




01
前言
用过MySQL的同学肯定都知道表联接,关键字即为 join
,使用的场景就是“当只查询一个表的信息不能满足我们需求”的时候,就需要用到两个甚至多个表联接查询。但是当不了解表联接的实现逻辑时,可能会有这样两个误区:
1. 只要业务需要,就随便关联表查询,能查到数据就行;
2. 曾经用表联接产生了SQL慢查询,被警告后再也不敢用了;
其实,究其原因只是对表联接的不熟悉,接下来咱们就一起跟着文章探索表联接的过程。在这之前我们需要带着下面几个问题:
1. 表联接是怎样实现的,是一个什么样的过程?
2. 业务中到底要不要用表联接?
3. 使用表联接会有什么样的问题,怎样避免和优化?
02
准备内容
这里我们需要用到3个表,这3个表都有一个主键索引 id 和一个索引 a,字段 b 上无索引。存储过程 idata() 往表 t1 里插入的是 100 行数据,表 t2、t3 里插入了 1000 行数据。建表语句如下:
CREATE TABLE `t1` (`id` INT ( 11 ) NOT NULL,`t1_a` INT ( 11 ) DEFAULT NULL,`t1_b` INT ( 11 ) DEFAULT NULL,PRIMARY KEY ( `id` ),KEY `idx_a` ( `t1_a` )) ENGINE = INNODB;CREATE TABLE `t2` (`id` INT ( 11 ) NOT NULL,`t2_a` INT ( 11 ) DEFAULT NULL,`t2_b` INT ( 11 ) DEFAULT NULL,PRIMARY KEY ( `id` ),KEY `idx_a` ( `t2_a` )) ENGINE = INNODB;CREATE TABLE `t3` (`id` INT ( 11 ) NOT NULL,`t3_a` INT ( 11 ) DEFAULT NULL,`t3_b` INT ( 11 ) DEFAULT NULL,PRIMARY KEY ( `id` ),KEY `idx_a` ( `t3_a` )) ENGINE = INNODB;-- 向t1添加100条数据-- drop procedure idata;delimiter ;;create procedure idata()begindeclare i int;set i=1;while(i<=100)doinsert into t1 values(i, i, i);set i=i+1;end while;end;;delimiter ;call idata();-- 向t2添加1000条数据drop procedure idata;delimiter ;;create procedure idata()begindeclare i int;set i=101;while(i<=1100)doinsert into t2 values(i, i, i);set i=i+1;end while;end;;delimiter ;call idata();-- 向t2添加1000条数据,且t3_a列的值为倒叙drop procedure idata;delimiter ;;create procedure idata()begindeclare i int;set i=101;while(i<=1100)doinsert into t3 values(i, 1101-i, i);set i=i+1;end while;end;;delimiter ;call idata();复制
03
联接的过程和实现
首先我们用准备好的t1
和t2
两个表做常规联接数据展示,因为我们表中记录有点多,如果全部展示则有 100*1000=100000
条数据,太多了,所以我们只取每个表的前3条做为示例:
mysql root@localhost:test> select * from t1,t2 where t1.id<=3 and t2.id<=103;+----+------+------+-----+------+------+| id | t1_a | t1_b | id | t2_a | t2_b |+----+------+------+-----+------+------+| 1 | 1 | 1 | 101 | 101 | 101 || 2 | 2 | 2 | 101 | 101 | 101 || 3 | 3 | 3 | 101 | 101 | 101 || 1 | 1 | 1 | 102 | 102 | 102 || 2 | 2 | 2 | 102 | 102 | 102 || 3 | 3 | 3 | 102 | 102 | 102 || 1 | 1 | 1 | 103 | 103 | 103 || 2 | 2 | 2 | 103 | 103 | 103 || 3 | 3 | 3 | 103 | 103 | 103 |+----+------+------+-----+------+------+9 rows in setTime: 0.012s复制
01. 表联接的实现过程
由上面的结果可以看出,联接查询的过程就是把t1
表和t2
表中的每一条记录相互联接组成更大的集合,而这也是表联接的实现过程:
1.先取出两个表其中的一个表的一条符合条件的数据; 2.用上一步取到的数据,跟另一个表的数据去匹配,符合条件的才放入最终的结果集; 3.如此以上两个步骤,直到第一个表符合条件的数据全部取完。
这个先取数据的表就是驱动表
,另一个就是被驱动表
。
02. 嵌套循环联接
(Nested-Loop Join)
这个过程在形式上,就像我们程序中的嵌套循环类型,用伪代码表示就是:
foreach rows in t1 { #此处表示遍历满足对t1单表查询结果集中的每一条记录foreach rows in t2 { #此处表示对于某条t1表的记录来说,遍历满足对t2单表查询结果集中的每一条记录... #此处表示可能有更多表需要联接#如果满足联接条件,发送到客户端if row satisfies join conditions, send to client}}复制
所以这种联接执行方式称之为嵌套循环联接
((Simple)Nested-Loop Join
)算法,简称 NLJ, 这是最简单也是最笨拙的一种联接查询算法。
但是有个问题,嵌套循环联接
的步骤2
中可能需要访问多次被驱动表,而且如果访问方式都是全表扫描的话查询效率就会非常低, 但是查询t2
表其实就相当于一次单表扫描,我们可以利用索引来加快查询速度,这种算法又称为索引嵌套循环联接
(Index Nested-Loop Join
)。
03. 块嵌套循环联接
(Block Nested-Loop Join)
扫描一个表的过程其实是先把这个表从磁盘上加载到内存(Buffer Pool
)中,然后从内存中比较匹配条件是否满足。现实生活中的表可不像t1
、t2
这种只有几条记录,而是几百万、几千万甚至几亿条记录。那么内存里可能就存放不下表中所有的记录,每次访问被驱动表,被驱动表的记录会被加载到内存中,在内存中的每一条记录只会和驱动表结果集的一条记录做匹配,之后就会被从内存中清除掉。然后再从驱动表结果集中拿出另一条记录,再一次把被驱动表的记录加载到内存中一遍,周而复始,驱动表结果集中有多少条记录,就得把被驱动表从磁盘上加载到内存中多少次。所以在两表联接过程中,被驱动表可是要被访问好多次的,那就相当于要从磁盘上读好几次这个表,这个I/O
代价就非常大了,所以我们得想办法:尽量减少访问被驱动表的次数。
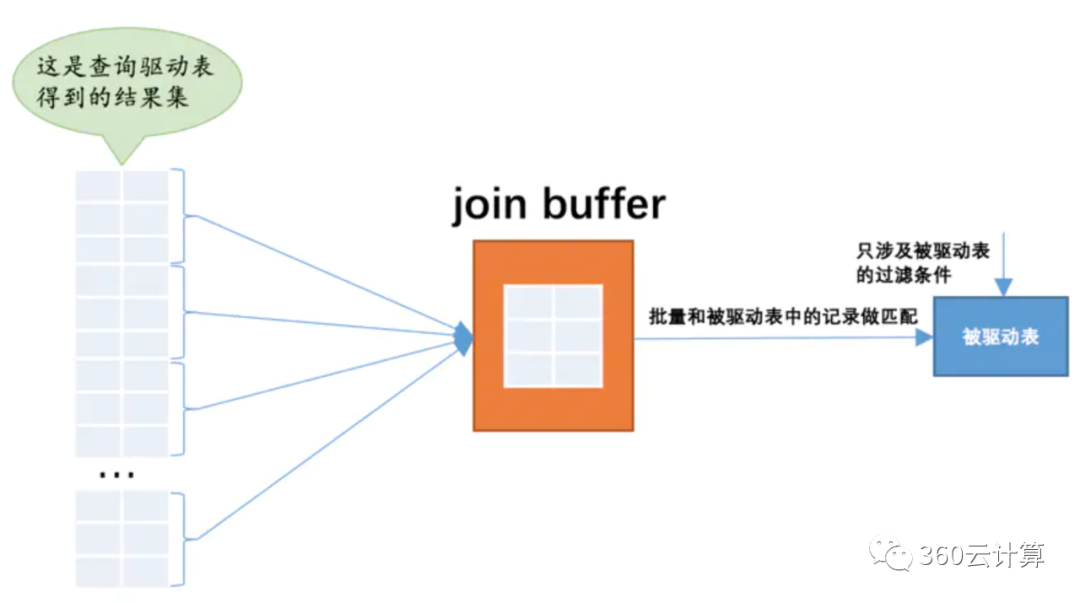
于是提出了一个join buffer
的概念,就是执行联接查询前申请的一块固定大小的内存,先把若干条驱动表结果集中的记录装在这个join buffer
中,然后开始扫描被驱动表,每一条被驱动表的记录一次性和join buffer
中的多条驱动表记录做匹配,因为匹配的过程都是在内存中完成的,所以这样可以显著减少被驱动表的I/O
代价。使用join buffer
的过程如下图所示:
最好的情况是join buffer
足够大,能容纳驱动表结果集中的所有记录,这样只需要访问一次被驱动表就可以完成联接操作了。设计MySQL
的大叔把这种加入了join buffer
的嵌套循环联接算法称之为块嵌套循环联接
(Block Nested-Loop Join)算法。
注意:
1. 驱动表的记录并不是所有列都会被放到join buffer
中,只有查询列表中的列和过滤条件中的列才会被放到join buffer
中,所以我们最好不要把*
作为查询列表,最好把真实用到的列作为查询列表
,这样还可以在join buffer
中放置更多记录。
2. 驱动表需要选择联接表中较小的表,或尽量使用筛选条件将表记录变得尽量少,这样可以减少join buffer
加载驱动表的次数。
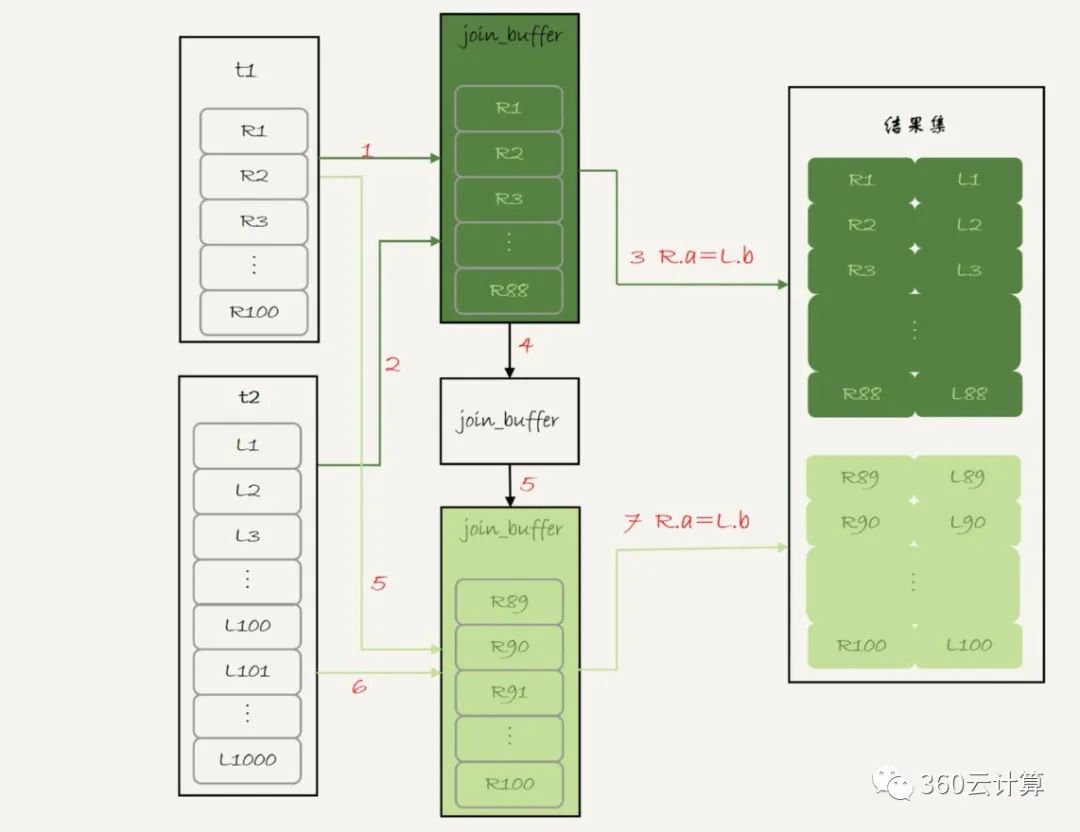
块嵌套循环联接的执行过程:
1. 扫描表 t1,顺序读取数据行放入 join_buffer 中,放完第 88 行 join_buffer 满了,继续第 2 步;
2. 扫描表 t2,把 t2 中的每一行取出来,跟 join_buffer 中的数据做对比,满足 join 条件的,作为结果集的一部分返回;
3. 清空 join_buffer;
4. 继续扫描表 t1,顺序读取最后的 12 行数据放入 join_buffer 中,继续执行第 2 步。(图中的步骤 4 和 5,表示清空 join_buffer 再复用。)
执行流程图:
04
批量键访问
(Batched Key Access)
01. Multi-Range Read 优化 (MRR)
虽然有了前面两个算法,但是这两个算法还是有可优化的空间的。在介绍优化方案之前,我们介绍一个知识点,即:Multi-Range Read 优化 (MRR)
。这个优化的主要目的是尽量使用顺序读盘。
我们来看一条SQL语句及其执行计划:
mysql root@localhost:test> select * from t3 where t3_a>=100 and t3_a<=200;+------+------+------+| id | t3_a | t3_b |+------+------+------+| 1001 | 100 | 1001 || 1000 | 101 | 1000 || 999 | 102 | 999 || 998 | 103 | 998 || 997 | 104 | 997 || 996 | 105 | 996 || 995 | 106 | 995 || 994 | 107 | 994 || 993 | 108 | 993 || 992 | 109 | 992 || 991 | 110 | 991 || 990 | 111 | 990 |...mysql root@localhost:test> explain select * from t3 where t3_a>=100 and t3_a<=200;+----+-------------+-------+-------+---------------+-------+---------+--------+------+-----------------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+-------+-------+---------------+-------+---------+--------+------+-----------------------+| 1 | SIMPLE | t3 | range | idx_a | idx_a | 5 | <null> | 101 | Using index condition |+----+-------------+-------+-------+---------------+-------+---------+--------+------+-----------------------+复制
上面我们可以看到,查询结果是按照索引idx_a
的顺序访问得到的结果,此时主键id的值为倒叙的,但是现实中按照索引idx_a
排序之后的主键id可能是乱序的。假设这样就会出现随机访问,性能相对较差。有什么解决办法呢?按照主键id重新排序就可以了。这就是 MRR 优化的设计思路。想要使用 MRR 优化,需要设置set optimizer_switch="mrr_cost_based=off"
。
我们看一下我们当前的设置:
mysql root@localhost:test> show variables like 'optimizer_switch';+------------------+-----------------------------------------------------------------------------------------------------------------| Variable_name | Value+------------------+-----------------------------------------------------------------------------------------------------------------| optimizer_switch | index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,subquery_materialization_cost_based=on,use_index_extensions=on复制
当我们开始MRR后再查询会得到以下结果:
mysql root@localhost:test> select * from t3 where t3_a>=100 and t3_a<=200;+------+------+------+| id | t3_a | t3_b |+------+------+------+| 901 | 200 | 901 || 902 | 199 | 902 || 903 | 198 | 903 || 904 | 197 | 904 || 905 | 196 | 905 || 906 | 195 | 906 || 907 | 194 | 907 || 908 | 193 | 908 || 909 | 192 | 909 || 910 | 191 | 910 |...mysql root@localhost:test> explain select * from t3 where t3_a>=100 and t3_a<=200;+----+-------------+-------+-------+---------------+-------+---------+--------+------+----------------------------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+-------+-------+---------------+-------+---------+--------+------+----------------------------------+| 1 | SIMPLE | t3 | range | idx_a | idx_a | 5 | <null> | 101 | Using index condition; Using MRR |+----+-------------+-------+-------+---------------+-------+---------+--------+------+----------------------------------+复制
02. Batched Key Access
理解了 MRR 性能提升的原理,我们就能理解 Batched Key Access(BKA)
算法了。
这个 BKA 算法,其实就是对 NLJ 算法的优化。
NLJ 算法执行的逻辑是:从驱动表 t1,一行行地取值,再到被驱动表 t2 去做 join。也就是说,对于表 t2 来说,每次都是匹配一个值。这时,MRR 的优势就用不上了。那怎么才能一次性地多传些值给表 t2 呢?方法就是,我们就把表 t1 的数据取出来一部分,先放到一个临时内存。这个临时内存不是别人,就是 join_buffer。通过q前面的介绍我们知道 join_buffer 在 BNL 算法里的作用,是暂存驱动表的数据。但是在 NLJ 算法里并没有用。那么,我们刚好就可以复用 join_buffer 到 BKA 算法中。
BKA算法的流程如下:
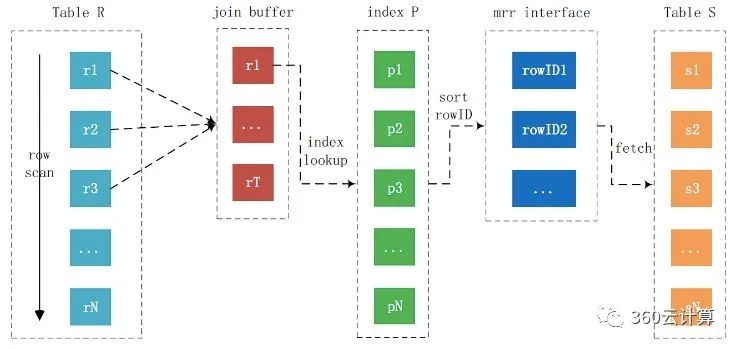
注意:
· BKA算法本质上还是NLJ算法,其发生的条件为被驱动表上有索引,并且该索引为非主键,并且联接需要访问被驱动表主键上的索引。
· BKA算法会调用MRR接口,批量的进行索引键的匹配,拿到主键id后进行排序,然后回表获取数据,此时随机IO变为顺序IO,以此来提高联接的执行效率。
那么,这个 BKA 算法到底要怎么启用呢?
需要在执行 SQL 语句之前,先设置set optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
其中,前两个参数的作用是要启用 MRR。
mysql root@localhost:test> explain select * from t3 left join t2 on t3.t3_a=t2.t2_a where t2.t2_a>=100 and t2.t2_a<=200;+----+-------------+-------+-------+---------------+-------+---------+--------------+------+----------------------------------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+-------+-------+---------------+-------+---------+--------------+------+----------------------------------------+| 1 | SIMPLE | t2 | range | idx_a | idx_a | 5 | <null> | 100 | Using index condition; Using MRR || 1 | SIMPLE | t3 | ref | idx_a | idx_a | 5 | test.t2.t2_a | 1 | Using join buffer (Batched Key Access) |+----+-------------+-------+-------+---------------+-------+---------+--------------+------+----------------------------------------+复制
说完了 NLJ 算法的优化,我们再来看 BNL 算法的优化。
我们执行语句之前,需要通过理论分析和查看 explain 结果的方式,确认是否要使用 BNL 算法。如果确认优化器会使用 BNL 算法,就需要做优化。
mysql root@localhost:test> explain select * from t1 join t2;+----+-------------+-------+------+---------------+--------+---------+--------+------+---------------------------------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+-------+------+---------------+--------+---------+--------+------+---------------------------------------+| 1 | SIMPLE | t1 | ALL | <null> | <null> | <null> | <null> | 100 | <null> || 1 | SIMPLE | t2 | ALL | <null> | <null> | <null> | <null> | 1000 | Using join buffer (Block Nested Loop) |+----+-------------+-------+------+---------------+--------+---------+--------+------+---------------------------------------+复制
优化的常见做法是:
给被驱动表的 join 字段加上索引,把 BNL 算法转成 BKA 算法,这是最好的情况。
如果是低频的 SQL 语句,为此创建一个索引有些浪费,但是不创建被驱动表需要扫描的条数比较多,待判断结果也需要进行很多次判断,非常耗CPU字段,这时就需要用到临时表,创建一个临时表temp_t,并且在临时表中创建所需字段索引,将驱动表与临时表temp_t进行联接即可;
如果驱动表和被驱动表联接时,需要判断的次数比较多,比如驱动表有数据1000条,被驱动表有10W条数据,那么一共就需要1000 * 100W = 10亿次判断;这时我们可以结合业务端构造hash判断,理论上效果要好于临时表的方案。实现思路:
3.1. 获取被驱动表的全部符合条件的数据,在业务端存入一个 hash 结构,比如PHP 的数组这样的数据结构。
3.2. 获取驱动表中满足条件的数据,然后遍历一行一行地到 hash 结构中匹配数据。满足匹配的条件的就作为结果集的一行。
05
业务中要不要用表联接
上面我们介绍了表联接的过程,那么我们平时到底可不可以用表联接?答案是,当然可以用!但是使用是有条件的,使用之前,我们先用explain对语句进行分析(就是看 explain 结果里面,Extra 字段里面有没有出现“Block Nested Loop”字样):
如果可以使用 Index Nested-Loop Join 算法,也就是说可以用上被驱动表上的索引,其实是没问题的;
如果使用 Block Nested-Loop Join 算法,扫描行数就会过多。尤其是在大表上的 join 操作,这样可能要扫描被驱动表很多次,会占用大量的系统资源。所以这种 join 尽量不要用。或者经过修改再使用。
反过来想,如果我们不用表联接,那我们就只能用单表查询。我们再看看上面嵌套循环联接中语句的需求,用单表查询怎么实现:
联表查询语句:
select * from t1 join t2 on t1.a=t2.a;复制
单表查询过程:
执行select * from t1,查出表 t1 的所有数据,假设这里有 100 行;
循环遍历这 100 行数据:
从每一行 R 取出字段 a 的值 $a;
执行select * from t2 where a=$a;
把返回的结果和 R 构成结果集的一行。
可以看到,在这个查询过程,也是扫描了 200 行,但是总共执行了 101 条语句,比直接 join 多了 100 次交互。除此之外,客户端还要自己拼接 SQL 语句和结果。显然,这么做还不如直接 join 好。
06
总结
经过上面的分析,我们能发现联接查询成本占大头的就是“驱动表记录数 乘以 单次访问被驱动表的成本”,所以我们的优化重点其实就是下面这两个部分:
尽量减少驱动表的记录数
对被驱动表的访问成本尽可能降低


