




央视来拍纪录片了,应该能在电视上看到我了;
so,用什么eclipse写代码,IDEA才是正规军,不做杂牌军,走上人生巅峰。
1、在IDEA中创建Spark工程,常规操作: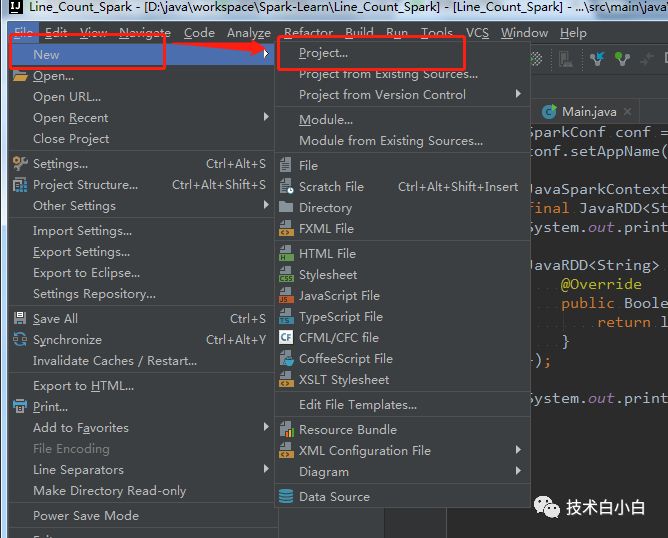
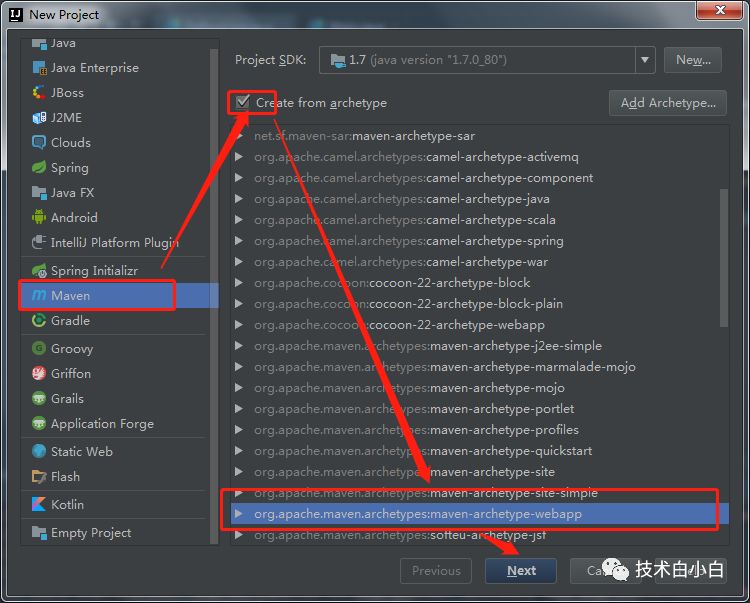
2、其他操作可以参考一篇Spark 学习系列三: Setup Apache Spark in eclipse JAVA
3、也可以直接导入maven工程,上一篇中的代码已经上传我的github仓库,地址Line_Count_Spark:https://github.com/baymux/Spark-Learn/tree/master/Line_Count_Spark
下载之后可以直接导入:
下载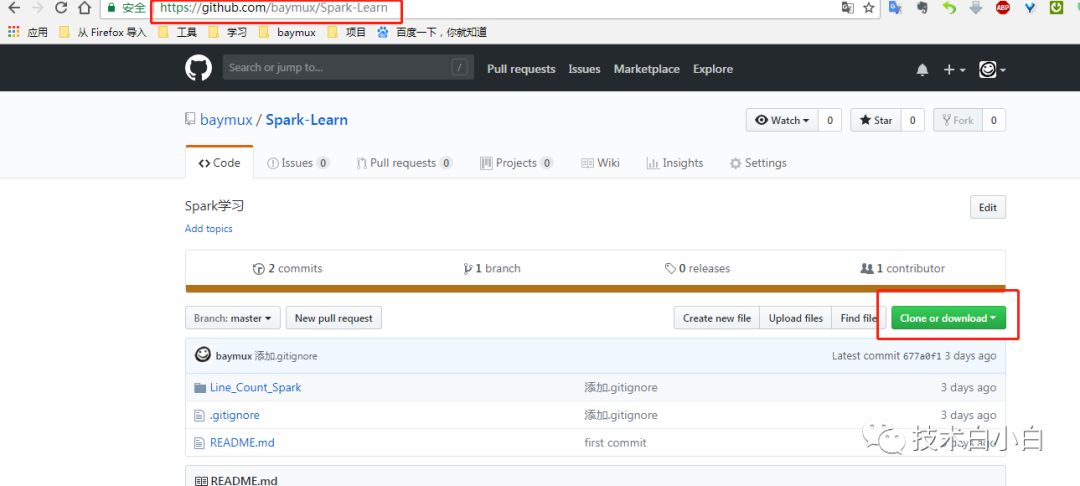
也可以通过IDEA直接导入: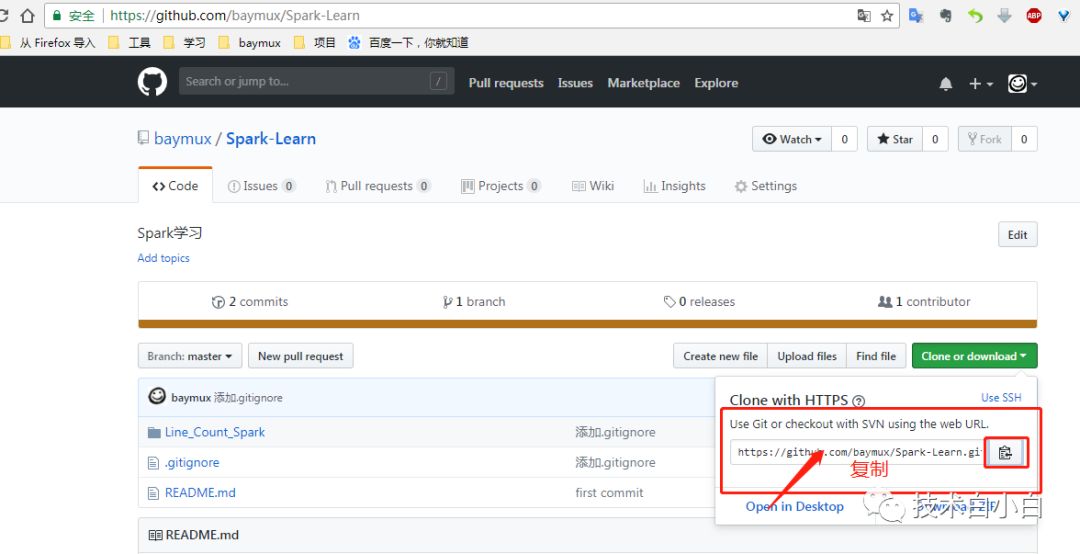
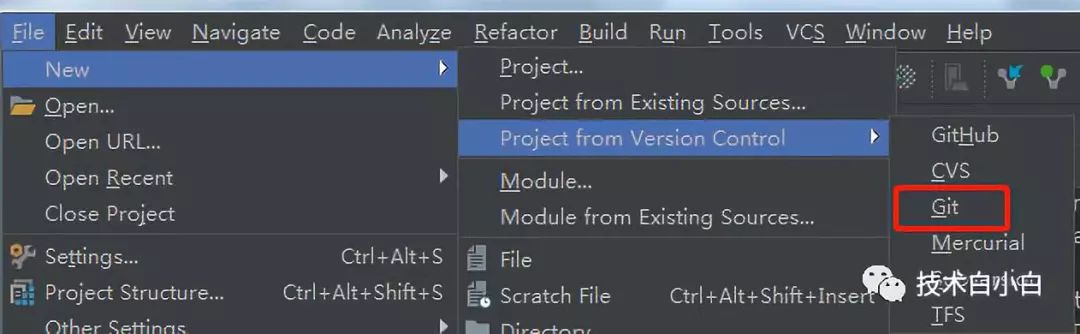
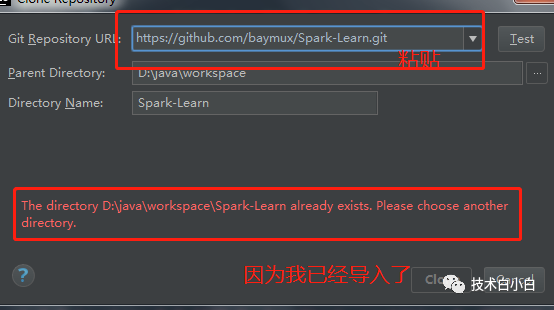
这样,我们的完整工程就创建好了。
在IDEA中运行Spark。一般我们的代码要编译成jar包,提交到Spark去运行,这样很容易出错,并且不便于debug,因此我们要在IDEA中直接运行Spark程序。
1、设置 Spark 运行环境
代码已经提交至github;
package com.baymux.spark;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;import org.apache.spark.api.java.function.Function;/** * Created by baymux on 2018/7/9 * 计算文件中包含 python 的行数 * * @author baymux **/public class PythonLine { public static void main(String[] args) { SparkConf conf = new SparkConf(); conf.setAppName("Python Line"); JavaSparkContext context = new JavaSparkContext(conf); final JavaRDD<String> textFileRDD = context.textFile("D:\\spark\\README.md"); System.out.println(textFileRDD.count()); JavaRDD<String> pythonLines = textFileRDD.filter(new Function<String, Boolean>() { @Override public Boolean call(String line) throws Exception { return line.contains("python"); } }); System.out.println(pythonLines); } }复制
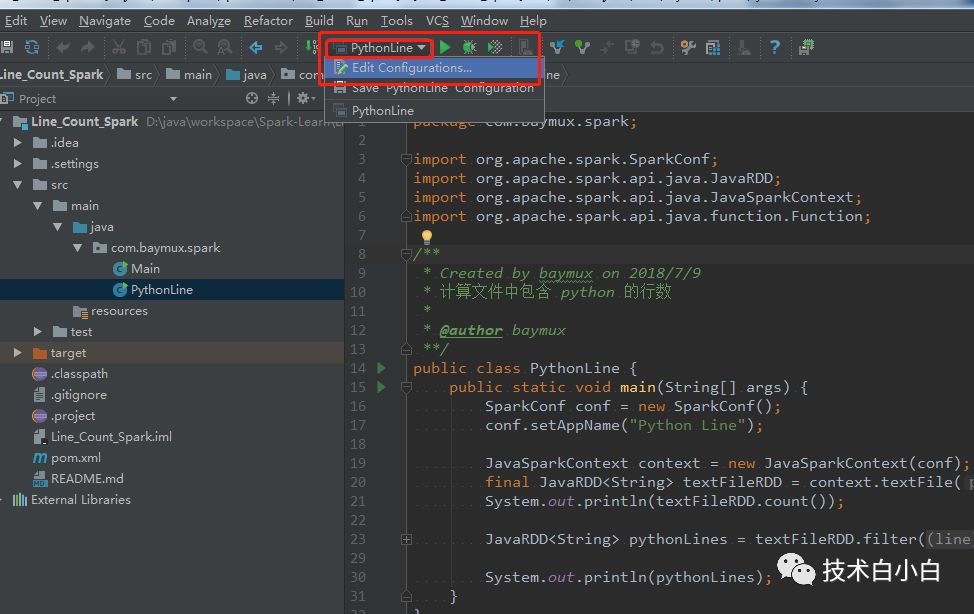
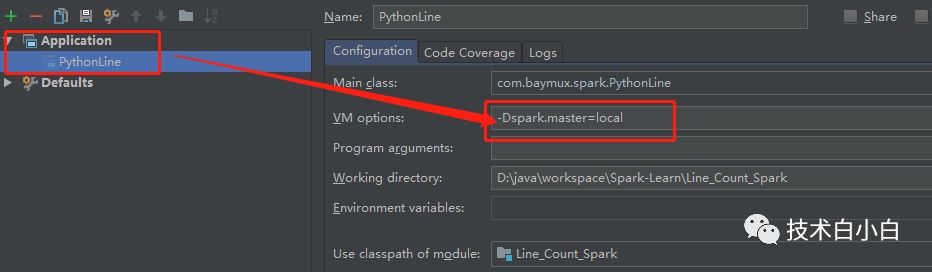
OK,我们可以正常运行Spark程序了。
ps : 但是会出现java.io.IOException: Could not locate executablenull\bin\winutils.exe in the Hadoop binaries. 异常,我们是下载了winutils.exe文件的,但是没有找到路径。
分析源代码:我们看到 HADOOP_HOME_DIR这个变量为 null,
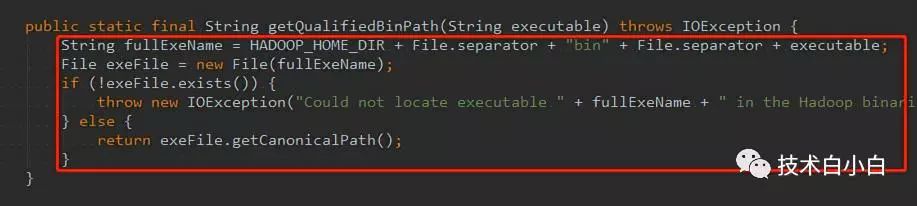
由此我们看到HADOOP_HOME_DIR由checkHadoopHome()这个方法获取。

由此我们可以看到,是由于获取系统环境变量是为null,但是我们在安装的时候配置了Hadoop的环境变量,因此怀疑是没有重启电脑造成的
重启电脑,问题解决;
运行如下: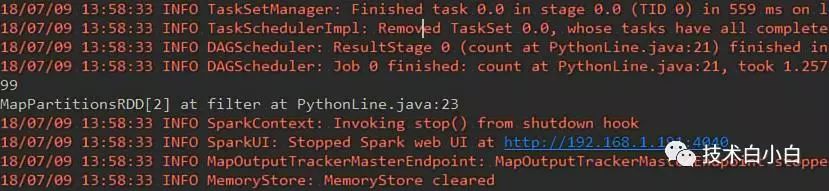
THE END;
github地址:https://github.com/baymux/Spark-Learn
