




0. 前言
使用PGBouncer作为PG的连接池进行压测,压测指标一直上不去,会是什么原因。本文带你详细探讨测试过程并解决这个问题。
近期有个客户想看看高并发下PG16能支撑多高的活动并发请求,以及高并发下可以达到什么样的tps。
于是想到用PGBench进行压力测试。
1. PG安装和配置
1.1 安装PG16
找来两台机器,一台作为服务器端,另一台作为压测客户端
分别安装pg16
- 下载源码
wget https://ftp.postgresql.org/pub/source/v16.3/postgresql-16.3.tar.gz复制
- 解压
tar xf postgresql-16.3.tar.gz复制
- 安装
cd postgresql-16.3 ./configure make && make install复制
安装后同时也就有了pgbench
1.2 初始化PG
数据库服务器端使用nvme盘,挂载目录为 /data。
初始化数据库:
initdb --PGDATA=/data复制
1.3 简单调整PG参数
- 操作系统级别设置ulimit open_files为999999
- 设置shared_buffers为物理内存一半
- 设置listener_address为’*’
- 设置max_connections为20000
2. 测试工具PGBench 介绍
2.1 PGBench简单介绍
- PGBench是PG内置的性能测试工具,安装好的PG里面默认包含PGBench的可执行文件。
- 可以通过调整数据量大小和并发数量来对数据库的能力做一个评估。
- 默认情况下的压测模型是TPC-B, 里面包含五个SELECT、UPDATE以及INSERT命令。
2.2 PGBench主要参数介绍
2.2.1 通用参数
- -h <服务器地址> -p <端口> -U<用户名>
- 前面不带“-”选项的 <数据库名>
- 隐藏的密码参数
这里隐藏了一个密码的参数,不能在命令行输入,但可以在SHELL中以环境变量形式定义PGPASSWORD, 就可以把密码传过去。否则,需要在运行时手动输入密码。
2.2.2 初始化时参数
- -i
这个是初始化的意思,会把表结构建起来,并插入数据。 - -s <数据膨胀因子>
这个是指数据量的大小,-s后面跟的数字越大,数据量就越大。
-s 1代表10万条记录,-s n就是n个10万条记录。
2.2.3 压测时参数
-
-j <线程数>
这个指的是pgbench会起多少个线程进行压测。 -
-c <会话>
这个指的是pgbench会起多少个会话进行压测,注意,这个和-j的线程数要结合来看,作用更大的其实是-j。由于PGBench发送请求是以线程去实施的,如果-c大于-j, PGBench也只能在-j线程数指定的范围内去排队发送。因此,数据库的实际活动(active) 并发会话也是最多只能到“-j指定的线程数”。 -
-T <运行秒数>
这个代表运行的时长
3. 进行压力测试
3.1 初始化数据
在服务器端创建数据库用户和数据库
psql
drop database if exists pgbs5000;
create database pgbs5000;
\c pgbs5000
drop user if exists pgbench ;
create user pgbench password 'Test@123';
grant all on database pgbs5000 to pgbench ;
create schema pgbench ;
alter schema pgbench owner to pgbench;
复制初始化数据, 这里选择5000的膨胀因子。相当于主表有5亿条记录。
HOST=192.168.88.101 # 服务器IP
PGPORT=5432 # 端口号
DBNAME=pgbs5000 #数据库名称
DBUSER=pg16 #登录用户
export PGPASSWORD=Test@123 #密码,作为环境变量
SCALE=5000
pgbench -i -s $SCALE -U$DBUSER -h $HOST -p $PGPORT $DBNAME
dropping old tables...
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
creating tables...
generating data (client-side)...
500000000 of 500000000 tuples (100%) done (elapsed 520.60 s, remaining 0.00 s))
vacuuming...
creating primary keys...
done in 774.01 s (drop tables 0.00 s, create tables 0.21 s, client-side generate 525.27 s, vacuum 1.15 s, primary keys 247.38 s).
复制查看数据库大小:
psql -c "select pg_size_pretty(pg_database_size('pgbs5000'));"
pg_size_pretty
----------------
75 GB
复制数据库大小为75GB。
3.2 测试单个并发
先选一个并发进行测试,这里选择16
HOST=192.168.88.101 # 服务器IP
PGPORT=5432 # 端口号
DBNAME=pgbs5000 #数据库名称
DBUSER=pgbench #登录用户
export PGPASSWORD=Test@123 #密码,作为环境变量
pgbench -r -T$RUNSEC $DBNAME -U$DBUSER -h $HOST -p $PGPORT -c16 -j16
复制测试结果,其中最主要的指标便是tps了。
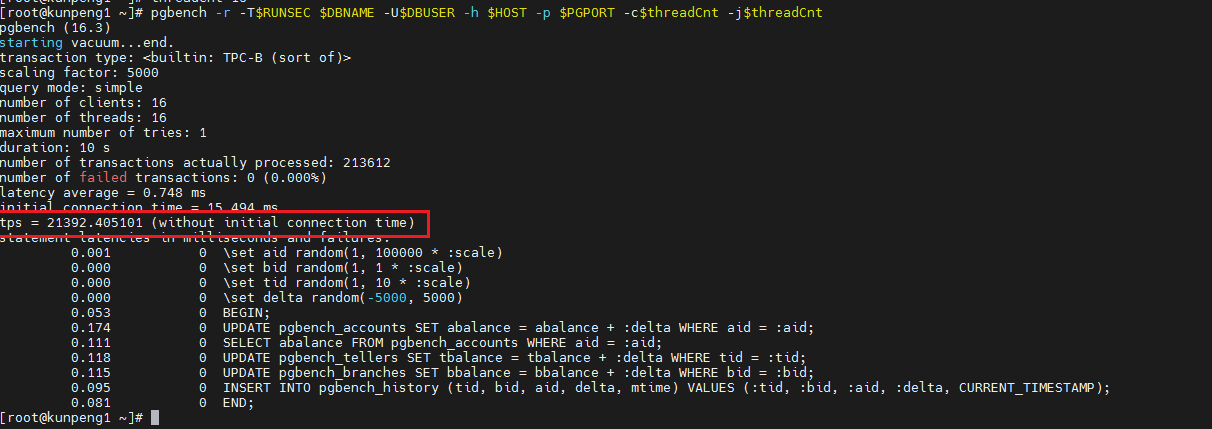
测试结果是16并发下21392的tps.
3.3 分不同并发进行测试
为了方便,直接写脚本进行多个并发测试,只输出并发数和TPS值。
由于主机是128 core, 因此并发选择这些:
16 32 64 128 192 256 384 512 768 1000 1500 2000 2500 3000 4000 5000 6000 7000 8000 9000 10000 11000 12000
HOST=192.168.88.101 # 服务器IP
PGPORT=5432 # 端口号
DBNAME=pgbs5000 #数据库名称
DBUSER=pgbench #登录用户
export PGPASSWORD=Test@123 #密码,作为环境变量
RUNSEC=60 # 运行时间
THREADS="16 32 64 128 192 256 384 512 768 1000 1500 2000 2500 3000 4000 5000 6000 7000 8000 9000 10000 11000 12000"
for threadCnt in $THREADS ; do #逐个并发
tps=`pgbench -r -T$RUNSEC $DBNAME -U$DBUSER -h $HOST -p $PGPORT -c$threadCnt -j$threadCnt 2>&1 |awk '/tps/{print $3}'`
echo "concurrent: $threadCnt ,tps: ${tps:-0}"
done
复制3.4 测试结果
多个并发结果如下:

把测试数据放到Excel, 进行简单画图
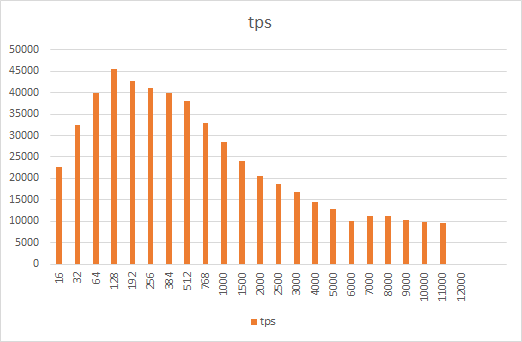
可以看出,结果并不理想,超过128并发后明显性能下降,且部分已经跑不出来。
另外,从结果中可以看到,128并发时可以达到最佳效果。(这里没有针对PGBench的其他选项进行优化,包括分区表等)
原因大概就是高并发下PG内部的争用针对,反而影响了性能的进一步提升。
4. 加上PGBouncer进行测试
这时候想到PG有个有名的连接池软件 PGBouncer,可以限制直连到数据库的并发,应该可以提高。
4.1 PGBouncer介绍
PGBouncer是一个轻量化的PostgreSQL连接池,在短连接应用盛行的时代很流行。
任何目标应用程序都可以像连接PostgreSQL服务器一样连接到PGBouncer,并且PGBouncer将创建到实际服务器的连接,或者从连接池中获取并重用其现有的连接。
4.2 PGBouncer安装
下载
wget http://www.pgbouncer.org/downloads/files/1.22.1/pgbouncer-1.22.1.tar.gz复制
安装依赖包
yum install -y libevent libevent-devel pkg-config openssl openssl-devel复制
解压并安装
tar xf pgbouncer-1.22.1.tar.gz
cd pgbouncer-1.22.1
./configure
make
复制4.3 PGBouncer配置参数介绍
PGBouncer的参数通过一个ini文件进行指定。需要在启动的时候指定该文件。
示例及重要参数如下
[pgbouncer]
pool_mode=transaction
default_pool_size=256
listen_port = 6432
listen_addr = 192.168.88.101
max_client_conn=100000
max_db_connections=1024
pidfile=pgbouncer.pid
logfile=pgbouncer.log
auth_user=pg16
[databases]
pgbs5000 = host=/tmp port=5432 dbname=pgbs5000 pool_size=256
复制其中包含两大类通用参数和连接池参数。当然,还有其他更精细配置的参数,篇幅原因,就不一一细说了。具体可参考 pgbouncer官方文档
4.3.1 通用参数
通用参数放在[pgbouncer]下
-
pool_mode
这个是很重要的参数,代表了应用连到PGBouncer之后,PGBouncer如何给应用分配真正的数据库连接
它有三个选项,包括
– session
当客户端连接时,服务器连接将在整个客户端连接期间分配给它。当客户端断开连接时,服务器连接将被放回池中。这是默认方法。
– Transaction
服务器连接只在事务期间分配给客户端。当PgBouncer注意到事务结束时,服务器连接将被放回池中。
– Statement
查询完成后,服务器连接将立即放回池中。在此模式下不允许多语句事务,因为它们会中断。
对于PGBench测试来说,第一个显然不合适,因为那样就起不到限制最高并发的作用。而第三个更是跑不通,因为PGBench默认压测模型下,一个默认事务里面包含了5个SQL语句。所以,我们需要把这个值设为Transaction。 -
default_pool_size
这个参数代表在不专门指定的情况下,连接池的默认大小。 -
max_db_connections=32
这个参数代表连接到数据库的最大会话数,和上面的区别在于,多个数据库连接池可以指向同一个实体的PostgreSQL数据库, 可以通过这个参数避免连接过多。 -
max_client_conn=100000
这个指的是最多有多少客户端可以连到 PGBouncer上。 -
listen_addr = 192.168.88.101
-
listen_port = 6432
这两个指的是暴露给应用的主机IP和端口。当然,这个listen_addr 必须是本主机上有的ip地址。listen_port 未被其他应用占用。 -
pidfile=pgbouncer.pid
这个参数指向一个文件名,文件用于记录PGBouncer进程的pid -
logfile=pgbouncer.log
这个参数指向一个文件名,文件用于记录PGBouncer的日志 -
auth_user
这个用户指定当客户端连接到PGBouncer时需要进行用户认证,认证时PGBouncer到实际库获取加密后的密码的用户。多数情况下,PGBouncer可以和实际库放在同一操作系统用户下,而这个auth_user可以设为PG的初始化用户,因此可以免密去获取加密后的密码信息。
4.3.2连接池参数
连接池参数放在 [databases]下。
写法是
<数据库名>=<真实数据库连接串> <其他连接池参数>复制
比如
pgbs5000 = host=/tmp port=5432 dbname=pgbs5000 pool_size=128复制
表示应用可以以pgbs5000 为dbname连接到“/tmp port=5432 dbname=pgbs5000”对应的PG数据库上。而这个连接池可提供128个真实连接连接。
为了达到高性能的目的,建议把PGBouncer部署在和真实PG数据库同一台主机,并通过 UNIX_SOCKET进行连接,如示例中的"/tmp"。
其他的主要连接池参数包括:
- pool_mode
和上面通用参数的pool_mode一个含义,代表连接池模式 - pool_size
和上面通用参数的default_pool_size一个含义,代表连接池最大的连接数
4.4 启动PGBouncer
最终使用PGBouncer的ini文件如下:
pgbouncer.ini
[pgbouncer]
pool_mode=transaction
default_pool_size=128
listen_port = 6432
listen_addr = 192.168.88.101
max_client_conn=100000
max_db_connections=1024
pidfile=pgbouncer.pid
logfile=pgbouncer.log
auth_user=pg16
[databases]
pgbs5000 = host=/tmp port=5432 dbname=pgbs5000 pool_size=128
pbgs750g = host=/tmp port=5432 dbname=pbgs750g pool_size=128
复制启动,注意命令行中有个 -d, 代表后台模式启动
./pgbouncer -d ./pgbouncer.ini复制
4.5 通过PGBouncer对PG进行压测
稍微修改脚本,把PGPORT从5432改成6432, 即可进行批量压测
HOST=192.168.88.101 # 服务器IP
PGPORT=6432 # 端口号,注意这里改成PGBoucer的端口号
DBNAME=pgbs5000 #数据库名称
DBUSER=pgbench #登录用户
export PGPASSWORD=Test@123 #密码,作为环境变量
RUNSEC=60 # 运行时间
THREADS="16 32 64 128 192 256 384 512 768 1000 1500 2000 2500 3000 4000 5000 6000 7000 8000 9000 10000 11000 12000"
for threadCnt in $THREADS ; do #逐个并发
tps=`pgbench -r -T$RUNSEC $DBNAME -U$DBUSER -h $HOST -p $PGPORT -c$threadCnt -j$threadCnt 2>&1 |awk '/tps/{print $3}'`
echo "concurrent: $threadCnt ,PGBouncer tps: ${tps:-0}"
done
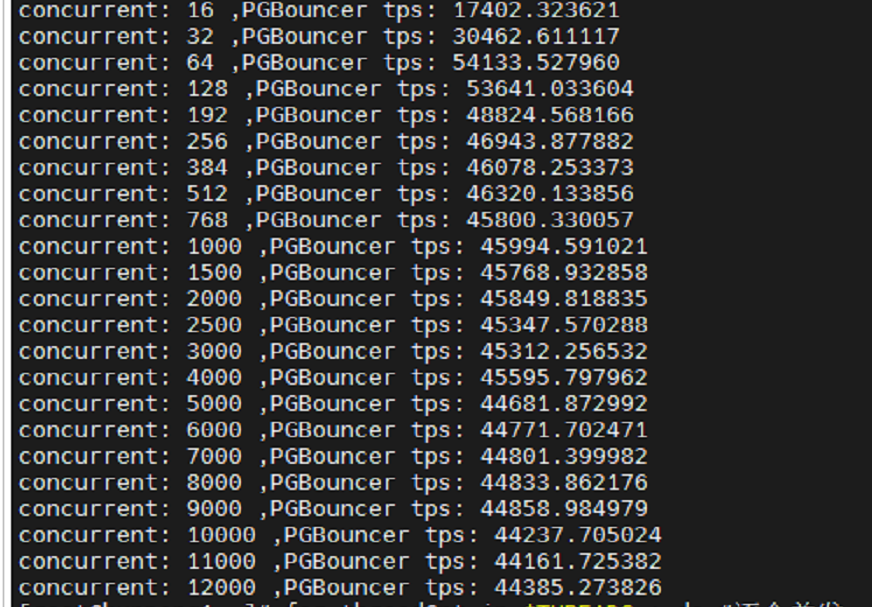
复制结果很不理想

基本都在1万tps左右。并发的增加似乎没有提高性能。
对比PG直连的效果,最高衰减达到80%。显然不应该是一个“轻量级”的连接池该有的表现。
那么问题可能在什么地方呢?
5. 优化PGBouncer
5.1 检查瓶颈
使用Top看看CPU和进程的状态。
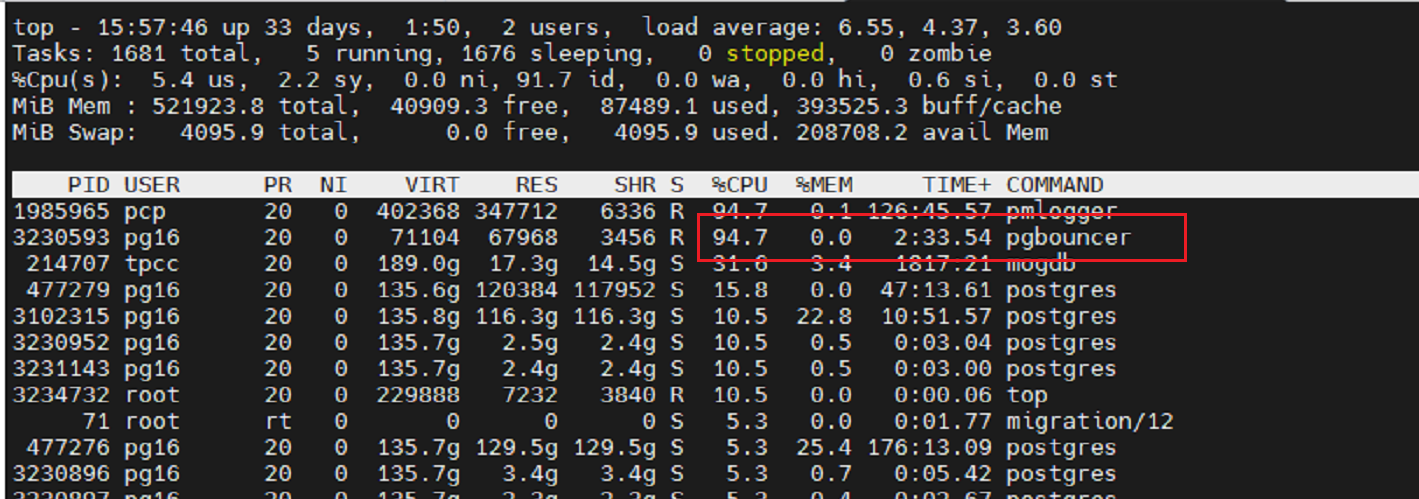
这里可以发现,PGBouncer 进程的CPU接近100%。且看起来只有一个进程在跑。
难道PGBouncer没有采用多线程或者多进程模式,只用一个线程来转发请求?
进一步检查它的进程情况:
pidof pgbouncer复制

是单进程
检查线程
pstree -t -p `pidof pgbouncer`复制

难以置信,竟然用一个单进程单线程的软件来作为连接池?
那就怪不得tps上限很低了。
5.2 让PGBouncer多进程跑起来
又仔细检查了一圈官方文档,才发现一个名字看着完全和多进程、多线程无关的参数:
so_reuseport (http://www.pgbouncer.org/config.html)
so_reuseport
Specifies whether to set the socket option SO_REUSEPORT on TCP listening sockets. On some operating systems, this allows running multiple PgBouncer instances on the same host listening on the same port and having the kernel distribute the connections automatically. This option is a way to get PgBouncer to use more CPU cores. (PgBouncer is single-threaded and uses one CPU core per instance.)
The behavior in detail depends on the operating system kernel. As of this writing, this setting has the desired effect on (sufficiently recent versions of) Linux, DragonFlyBSD, and FreeBSD. (On FreeBSD, it applies the socket option SO_REUSEPORT_LB instead.) Some other operating systems support the socket option but it won’t have the desired effect: It will allow multiple processes to bind to the same port but only one of them will get the connections. See your operating system’s setsockopt() documentation for details.
On systems that don’t support the socket option at all, turning this setting on will result in an error.
Each PgBouncer instance on the same host needs different settings for at least unix_socket_dir and pidfile, as well as logfile if that is used. Also note that if you make use of this option, you can no longer connect to a specific PgBouncer instance via TCP/IP, which might have implications for monitoring and metrics collection.
To make sure query cancellations keep working, you should set up PgBouncer peering between the different PgBouncer processes. For details look at docs for the peer_id configuration option and the peers configuration section. There’s also an example that uses peering and so_reuseport in the example section of these docs.
so_reuseport的作用是让PGBouncer启动并监听网络端口时增加Socket选项SO_REUSEPORT ,这个选项允许多个进程在同一个端口上进行监听
根据文档描述,可以手动起多个PGBouncer进程,监听同一端口,但要设置so_reuseport=1且需要设置不同的unix_socket_dir、pidfile和logfile参数。
很奇怪的是,官方文档竟然没有把非常重要的这个多进程能力作为单独章节或者目录项来描述。国内技术文章也没有单独作为一个文章来描述。这也是我为什么专门写这么一篇文章的重要原因。
5.3 脚本自动生成多个PGBouncer进程
根据目前的数据,PG直连可以4.5万tps, 而单个PGBouncer进程可以提供1万左右的tps, 因此,可以考虑用8个或者16个单独的PGBouncer来作为连接池。
显然,手动去生成8个或者16个配置文件并组个启动太费劲了。下面用脚本来批量创建。
第一步,创建一个通用的 ini文件,比如名字叫pgboucerbase.ini, 里面包含一些通用的配置。但不包含unix_socket_dir、pidfile和logfile。注意把[pgbouncer]放在所有Section的最后面
另外,由于使用了多个进程,要考虑降低pool_size和max_db_connections的值,不然并发量可能会涨得太多。
pgboucerbase.ini
[databases]
pgbs5000 = host=/tmp port=5432 dbname=pgbs5000 pool_size=16
pbgs750g = host=/tmp port=5432 dbname=pbgs750g pool_size=16
[pgbouncer]
pool_mode=transaction
default_pool_size=16
listen_port = 6432
listen_addr = 192.168.88.101
max_client_conn=100000
max_db_connections=32
auth_user=pg16
复制在PGBouncer同一目录下写个脚本,接收两个参数,分别是启动的并发进程数量和通用参数文件名。
如pgb-mulit.sh
#!/bin/bash
function usage(){
echo "Usage: $0 <processCount> <baseIniFile>"
}
if [ $# -lt 2 ] ; then
usage
exit
fi
if [ ! -f $2 ] ; then
echo "File $2 does not exists"
usage
exit
fi
ProcessCnt=$1
BASEINI=$2
usage
for i in `seq -w 1 $ProcessCnt ` ; do
SOCKDIR=/tmp/pgb_socket.${i}
INIFILE=${BASEINI}.${i}
mkdir -p $SOCKDIR
cp $BASEINI $INIFILE
cat >> $INIFILE <<EOF
unix_socket_dir=$SOCKFILE
logfile = pgbouncer.log.${i}
pidfile = pgbouncer.pid.${i}
so_reuseport =1
EOF
echo "Starting pgbouncer instance #i using ini file $INIFILE"
./pgbouncer -d $INIFILE
done
复制增加权限
chmod +x pgb-multi.sh复制
执行
./pgb-multi.sh 16 pgboucerbase.ini复制
启动后,就有了16个独立的PGBoucer进程提供连接池服务了。

5.4 压测PGBouncer多进程
使用和前面压测同样的脚本,进行压测
HOST=192.168.88.101 # 服务器IP
PGPORT=6432 # 端口号,注意这里改成PGBoucer的端口号
DBNAME=pgbs5000 #数据库名称
DBUSER=pgbench #登录用户
export PGPASSWORD=Test@123 #密码,作为环境变量
RUNSEC=60 # 运行时间
THREADS="16 32 64 128 192 256 384 512 768 1000 1500 2000 2500 3000 4000 5000 6000 7000 8000 9000 10000 11000 12000"
for threadCnt in $THREADS ; do #逐个并发
tps=`pgbench -r -T$RUNSEC $DBNAME -U$DBUSER -h $HOST -p $PGPORT -c$threadCnt -j$threadCnt 2>&1 |awk '/tps/{print $3}'`
echo "concurrent: $threadCnt ,PGBouncer tps: ${tps:-0}"
done
复制测试过程中Top结果
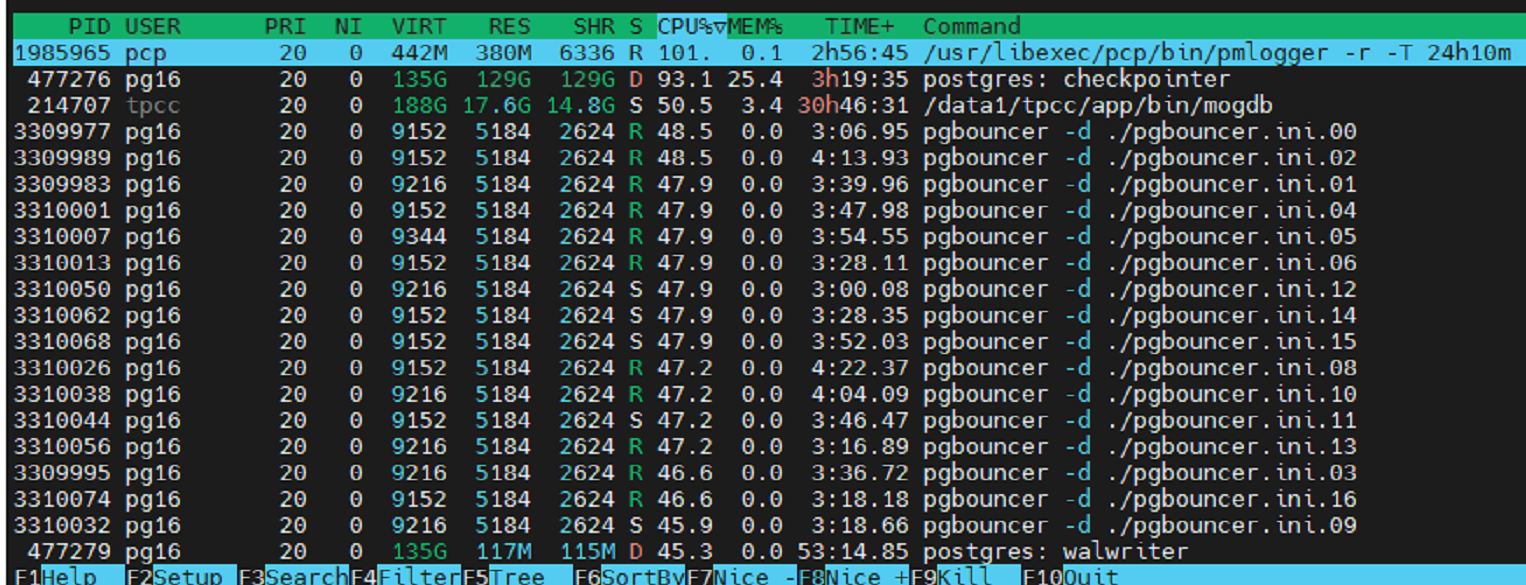
可以看到,每个PGBouncer的CPU占用率下来了,不再是瓶颈
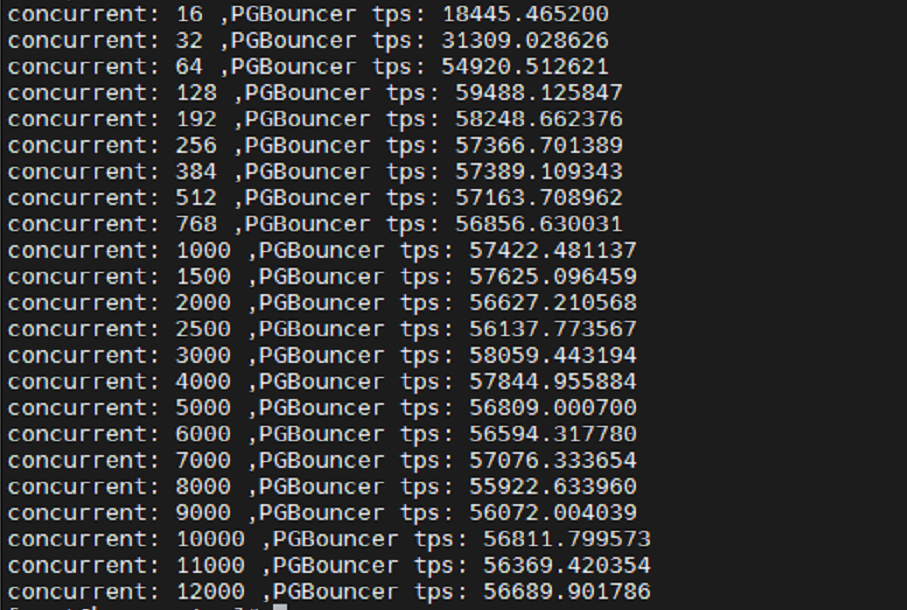
测试结果,高并发很稳定。
把测试结果和PG的放在一块
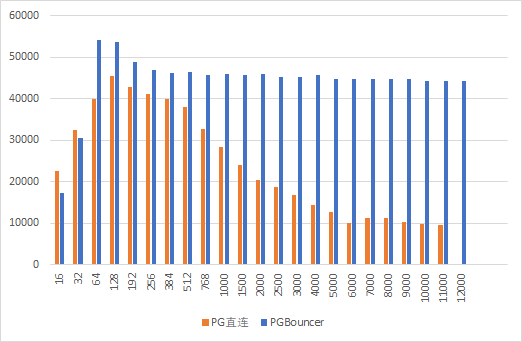
6. 最终测试结果
在上面的结果图,可以发现,在高并发下,PGBouncer并没有达到低并发的效果。原因是,启动16个进程的时候,当时每个进程设了16的pool_size,也就是总共用256个实际连接。根据PG的结果,最高值是出现在128个并发。因此,尝试降低为 每个进程对应8的pool_size, 这样就正好16*8=128。(当然,也可以考虑8个PGBouncer进程,每个进程16个pool_size, 效果应该类似)
6.1 pool_size=8的ini
pgb-base-pool8.ini, 改的pool_size=8
[databases]
pgbs5000 = host=/tmp port=5432 dbname=pgbs5000 pool_size=8
pbgs750g = host=/tmp port=5432 dbname=pbgs750g pool_size=8
[pgbouncer]
pool_mode=transaction
default_pool_size=16
listen_port = 6432
listen_addr = 192.168.88.101
max_client_conn=100000
max_db_connections=32
auth_user=pg16
复制6.2 重新启动PGBouncer
pkill -9 pgbouncer ./pgb-multi.sh 16 pgb-base-pool8.ini复制
6.3 重新启动测试
HOST=192.168.88.101 # 服务器IP
PGPORT=6432 # 端口号,注意这里改成PGBoucer的端口号
DBNAME=pgbs5000 #数据库名称
DBUSER=pgbench #登录用户
export PGPASSWORD=Test@123 #密码,作为环境变量
RUNSEC=60# 运行时间
THREADS="16 32 64 128 192 256 384 512 768 1000 1500 2000 2500 3000 4000 5000 6000 7000 8000 9000 10000 11000 12000"
for threadCnt in $THREADS ; do #逐个并发
tps=`pgbench -r -T$RUNSEC $DBNAME -U$DBUSER -h $HOST -p $PGPORT -c$threadCnt -j$threadCnt 2>&1 |awk '/tps/{print $3}'`
echo "concurrent: $threadCnt ,PGBouncer tps: ${tps:-0}"
done
复制6.4 调整后测试结果
Excel趋势图:
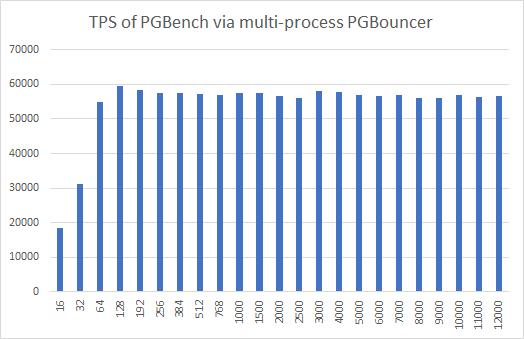
可以看到,高并发下的tps已经和最高tps值没有显著差距。
6.5 和PG直连的混合测试
为了避免由于多次测试,数据量变化,缓存变化等带来的影响,重新进行测试。
这次,每个不同并发,先连一次PGBouncer,得到tps,再直连PG, 得到tps, 这样最大限度避免数据量变化,缓存变化等带来的影响。
测试脚本如下
HOST=192.168.88.101 # 服务器IP
PGDirect_PORT=5432 # PG直连端口号
PGBoucer_PORT=6432 # PGBoucer端口号
DBNAME=pgbs5000 #数据库名称
DBUSER=pgbench #登录用户
export PGPASSWORD=Test@123 #密码,作为环境变量
RUNSEC=60# 运行时间
THREADS="16 32 64 128 192 256 384 512 768 1000 1500 2000 2500 3000 4000 5000 6000 7000 8000 9000 10000 11000 12000"
# 表头
printf "%20s %20s %20s\n" "Concurrent" "TPS_PGDirect" "TPS_PGBoucer"
for threadCnt in $THREADS ; do #逐个并发
# 使用PGBoucer端口号连接并获取tps
tps_pgbouncer=`pgbench -r -T$RUNSEC $DBNAME -U$DBUSER -h $HOST -p ${PGBoucer_PORT} -c$threadCnt -j$threadCnt 2>&1 |awk '/tps/{print $3}'`
# 使用PG直连端口号连接并获取tps
tps_pgdirect=`pgbench -r -T$RUNSEC $DBNAME -U$DBUSER -h $HOST -p ${PGDirect_PORT} -c$threadCnt -j$threadCnt 2>&1 |awk '/tps/{print $3}'`
# 输出结果
printf "%20s %20s %20s\n" ${threadCnt} ${tps_pgdirect:-0} ${tps_pgbouncer:-0}
done
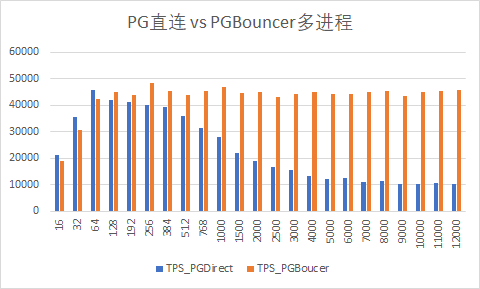
复制最终结果:
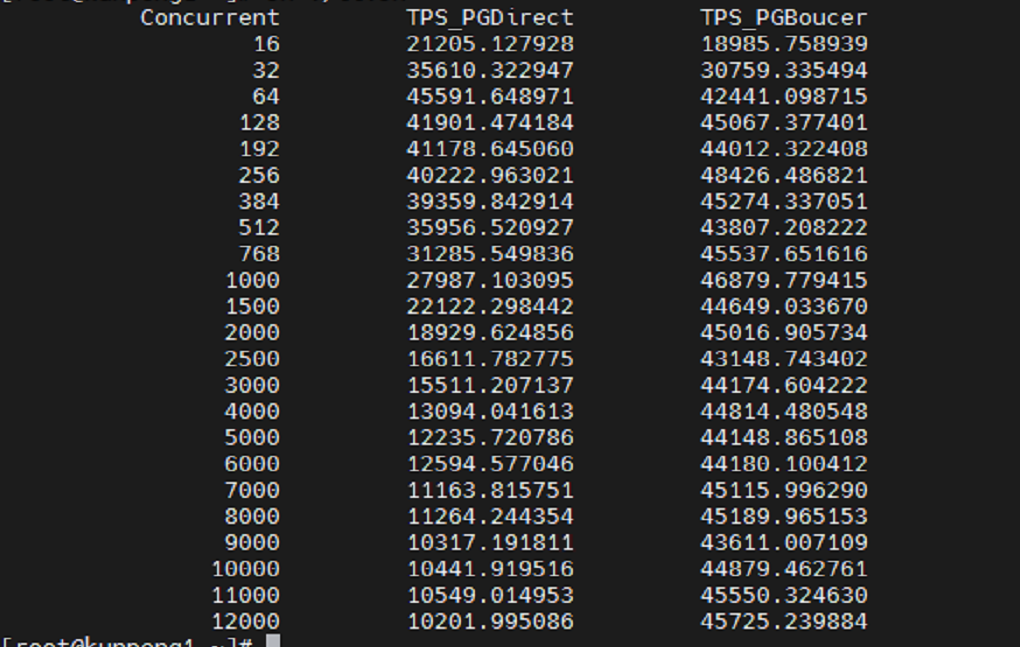
Excel图:
7. 总结
使用PGBouncer时,一定要注意单进程时的吞吐量瓶颈,在必要的时候,要使用so_reuseport=1这个参数并启动多个PGBouncer进程,以达到最佳效果。在使用多个PGBouncer进程时,注意pool_size需要适当降低。可通过实际压测选择合适的进程数和pool_size。
