




前言
数据分析中会用数据库语言是个人能力的门槛,虽然在工作中其实用excel 处理结果数据是占多数的,但是数据的提取还需要mysql或hive等进行辅助。
对于我们来说实操能力要大于理论知识,当然不是说理论知识不重要,理论知识可以优化你的语句流程等是重要的,但是对于刚入门数据分析来说通常要优先掌握一些查询方法来处理业务需求,后期熟练了可以再深入了解。
下面分几章讲一下工作中常用的mysql查询方法。
查询语法常用关键字说明
Select:查询
from:要查的哪个表
Where:成立条件
Like:模糊查找
union:联合,合并
distinct:不重复的
order by desc/asc :排序(desc :降序;asc:升序)
group by:分组
join:关联
去重
去重:常用于统计数据指标中的指定时间段内的UV(人数)。
比如运营同学说:帮忙统计一下前天到现在进入活动页面的人数多少?这里我们就知道他要的是时间段内不重复的人头数,那就要用到去重的手段。
msyql 中常用的去重的方式有distinct 和 group by :
distinct : 是对表中的某一列去重;
group by :是对某列进行分组;
下面我们通过案例来说明具体的用法:
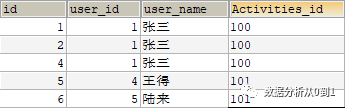
上面表字段表示:id(序号)、user_id(用于唯一标识)、user_name(用户姓名)、Activities_id(活动唯一标识)
问:求参加活动100和活动101的有多少人?
--- 因为user_id 和 user_name是一一对应的 所以对哪个去重都是一样的--- count 表示统计次数,UV 表示别名,类似小名SELECT COUNT(DISTINCT user_name) uv FROM tmp_table;---结果 3复制
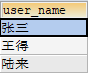
问:求参加活动100和活动101的有哪些人?
--- 使用distinct方式去重select distinct user_name uv from tmp_table;--- 使用group by 方式分组去重select user_name uv from tmp_table group by user_name;复制
结果:
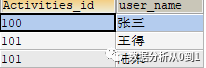
问:求参加活动100和活动101的分别有哪些人?
SELECT Activities_id,user_name FROM tmp_tableGROUP BY Activities_id,user_name;复制
结果:
排序
排序:order by desc/asc :排序(desc :降序;asc:升序) 默认是升序。
对于排序,通常运营的同学会问:想看一下 ”top N“ 这种数据常用的就是排序方法。
现有学生班级成绩表:
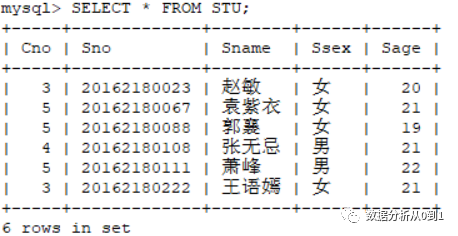
上面表字段表示:cno(班级号)、sno(学号)、Sname(用户姓名)、ssex(性别)、Sage(年龄)
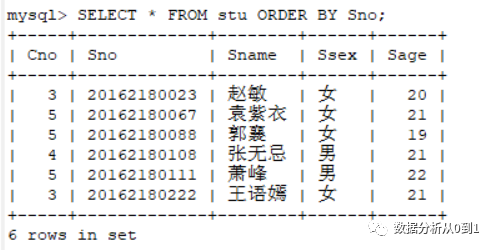
问:想依据Sno(学号)对输出进行从小到大排序
SELECT * FROM stu ORDER BY Sno;复制
得到以下排序后的输出:
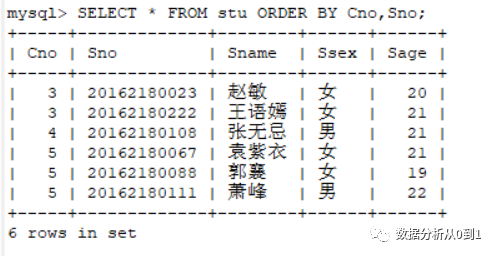
问:如何先进行班排序,然后在班内进行学号的排序。
操作语句如下:
SELECT * FROM stu ORDER BY Cno,Sno;复制
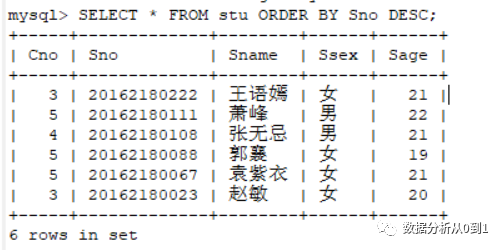
问:想依据Sno(学号)对输出进行从大到小排序。
操作语句如下
SELECT * FROM stu ORDER BY Sno DESC;复制
好了,先到这里,量虽不多,但希望学习的同学好好吸收,本章讲解了mysql中 的去重,以及排序,虽然案例简单,但是在工作中用到的地方还是很多的,希望看完再遇到类似的问题可以得到帮助,下章讲解工作中常遇到的子查询。
