




本篇对PolarDB-X 全局binlog系统的高可用机制以及稳定性相关的内容进行介绍,主要以FAQ的方式展开,并对核心问题进行重点描述。
总体架构
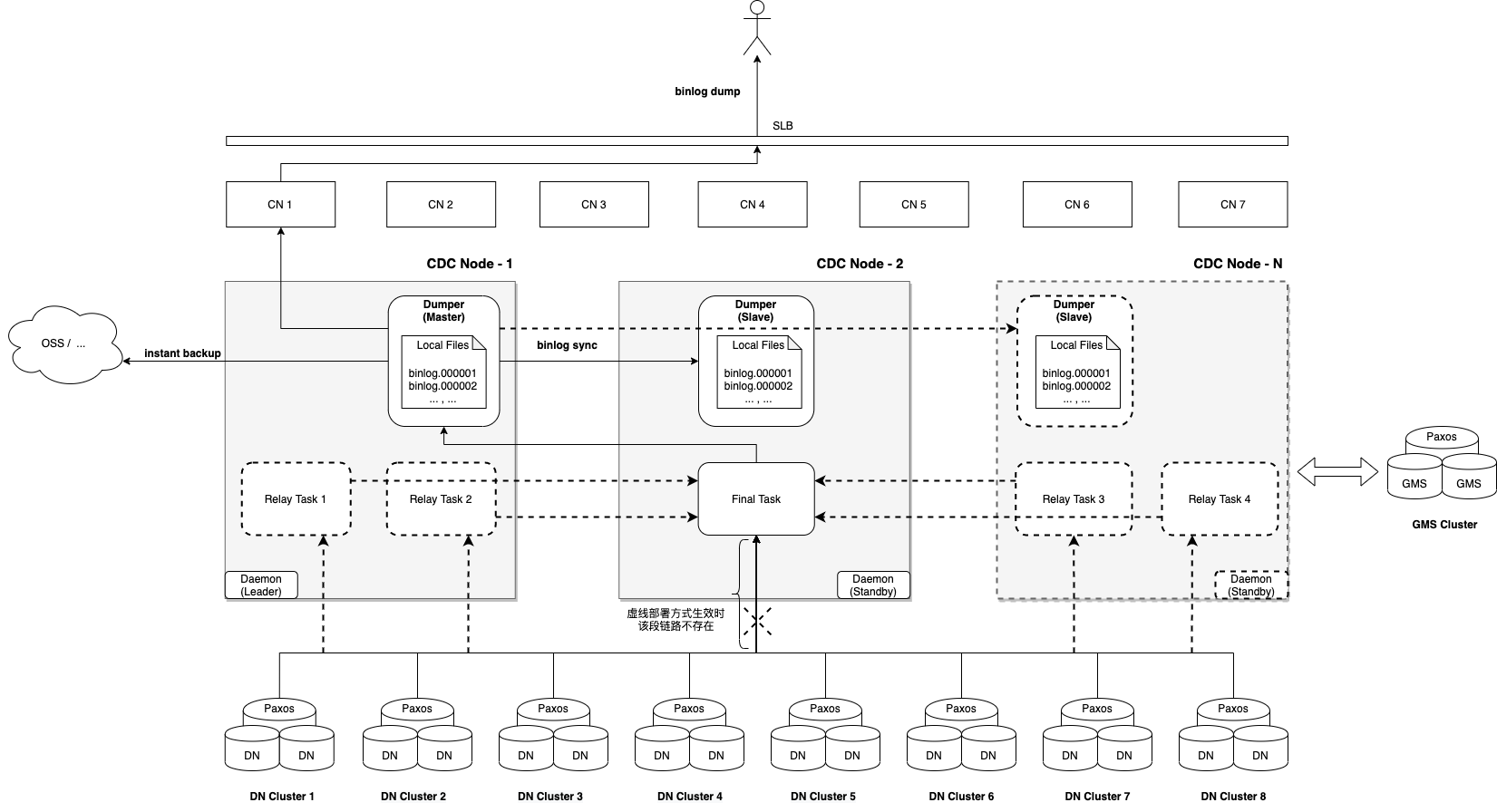
全局binlog系统的部署架构如上图所示,支持三种部署模式:
单机部署
只需要一个节点,即可运行全局binlog系统,该节点上会运行一个Daemon进程、一个FinalTask进程和一个Dumper进程。单机部署模式下,系统并没有HA的能力,借此小节主要对这几个进程的功能定位进行一下介绍
Daemon(后台进程)
Daemon进程是一个后台进程,虽然不直接参与全局binlog的生产,但是其为整个系统的大脑。每个节点上都会运行一个Daemon进程,其中会有一个进程抢占为leader,承担一些全局总控的任务。Daemon的核心功能主要有:
- 集成HTTP服务,提供运维接口 详情
- 收集metrics信息 详情
- 管理异常事件 详情
- 维护运行时拓扑 详情
- 监测工作进程健康状态 详情
- 监测和清理历史数据 详情
- 维护TSO心跳 详情
FinalTask(工作进程)
FinalTask进程属于工作进程,承担了全局binlog生产链路中最核心的业务逻辑,其核心功能主要有:
- 物理binlog解析
- 事务排序和合并
- 元数据解析和维护
- binlog数据整形(DDL)
Dumper(工作进程)
Dumper进程属于工作进程,处于全局binlog生产链路的末端,在非单机部署模式下,可以有Master和Slave两个角色,Master负责拉取FinalTask的数据,并构建全局binlog文件,Slave则负责复制Master的binlog文件,在发生故障时实现HA快速切换。Dumper的核心功能主要有:
- 构建终态binlog event
- 本地binlog文件的维护
- 提供dump接口
- binlog文件的备份和恢复(Dumper主备复制和备份本地文件到中心化存储)
标准部署
去掉上图中虚线标识的部分,便是标准部署模式对应的形态,其主要特点有:
- 需要两个节点(容器),每个节点上都有一个dumper进程,一个为Master,一个为Slave
- 为达到负载均衡,FinalTask和Dumper Master会分署不同节点
- 该模式主要用来适配DN规模不太大的集群(<=64),FinalTask直接对接所有DN节点
多级部署
上图中虚线标识的部分展示的是多级部署形态,所谓多级指的是进程级的多级归并,其主要特点有:
- 至少两个节点(容器),节点数量可任意伸缩
- 每个节点上都有一个dumper进程,一个为Master,其它为Slave(slave数量可自定义)
- Task分为两层,RelayTask直接对接DN承接部分DN的流量,FinalTask对接所有RelayTask实现最终事务归并
- RelayTask的核心功能和FinalTask基本一致,主要差异在于层级不同,其均匀分布在所有节点上
- 该模式主要用来适配DN规模比较大的集群(大于64),通过进程级的多级归并保障数据链路的性能
HA场景
下面罗列一下会导致系统发生自动重启、故障转移或HA切换的主要场景
CDC节点数量变更
每个CDC节点上都会运行一个Daemon进程,每个Daemon进程会在系统表binlog_node_info中注册一条记录,并实时更新心跳时间戳。Daemon中的Leader进程负责监测binlog_node_info表的信息变化,当监测到有新的节点加入或某个节点退出时(正常退出或宕机,Daemon的心跳会出现超时,默认的超时时间是5s),会触发Rebalance,即重新构建运行时拓扑。新版本拓扑构建完成后,所有对应上一版本拓扑的正在运行的工作进程会被Daemon进程Stop,或主动感知到拓扑信息的变化自动退出执行,然后Daemon进程会依据新版本的拓扑信息分别拉起各自负责管理的工作进程,完成状态变更。示意图如下: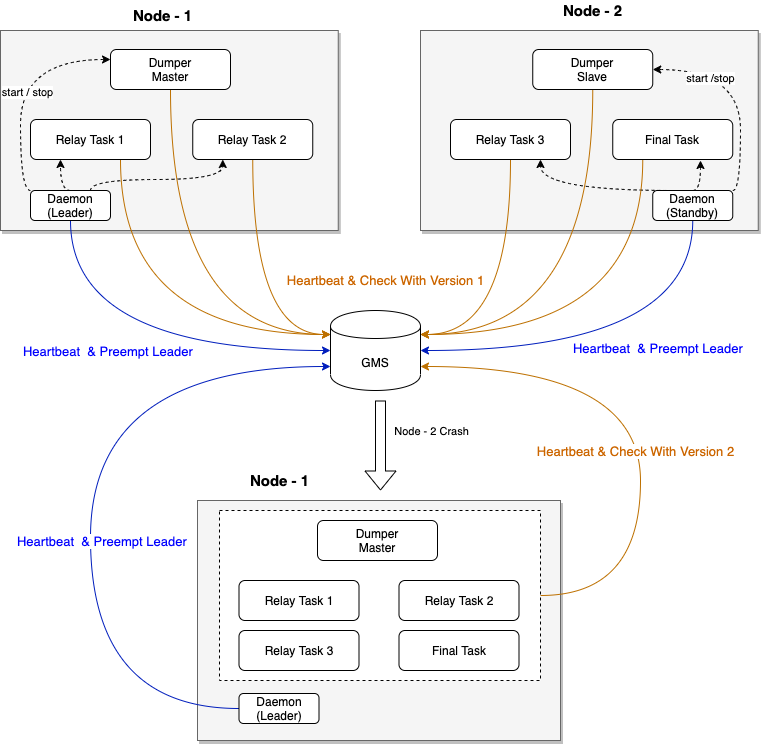
DN节点数量变更
支持在线扩缩容是分布式数据库的必备能力,想体验PolarDB-X的扩缩容能力?可参见文章《实践教程之如何对PolarDB-X集群做动态扩缩容》进行实操演练。CDC通过汇聚各个DN节点的物理binlog来生产全局binlog,当DN节点进行扩容和缩容时,CDC运行时拓扑会自动自行重新构建,整个流程如下图所示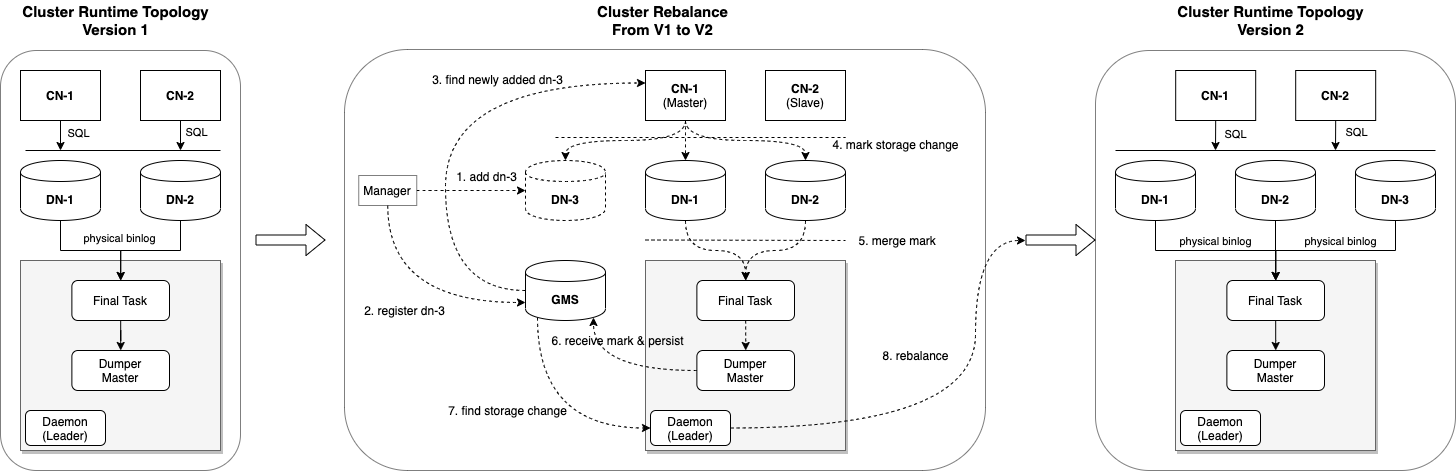
DN节点发生HA
不管是主动对DN集群发起HA切换,还是由于DN Leader节点发生Crash被动触发HA切换,都会导致Task进程和DN之间的连接中断,Task需要重新向新的DN Leader发起重连。全局binlog系统目前采用了进程级的重连机制,即通过触发一次Task进程的重启实现重连,而非进程内的线程级的重连。进程级重连相比线程级重连更容易实现资源的清理,前者通过一次重启实现资源的重新初始化,简单直接,后者需要通过代码显式进行资源的清理,相对复杂和容易出现漏洞。进程级重连相比线程级重连,会额外触发下游工作进程的重连动作,总体的恢复速度会慢几秒钟的时间。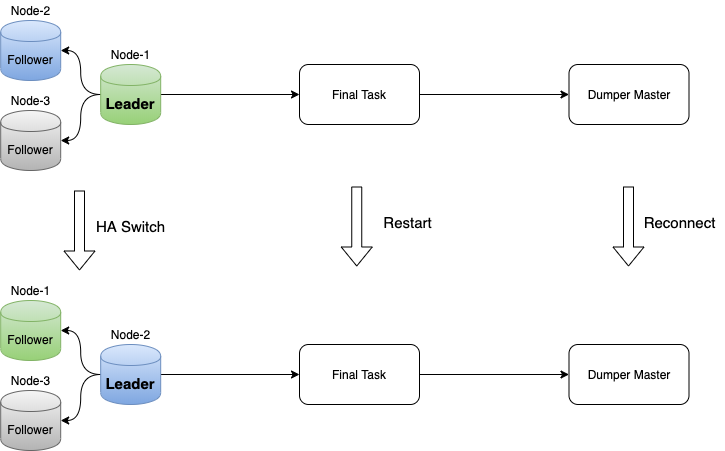
重点问题
工作进程发生crash后如何实现自动recovery?完成recovery的RTO是什么水平?
- 工作进程发生crash后会由Daemon进程进行拉起,Daemon进程会定期探测它所管理的工作进程的健康状态,探测间隔默认为1秒钟。
- 工作进程会维护一个心跳线程,默认每1秒钟更新一次心跳,当Daemon发现工作进程出现心跳超时时会触发主动拉起动作,默认超时时间是2秒钟。
- 工作进程发生crash并重启后,会导致binlog生产链路的重启,链路的RTO不是恒定的,主要受两个因素的影响,元数据的数据量和需要回溯的物理binlog的大小,一般情况下恢复时间为10s左右
DN节点如果发生crash,在其未完成恢复前,是否意味着全局binlog也是不可用的?
- 是的,单个DN节点不可用会触发全局binlog链路的block
- 按照CAP理论来理解,全局binlog采用的是CP模型,即优先保证一致性而不是可用性。
- DN节点可以保证RTO<30s, DN节点发生crash的场景,全局binlog一般可以保证RTO<60s
全局binlog是异步消费DN上的binlog的,DN上的binlog在被消费前如果被清理了,应该如何处理?
- 会导致链路中断且无法恢复,只能进行reset,然后从binlog.000001开始重新构建链路。
- 应尽量调大DN上binlog文件的保留时间,保证在发生消费延迟或其它异常情况时,数据链路能够正常恢复
如果部分CDC节点发生不可用,系统的恢复流程和恢复速度如何?
- 恢复流程可参见上文所述的“CDC节点数量变更”,当部分节点不可用时,问题节点上的Daemon进程会出现心跳超时,系统会通过触发新一轮的rebalance自动完成故障转移
- 恢复时间相比于工作进程发生Crash的场景,会增加5s左右
如果全部CDC节点发生不可用,且无法原地恢复,系统是否还具备恢复能力?恢复时间如何?
- 具备。如果是全部节点出现不可用且无法原地恢复,待新的节点被拉起后,本地并没有binlog文件,此时进行链路恢复有两种策略
恢复策略一: 如果开启了远端备份,系统会将远端存储的binlog文件下载到本地,然后发起链路恢复;当然并不是下载所有的binlog文件,而是下载临近的几个binlog文件,并支持参数控制,方便在恢复速度和恢复文件数量之间做权衡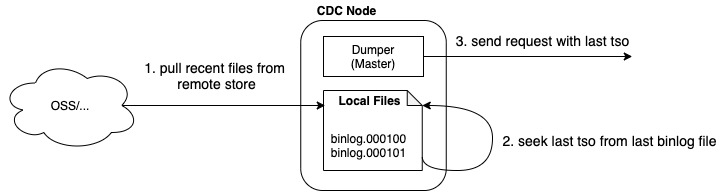
恢复策略二: 如果没有开启远端备份,系统会基于binlog_oss_record表,选择一个合适的binlog文件,发起链路恢复;所谓合适的binlog文件是指已经完成写入的、临近一段时间内的某个binlog文件(倒数第n个),并支持参数控制,方便在恢复速度和恢复文件数量之间做权衡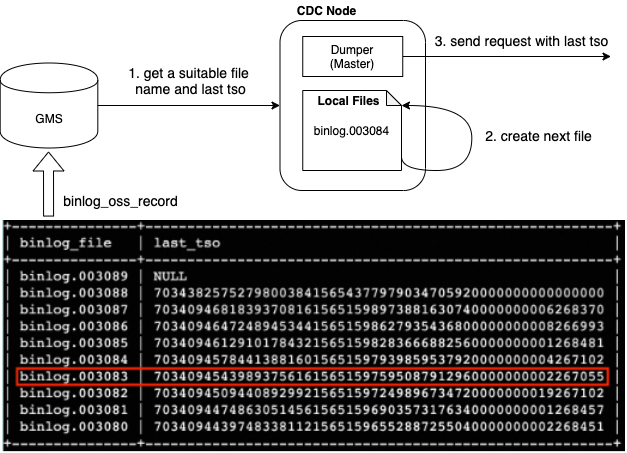
- 恢复时间 = 新节点被拉起的时间 + binlog文件的恢复时间
新节点被拉起的时间取决于管控平台的能力,如k8s。binlog文件的恢复时间主要取决于需要恢复的文件数量:对于恢复策略一,需要恢复的文件数量越多,则需要seek的物理binlog文件的数量越多,耗时也就越长;对于恢复策略二,需要恢复的文件数量越多,则需要下载的数据量越大,耗时也就越长
CDC节点访问CN节点,是通过SLB保证高可用的吗?
不是。为了减少外部依赖并提供更高的灵活性,CDC访问CN节点,自行实现了一套高可用方案,想了解细节可参见DataSourceWrapper
系统发生重启、HA转移等动作后,是如何保证全局binlog文件中的数据不重、不丢、不乱的?
相比MySQL原生binlog,PolarDB-X在全局binlog中为每个事务额外附加了TSO信息,当系统发生重启、HA转移等动作后,会从编号最大的binlog文件中定位到最后一个事务的TSO和File Position,以该TSO为基准发起链路恢复,通过边界判断和幂等判断,控制数据不重、不丢、不乱。
Daemon发生脑裂是否会导致一致性问题?Dumper发生脑裂是否会导致一致性问题?
Daemon进程通过定时向GMS发送SELECT GET_LOCK('xxx')进行Leader的抢占,当出现网络分区等异常情况时,可能会出现短暂的“双Leader"场景,对此,系统主要通过乐观锁、幂等判断等方式进行并发冲突处理。
Dumper Master是Daemon在构建运行时拓扑时指定的,当运行时拓扑发生变更时,Dumper Master也可能发生变化,可能会出现之前的Master进程还未退出、新的Master进程已经启动的“双Master”场景,对此,系统主要通过加锁和对比运行时版本号来控制并发冲突。该方案不仅适用于Dumper,同时也适用于FinalTask,在运行时拓扑发生变更时,同样可能出现“双FinalTask”的场景。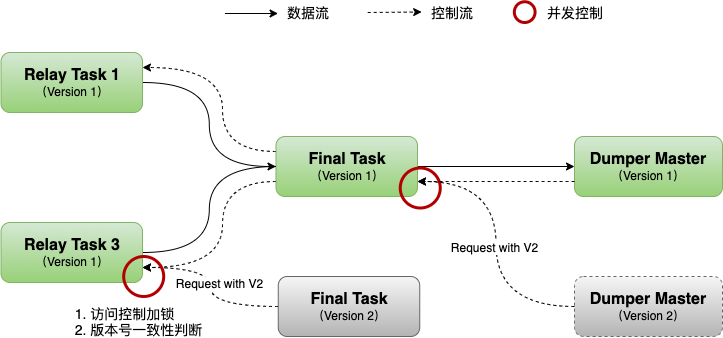
Dumper主备节点上的binlog是完全一样的吗?如果发生主备切换,基于文件名+位点继续进行消费是否是安全的?
CDC的Master节点和Slave节点之间会进行全局binlog文件的复制,并保证两边数据完全一致,即下游按照filename + position的方式进行消费订阅,当CDC发生主从切换时,不用担心文件名和位点会发生变化。
Dumper生成的全局binlog文件会保存在本地磁盘,系统是否提供了自动清理机制?
系统提供了自动清理机制,涉及文件清理的参数有
参数名 | 参数描述 |
binlog.cleaner.clean.enable | 是否自动清理本地binlog文件,默认true |
binlog.cleaner.clean.threshold | 触发清理本地binlog文件的阈值,超过inst_disk*阈值后会触发自动清理,inst_disk参数指定了binlog文件可用的磁盘容量的大小 |
binlog.cleaner.check.interval | 检测频率,默认1分钟 |
本地磁盘上的binlog文件被清理后,是否支持通过mysql dump协议直接消费远端存储(如OSS)上的文件?
支持。CDC会优先把构建好的binlog文件保存在本地磁盘,并支持实时上传到远端存储(如OSS),本地磁盘上的文件一般具有较短的存活周期,远端存储上的文件具有较长的存活周期(如15天)。针对远端存储上的文件,CDC提供了透明消费能力,即屏蔽了本地和远端的存储差异,下游系统无需为访问远端存储上的binlog数据做任何额外适配。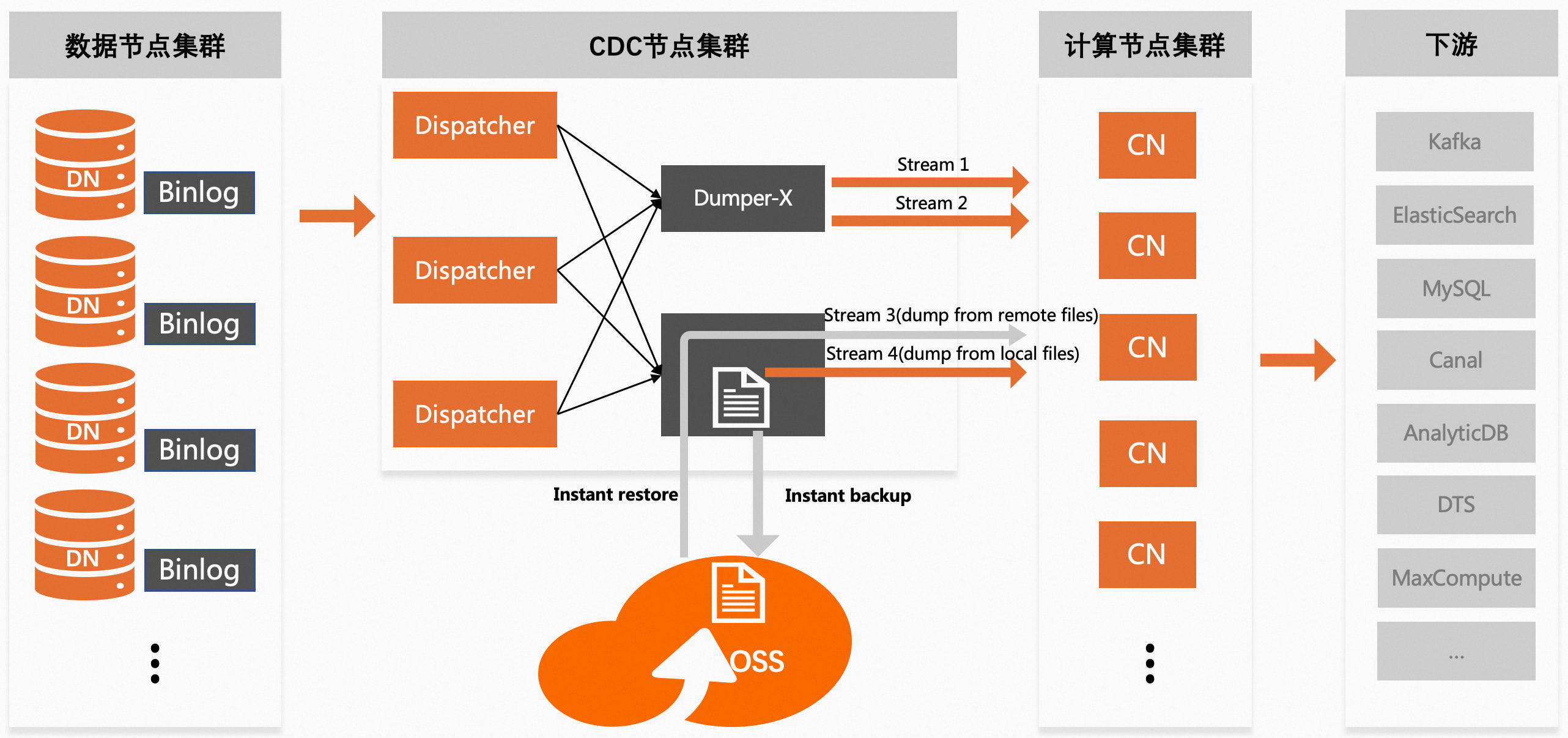
Daemon进程如果发生Crash,是如何被拉起的?Daemon进程发生Crash,是否就意味着所在节点不可用了?
Daemon进程负责管理工作进程,Daemon进程发生Crash后靠cron定时任务进行拉起。Daemon发生Crash,并不代表所在节点就不可用了,当该节点SSH端口可用,且分配给该节点的工作进程都正常时,即使Daemon发生Crash,也不会触发运行时拓扑的Rebalance。
总结
本文对全局binlog系统的高可用和稳定性相关的内容进行了详细的介绍,下面对系统的RTO能力进行汇总
HA场景 | RTO(单位:s) | 说明 |
工作进程Crash | <= 15s | TRT = PST + PRT |
DN HA | <= 45s | TRT = DRT + PST + PRT |
DN扩缩容 | <= 20s | TRT = RBT + PST + PRT |
CDC节点部分不可用 | <= 20s | TRT = RBT + PST + PRT |
CDC节点全部不可用 | <= (20s + CNRT + BFRT) | TRT = RBT + PST + PRT + CNRT + BFRT |
各类型恢复时间的简称定义如下
- TRT(total recovery time)
总的链路恢复时间
- PST(process start time)
进程拉起时间,从Daemon检测到需要启动进程,到触发启动的时间,一般2~3s
- PRT(process recovery time)
进程恢复完成时间,如恢复元数据、定位恢复位点等,一般5~10s
- DRT(datanode recovery time)
DN节点发生HA转移后的恢复时间,恢复时间和恢复的数据量强相关,一般小于30s
- RBT(rebalance during time)
Daemon监测是否需要进行运行时拓扑重建并完成重建的时间,一般5s
- CNRT(cdc node recovery time)
CDC节点发生物理不可用,新节点被拉起的时间,取决于管控平台的能力
- BFRT(binlog file recovery time)
本地binlog file为空时,恢复指定数量binlog文件的时间,恢复5个binlog文件,一般30s左右



