




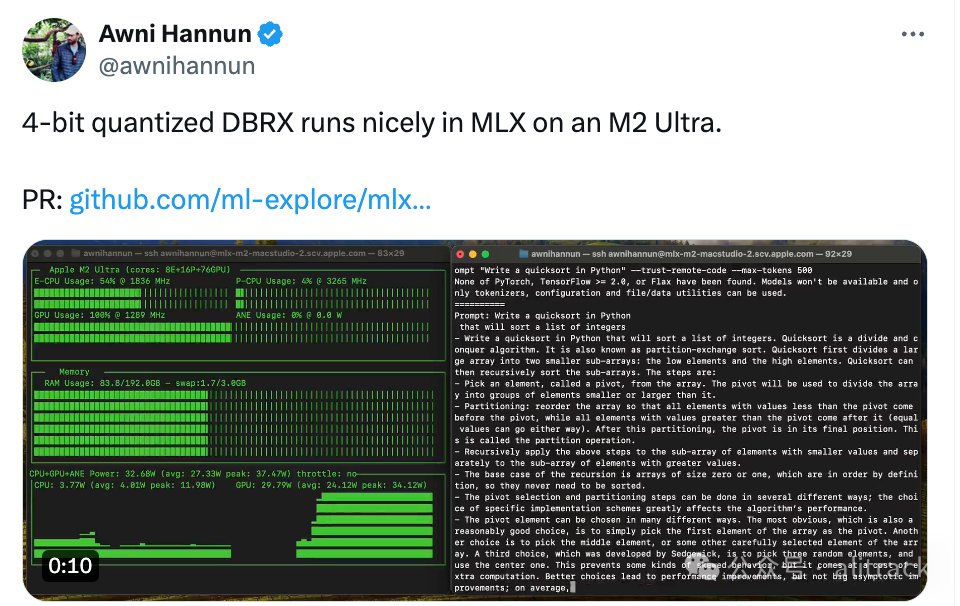
DBRX 在 M2 Ultra上跑起来了,内存使用更低
昨天才知道性能超LLaMA2、Grok-1!1320亿参数的开源大模型DBRX来了, 今天就看到了有人在Mac Studio M2 Ultra 上跑起来了,比Grok-1的要求更低。
https://twitter.com/awnihannun/status/1773024954667184196
从上面的视频可以看出,硬件信息如下:
• M2 Ultra 8E+16P+76GPU,内存192GB
• 8E - 表示8个高性能CPU核心(E代表Efficient高性能核心)
• 16P - 表示16个能耗核心(P代表Performance高效能核心)
• 76GPU - 表示76个GPU核心,用于图形处理和加速各种计算任务
• 内存峰值没有到90GB, 有128GB的mac Studio 可以试试了。
• 速度
• 提示词(prompt): 3.415 tokens/s
• 生成(generation): 14.071 tokens/s
作者介绍
Awni Hannun目前是 Apple 机器学习研究(MLR)团队的研究科学家。在此之前,曾在Zoom、Facebook AI Research和百度的硅谷AI实验室工作,在那里他领导了Deep Speech项目。计算机科学博士学位是在吴恩达的指导下在斯坦福大学完成的。
python -m mlx_lm.generate --model --prompt "Write a quicksort in Python" --trust-remote-code --max-tokens 500复制
其他发现
从mlx-examples的PR:https://github.com/ml-explore/mlx-examples/pull/628, 看到下面这段话,
I have been running it sharded on 4xA100 80GB - and indeed the above are the prompts I get with either.
I could 8 bit quant it, but llama.cpp doesn't support less than 8 bit quantization for DBRX yet as it is slightly customized. Right now I am in FP16. Would it help to try 8?
For what its worth, I have benchmarked somewhere in the neighborhood of ~50 IFT LLMs against humaneval, in none of the cases did dropping to 4 bit affect performance substantially (3 bit did a bit, though, but not to the point of being unusable). So FWIW quantization error alone absent a bug isn't sufficient to explain such drastic results IME - i.e. dropping to a 0 on humaneval would be unheard of, which is what happens here.
也就是说, 4xA100 80GB 就可以跑 FP16了?
这样的机器多少钱?
我之前一篇文章跑特斯拉大模型Grok-1的电脑这样买能省2W+?
讨论了如何能用更低的价格买到苹果家的产品,已经有人实践成功了。
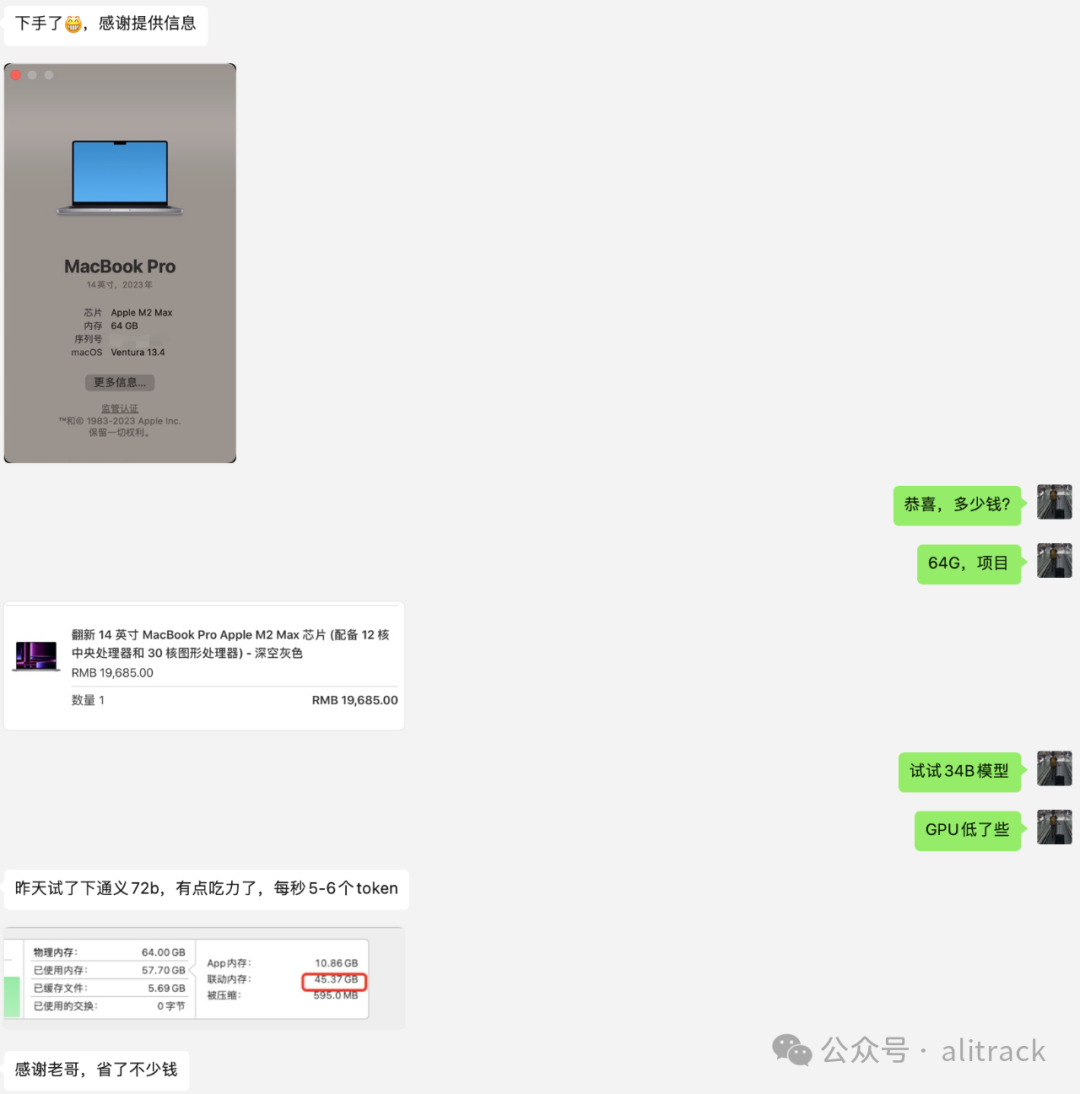
另外也有人说,不需要那么多钱(因为不需要那么大的SSD), 是的,我这个是按顶配来看的。
没有条件自己跑,但想体验的同学接着往下看, 自行解决🪄问题。
可以免费在线体验DBRX的地方
官方
https://huggingface.co/spaces/databricks/dbrx-instruct
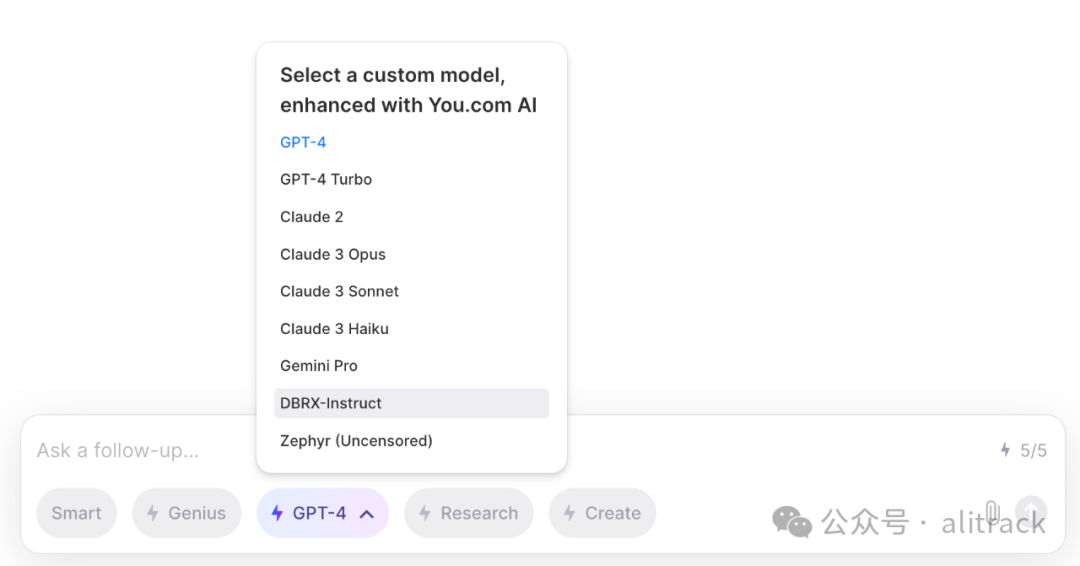
you.com[1]
需要注册才能使用
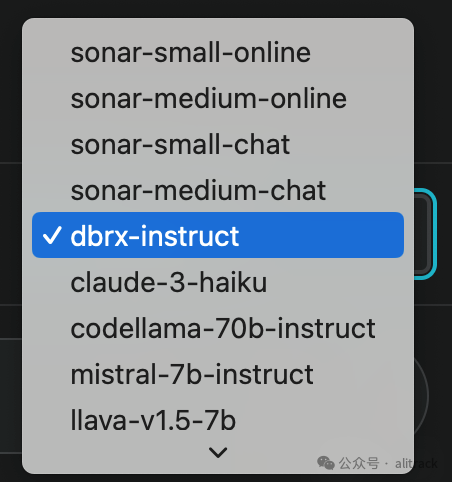
perplexity[2]
免注册
引用链接
[1]
you.com: https://you.com[2]
perplexity: https://labs.perplexity.ai/
