





上图中,最左边一列是原图,右侧的4列是将原图转换成其他风格后的图像。在保证原始图像内容信息不丢失的情况下,将原始图像的风格转换为另一类图像的风格,这种转换被称为图像风格迁移。
有了风格迁移技术,就可以让寒冷的冬季照片一秒入夏啦,就像这样:

是不是很神奇呢?
其实,实现图像风格迁移的方法有很多,这里我们介绍其中之一:CycleGAN。
CycleGAN的网络结构
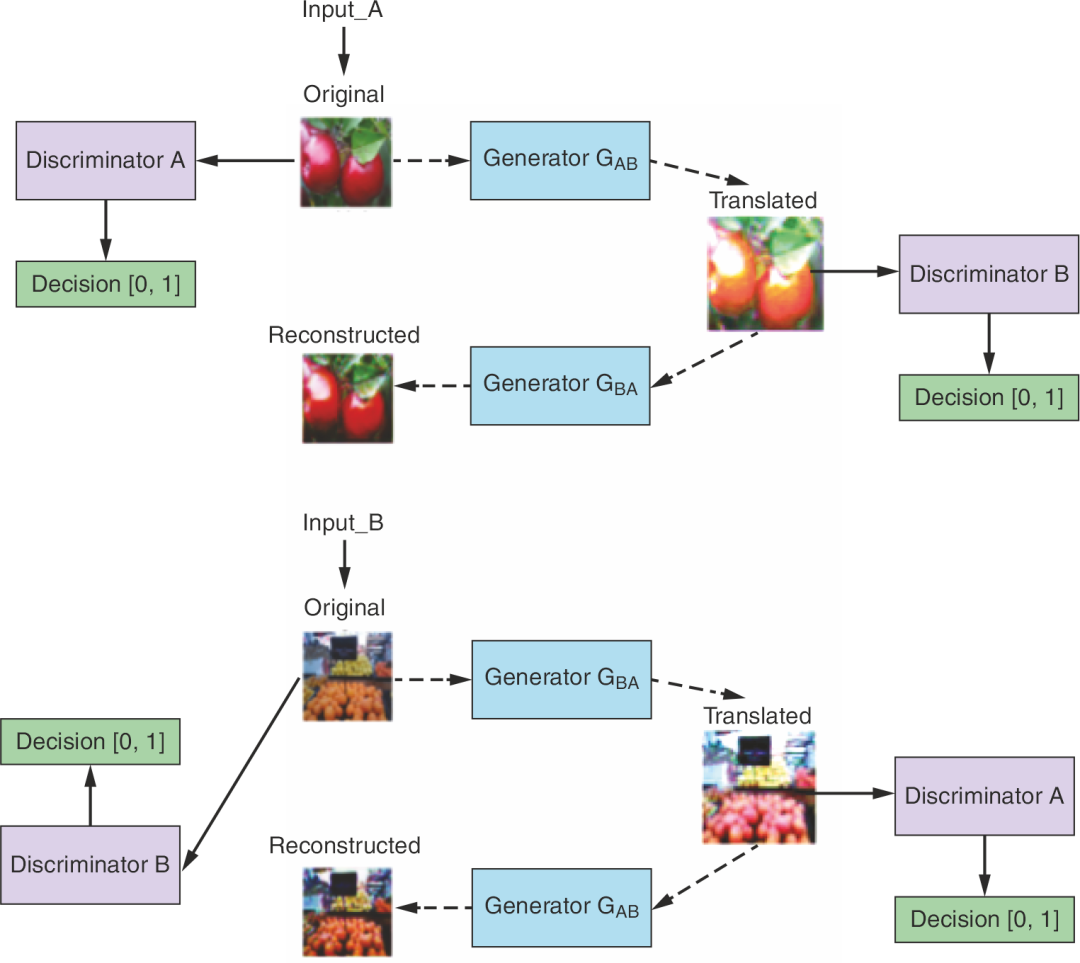
CycleGAN的网络结构如上图所示。它的训练数据集需要来自两个不同的域(就是两种不同风格的图像):;
CycleGAN包含两个生成器:,分别用于将A风格图像转换为B风格图像,以及将B风格图像转换为A风格图像;
同样,它也包含两个判别器:。
CycleGAN的损失函数
在原始GAN损失函数的基础上,CycleGAN为了防止生成器偷懒(解释见下一段),增加了循环一致性损失,这个东西其实就是重构损失,以保证转换后的图像和原图像的内容一致性。
李宏毅老师的PPT中一幅图很形象的展示了循环一致性损失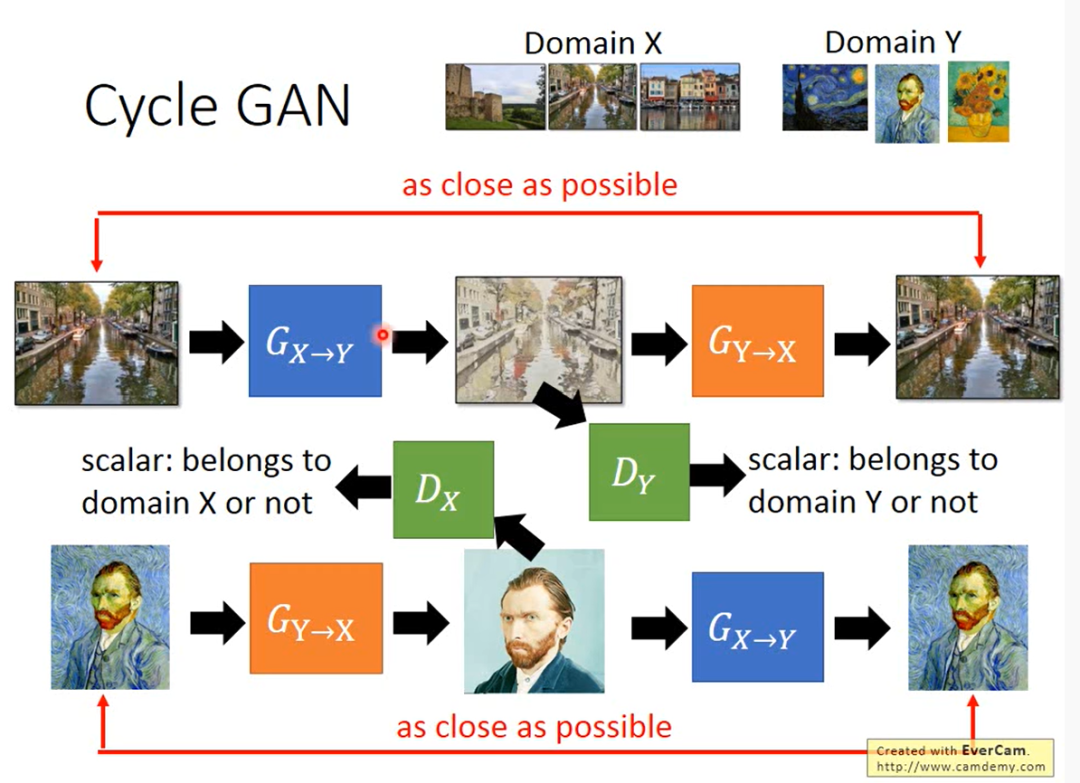
现在举个例子解释偷懒 的含义:比如由A风格转换为B风格时,需要把转换后的图像(记作)与真实的B风格图像(记作)一起喂入判别器,而只是希望与真实B风格图像越接近越好,与真实B风格图像越不接近越好,那么就可能导致生成器直接拿域B中的图像作为,这样就只保证了风格变换的正确性,轻轻松松欺骗过,但是,原图的内容却在转换后丢失了。
加入循环一致性损失,就可以保证转换前后图像的内容不会有太大变化,仅仅是在风格上做了转换。
这样,CycleGAN的损失函数就包括两部分:原始GAN损失+循环一致性损失。其中,原始GAN损失在论文中被称为对抗损失,表达式如下: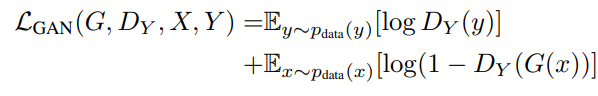
上面的式子是关于一个生成器G的,对于另一个生成器F,只需把上式中的G换成F即可。也就是说,两个生成器的结构是完全一样的。
循环一致性损失表达式如下,它采用了原图和重构图之间的L1 norm 进行计算: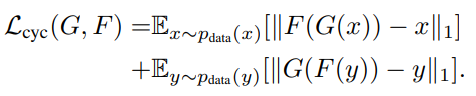
于是总的损失如下: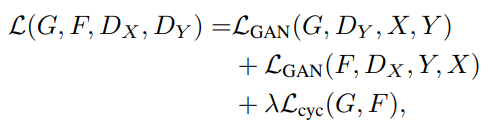
其中用于控制两个域之间的相关性大小。
最终的优化目标如下:
还有一点细节,就是作者实际做实验的时候,将对抗损失的负对数似然损失函数改为最小二乘( least square,)的形式,以获得更强的稳定性: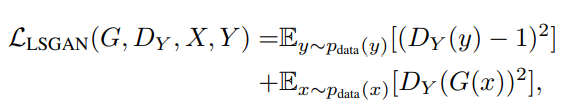
用PyTorch实现CycleGAN
代码来自Github开源项目(点击阅读原文可直达),下面分模块进行解读,请配合代码注释食用。
(ps: 主要关注train和models模块,这是Cycle GAN的核心)
models
models模块实现了生成器和判别器的网络结构搭建。
其中生成器负责将输入图像先通过卷积做下采样,然后连接若干残差块,最后使用转置卷积进行上采样。
#生成器
class Generator(nn.Module):
def __init__(self, input_nc, output_nc, n_residual_blocks=9):
super(Generator, self).__init__()
# 初始化卷积块
model = [ nn.ReflectionPad2d(3),
nn.Conv2d(input_nc, 64, 7),
nn.InstanceNorm2d(64),
nn.ReLU(inplace=True) ]
# 下采样
in_features = 64
out_features = in_features*2
for _ in range(2):
model += [ nn.Conv2d(in_features, out_features, 3, stride=2, padding=1),
nn.InstanceNorm2d(out_features),
#inplace=True:覆盖而非副本,节省内存
nn.ReLU(inplace=True) ]
#特征图个数加倍
in_features = out_features
out_features = in_features*2 # zzz
# 下采样后接残差块
for _ in range(n_residual_blocks):
model += [ResidualBlock(in_features)]
# 上采样
out_features = in_features//2#重新设置out_features
for _ in range(2):
model += [ # 关于output_padding的解释看这儿:https://www.cnblogs.com/wanghui-garcia/p/10791778.html
nn.ConvTranspose2d(in_features, out_features, 3, stride=2, padding=1, output_padding=1),
nn.InstanceNorm2d(out_features),
nn.ReLU(inplace=True) ]
in_features = out_features
out_features = in_features//2
# 输出层
model += [ nn.ReflectionPad2d(3),
nn.Conv2d(64, output_nc, 7),
nn.Tanh() ]
self.model = nn.Sequential(*model)
def forward(self, x):
return self.model(x)复制
上面的代码中,残差块ResidualBlock
实现如下
#残差块
class ResidualBlock(nn.Module):
def __init__(self, in_features):
super(ResidualBlock, self).__init__()
conv_block = [ nn.ReflectionPad2d(1),
nn.Conv2d(in_features, in_features, 3),
nn.InstanceNorm2d(in_features),
nn.ReLU(inplace=True),
nn.ReflectionPad2d(1),
nn.Conv2d(in_features, in_features, 3),
nn.InstanceNorm2d(in_features) ]
self.conv_block = nn.Sequential(*conv_block)
def forward(self, x):
return x + self.conv_block(x)复制
残差块的结构:
初始化一个生成器,来看一下具体的网络结构:
gen=Generator(3,3)
gen复制
输出
Generator(
(model): Sequential(
(0): ReflectionPad2d((3, 3, 3, 3))
(1): Conv2d(3, 64, kernel_size=(7, 7), stride=(1, 1))
(2): InstanceNorm2d(64, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace=True)
(4): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(5): InstanceNorm2d(128, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(6): ReLU(inplace=True)
(7): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(8): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(9): ReLU(inplace=True)
(10): ResidualBlock(
(conv_block): Sequential(
(0): ReflectionPad2d((1, 1, 1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(2): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace=True)
(4): ReflectionPad2d((1, 1, 1, 1))
(5): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(6): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
)
)
(11): ResidualBlock(
(conv_block): Sequential(
(0): ReflectionPad2d((1, 1, 1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(2): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace=True)
(4): ReflectionPad2d((1, 1, 1, 1))
(5): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(6): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
)
)
(12): ResidualBlock(
(conv_block): Sequential(
(0): ReflectionPad2d((1, 1, 1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(2): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace=True)
(4): ReflectionPad2d((1, 1, 1, 1))
(5): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(6): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
)
)
(13): ResidualBlock(
(conv_block): Sequential(
(0): ReflectionPad2d((1, 1, 1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(2): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace=True)
(4): ReflectionPad2d((1, 1, 1, 1))
(5): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(6): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
)
)
(14): ResidualBlock(
(conv_block): Sequential(
(0): ReflectionPad2d((1, 1, 1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(2): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace=True)
(4): ReflectionPad2d((1, 1, 1, 1))
(5): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(6): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
)
)
(15): ResidualBlock(
(conv_block): Sequential(
(0): ReflectionPad2d((1, 1, 1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(2): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace=True)
(4): ReflectionPad2d((1, 1, 1, 1))
(5): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(6): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
)
)
(16): ResidualBlock(
(conv_block): Sequential(
(0): ReflectionPad2d((1, 1, 1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(2): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace=True)
(4): ReflectionPad2d((1, 1, 1, 1))
(5): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(6): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
)
)
(17): ResidualBlock(
(conv_block): Sequential(
(0): ReflectionPad2d((1, 1, 1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(2): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace=True)
(4): ReflectionPad2d((1, 1, 1, 1))
(5): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(6): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
)
)
(18): ResidualBlock(
(conv_block): Sequential(
(0): ReflectionPad2d((1, 1, 1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(2): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace=True)
(4): ReflectionPad2d((1, 1, 1, 1))
(5): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(6): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
)
)
(19): ConvTranspose2d(256, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
(20): InstanceNorm2d(128, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(21): ReLU(inplace=True)
(22): ConvTranspose2d(128, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
(23): InstanceNorm2d(64, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(24): ReLU(inplace=True)
(25): ReflectionPad2d((3, 3, 3, 3))
(26): Conv2d(64, 3, kernel_size=(7, 7), stride=(1, 1))
(27): Tanh()
)
)复制
判别器很简单了,直接堆叠卷积块即可。对于输入图像,网络的输出是一张特征图,用于预测,这也被称为Patch GAN。只不过作者在最终输出时直接取了特征图元素的平均值。
#判别器
class Discriminator(nn.Module):
def __init__(self, input_nc):
super(Discriminator, self).__init__()
# 堆叠卷积层
model = [ nn.Conv2d(input_nc, 64, 4, stride=2, padding=1),
nn.LeakyReLU(0.2, inplace=True) ]
model += [ nn.Conv2d(64, 128, 4, stride=2, padding=1),
nn.InstanceNorm2d(128),
nn.LeakyReLU(0.2, inplace=True) ]
model += [ nn.Conv2d(128, 256, 4, stride=2, padding=1),
nn.InstanceNorm2d(256),
nn.LeakyReLU(0.2, inplace=True) ]
model += [ nn.Conv2d(256, 512, 4, padding=1),
nn.InstanceNorm2d(512),
nn.LeakyReLU(0.2, inplace=True) ]
# FCN classification layer
#输出特征图个数为1,这里体现了Patch GAN
#只不过作者在最后的输出时直接取了特征图元素的平均值
model += [nn.Conv2d(512, 1, 4, padding=1)]
self.model = nn.Sequential(*model)
def forward(self, x):
x = self.model(x)
# 平均池化+展平
return F.avg_pool2d(x, x.size()[2:]).view(x.size()[0], -1)复制
不妨初始化一个判别器,来看一下具体的网络结构: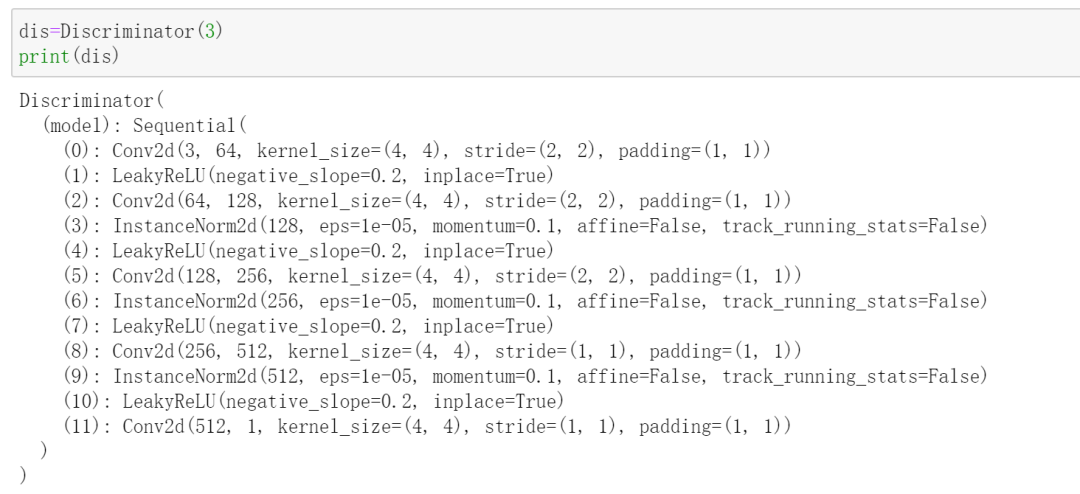
utils
utils模块里定义了一些工具函数
#tensor转image
def tensor2image(tensor):
image = 127.5*(tensor[0].cpu().float().numpy() + 1.0)
if image.shape[0] == 1:
image = np.tile(image, (3,1,1))
return image.astype(np.uint8)
#log
class Logger():
def __init__(self, n_epochs, batches_epoch):
self.viz = Visdom()
self.n_epochs = n_epochs
self.batches_epoch = batches_epoch
self.epoch = 1
self.batch = 1
self.prev_time = time.time()
self.mean_period = 0
self.losses = {}
self.loss_windows = {}
self.image_windows = {}
def log(self, losses=None, images=None):
self.mean_period += (time.time() - self.prev_time)
self.prev_time = time.time()
sys.stdout.write('\rEpoch %03d/%03d [%04d/%04d] -- ' % (self.epoch, self.n_epochs, self.batch, self.batches_epoch))
for i, loss_name in enumerate(losses.keys()):
if loss_name not in self.losses:
self.losses[loss_name] = losses[loss_name].data[0]
else:
self.losses[loss_name] += losses[loss_name].data[0]
if (i+1) == len(losses.keys()):
sys.stdout.write('%s: %.4f -- ' % (loss_name, self.losses[loss_name]/self.batch))
else:
sys.stdout.write('%s: %.4f | ' % (loss_name, self.losses[loss_name]/self.batch))
batches_done = self.batches_epoch*(self.epoch - 1) + self.batch
batches_left = self.batches_epoch*(self.n_epochs - self.epoch) + self.batches_epoch - self.batch
sys.stdout.write('ETA: %s' % (datetime.timedelta(seconds=batches_left*self.mean_period/batches_done)))
# Draw images
for image_name, tensor in images.items():
if image_name not in self.image_windows:
self.image_windows[image_name] = self.viz.image(tensor2image(tensor.data), opts={'title':image_name})
else:
self.viz.image(tensor2image(tensor.data), win=self.image_windows[image_name], opts={'title':image_name})
# End of epoch
if (self.batch % self.batches_epoch) == 0:
# Plot losses
for loss_name, loss in self.losses.items():
if loss_name not in self.loss_windows:
self.loss_windows[loss_name] = self.viz.line(X=np.array([self.epoch]), Y=np.array([loss/self.batch]),
opts={'xlabel': 'epochs', 'ylabel': loss_name, 'title': loss_name})
else:
self.viz.line(X=np.array([self.epoch]), Y=np.array([loss/self.batch]), win=self.loss_windows[loss_name], update='append')
# Reset losses for next epoch
self.losses[loss_name] = 0.0
self.epoch += 1
self.batch = 1
sys.stdout.write('\n')
else:
self.batch += 1
# 每次实例化时都会重置缓冲区
class ReplayBuffer():
def __init__(self, max_size=50):
assert (max_size > 0), 'Empty buffer or trying to create a black hole. Be careful.'
self.max_size = max_size
self.data = []
def push_and_pop(self, data):
to_return = []
for element in data.data:
element = torch.unsqueeze(element, 0)
#缓冲区未满,直接放进去
if len(self.data) < self.max_size:
self.data.append(element)
to_return.append(element)
#缓冲区满了
else:
#随机做以下两个动作之一
#复制缓冲区内的一个元素,放入to_return
#然后更新缓冲区被复制元素为当前的元素element
if random.uniform(0,1) > 0.5:
i = random.randint(0, self.max_size-1)
to_return.append(self.data[i].clone())
self.data[i] = element
#直接把当前元素element放入to_return
else:
to_return.append(element)
return Variable(torch.cat(to_return))
#学习率调度策略
class LambdaLR():
def __init__(self, n_epochs, offset, decay_start_epoch):
assert ((n_epochs - decay_start_epoch) > 0), "Decay must start before the training session ends!"
self.n_epochs = n_epochs
self.offset = offset
self.decay_start_epoch = decay_start_epoch
def step(self, epoch):
return 1.0 - max(0, epoch + self.offset - self.decay_start_epoch)/(self.n_epochs - self.decay_start_epoch)
#网络权值(参数)初始化方案
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
torch.nn.init.normal(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm2d') != -1:
torch.nn.init.normal(m.weight.data, 1.0, 0.02)
torch.nn.init.constant(m.bias.data, 0.0)复制
datasets
用于准备训练数据。CycleGAN的训练数据集包含两个域的图像,我下载了转换斑马和马的数据集horse2zebra
,它的目录结构如下,如果你想换成其他数据集,也要遵循此结构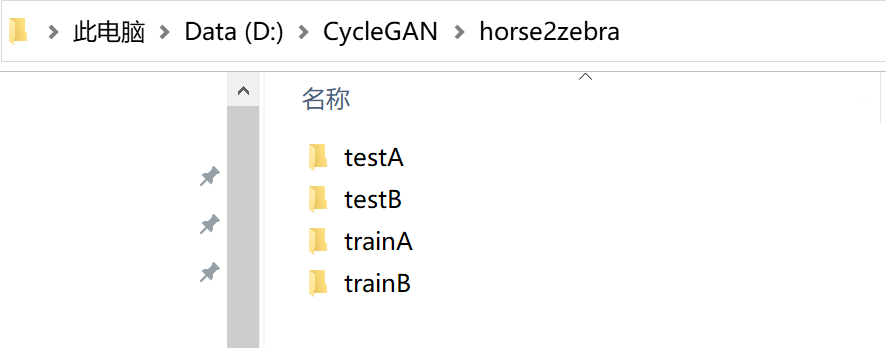
class ImageDataset(Dataset):
def __init__(self, root, transforms_=None, unaligned=False, mode='train'):
self.transform = transforms.Compose(transforms_)
self.unaligned = unaligned
self.files_A = sorted(glob.glob(os.path.join(root, '%s/A' % mode) + '/*.*'))
self.files_B = sorted(glob.glob(os.path.join(root, '%s/B' % mode) + '/*.*'))
#重写使用[]查找对应下标元素时的返回值
def __getitem__(self, index):
item_A = self.transform(Image.open(self.files_A[index % len(self.files_A)]))
if self.unaligned:
item_B = self.transform(Image.open(self.files_B[random.randint(0, len(self.files_B) - 1)]))
else:
item_B = self.transform(Image.open(self.files_B[index % len(self.files_B)]))
return {'A': item_A, 'B': item_B}
#重写len(当前类实例)的返回值
def __len__(self):
return max(len(self.files_A), len(self.files_B))复制
train
train模块实现了模型的训练过程代码。首先,设置一些变量:
# 定义生成器和判别器
netG_A2B = Generator(opt.input_nc, opt.output_nc)
netG_B2A = Generator(opt.output_nc, opt.input_nc)
netD_A = Discriminator(opt.input_nc)
netD_B = Discriminator(opt.output_nc)
#参数初始化
netG_A2B.apply(weights_init_normal)
netG_B2A.apply(weights_init_normal)
netD_A.apply(weights_init_normal)
netD_B.apply(weights_init_normal)
# 设置损失函数
#相比于原始论文,这里多了一个identity loss
criterion_GAN = torch.nn.MSELoss()
criterion_cycle = torch.nn.L1Loss()
criterion_identity = torch.nn.L1Loss()
# 设置优化器和学习率调度器
#使用itertools.chain,可以用一个优化器更新多个网络(这里是两个生成器)的参数
optimizer_G = torch.optim.Adam(itertools.chain(netG_A2B.parameters(), netG_B2A.parameters()),
lr=opt.lr, betas=(0.5, 0.999))
optimizer_D_A = torch.optim.Adam(netD_A.parameters(), lr=opt.lr, betas=(0.5, 0.999))
optimizer_D_B = torch.optim.Adam(netD_B.parameters(), lr=opt.lr, betas=(0.5, 0.999))
lr_scheduler_G = torch.optim.lr_scheduler.LambdaLR(optimizer_G, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step)
lr_scheduler_D_A = torch.optim.lr_scheduler.LambdaLR(optimizer_D_A, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step)
lr_scheduler_D_B = torch.optim.lr_scheduler.LambdaLR(optimizer_D_B, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step)
# 内存分配
Tensor = torch.cuda.FloatTensor if opt.cuda else torch.Tensor
#真实域内图像
input_A = Tensor(opt.batchSize, opt.input_nc, opt.size, opt.size)
input_B = Tensor(opt.batchSize, opt.output_nc, opt.size, opt.size)
#label
target_real = Variable(Tensor(opt.batchSize).fill_(1.0), requires_grad=False)
target_fake = Variable(Tensor(opt.batchSize).fill_(0.0), requires_grad=False)
#重置buffer
fake_A_buffer = ReplayBuffer()
fake_B_buffer = ReplayBuffer()
# 准备训练数据
transforms_ = [ transforms.Resize(int(opt.size*1.12), Image.BICUBIC),
transforms.RandomCrop(opt.size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5)) ]
dataloader = DataLoader(ImageDataset(opt.dataroot, transforms_=transforms_, unaligned=True),
batch_size=opt.batchSize, shuffle=True, num_workers=opt.n_cpu)
# 用于绘制loss曲线
logger = Logger(opt.n_epochs, len(dataloader))复制
在原始论文中,并没有提到identity loss,这是作者在实现时想到的,具体来说,如果将真实的域B中的图像输入(用于将域A图像转换成域B图像),那么在理想情况下应该输出(越接近越好,所以设置了一个与之间的重构损失)。
然后实现训练过程:
###### 训练 ######
for epoch in range(opt.epoch, opt.n_epochs):
for i, batch in enumerate(dataloader):
# 获取域A和域B中一个batch的真实图像
real_A = Variable(input_A.copy_(batch['A']))
real_B = Variable(input_B.copy_(batch['B']))
###### Generators A2B and B2A ######
optimizer_G.zero_grad()
# loss part1 :Identity loss
# 如果输入是B_real,那么应该输出B_real
same_B = netG_A2B(real_B)
loss_identity_B = criterion_identity(same_B, real_B)*5.0
# 如果输入是A_real,那么应该输出A_real
same_A = netG_B2A(real_A)
loss_identity_A = criterion_identity(same_A, real_A)*5.0
# loss part2 :GAN loss,即对抗损失
fake_B = netG_A2B(real_A)#real_A->fake_B
pred_fake = netD_B(fake_B)
loss_GAN_A2B = criterion_GAN(pred_fake, target_real)
fake_A = netG_B2A(real_B)#real_B ->fake_A
pred_fake = netD_A(fake_A)
loss_GAN_B2A = criterion_GAN(pred_fake, target_real)
# loss part3 :循环一致性损失
recovered_A = netG_B2A(fake_B)
loss_cycle_ABA = criterion_cycle(recovered_A, real_A)*10.0
recovered_B = netG_A2B(fake_A)
loss_cycle_BAB = criterion_cycle(recovered_B, real_B)*10.0
# 生成器总的loss
loss_G = loss_identity_A + loss_identity_B + loss_GAN_A2B + loss_GAN_B2A + loss_cycle_ABA + loss_cycle_BAB
loss_G.backward()
#更新两个生成器的参数
optimizer_G.step()
###################################
#两个判别器的损失函数和原始GAN的一致,只是度量方式由交叉熵改为了mse
###### Discriminator A ######
optimizer_D_A.zero_grad()
# Real loss
pred_real = netD_A(real_A)
loss_D_real = criterion_GAN(pred_real, target_real)
# Fake loss
fake_A = fake_A_buffer.push_and_pop(fake_A)
pred_fake = netD_A(fake_A.detach())
loss_D_fake = criterion_GAN(pred_fake, target_fake)
# Total loss
loss_D_A = (loss_D_real + loss_D_fake)*0.5
loss_D_A.backward()
optimizer_D_A.step()
###################################
###### Discriminator B ######
optimizer_D_B.zero_grad()
# Real loss
pred_real = netD_B(real_B)
loss_D_real = criterion_GAN(pred_real, target_real)
# Fake loss
fake_B = fake_B_buffer.push_and_pop(fake_B)
pred_fake = netD_B(fake_B.detach())
loss_D_fake = criterion_GAN(pred_fake, target_fake)
# Total loss
loss_D_B = (loss_D_real + loss_D_fake)*0.5
loss_D_B.backward()
optimizer_D_B.step()
###################################
# Progress report (http://localhost:8097)
logger.log({'loss_G': loss_G, 'loss_G_identity': (loss_identity_A + loss_identity_B), 'loss_G_GAN': (loss_GAN_A2B + loss_GAN_B2A),
'loss_G_cycle': (loss_cycle_ABA + loss_cycle_BAB), 'loss_D': (loss_D_A + loss_D_B)},
images={'real_A': real_A, 'real_B': real_B, 'fake_A': fake_A, 'fake_B': fake_B})
# 更新学习率
lr_scheduler_G.step()
lr_scheduler_D_A.step()
lr_scheduler_D_B.step()
# Save models checkpoints
torch.save(netG_A2B.state_dict(), 'output/netG_A2B.pth')
torch.save(netG_B2A.state_dict(), 'output/netG_B2A.pth')
torch.save(netD_A.state_dict(), 'output/netD_A.pth')
torch.save(netD_B.state_dict(), 'output/netD_B.pth')
###################################复制
test
测试模块部分代码和训练模块类似
###### 定义变量######
#以下部分和train模块中写法类似
# 初始化生成器,由于是测试,因此无需判别器
netG_A2B = Generator(opt.input_nc, opt.output_nc)
netG_B2A = Generator(opt.output_nc, opt.input_nc)
if opt.cuda:
netG_A2B.cuda()
netG_B2A.cuda()
# 加载模型权重
netG_A2B.load_state_dict(torch.load(opt.generator_A2B))
netG_B2A.load_state_dict(torch.load(opt.generator_B2A))
# 设置模型为train模式
netG_A2B.eval()
netG_B2A.eval()
# 内存分配
Tensor = torch.cuda.FloatTensor if opt.cuda else torch.Tensor
input_A = Tensor(opt.batchSize, opt.input_nc, opt.size, opt.size)
input_B = Tensor(opt.batchSize, opt.output_nc, opt.size, opt.size)
# Dataset loader
transforms_ = [ transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5)) ]
dataloader = DataLoader(ImageDataset(opt.dataroot, transforms_=transforms_, mode='test'),
batch_size=opt.batchSize, shuffle=False, num_workers=opt.n_cpu)
###################################
###### 测试 ######
# 若输出文件夹不存在,则创建之
if not os.path.exists('output/A'):
os.makedirs('output/A')
if not os.path.exists('output/B'):
os.makedirs('output/B')
for i, batch in enumerate(dataloader):
# 两个域中的真实图像
real_A = Variable(input_A.copy_(batch['A']))
real_B = Variable(input_B.copy_(batch['B']))
#由于做了标准化,生成器生成的tensor的取值范围为[-1,1]
#所以做了个变换,将取值恢复到[0,1],这才是用tensor表示的图像
# A->B
fake_B = 0.5*(netG_A2B(real_A).data + 1.0)
# B->A
fake_A = 0.5*(netG_B2A(real_B).data + 1.0)
# 保存生成的图像
save_image(fake_A, 'output/A/%04d.png' % (i+1))
save_image(fake_B, 'output/B/%04d.png' % (i+1))
sys.stdout.write('\rGenerated images %04d of %04d' % (i+1, len(dataloader)))
sys.stdout.write('\n')
###################################复制
参考:
[1][https://livebook.manning.com/book/gans-in-action/chapter-9/64] [2][https://www.youtube.com/watch?v=9N_uOIPghuo] [3][https://openaccess.thecvf.com/content_ICCV_2017/papers/Zhu_Unpaired_Image-To-Image_Translation_ICCV_2017_paper.pdf] [4][https://github.com/aitorzip/PyTorch-CycleGAN]
 快点
快点
