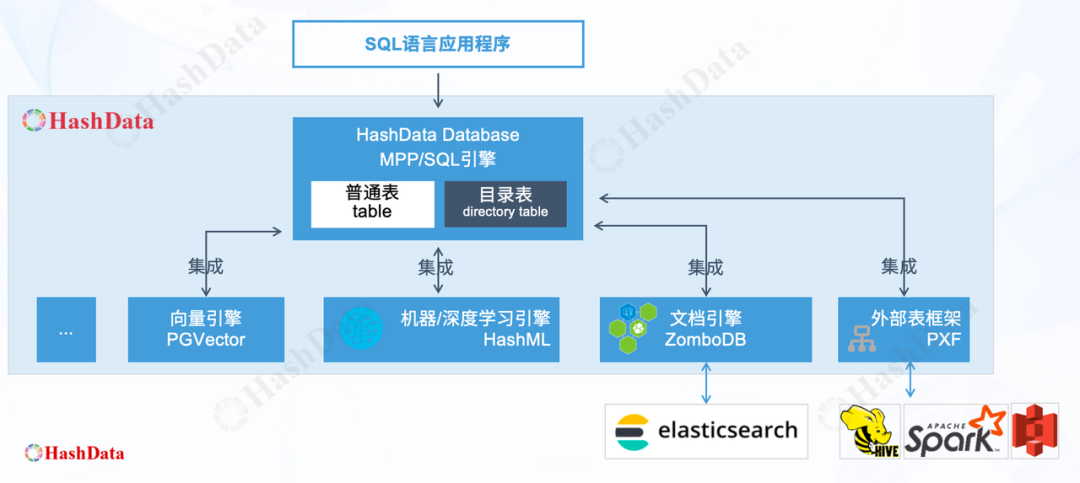
然而,仅仅将非结构化数据纳管进来并不够,我们还需要对其进行清洗、解析和加工,以生成高质量的训练语料。为了实现这一目标,HashData SQL数据库引擎整合了多种外部引擎插件,包括向量引擎、机器/深度学习引擎HashML和文档引擎等等。
向量引擎:在大模型的应用方式中,RAG知识增强方式便充分利用了向量库。因此,在清洗完目录表中的非结构化文档数据后,我们可以直接将其导入向量引擎,为AI应用提供丰富的知识库支持。
HashML机器/深度学习引擎:具备多种强大的算法模型,能够迅速解析非结构化文档,并执行语料的清洗工作。
文档引擎:针对文档内容关键词检索的需求,我们集成了ZomboDB引擎,将索引数据存储在其中。同时,具体的文档数据则存储在elasticsearch平台上。这样,用户只需采用简单的SQL语言就能使用文档引擎基于关键词轻松检索文档内容。检索结果可进一步用于机器学习算法处理,从而丰富非结构化数据处理能力。
Directory Table定位
在深入探讨Directory Table的定位之前,我们首先需要理解它在整个HashData SQL数据库引擎架构中的角色和与其他组件的关系。
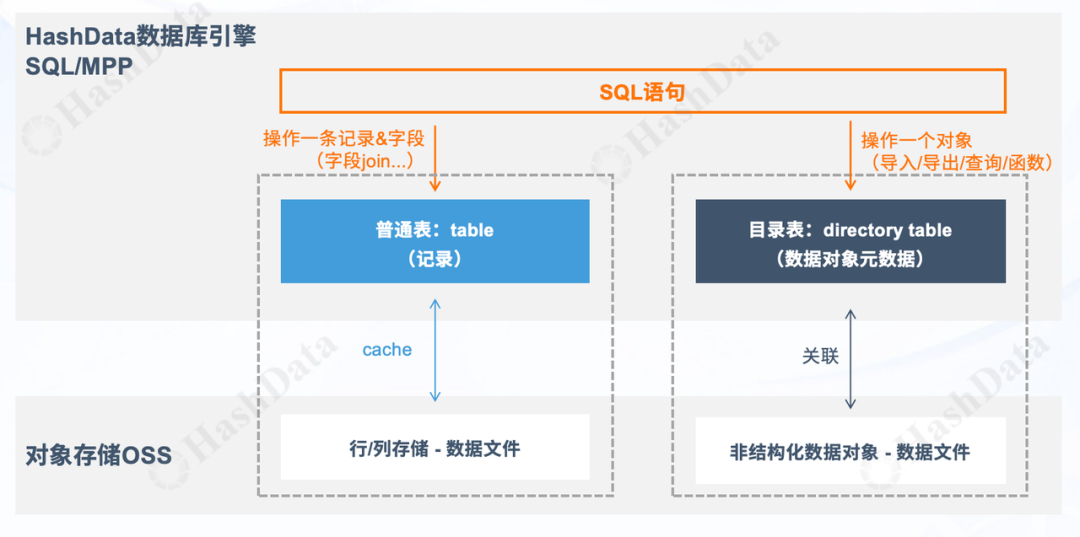
在HashData SQL数据库引擎中,原本包含Table普通表,属于记录表。这种记录表的实际数据是以行/列或者行列混合的方式作为数据文件存储在对象存储OSS层中。数据文件与Table普通表之间是cache关系,也就是一对一的关系。这种存储方式确保了数据的一致性和高效访问。然而,随着非结构化数据的快速增长,我们需要一种新的方法来有效管理和分析这些数据。这就是Directory Table的用武之地。
与普通表不同,Directory Table被设计为存储和管理非结构化数据对象的元数据。这些元数据以结构化的形式存在,与非结构化数据文件本身形成关联关系,而非一一对应的cache关系。这种设计使得我们能够用结构化的方式来描述和查询非结构化数据,从而提高了数据管理的灵活性和效率。
在实现上,HashData SQL数据库引擎在SQL层面进行了统一,让用户可以使用熟悉的SQL语句来操作Directory Table和Table普通表。无论是创建表、导入数据、导出数据还是执行查询,都可以通过SQL语句来完成。这种统一的操作方式降低了用户的学习成本,同时提高了系统的易用性。
Directory Table最佳实践
如何使用这个Directory Table表呢?
其中,需要重点介绍Directory Table的表定义、表数据导入和表数据查询三个部分:
🚩Directory Table使用:表定义
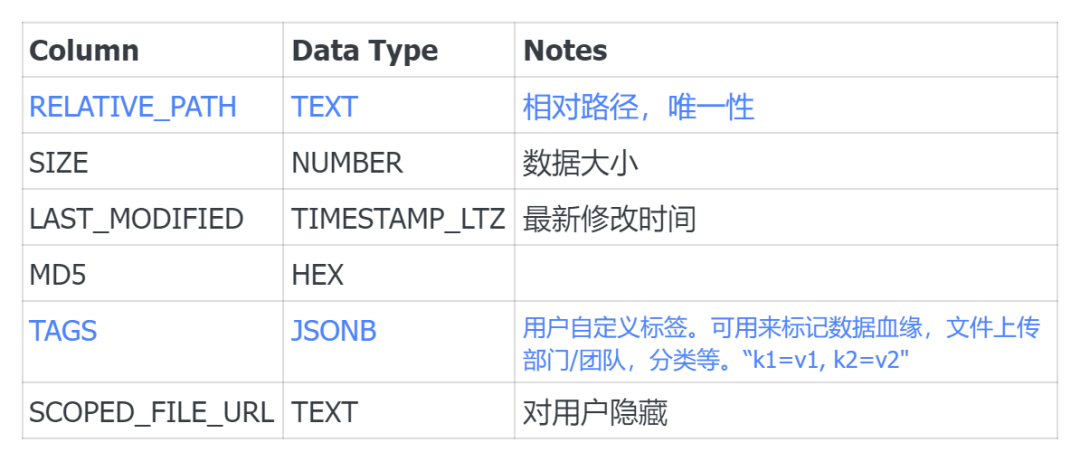
Directory Table定义了一个表结构,用于存储非结构化数据文件的元数据信息,包含以下字段:
RELATIVE_PATH:路径字段,具有唯一性。在数据导入时生成,可以作为数据的唯一标识符使用。通过这个字段,我们可以大致了解语料的来源;
SIZE:表示语料数据的大小;
LAST_MODIFIED:记录语料数据的最后修改时间;
MD5:生成一个唯一的MD5码,用于校验。当语料数据重复加载时,通过MD5码进行校验,确保数据的准确性;
TAGS:标签字段,当面对海量语料数据时,通常通过标签来管理和检索数据。标签支持KV(键值对)方式存储,上传时可以自定义;
SCOPED_FILE_URL:隐藏字段,用于内部处理。
针对这个表结构定义,我们在HashData SQL数据库引擎中构建对应的存储空间。由于语料数据存储在对象存储OSS上,我们在创建存储空间(表空间)时,会将其关联到对象存储上。有了这个表空间之后,我们就可以创建目录表,并将存储的对象数据默认放置在对象存储的表空间上。
首先创建一个自定义表空间,并指定其位置和服务器:
CREATE TableSPACE <Tablespace_name>LOCATION '<对象存储OSS Tablespace_path>'WITH ( [SERVER = <server_name>] );复制
然后在自定义表空间中创建目录表:
CREATE DIRECTORY Table <Table_name>TableSPACE <Tablespace_name>;复制
这样,我们就成功创建了一个用于存储非结构化数据文件的元数据信息的目录表,并将其数据对象文件存储在HashData对象存储OSS中。
🚩Directory Table使用:表数据导入
Directory Table支持从本地导入数据,用户可以将文件从本地路径导入至表中。此外,系统支持使用Wildcard进行批量上传,大大提高了导入效率。为保持数据文件的组织结构一致,我们推荐使用子目录功能,确保上传后的目录路径与本地一致,便于后续管理。
导入数据的SQL语句如下:
\COPY <directory_Table_name>[/<path>] FROM <local_path_to_file>/<file_name>;-- filename: Wildcard characters (*, ?) are supported to enable uploading multiple files in a directory复制
除了本地导入,我们还提供了专门的导入工具dataX,它支持通过JDBC、ODBC接口将表数据导入至Directory Table,为用户提供了更多的选择和灵活性。
🚩Directory Table使用:表数据查询(支持关键词检索)
数据导入后,用户可以使用SQL语句对Directory Table进行查询和检索。通过查询,用户可以获取文件的相对路径、大小、最后修改时间、MD5码标签等信息。
在查询之前,需要使用我们数据库提供的目录表函数。此函数接收目录表的表名作为参数,并自动读取表中的数据,解析为各个字段,并以字段的形式展示给用户。因此,用户可以使用SQL语句来查询这张表。
以下是查询Directory Table表内语料数据对象元数据的SQL示例:
-- 使用 Table function directory_Table() 读取文件元数据及内容SELECT relative_path,size,last_modified,md5,tagsFROM directory_Table('<dir_Table_name>');复制
通过执行上述SQL语句,用户可以检索出所需的语料数据对象元数据,为后续的算法训练和使用提供数据支持。
语料管理方案介绍及demo演示
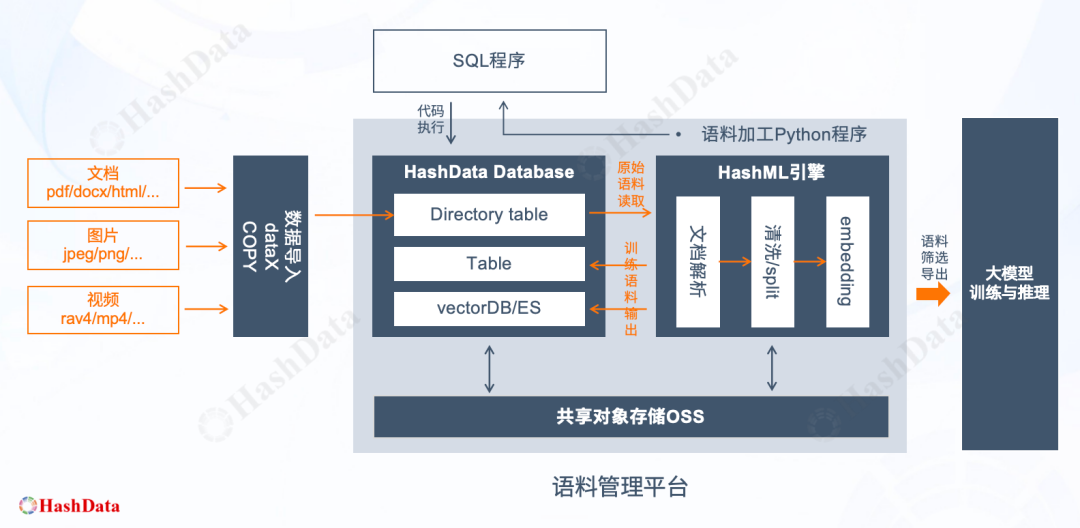
接下来,我们来给大家简单讲解下基于Directory Table特性的语料管理技术方案及demo演示。该技术方案旨在为客户提供一个高效、灵活的语料处理平台,核心在于利用Directory Table的特性,实现对各种格式的文档、图片等原始语料的统一存储、处理与管理。
结语
面对AI应用带来的非结构化数据管理挑战,HashData湖仓一体架构通过引入Directory Table这一新技术特性,为结构化和非结构化数据提供了统一的管理平台。结合HashML的并行处理能力,能够有效降低用户使用门槛,让更多的开发者能够轻松地处理和加工非结构化数据,让用户更加便捷地探索AI应用场景与价值。相关方案已经在大型央企集团开展共创落地,欢迎感兴趣的朋友们与我们联络交流。
*文章篇幅有限,更多技术细节讲解欢迎大家点击文末左下角【阅读原文】链接,观看本期直播回放~
相关阅读:
欢迎大家扫描下方二维码
添加企微小助手联系我们
获取HashData产品与活动最新资讯!


评论

 0 点赞
0 点赞 0 点赞 0 点赞 0 点赞
0 点赞 0 点赞 0 点赞 0 点赞
0 点赞 0 点赞
0 点赞


