




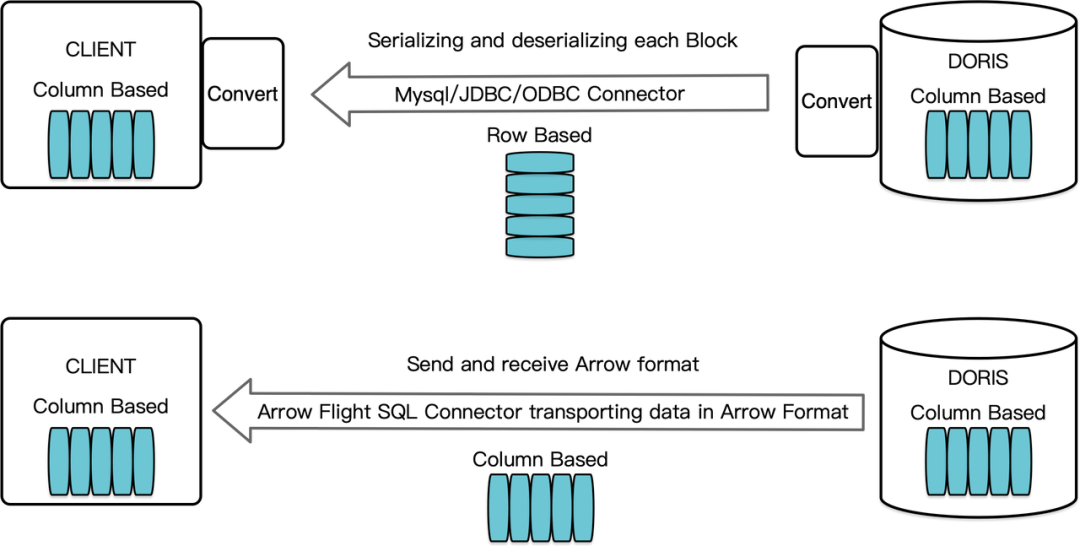
近年来,随着数据科学、数据湖分析等场景的兴起,对数据读取和传输速度提出更高的要求。而 JDBC/ODBC 作为与数据库交互的主流标准,在应对大规模数据读取和传输时显得力不从心,无法满足高性能、低延迟等数据处理需求。为提供更高效的数据传输方案,Apache Doris 在 2.1 版本中基于 Arrow Flight SQL 协议实现了高速数据传输链路,使得数据传输性能实现百倍飞跃。
基于 Arrow Flight SQL 的高速数据传输链路
性能测试及对比

分别使用 Pymysql、Pandas、Arrow Flight SQL 对不同类型数据的传输进行了测试,测试结果如下:
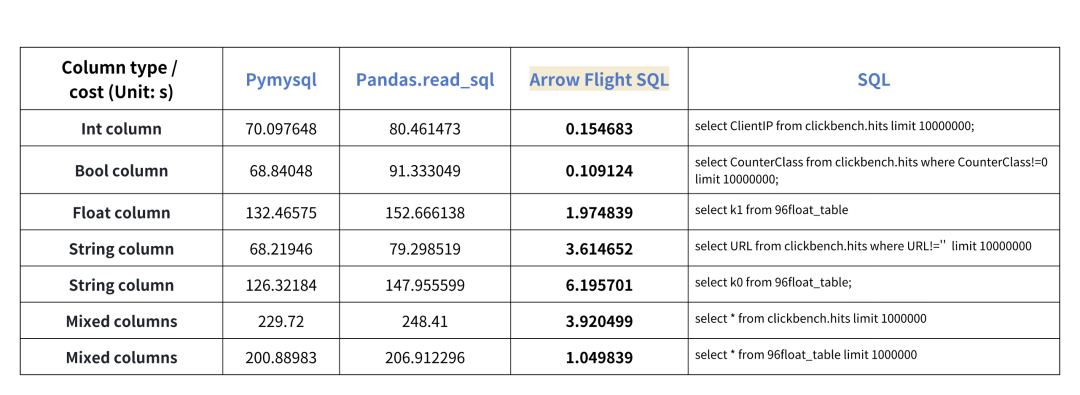
从测试结果来看,Arrow Flight SQL 在所有列类型的传输上都展现出了显著的性能优势。在绝大多数读取场景中,Arrow Flight SQL 的性能提升超 20 倍,而在部分场景中甚至实现了百倍的性能飞跃,为大数据处理和分析提供了强有力的保障。
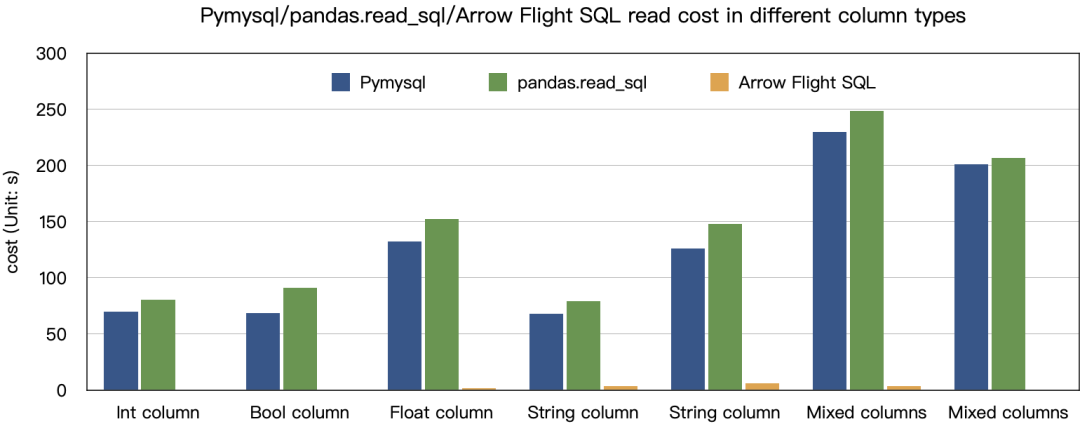
使用介绍
01 安装 Library
pip install adbc_driver_manager
pip install adbc_driver_flightsql复制
import以下模块/库来使用已安装的 Library:import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql复制
修改 fe/conf/fe.conf中arrow_flight_sql_port为一个可用端口,如 9090。修改 be/conf/be.conf中arrow_flight_port为一个可用端口,如 9091。
conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "user",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "pass",
})
cursor = conn.cursor()复制
03 建表与获取元数据
cursor.execute()函数,执行建表与获取元数据操作:cursor.execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("create database arrow_flight_sql;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show databases;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("use arrow_flight_sql;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("""CREATE TABLE arrow_flight_sql_test
(
k0 INT,
k1 DOUBLE,
K2 varchar(32) NULL DEFAULT "" COMMENT "",
k3 DECIMAL(27,9) DEFAULT "0",
k4 BIGINT NULL DEFAULT '10',
k5 DATE,
)
DISTRIBUTED BY HASH(k5) BUCKETS 5
PROPERTIES("replication_num" = "1");""")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show create table arrow_flight_sql_test;")
print(cursor.fetchallarrow().to_pandas())复制
StatusResult返回 0 ,则说明 Query 执行成功(这样设计是为了兼容 JDBC)。StatusResult
0 0
StatusResult
0 0
Database
0 __internal_schema
1 arrow_flight_sql
.. ...
507 udf_auth_db
[508 rows x 1 columns]
StatusResult
0 0
StatusResult
0 0
Table Create Table
0 arrow_flight_sql_test CREATE TABLE `arrow_flight_sql_test` (\n `k0`...复制
04 导入数据
cursor.execute("""INSERT INTO arrow_flight_sql_test VALUES
('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'),
('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'),
('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'),
('3', 4, "ID", 4, 4, '2023-10-22'),
('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")
print(cursor.fetchallarrow().to_pandas())
StatusResult
0 0复制
05 执行查询
cursor.execute("select * from arrow_flight_sql_test order by k0;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("set exec_mem_limit=2000;")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("show variables like \"%exec_mem_limit%\";")
print(cursor.fetchallarrow().to_pandas())
cursor.execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
print(cursor.fetchallarrow().to_pandas())复制
k0 k1 K2 k3 k4 k5
0 0 0.10000 ID 0.000100000 9999999999 2023-10-21
1 1 0.20000 ID_1 1.000000010 0 2023-10-21
2 2 3.40000 ID_1 3.100000000 123456 2023-10-22
3 3 4.00000 ID 4.000000000 4 2023-10-22
4 4 122345.54321 ID 122345.543210000 5 2023-10-22
[5 rows x 6 columns]
StatusResult
0 0
Variable_name Value Default_Value Changed
0 exec_mem_limit 2000 2147483648 1
k5 Nullable(Float64)_1 Int64_2 Nullable(Decimal(38, 9))_3
0 2023-10-22 122352.94321 3 40784.214403333
1 2023-10-21 0.30000 2 0.500050005
[2 rows x 5 columns]复制
06 完整代码
# Doris Arrow Flight SQL Test
# step 1, library is released on PyPI and can be easily installed.
# pip install adbc_driver_manager
# pip install adbc_driver_flightsql
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
# step 2, create a client that interacts with the Doris Arrow Flight SQL service.
# Modify arrow_flight_sql_port in fe/conf/fe.conf to an available port, such as 9090.
# Modify arrow_flight_port in be/conf/be.conf to an available port, such as 9091.
conn = flight_sql.connect(uri="grpc://127.0.0.1:9090", db_kwargs={
adbc_driver_manager.DatabaseOptions.USERNAME.value: "root",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "",
})
cursor = conn.cursor()
# interacting with Doris via SQL using Cursor
def execute(sql):
print("\n### execute query: ###\n " + sql)
cursor.execute(sql)
print("### result: ###")
print(cursor.fetchallarrow().to_pandas())
# step3, execute DDL statements, create database/table, show stmt.
execute("DROP DATABASE IF EXISTS arrow_flight_sql FORCE;")
execute("show databases;")
execute("create database arrow_flight_sql;")
execute("show databases;")
execute("use arrow_flight_sql;")
execute("""CREATE TABLE arrow_flight_sql_test
(
k0 INT,
k1 DOUBLE,
K2 varchar(32) NULL DEFAULT "" COMMENT "",
k3 DECIMAL(27,9) DEFAULT "0",
k4 BIGINT NULL DEFAULT '10',
k5 DATE,
)
DISTRIBUTED BY HASH(k5) BUCKETS 5
PROPERTIES("replication_num" = "1");""")
execute("show create table arrow_flight_sql_test;")
# step4, insert into
execute("""INSERT INTO arrow_flight_sql_test VALUES
('0', 0.1, "ID", 0.0001, 9999999999, '2023-10-21'),
('1', 0.20, "ID_1", 1.00000001, 0, '2023-10-21'),
('2', 3.4, "ID_1", 3.1, 123456, '2023-10-22'),
('3', 4, "ID", 4, 4, '2023-10-22'),
('4', 122345.54321, "ID", 122345.54321, 5, '2023-10-22');""")
# step5, execute queries, aggregation, sort, set session variable
execute("select * from arrow_flight_sql_test order by k0;")
execute("set exec_mem_limit=2000;")
execute("show variables like \"%exec_mem_limit%\";")
execute("select k5, sum(k1), count(1), avg(k3) from arrow_flight_sql_test group by k5;")
# step6, close cursor
cursor.close()复制
大规模数据传输场景应用示例
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import adbc_driver_manager
import adbc_driver_flightsql.dbapi as flight_sql
import pandas
from datetime import datetime
my_uri = "grpc://0.0.0.0:`fe.conf_arrow_flight_port`"
my_db_kwargs = {
adbc_driver_manager.DatabaseOptions.USERNAME.value: "root",
adbc_driver_manager.DatabaseOptions.PASSWORD.value: "",
}
sql = "select * from clickbench.hits limit 1000000;"
# PEP 249 (DB-API 2.0) API wrapper for the ADBC Driver Manager.
def dbapi_adbc_execute_fetchallarrow():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
cursor.execute(sql)
arrow_data = cursor.fetchallarrow()
dataframe = arrow_data.to_pandas()
print("\n##################\n dbapi_adbc_execute_fetchallarrow" + ", cost:" + str(datetime.now() - start_time) + ", bytes:" + str(arrow_data.nbytes) + ", len(arrow_data):" + str(len(arrow_data)))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
# ADBC reads data into pandas dataframe, which is faster than fetchallarrow first and then to_pandas.
def dbapi_adbc_execute_fetch_df():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
cursor.execute(sql)
dataframe = cursor.fetch_df()
print("\n##################\n dbapi_adbc_execute_fetch_df" + ", cost:" + str(datetime.now() - start_time))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
# Can read multiple partitions in parallel.
def dbapi_adbc_execute_partitions():
conn = flight_sql.connect(uri=my_uri, db_kwargs=my_db_kwargs)
cursor = conn.cursor()
start_time = datetime.now()
partitions, schema = cursor.adbc_execute_partitions(sql)
cursor.adbc_read_partition(partitions[0])
arrow_data = cursor.fetchallarrow()
dataframe = arrow_data.to_pandas()
print("\n##################\n dbapi_adbc_execute_partitions" + ", cost:" + str(datetime.now() - start_time) + ", len(partitions):" + str(len(partitions)))
print(dataframe.info(memory_usage='deep'))
print(dataframe)
dbapi_adbc_execute_fetchallarrow()
dbapi_adbc_execute_fetch_df()
dbapi_adbc_execute_partitions()
##################
dbapi_adbc_execute_fetchallarrow, cost:0:00:03.548080, bytes:784372793, len(arrow_data):1000000
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000000 entries, 0 to 999999
Columns: 105 entries, CounterID to CLID
dtypes: int16(48), int32(19), int64(6), object(32)
memory usage: 2.4 GB
None
CounterID EventDate UserID EventTime WatchID JavaEnable Title GoodEvent ... UTMCampaign UTMContent UTMTerm FromTag HasGCLID RefererHash URLHash CLID
0 245620 2013-07-09 2178958239546411410 2013-07-09 19:30:27 8302242799508478680 1 OWAProfessionov — Мой Круг (СВАО Интернет-магазин 1 ... 0 -7861356476484644683 -2933046165847566158 0
999999 1095 2013-07-03 4224919145474070397 2013-07-03 14:36:17 6301487284302774604 0 @дневники Sinatra (ЛАДА, цена для деталли кто ... 1 ... 0 -296158784638538920 1335027772388499430 0
[1000000 rows x 105 columns]
##################
dbapi_adbc_execute_fetch_df, cost:0:00:03.611664
##################
dbapi_adbc_execute_partitions, cost:0:00:03.483436, len(partitions):1
##################
low_level_api_execute_query, cost:0:00:03.523598, stream.address:139992182177600, rows:-1, bytes:784322926, len(arrow_data):1000000
##################
low_level_api_execute_partitions, cost:0:00:03.738128streams.size:3, 1, -1复制
jdbc:mysql换成jdbc:arrow-flight-sql,查询返回的结果依然是 JDBC 的 ResultSet 数据结构。import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
Class.forName("org.apache.arrow.driver.jdbc.ArrowFlightJdbcDriver");
String DB_URL = "jdbc:arrow-flight-sql://0.0.0.0:9090?useServerPrepStmts=false"
+ "&cachePrepStmts=true&useSSL=false&useEncryption=false";
String USER = "root";
String PASS = "";
Connection conn = DriverManager.getConnection(DB_URL, USER, PASS);
Statement stmt = conn.createStatement();
ResultSet resultSet = stmt.executeQuery("show tables;");
while (resultSet.next()) {
String col1 = resultSet.getString(1);
System.out.println(col1);
}
resultSet.close();
stmt.close();
conn.close();
03 JAVA
// method one
AdbcStatement stmt = connection.createStatement()
stmt.setSqlQuery("SELECT * FROM " + tableName)
// executeQuery, two steps:
// 1. Execute Query and get returned FlightInfo;
// 2. Create FlightInfoReader to sequentially traverse each Endpoint;
QueryResult queryResult = stmt.executeQuery()
// method two
AdbcStatement stmt = connection.createStatement()
stmt.setSqlQuery("SELECT * FROM " + tableName)
// Execute Query and parse each Endpoint in FlightInfo, and use the Location and Ticket to construct a PartitionDescriptor
partitionResult = stmt.executePartitioned();
partitionResult.getPartitionDescriptors()
//Create ArrowReader for each PartitionDescriptor to read data
ArrowReader reader = connection2.readPartition(partitionResult.getPartitionDescriptors().get(0).getDescriptor()))复制
结束语
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
【活动】分享你的压箱底干货文档,三篇解锁进阶奖励!
墨天轮编辑部
385次阅读
2025-04-17 17:02:24
云和恩墨钟浪峰:安全生产系列之SQL优化安全操作
墨天轮编辑部
245次阅读
2025-03-31 11:08:20
周边生态|PGRX for Cloudberry 开源,pgvector for Cloudberry 升级到 0.8.0
HashData
234次阅读
2025-04-11 15:35:07
TDengine 3.3.6.0 发布:TDgpt + 虚拟表 + JDBC 加速 8 大升级亮点
TDengine
198次阅读
2025-04-09 11:01:22
Apache Doris 2025 Roadmap:构建 GenAI 时代实时高效统一的数据底座
SelectDB
185次阅读
2025-04-03 17:41:08
Apache Doris & SelectDB 技术能力全面解析
SelectDB
132次阅读
2025-04-11 11:13:20
拉卡拉 x Apache Doris:统一金融场景 OLAP 引擎,查询提速 15 倍,资源直降 52%
SelectDB
128次阅读
2025-04-02 17:52:59
Apache Doris 2.1.9 版本正式发布
SelectDB
118次阅读
2025-04-03 17:40:15
Before & After:SQL整容级优化
薛晓刚
112次阅读
2025-04-14 22:08:44
SQL 优化之 OR 子句改写
xiongcc
98次阅读
2025-04-21 00:08:06
