




导读
之前做数据迁移之后, 关于数据的一致性校验, 我们是使用checksum来做的, 也可以使用count(*), 但是都比较慢. 而数据校验的时候, 数据实际上是静态的, 没有业务使用的, 欸, 那我们是不是就可以自己来统计行数呢?
实现原理
我们来简单回顾下数据文件的结构, 大概如下图:
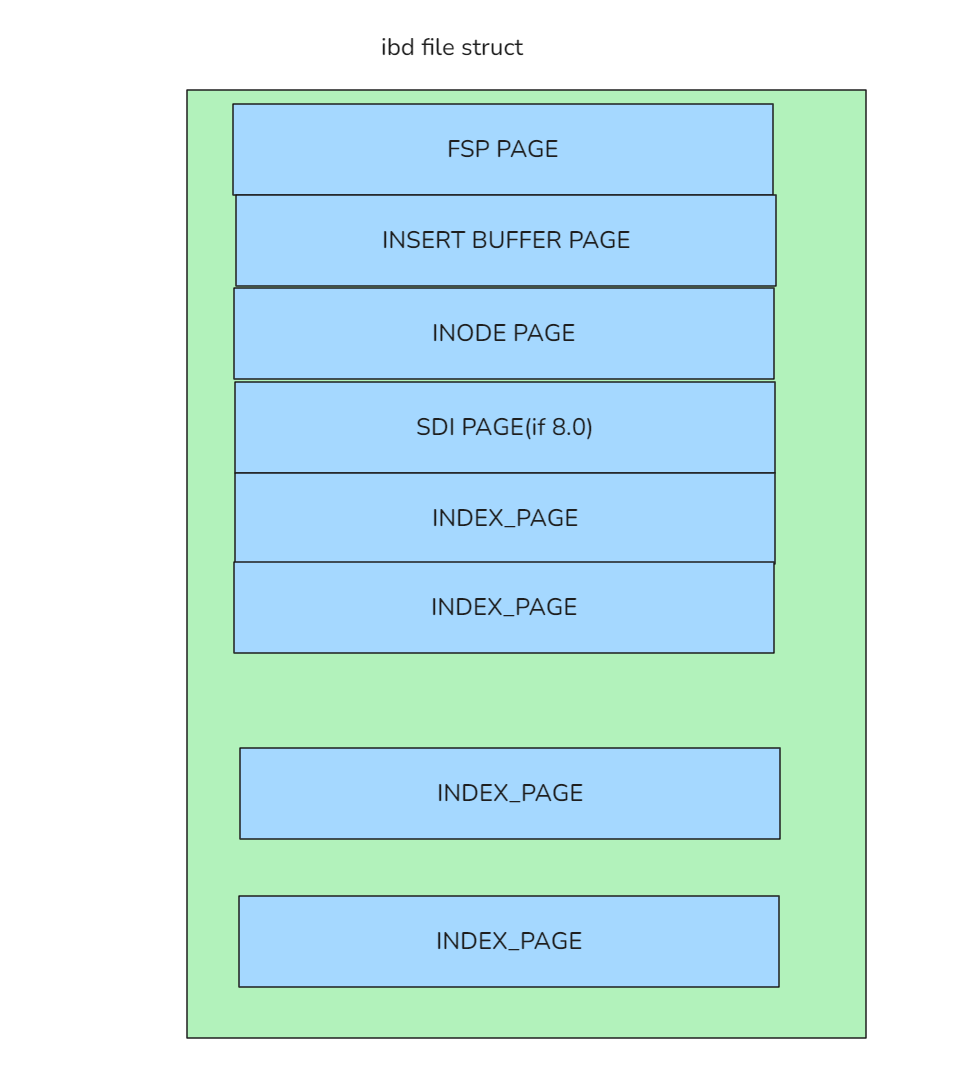
FSP PAGE主要是记录sdi信息, xdes和key之类的信息.
INODE PAGE主要是记录 segment信息, 每2个segemnt为一个索引, 第一对为主键索引信息, 如果是8.0环境则第一对segment为sdi信息
主键索引存储了该表的完整数据.统计索引的行数,即为统计表的行数.
INDEX PAGE就是我们的索引行, 也就是数据行所在的页了. INDEX PAGE虽然结构是一样的, 但却分为叶子节点和非叶子节点供btr+使用, INODE PAGE中的每2个segment对应的就是 btr+里面的第一个非叶子节点(ROOT PAGE)和第一个叶子节点的
我们知道mysql的索引通常是btr+结构的, 比如:
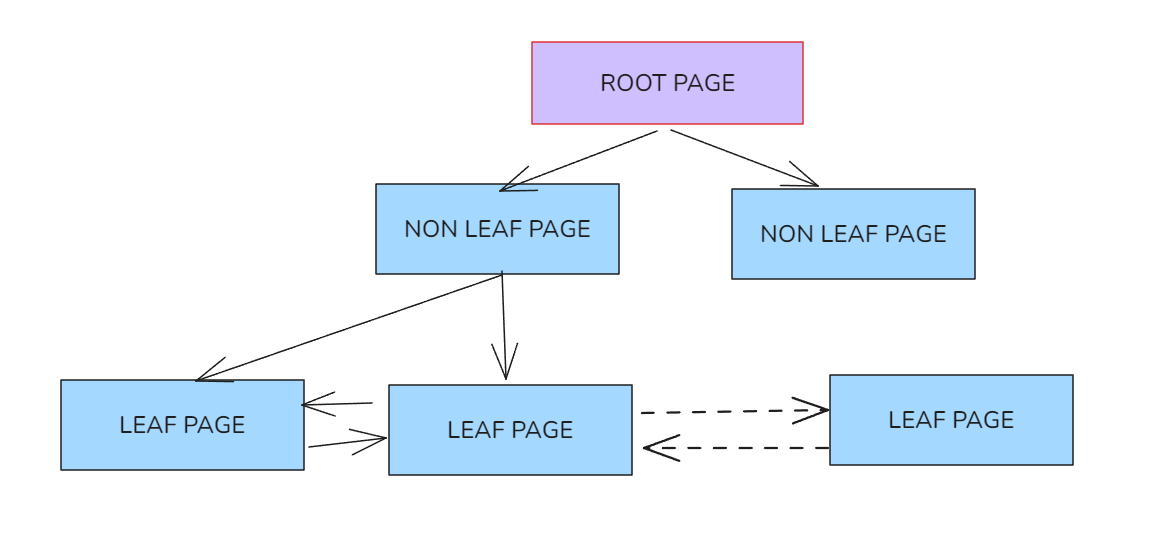
叶子节点是相互连接的, 也就是找到第一个叶子节点, 即可顺藤摸瓜,找到所有的数据.
我们有必要解析每个叶子节点里面的每行数据吗? 其实没必要的, 因为叶子节点(INDEX PAGE)中的PAGE HEADER部分的PAGE_N_RECS就是记录本页数据有多少行.我们只需要统计所有叶子节点的PAGE_N_RECS即可.
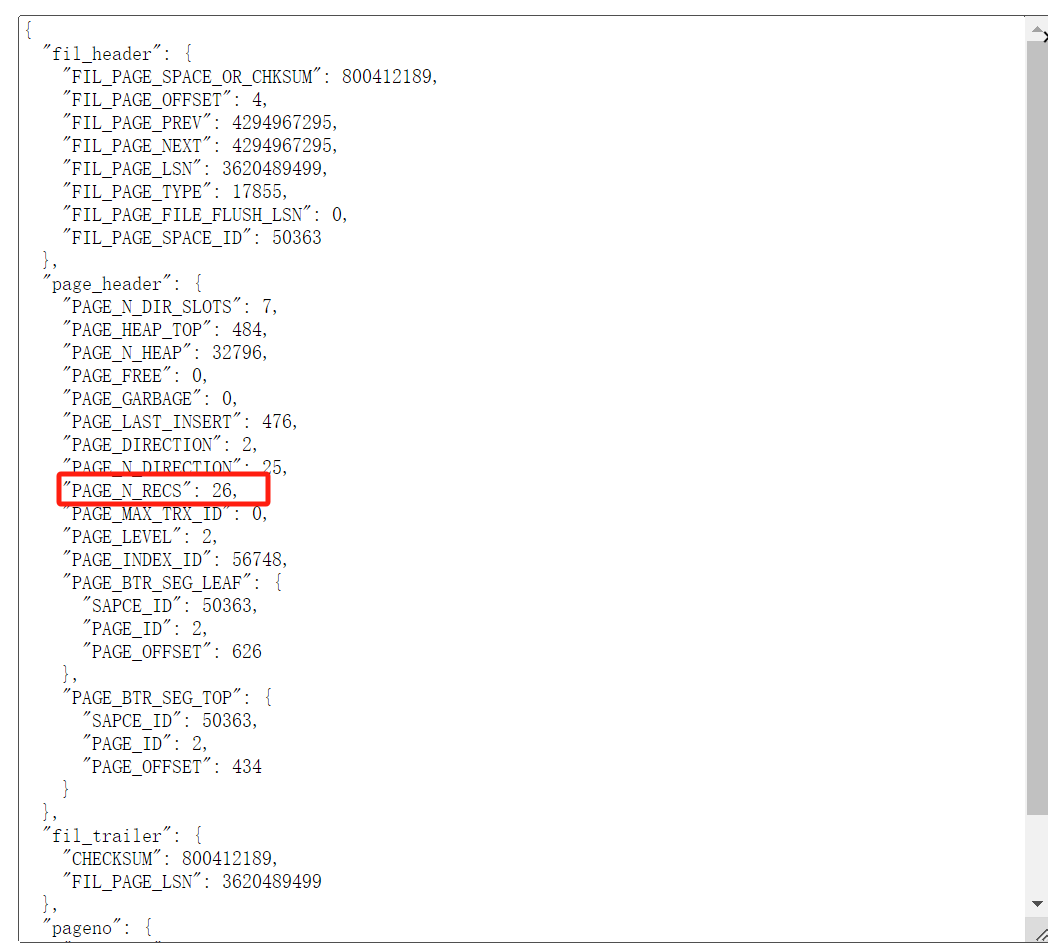
理论上似乎是可行的, 那我们就来使用python实现它吧.
测试验证
编写代码的过程就略了, 我们还稍微做了下兼容性, 使其能使用python2/python3直接执行, 支持mysql5.7和8.0环境
其它版本我这没得环境测试…
这个功能和ibd2sql比较像, 我们就放到ibd2sql项目里面吧.
既然是统计行数的, 那我们就叫它super_fast_count.py吧
希望它能对得起它的名字.
说了这么多, 脚本呢? 见文末.
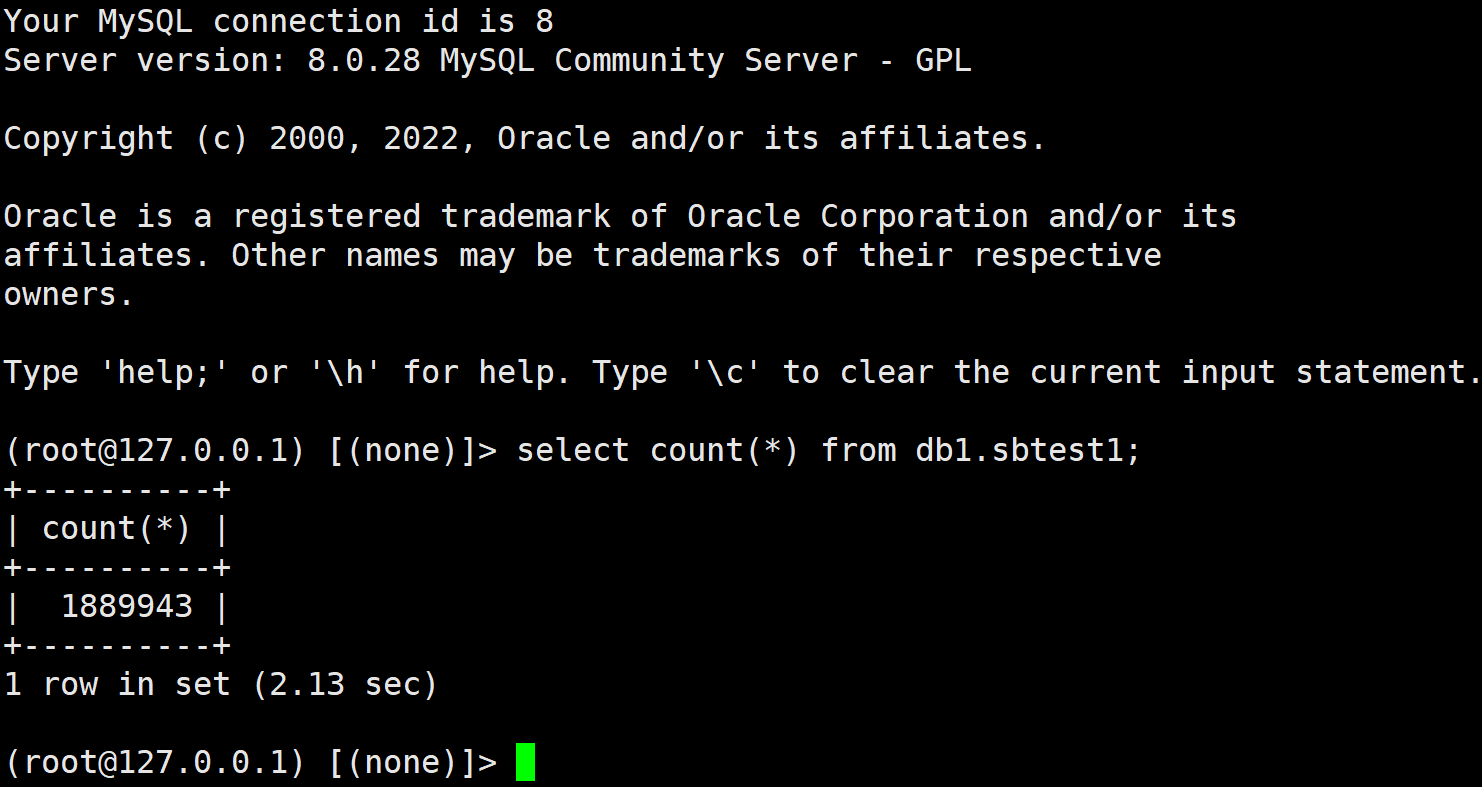
先看看原生的mysql的count(*)速度
188W数据, 耗时2秒! 还是不错的成绩.
神器
使用这个神器前, 先深呼吸,吸收天地之灵气. 然后快速敲下如下命令:
time python3 super_fast_count.py /data/mysql_3314/mysqldata/db1/sbtest1.ibd
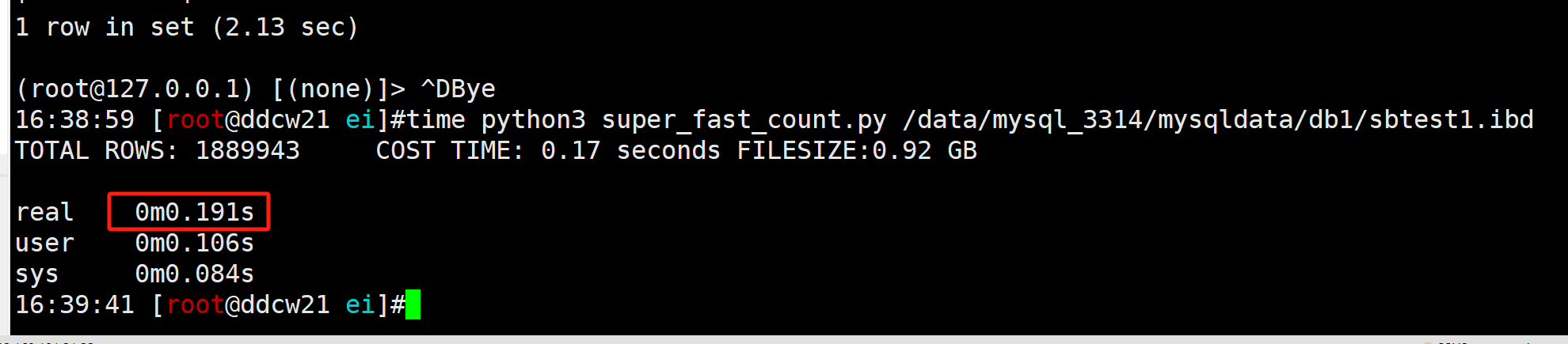
耗时为 0.19 秒. 差不多只有mysql原版的十分之一, 可喜可贺. 行数也是能对上的, 说明我们统计的结果也是对的.
经过测试发现, 敲命令的速度和脚本执行速度没有明显关系. 实际使用的时候可以放心的慢慢敲.
神器的兼容性测试
然后我们来测试下兼容性:
python2环境: 看起来慢一丢丢, 但无伤大雅

mysql 5.7环境: 我没得大表了, 就这个10W行的意思意思吧. 0.04秒还是不错的成绩

总结
由于我们是直接读取的磁盘上的ibd数据文件, 所以使用场景是有限的, 而且使用时,会吃很多IO的.
常见使用场景:主从切换后数据快速校验, 大概估计下表的行数. 很闲的库. 没得脏数据的情况(show engine innodb看下LSN)
不建议使用的场景: 频繁更新的表, 服务器IO压力比较大.
附源码
可以到github下载最新版: https://github.com/ddcw/ibd2sql
也可以使用本文的代码, 如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# write by ddcw @https://github.com/ddcw
# 快速统计表行数的脚本
import os
import sys
import struct
import time
# 一些变量的初始化
PAGE_SIZE = 16384
# 后面内容就不可以修改了哈
FSP_EXTENT_SIZE = 1048576//PAGE_SIZE if PAGE_SIZE <= 16384 else 2097152//PAGE_SIZE if PAGE_SIZE <= 32768 else 4194304//PAGE_SIZE
XDES_COUNT = PAGE_SIZE//FSP_EXTENT_SIZE
XDES_SIZE = 24 + (FSP_EXTENT_SIZE*2+7)//8
argv = sys.argv
def USAGE():
sys.stdout.write('\nUSAGE: python super_fast_count.py xxx.ibd\n')
sys.exit(1)
if len(argv) != 2:
USAGE()
filename = sys.argv[1]
if not os.path.exists(filename):
sys.stdout.write(str(filename)+" is not exists\n")
USAGE()
MAX_PAGE_ID = os.path.getsize(filename)//PAGE_SIZE
starttime = time.time()
with open(filename,'rb') as f:
# 获取first leaf pageid, 本来可以使用ibd2sql去做的, 但为了兼容性, 就单独来做吧..
fsp_data = f.read(PAGE_SIZE) # FSP, 要判断是否是8.x, 主要是有个SDI信息占了2 sgement
f.seek(2*PAGE_SIZE)
# fil_hedaer + space_header + XDES + keyring(+4)
offset = 38 + 112 + XDES_COUNT*XDES_SIZE + 115
HAVE_SDI = 0
if fsp_data[offset:offset+4] == b'\x00\x00\x00\x01':
HAVE_SDI = 1
data = f.read(PAGE_SIZE) # inode
if data[24:26] != b'\x00\x03':
sys.stdout.write(str(filename)+" is not ibd file\n")
USAGE()
offset = 38 + 12 + 192*2*HAVE_SDI + 192
leaf_page_seg = data[offset:offset+192]
PAGE_ID = 4294967295
for x in struct.unpack('>32L',leaf_page_seg[64:192]):
if x != 4294967295:
PAGE_ID = x
break
# 开始遍历
#OLD_NEXT_PAGE_NO = 0
ROW_COUNT = 0
while True:
if PAGE_ID == 4294967295 or PAGE_ID > MAX_PAGE_ID:
break
f.seek(PAGE_ID*PAGE_SIZE)
#OLD_NEXT_PAGE_NO = PAGE_ID
data = f.read(PAGE_SIZE)
PAGE_ID = struct.unpack('>4LQHQ',data[:34])[3] # FIL_PAGE_NEXT
ROW_COUNT += struct.unpack('>9HQHQ',data[38:][:36])[-4] # PAGE_N_RECS
stoptime = time.time()
filesize = str(round(MAX_PAGE_ID*PAGE_SIZE/1024/1024/1024,2))+' GB'
costtime = str(round(stoptime-starttime,2))+' seconds'
sys.stdout.write('TOTAL ROWS: '+str(ROW_COUNT)+'\tCOST TIME: '+costtime+'\tFILESIZE:'+filesize+'\n')
