




本期主要介绍如何使用Confluent-Kafka-Python实现Kafka消费阿里云SLS的日志内容,并写入到Starrocks数据库持久化。阿里云提供的Kafka消费方案,可以提供以下链接:使用Confluent-Kafka-Python实现Kafka消费_日志服务(SLS)-阿里云帮助中心 (aliyun.com)
大致流程如下:
SLS-->Confluent-Kafka-Python-->Kafka-->Confluent-Kafka-Python-->Starrocks
那从这里,我们也知道了,如果要完成这个消费任务,除了需要阿里云的API,还需要借助python、kafka和Confluent-Kafka-Python等组件。以下就通过这些组件,将任务拆分成多个部分,进行一些相应测试,讲述消费的实现过程。
假如当前环境已经配备了python,这次操作背景,我的环境已经配备了python3.

--安装Kafka
kafka下载地址:Apache Kafka
--创建安装目录mkdir -p opt/soft/kafka_datamkdir -p opt/soft/kafka_data/zookeepermkdir -p opt/soft/kafka_data/logmkdir -p opt/soft/kafka_data/log/kafkamkdir -p opt/soft/kafka_data/log/zookeeper--添加kafka配置# vi server.propertiesbroker.id=0port=9092host.name=172.17.7.11log.dirs=/opt/soft/kafka_data/log/kafkazookeeper.connect=localhost:2181--添加zookeeper配置dataDir=/opt/soft/kafka_data/zookeeperdataLogDir=/opt/soft/kafka_data/log/zookeeperclientPort=2181maxClientCnxns=100tickTimes=2000initLimit=10syncLimit=5--添加启动Kafka的脚本vi kafka_start.sh#!/bin/sh#启动zookeeper/opt/kafka_2.12-3.6.2/bin/zookeeper-server-start.sh opt/kafka_2.12-3.6.2/config/zookeeper.properties &sleep 3 #等3秒后执行#启动kafka/opt/kafka_2.12-3.6.2/bin/kafka-server-start.sh opt/kafka_2.12-3.6.2/config/server.properties &--添加关闭Kafka的脚本vi kafka_stop.sh#!/bin/sh#关闭zookeeper/opt/kafka_2.12-3.6.2/bin/zookeeper-server-stop.sh opt/kafka_2.12-3.6.2/config/zookeeper.properties &sleep 3 #等3秒后执行#关闭kafka/opt/kafka_2.12-3.6.2/bin/kafka-server-stop.sh opt/kafka_2.12-3.6.2/config/server.properties &复制
--安装Confluent-Kafka和mysql-connector-python
pip install confluent-kafka mysql-connector-python复制
安装两个python客户端组件,为了可以通过python连接Kafka和Starrocks数据库,实现日志生产端和消费端,以及数据存储端之间的连接通讯。
--消费SLS的配置
import sysimport osfrom confluent_kafka import Consumer, KafkaError, KafkaExceptionendpoint = "cn-huhehaote.log.aliyuncs.com""""阿里云账号AccessKey拥有所有API的访问权限,风险很高。强烈建议您创建并使用RAM用户进行API访问或日常运维,请登录RAM控制台创建RAM用户。此处以把AccessKey和AccessKeySecret保存在环境变量为例说明。您可以根据业务需要,保存到配置文件里。强烈建议不要把AccessKey和AccessKeySecret保存到代码里,会存在密钥泄漏风险。"""accessKeyId = os.getenv("SLS_ACCESS_KEY_ID")accessKeySecret = os.getenv("SLS_ACCESS_KEY_SECRET")project = "etl-dev"logstore = "test"port = "10012"groupId = "kafka-test"kafkaEndpoint = "{}.{}:{}".format(project, endpoint, port)groupId = "kafka-test2112"c = Consumer({"bootstrap.servers": kafkaEndpoint,"sasl.mechanism": "PLAIN","security.protocol": "sasl_ssl","sasl.username": project,"sasl.password": "%s#%s" % (accessKeyId, accessKeySecret),"group.id": groupId,"enable.auto.commit": "true","auto.commit.interval.ms": 30000,"session.timeout.ms": 120000,"auto.offset.reset": "earliest","max.poll.interval.ms": 130000,"heartbeat.interval.ms": 5000,})c.subscribe([logstore])while True:msg = c.poll(1.0)if msg is None:continueif msg.error():print("Consumer error: {}".format(msg.error()))continueprint('Received message: {}'.format(msg.value().decode('utf-8')))c.close()复制
可以直接使用阿里云官网提供的示例代码,根据要求提示,补充配置参数就可以消费SLS的内容到Kafka上了。
--消费Kafka的内容到Starrocks
cat >kafka_test_001.pyfrom confluent_kafka import Consumer, KafkaErrorimport mysql.connectorimport json# Kafka消费者配置kafka_conf = {'bootstrap.servers': '172.17.7.11', # 替换为你的Kafka broker地址'group.id': '100001', # 替换为你的消费者组ID'auto.offset.reset': 'earliest',}# StarRocks数据库连接配置starrocks_conf = {'host': '172.17.199.36', # 替换为你的StarRocks主机地址'port': 9030, # 替换为你的StarRocks端口'user': 'user', # 替换为你的StarRocks用户名'password': 'XXXXXXXXX', # 替换为你的StarRocks密码'database': 'mytest', # 替换为你的StarRocks数据库名称}# 创建Kafka消费者实例consumer = Consumer(kafka_conf)consumer.subscribe(['mykafka_test03']) # 替换为你的Kafka主题# 创建StarRocks连接starrocks_connection = mysql.connector.connect(**starrocks_conf)cursor = starrocks_connection.cursor()try:while True:msg = consumer.poll(1.0)if msg is None:continueif msg.error():if msg.error().code() == KafkaError._PARTITION_EOF:continueelse:print(f"Kafka error: {msg.error()}")breaktry:# 解析Kafka消息的内容message_content = json.loads(msg.value().decode('utf-8'))# 构建SQL插入语句,表名和字段应根据StarRocks表的结构来定义sql = "INSERT INTO mytest_kafka_tab (id, city,country) VALUES (%s, %s,%s)"data = (message_content['id'], message_content['city'],message_content['country'])# 执行SQL语句并提交到StarRockscursor.execute(sql, data)starrocks_connection.commit()except json.JSONDecodeError as e:print(f"Error decoding JSON: {e}")except mysql.connector.Error as e:print(f"Error inserting data into StarRocks: {e}")finally:# 清理Kafka消费者和StarRocks连接consumer.close()cursor.close()starrocks_connection.close()复制
以上,基本把整个数据流的链路打通了。以下是部分消费环节的拆分测试。
--测试一:Kafka消费json数据并写入Starrocks数据库
##创建一个topic
1. 在一个终端执行创建生产者:(推消息到wd_test)cd /opt/kafka_2.12-3.6.2/bin/ #进入kafka目录./kafka-console-producer.sh --broker-list 172.17.7.11:9092 --topic mykafka_test03 #(注:wd_test你要建立的topic名)2. 在另一个终端执行创建消费者:(从wd_test上消费消息)cd /opt/kafka_2.12-3.6.2/bin/ #进入kafka目录./kafka-console-consumer.sh --bootstrap-server 172.17.7.11:9092 --topic mykafka_test03 #消费wd_test的topic消息复制
##添加消费数据
{"id":1001,"city":"New York","country":"Amarica"}{"id":1002,"city":"Los Angeles","country":"Amarica"}{"id":1003,"city":"Chicago","country":"Amarica"}{"id":1004,"city":"Florid","country":"Amarica"}{"id":1006,"city":"Florid","country":"Amarica"}{"id":"1005","city":"New York","country":"Amarica"}复制
##效果展示
#生产端

#消费端

#Starrocks数据库存储端

--测试二:使用Confluent-Kafka-Python将SLS的数据并写入Starrocks数据库
#测试片段代码
cat >new_test.pyimport jsonimport pymysql# StarRocks数据库连接配置starrocks_config = {'host': '172.17.199.36','port': 9030, # StarRocks MySQL协议端口'user': 'user','password': 'xxxxxxxx','database': 'example_db'}# 假设JSON数据存储在 'log.json' 文件中json_file_path = '/root/pythondir/jsonfile/mytest.json'# 从文件中读取JSON字符串with open(json_file_path, 'r') as file:json_str = file.read()# 将JSON字符串解析为Python字典log_entry = json.loads(json_str)# 映射和转换数据以匹配StarRocks表结构# 这里需要根据你的StarRocks表的实际结构来调整starrocks_data = (log_entry['winlog']['record_id'],log_entry['winlog']['api'],log_entry['winlog']['computer_name'],log_entry['log']['level'],log_entry['host']['hostname'],log_entry['host']['mac'],log_entry['host']['architecture'],log_entry['host']['os']['name'],log_entry['host']['os']['platform'],log_entry['host']['os']['kernel'],log_entry['host']['os']['type'],log_entry['host']['os']['build'],log_entry['host']['os']['version'],log_entry['host']['os']['family'],log_entry['host']['id'],log_entry['host']['ip'],log_entry['agent']['type'],log_entry['agent']['version'],log_entry['winlog']['channel'],log_entry['winlog']['provider_name'],log_entry['winlog']['task'],log_entry['winlog']['keywords'],log_entry['winlog']['event_id'],log_entry['winlog']['event_data']['TargetUserName'],log_entry['winlog']['event_data']['TargetDomainName'],log_entry['winlog']['event_data']['IpAddress'],log_entry['winlog']['event_data']['LogonGuid'],log_entry['@timestamp'],log_entry['message'],log_entry['event']['action'],log_entry['event']['outcome'],log_entry['event']['provider'],log_entry['event']['code'],log_entry['event']['kind']# ...其他字段映射)# 插入数据到StarRocks的函数def insert_into_starrocks(data):# 构建插入SQL语句insert_sql = """INSERT INTO alicloud_sls_even_log_audit_tbl (record_id, api,computer_name,level,hostname,mac,architecture,os_name,platform,kernel,type,build,version,family,host_id,host_ip,agent_type,agent_version,winlog_channel,winlog_provider_name,winlog_task,winlog_keywords,winlog_event_id,winlog_event_data_tuname,winlog_event_data_tdoname,winlog_event_data_ip,winlog_event_data_logid,timestamp,message,event_action,event_outcome,event_provider,event_code,event_kind)VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s, %s,%s,%s,%s,%s,json_arry%s,%s,%s,%s,%s, %s,%s,%s,%s,%s,%s,%s,%s,%s,%s, %s,%s,%s,%s);"""# 连接到StarRocks数据库connection = pymysql.connect(**starrocks_config)try:with connection.cursor() as cursor:# 执行SQL语句cursor.execute(insert_sql, data)# 提交事务connection.commit()print("Data inserted into StarRocks successfully.")except Exception as e:print(f"Failed to insert data into StarRocks: {e}")finally:connection.close()# 调用函数,插入数据insert_into_starrocks(starrocks_data)复制
#存储表结构
CREATE TABLE `alicloud_sls_event_log_audit_tbl` (`record_id` int(11) NOT NULL COMMENT "",`api` varchar(65533) NULL COMMENT "",`computer_name` varchar(65533) NULL COMMENT "",`level` varchar(65533) NULL COMMENT "",`hostname` varchar(65533) NULL COMMENT "",`mac` varchar(65533) NULL COMMENT "",`architecture` varchar(65533) NULL COMMENT "",`os_name` varchar(65533) NULL COMMENT "",`platform` varchar(65533) NULL COMMENT "",`kernel` varchar(65533) NULL COMMENT "",`type` varchar(65533) NULL COMMENT "",`build` varchar(65533) NULL COMMENT "",`version` varchar(65533) NULL COMMENT "",`family` varchar(65533) NULL COMMENT "",`host_id` varchar(65533) NULL COMMENT "",`host_ip` ARRAY<STRING> NULL COMMENT "",`agent_type` varchar(65533) NULL COMMENT "",`agent_version` varchar(65533) NULL COMMENT "",`winlog_channel` varchar(65533) NULL COMMENT "",`winlog_provider_name` varchar(65533) NULL COMMENT "",`winlog_task` varchar(65533) NULL COMMENT "",`winlog_keywords` varchar(65533) NULL COMMENT "",`winlog_event_id` varchar(65533) NULL COMMENT "",`winlog_event_data_tuname` varchar(65533) NULL COMMENT "",`winlog_event_data_tdoname` varchar(65533) NULL COMMENT "",`winlog_event_data_ip` varchar(65533) NULL COMMENT "",`winlog_event_data_logid` varchar(65533) NULL COMMENT "",`timestamp` varchar(65533) NULL COMMENT "",`message` varchar(65533) NULL COMMENT "",`event_action` varchar(65533) NULL COMMENT "",`event_outcome` varchar(65533) NULL COMMENT "",`event_provider` varchar(65533) NULL COMMENT "",`event_code` varchar(65533) NULL COMMENT "",`event_kind` varchar(65533) NULL COMMENT "") ENGINE=OLAPPRIMARY KEY(`record_id`)DISTRIBUTED BY HASH(`record_id`)PROPERTIES ("replication_num" = "2","in_memory" = "false","enable_persistent_index" = "true","replicated_storage" = "true","compression" = "LZ4");复制
#效果展示
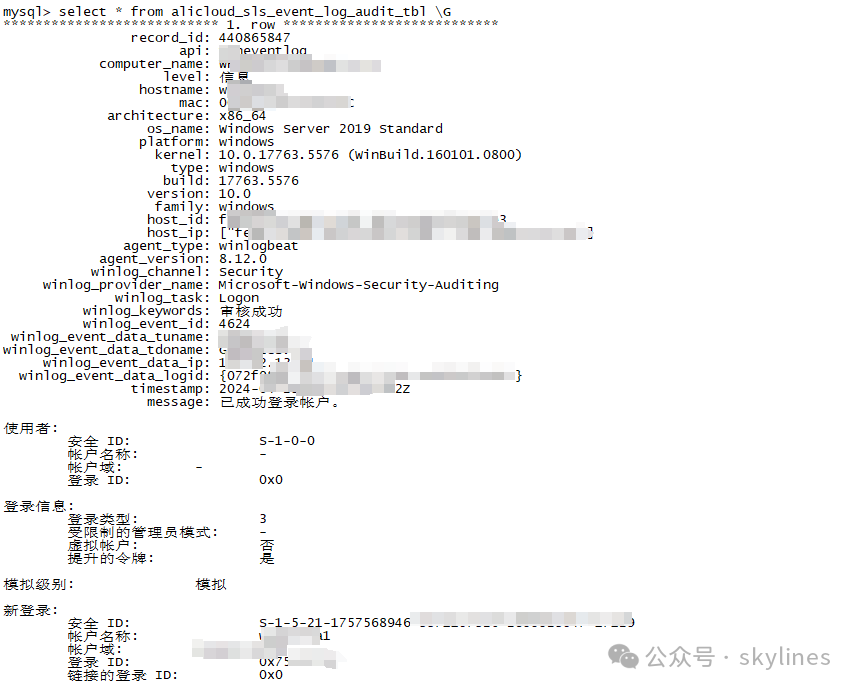
以上就是本次SLS消费的所有详细内容,希望对你有用。谢谢!



