




MySQL数据迁移到TiDB集群实践解析(DM篇)
一、概要
TiDB 是 PingCAP 公司自主设计、研发的开源分布式关系型数据库,是一款同时支持在线事务处理与在线分析处理 (Hybrid Transactional and Analytical Processing, HTAP) 的融合型分布式数据库产品,具备水平扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 协议和 MySQL 生态等重要特性。目标是为用户提供一站式 OLTP (Online Transactional Processing)、OLAP (Online Analytical Processing)、HTAP 解决方案。TiDB 适合高可用、强一致要求较高、数据规模较大等各种应用场景。
本次通过搭建虚拟机环境使用 TiDB DM (以下简称 DM)以全量+增量的模式,模拟MySQL数据迁移到TiDB。
二、TiDB DM迁移流程
使用 TiDB DM 迁移的流程如下图所示。
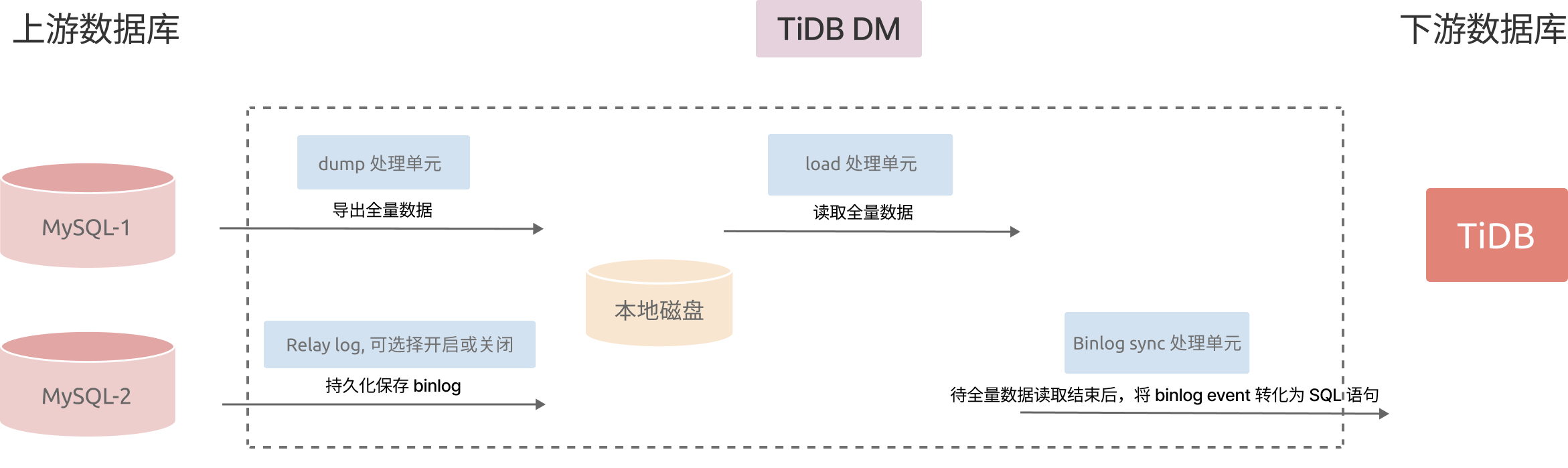
迁移阶段:dump(全量导出) + load(全量导入)+ sync(增量同步)
三、TiDB DM架构
DM 主要包括三个组件:DM-master,DM-worker 和 dmctl。
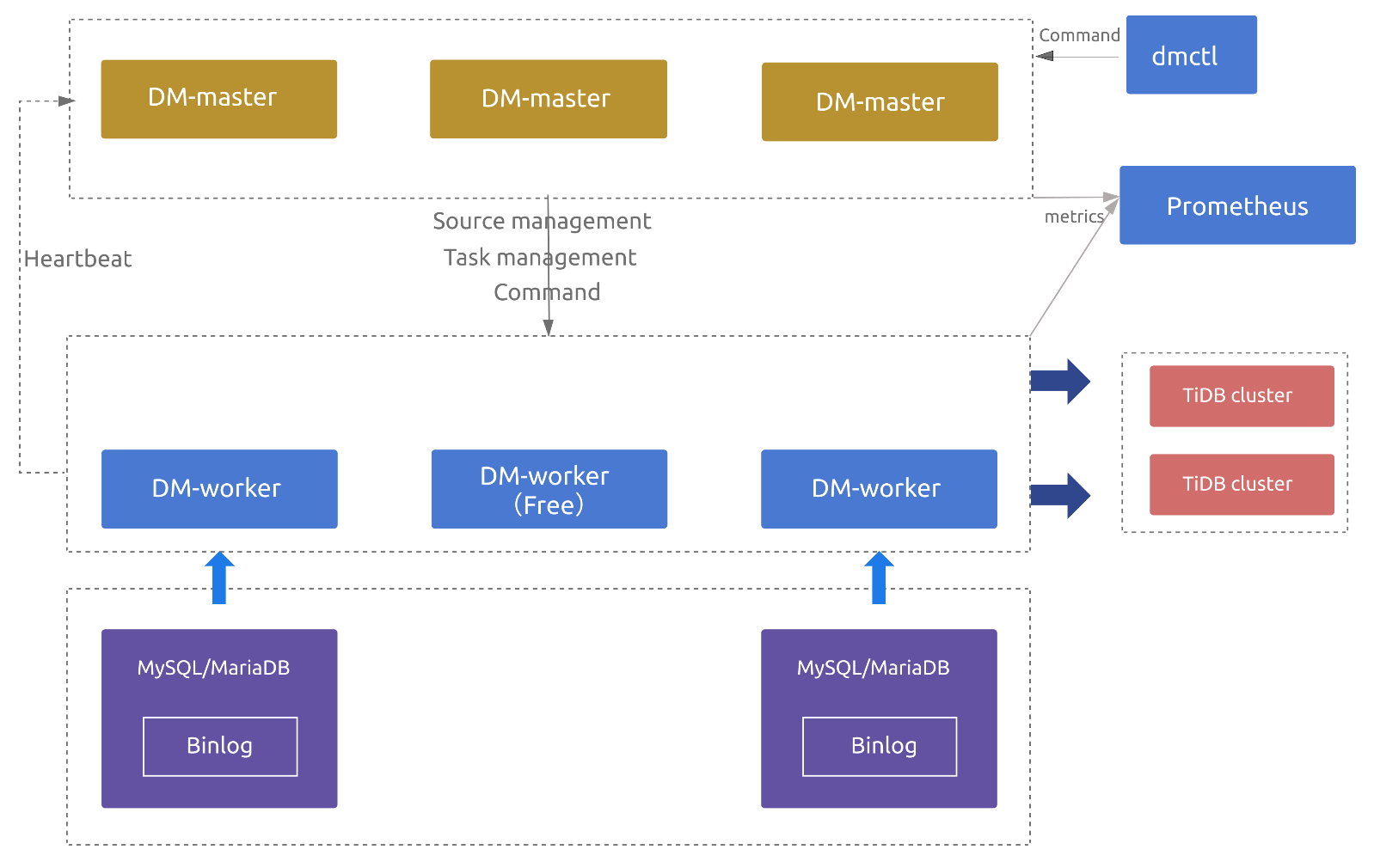
dmctl 简介
dmctl 是用来控制 DM 集群的命令行工具。
- 创建、更新或删除数据迁移任务
- 查看数据迁移任务状态
- 处理数据迁移任务错误
- 校验数据迁移任务配置的正确性
DM-master 简介
DM-master 负责管理和调度数据迁移任务的各项操作。
- 保存 DM 集群的拓扑信息
- 监控 DM-worker 进程的运行状态
- 监控数据迁移任务的运行状态
- 提供数据迁移任务管理的统一入口
- 协调分库分表场景下各个实例分表的 DDL 迁移
DM-worker 简介
DM-worker 是 DM (Data Migration) 的一个组件,负责执行具体的数据迁移任务。
其主要功能如下:
- 注册为一台 MySQL 或 MariaDB 服务器的 slave。
- 读取 MySQL 或 MariaDB 的 binlog event,并将这些 event 持久化保存在本地 (relay log)。
- 单个 DM-worker 支持迁移一个 MySQL 或 MariaDB 实例的数据到下游的多个 TiDB 实例。
- 多个 DM-Worker支持迁移多个 MySQL 或 MariaDB 实例的数据到下游的一个 TiDB 实例。
DM-worker 处理单元
DM-worker 任务包含如下多个逻辑处理单元。
- Relay log
Relay log 持久化保存从上游 MySQL 或 MariaDB 读取的 binlog,并对 binlog replication 处理单元提供读取 binlog event 的功能。
其原理和功能与 MySQL relay log 类似,详见 MySQL Relay Log。
dump 处理单元从上游 MySQL 或 MariaDB 导出全量数据到本地磁盘。
load 处理单元读取 dump 处理单元导出的数据文件,然后加载到下游 TiDB。
Binlog replication/sync 处理单元读取上游 MySQL/MariaDB 的 binlog event 或 relay log 处理单元的 binlog event,将这些 event 转化为 SQL 语句,再将这些 SQL 语句应用到下游 TiDB。
DM-worker 所需权限
上游数据库用户权限
上游数据库 (MySQL/MariaDB) 用户必须拥有以下权限:
权限 | 作用域 |
|---|---|
SELECT | Tables |
RELOAD | Global |
REPLICATION SLAVE | Global |
REPLICATION CLIENT | Global |
如果要迁移 db1 的数据到 TiDB,可执行如下的 GRANT 语句:
GRANT RELOAD,REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'your_user'@'your_wildcard_of_host'
GRANT SELECT ON db1.* TO 'your_user'@'your_wildcard_of_host';
如果还要迁移其他数据库的数据到 TiDB,请确保已赋予这些库跟 db1 一样的权限。
下游数据库 (TiDB) 用户必须拥有以下权限:
权限 | 作用域 |
|---|---|
SELECT | Tables |
INSERT | Tables |
UPDATE | Tables |
DELETE | Tables |
CREATE | Databases,tables |
DROP | Databases,tables |
ALTER | Tables |
INDEX | Tables |
对要执行迁移操作的数据库或表执行下面的 GRANT 语句:
GRANT SELECT,INSERT,UPDATE,DELETE,CREATE,DROP,ALTER,INDEX ON db.table TO 'your_user'@'your_wildcard_of_host';
GRANT ALL ON dm_meta.* TO 'your_user'@'your_wildcard_of_host';
处理单元 | 最小上游 (MySQL/MariaDB) 权限 | 最小下游 (TiDB) 权限 | 最小系统权限 |
|---|---|---|---|
Relay log | REPLICATION SLAVE (读取 binlog) | 无 | 本地读/写磁盘 |
Dump | SELECT | 无 | 本地写磁盘 |
Load | 无 | SELECT(查询 checkpoint 历史) | 读/写本地文件 |
Binlog replication | REPLICATION SLAVE(读 binlog) | SELECT(显示索引和列) | 本地读/写磁盘 |
备注:
dm_meta 即 meta-schema,是下游数据库中存放断点信息的数据库。全量迁移阶段以及增量复制阶段均支持断点续传,断点信息从 dm_meta 中获取,即断点信息丢失,则重新进行数据同步。
全量迁移阶段位点实时更新,而增量复制阶段位点是非实时更新的。
四、TiDB DM原理
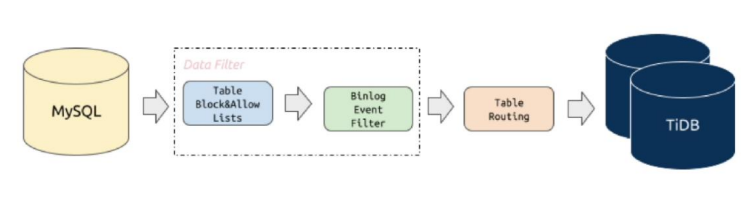
DM 提供了 Table routing、Block & Allow Table Lists、Binlog event filter 等基本功能,适用于不同的迁移场景。
Data Filter 数据的过滤包括如下2个模块:
Block & Allow Table Lists
上游数据库实例表的黑白名单过滤规则,可以用来过滤或者只迁移某些 database/table 的所有操作。
Binlog event filter
Binlog event filter 是比迁移表黑白名单更加细粒度的过滤规则,可以指定只迁移或者过滤掉某些schema / table 的指定类型 binlog,比如 增删改INSERT、TRUNCATE TABLE
还有
Table routing 表的路由功能
Table routing可以将上游 MySQL/MariaDB 实例的某些表迁移到下游指定表,它也是分库分表合并迁移所需的一个核心功能。
四、环境准备
节点名称 | IP地址 | 部署的组件 | 备注 |
DM集群 | 192.168.126.231~233 | DM-worker DM-master | 从 DM v5.4.0 起,TiDB Data Migration 的 Release Notes 合并入相同版本号的 TiDB Release Notes。 在生产环境中,不建议将 DM-master 和 DM-worker 部署和运行在同一个服务器上,以防 DM-worker 对磁盘的写入干扰 DM-master 高可用组件使用磁盘。 |
Mysql | 192.168.126.110 192.168.126.201 | Mysql5.7 Mysql8.0 | 源数据库及版本要求: MySQL 版本 5.5 ~ 5.7,MySQL 版本 = 8.0(实验特性),MariaDB 版本 >= 10.1.2 (实验特性)。 |
TiDB | 192.168.126.201 | TiDB v7.5.1 | 目前,TiDB部分兼容MySQL 支持的DDL语句。因为 DM 使用 TiDB parser 来解析处理 DDL 语句,所以目前仅支持 TiDB parser 支持的 DDL 语法。详见 TiDB DDL 语法支持 |
说明
- 目标 TiKV 集群必须有足够空间接收新导入的数据。除了标准硬件配置以外,目标 TiKV 集群的总存储空间必须大于 数据源大小 × 副本数量 × 2。例如集群默认使用 3 副本,那么总存储空间需为数据源大小的 6 倍以上。
- 在单机部署多个 DM-master 或 DM-worker 时,需要确保每个实例的端口以及运行命令的当前目录各不相同。
- 如果不需要确保 DM 集群高可用,则可只部署 1 个 DM-master 节点,且部署的 DM-worker 节点数量不少于上游待迁移的 MySQL/MariaDB 实例数。
- 如果需要确保 DM 集群高可用,则推荐部署 3 个 DM-master 节点,且部署的 DM-worker 节点数量大于上游待迁移的 MySQL/MariaDB 实例数(如 DM-worker 节点数量比上游实例数多 2 个)。
- 需要确保以下组件间端口可正常连通:
各 DM-master 节点间的 8291 端口可互相连通。
各 DM-master 节点可连通所有 DM-worker 节点的 8262 端口。
各 DM-worker 节点可连通所有 DM-master 节点的 8261 端口。
- 在遇到性能问题时可参照配置调优尝试修改任务配置。调优效果不明显时,可以尝试升级服务器配置。
- 如果业务分库分表之间存在数据冲突,自增主键冲突处理来解决。
TiDB Data Migration 兼容性目录
https://www.bookstack.cn/read/tidb-7.5-zh/d398ab9d0c212598.md
#MySQL需要开启参数如下:


五、DM 迁移数据配置文件
DM迁移数据需要调用几种配置文件来执行:
1、上游数据源配置文件
创建yaml文件将MySQL的相关信息写入到 source1.yaml
- # 唯一命名,不可重复。
- source-id: "mysql-01"
- # DM-worker 是否使用全局事务标识符 (GTID) 拉取 binlog。使用前提是上游 MySQL 已开启 GTID 模式。若上游存在主从自动切换,则必须使用 GTID 模式。
- enable-gtid: true
- from:
- host: "${host}" # 例如:172.16.10.81
- user: "root"
- password: "${password}" # 支持但不推荐使用明文密码,建议使用 dmctl encrypt 对明文密码进行加密后使用
- port: 3306
- # 从 DM v2.0.2 开始,Binlog event filter 也可以在上游数据库配置文件中进行配置
使用 tiup dmctl 将数据源配置加载到 DM 集群中:
tiup dmctl --master-addr ${advertise-addr} operate-source create source1.yaml
2、DM任务配置文件
按照规则,配置 DM 任务配置文件 dm-task.yaml,包括如下:
1. 任务基本信息配置(全局配置)
- name: "dm-taskX" #任务名:dm-taskX,(X 代表任意字符)
- task-mode: all #复制方式:all(全量 + 增量),
- ignore-checking-items: ["auto_increment_ID"] #忽略自增主键检测
2. 目标TiDB数据库配置信息(全局配置)
- target-database:
- host: "172.16.6.212"
- port: 4000
- user: "root"
- password: "tidb" #数据库地址:172.16.6.212,端口为:4000,用户名:root,密码:tidb
3. 任务规则配置信息(全局配置)
1. 配置需要迁移的表Block& Allow Table Lists
如果不需要过滤或迁移特定表,可以跳过该项配置。
配置从数据源迁移表的黑白名单,则需要添加两个定义,详细配置规则参考 Block & Allow Lists:
- block-allow-list:
- bw-rule-1: # 规则名称
- do-dbs:["test.*","user"] #迁移哪些,do-tables 和 ignore-tables 只需要配置一个,如果两者同时配置只有 do-tables 会生效
- # ignore-dbs:["mysql","account"] # 忽略哪些库,支持通配符"*”和"?"
- do-tables : #迁移哪些,do-tables 和 ignore-tables 只需要配置一个,如果两者同时配置只有 do-tables 会生效
- - db-name: "test.* "
- tbl-name: "t.*"
- - db-name:" user”
- tbl-name :"information”
- bw-rule-2: # 规则名称
- ignore-tables: # 忽略哪些表
- - db-name:”user”
- tbl-name: "log”
2. 配置需要过滤的操作Binlog event filter
如果不需要过滤特定库或者特定表的特定操作,可以跳过该项配置。
配置过滤特定操作,则需要添加两个定义,详细配置规则参考 Binlog Event Filter:
定义全局的数据源操作过滤规则
- filters: #上游数据库实例匹配的表的 binlog event filter 规则集
- filter-rule-1: # 配置名称
- schema-pattern: "test_*" #库名匹配规则, 支持通配符 “*” 和 “?”
- table-pattern: "t_*" # 表名匹配规则, 支持通配符 "*" 和"?"
- events: ["insert"] # 匹配哪些 event类型
- sql-pattern:[“^DROP\\s+PROCEDURE”,”^CREATE\\s+PROCEDURE”]
- action: Ignore #对与符合匹配规则的 binlog 迁移(Do) 还是忽略(Ignore)
- filter-rule-2:
- schema-pattern: "test"
- events: ["truncate table"]
- action: Do
- # 从 DM v2.0.2 开始,Binlog event filter 也可以在上游数据库配置文件中进行配置
3. 配置需要数据源表到目标 TiDB 表的映射Table routings
如果不需要将数据源表路由到不同名的目标 TiDB 表,可以跳过该项配置。
分库分表合并迁移的场景必须配置该规则。
配置数据源表迁移到目标 TiDB 表的路由规则,则需要添加两个定义,详细配置规则参考 Table Routing:
- routes: #上游和下游表之间的路由 table routing 规则集
- route-rule-1: #配置名称
- schema-pattern: "test_*" #库名匹配规则,支持通配符 "*" 和 "?"
- table-pattern: "t_*" #表名匹配规则, 支持通配符 “*” 和 “?”
- target-schema: "test" #目标库名称
- target-table: "t" #目标表名称
4. 配置是否进行分库分表合并
如果是分库分表合并的数据迁移场景,并且需要同步分库分表的 DDL,则必须显式配置 shard-mode,否则不要配置该选项。
分库分表 DDL 同步问题特别多,请确认了解 DM 同步分库分表 DDL 的原理和限制后,谨慎使用。
- ---
- ## ********* 任务信息配置 *********
- name: test # 任务名称,需要全局唯一
- shard-mode: "pessimistic" # 默认值为 "" 即无需协调。如果为分库分表合并任务,请设置为悲观协调模式 "pessimistic"。在深入了解乐观协调模式的原理和使用限制后,也可以设置为乐观协调模式 "optimistic"
4. 在数据源配置中引用规则(实例配置)
- mysql-instances:
- - source-id: "mysql-replica-01 " # 从 source-id = mysql-replica-01 的数据源迁移数据
- block-allow-list: "bw-rule-1" # 黑白名单配置名称
- filter-rules: ["filter-rule-1"] #过滤数据源特定操作的规则,可以配置多个过滤规则
- route-rules: ["route-rule-1", "route-rule-2"] #数据源表迁移到目标 TiDB 表的路由规则,可以定义多个规则
- - source-id: "mysql-replica-02" # 从 source-id = mysql-replica-02 的数据源迁移数据
- block-allow-list: "bw-rule-2" # 黑白名单配置名称
- filter-rules: ["filter-rule-2"] #过滤数据源特定操作的规则,可以配置多个过滤规则
六、DM 迁移数据实操
DM 提供了两种迁移任务工具如下:
- 使用 WebUI 管理 DM 迁移任务
DM WebUI 是一个 TiDB Data Migration (DM) 迁移任务管理界面,方便用户以直观的方式管理大量迁移任务,无需使用 dmctl 命令行,简化任务管理的操作步骤。
备注:
DM WebUI 当前为实验特性,不建议在生产环境中使用。
DM WebUI 中 task 的生命周期有所改变,不建议与 dmctl 同时使用。
访问方式
在开启 OpenAPI 后,你可以从 DM 集群的任意 master 节点访问 DM WebUI,访问端口与 DM OpenAPI 保持一致,默认为 8261。访问地址示例:http://{master_ip}:{master_port}/dashboard/。
- 使用 dmctl 运维 TiDB Data Migration 集群
注意
对于用 TiUP 部署的 DM 集群,推荐直接使用 tiup dmctl 命令。
dmctl 是用来运维 DM 集群的命令行工具,支持交互模式和命令模式。
1、DM 创建上游MySQL数据源并加载
第一个MySQL
$ tiup dmctl --master-addr=192.168.126.233:8261 operate-source create ./source-mysql-01.yaml
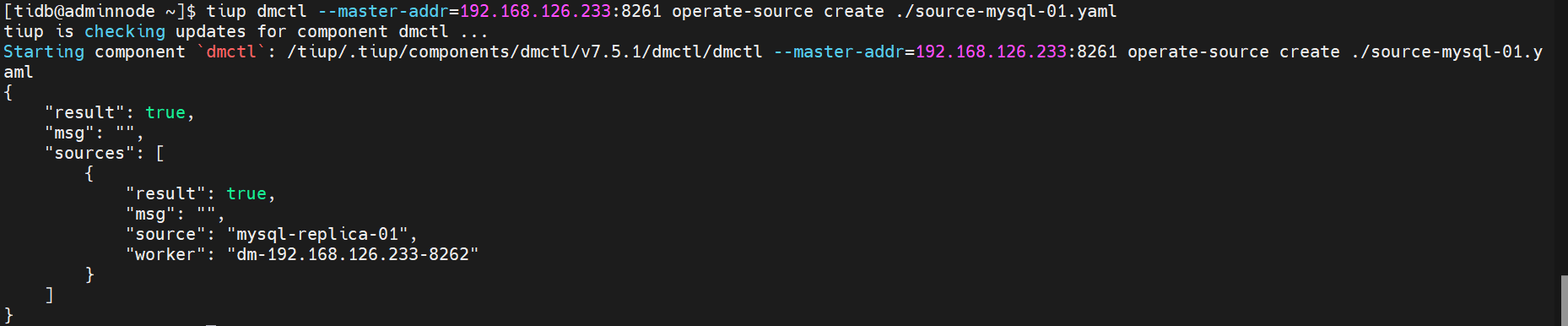
同理第二个MySQL
$ tiup dmctl --master-addr=192.168.126.231:8261 operate-source create ./source-mysql-02.yaml

#推荐使用dmctl 对上游数据库的用户密码加密之后的密码,生成命令如下(密码为mysql):
tiup dmctl --encrypt ‘mysql’

查看dm-worker已加载的数据源
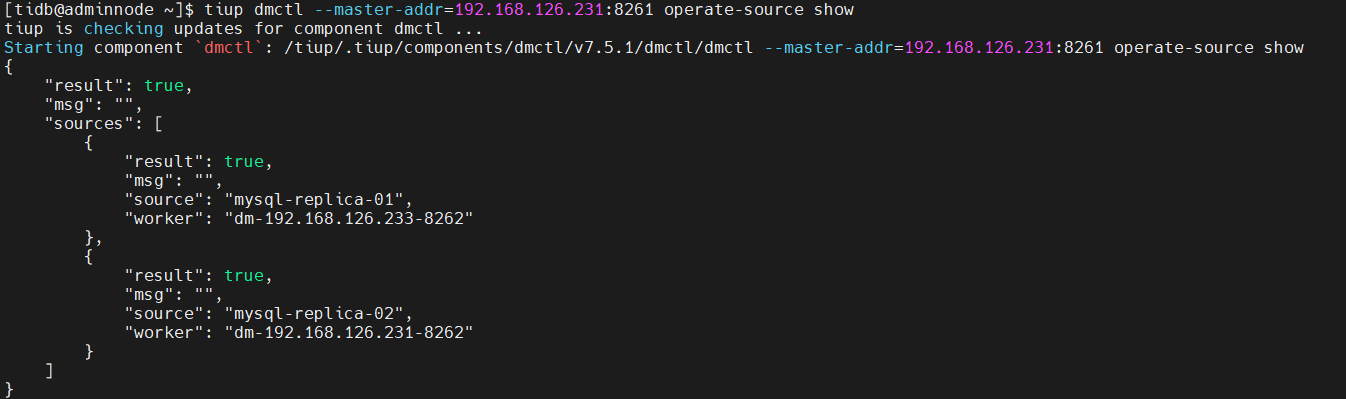
tiup dmctl --master-addr=192.168.126.231:8261 operate-source show
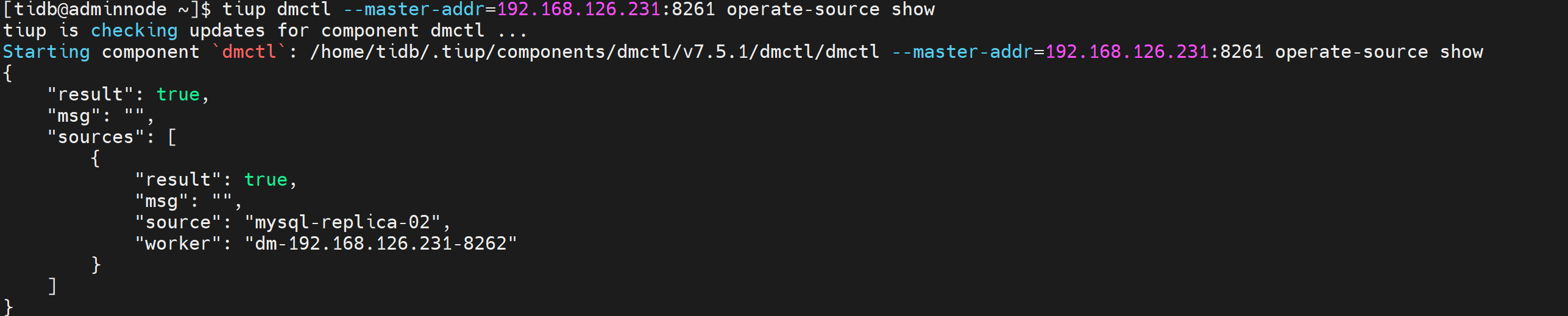
tiup dmctl --master-addr=192.168.126.231:8261 get-config source mysql-replica-02

#删除已加载的数据源
tiup dmctl --master-addr=192.168.126.231:8261 operate-source stop mysql-replica-02.yaml
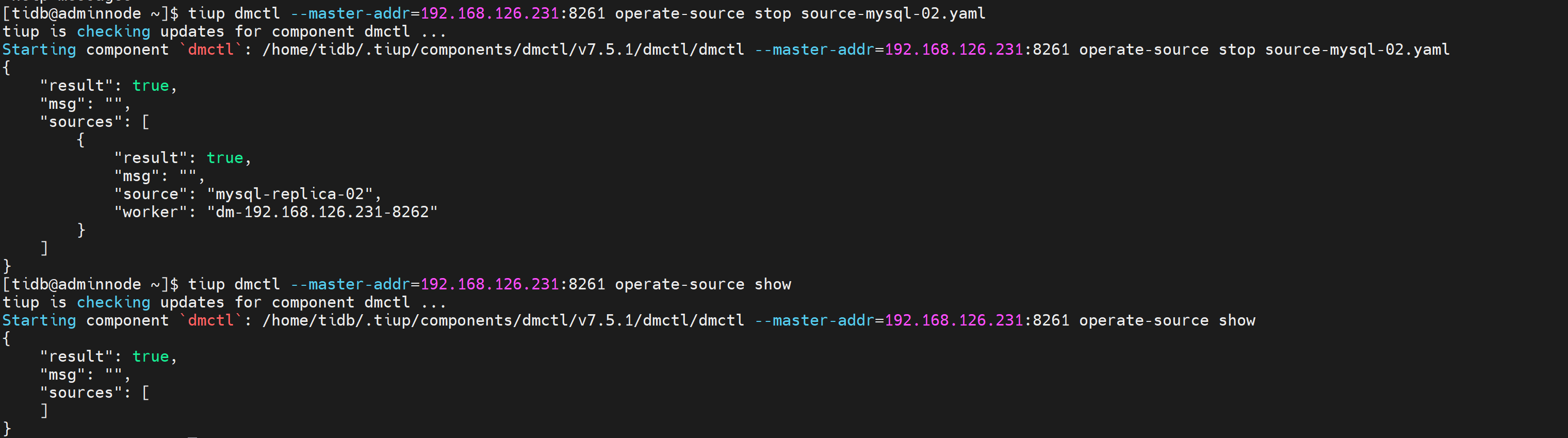
查看dm-worker 状态为Bound(没有的话为free)
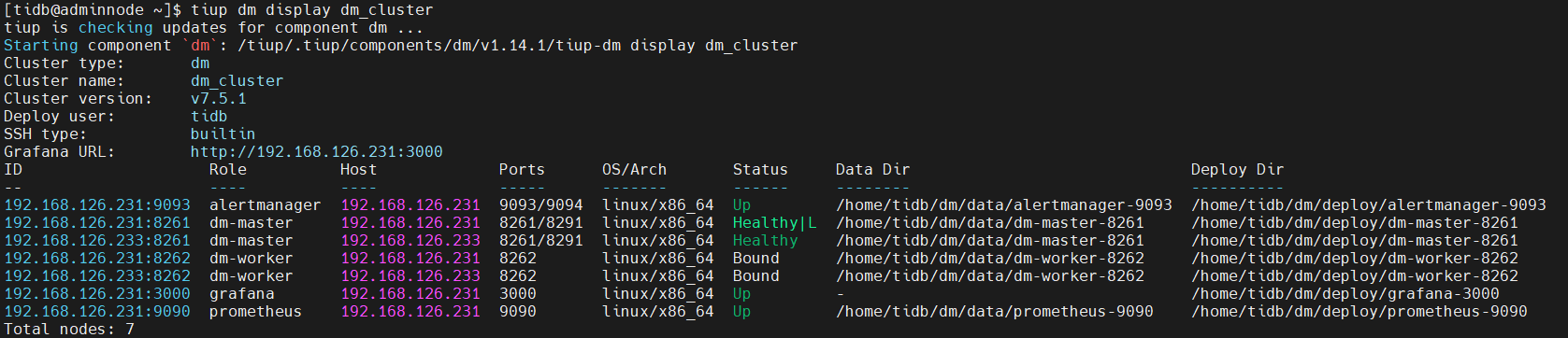
查看数据源与dm-worker对应关系
2、创建迁移任务
举例
迁移任务一:
MySQL1数据库实例中的 user 库中所有的表同步到 TiDB 数据库的 user_north 中去, MySQL2数据库实例中的 user 库中所有的表同步到 TiDB 数据库的 user_east 中去。我们使用 Table routings 实现,如下:
- routes:
- instance-1-user-rule:
- schema-pattern: "user"
- target-schema: "user _north"
- instance-2-user-rule:
- schema-pattern: "user"
- target-schema: "user _east"
迁移任务二:
MySQL1和2 数据库实例中的 store 库中的表原样同步到 TiDB 数据库中的 store 库中的表,但是 MySQL 2中的 store 库中的表 store_sz 会同步到 TIDB 的 store_suzhou 表中。我们使用 Table routings 实现,如下
- instance-2-store-rule:
- schema-pattern: "store"
- table-pattern: "store_sz"
- target-schema: "store"
- target-table: "store_suzhou"
迁移任务三:
MySQL1和2数据库实例中的 salesdb 库中的表 sales 做了分表,它们会同步到 TiDB 中的,salesdb 库的 sales 表中。(分表分库规则) 我们使用 Table routings 实现,如下:
- routes:
- sale-route-rule:
- schema-pattern: "salesdb" #源库的salesdb库
- table-pattern: "sales*" #源库的sales库中以sales开头的表
- target-schema: "salesdb" #目标库的 salesdb库
- target-table: "sales" #目标库的 sales 库的sales表
迁移任务四:
MySQL1和2数据库实例中的 user 库不会复制删除操作,user 库中的 trace 表 不会复制 truncate ,drop 和 delete 操作,store 库不会复制删除操作,store 库的表不会复制 truncate ,drop 和 delete 操作。我们使用 Binlog event filter 实现,如下:
- filters:
- trace-filter-rule: # user 库中的 trace 表不会复制 truncate ,drop 和 delete 操作
- schema-pattern: "user"
- table-pattern: "trace"
- events: ["truncate table", "drop table", "delete"]
- action: Ignore
- user-filter-rule: # MySQL 数据库实例 3306 和 3307 中的 user 库不会复制删除操作
- schema-pattern: "user"
- events: ["drop database"]
- action: Ignore
- store-filter-rule: # store 库不会复制删除操作,store 库的表不会复制 truncate ,drop 和delete 操作
- schema-pattern: "store"
- events: ["drop database", "truncate table", "drop table", "delete"]
- action: Ignore
迁移任务五:
MySQL1和2数据库实例中的 log 库不会参与复制。我们使用 block allow list 实现,如下:
- block-allow-list:
- log-ignored:
- ignore-dbs: ["log"]
我们将 MySQL1和2 数据库两个实例关联上述规则:
- mysql-instances:
- -
- source-id: "mysql-replica-01"
- route-rules: ["instance-1-user-rule","sale-route-rule"]
- filter-rules: ["trace-filter-rule", "user-filter-rule" , "store-filter-rule"]
- block-allow-list: "log-ignored"
- mydumper-config-name: "global"
- loader-config-name: "global"
- syncer-config-name: "global"
- -
- source-id: "mysql-replica-02"
- route-rules: ["instance-2-user-rule", "instance-2-store-rule","sale-route-rule"]
- filter-rules: ["trace-filter-rule", "user-filter-rule" , "store-filter-rule"]
- block-allow-list: "log-ignored"
- mydumper-config-name: "global"
- loader-config-name: "global"
- syncer-config-name: "global"
新建dm-task.yaml 文件,写入以下内容:
name: "dm-taskX"
task-mode: all
ignore-checking-items: ["auto_increment_ID"]
target-database:
host: "192.168.126.201"
port: 4000
user: "root"
password: "tidb123"
mysql-instances:
-
source-id: "mysql-replica-01"
route-rules: ["instance-1-user-rule","sale-route-rule"]
filter-rules: ["trace-filter-rule", "user-filter-rule" , "store-filter-rule"]
block-allow-list: "log-ignored"
mydumper-config-name: "global"
loader-config-name: "global"
syncer-config-name: "global"
-
source-id: "mysql-replica-02"
route-rules: ["instance-2-user-rule", "instance-2-store-rule","sale-route-rule"]
filter-rules: ["trace-filter-rule", "user-filter-rule" , "store-filter-rule"]
block-allow-list: "log-ignored"
mydumper-config-name: "global"
loader-config-name: "global"
syncer-config-name: "global"
# 所有实例的共有配置
routes:
instance-1-user-rule:
schema-pattern: "user"
target-schema: "user_north"
instance-2-user-rule:
schema-pattern: "user"
target-schema: "user_east"
instance-2-store-rule:
schema-pattern: "store"
table-pattern: "store_sz"
target-schema: "store"
target-table: "store_suzhou"
sale-route-rule:
schema-pattern: "salesdb"
target-schema: "salesdb"
filters:
trace-filter-rule:
schema-pattern: "user"
table-pattern: "trace"
events: ["truncate table", "drop table", "delete"]
action: Ignore
user-filter-rule:
schema-pattern: "user"
events: ["drop database"]
action: Ignore
store-filter-rule:
schema-pattern: "store"
events: ["drop database", "truncate table", "drop table", "delete"]
action: Ignore
block-allow-list:
log-ignored:
ignore-dbs: ["log"]
mydumpers:
global:
threads: 4
chunk-filesize: 64
3、检查与启动
为了提前发现数据迁移任务的一些配置错误,DM 中增加了前置检查功能:
- 启动数据迁移任务时,DM 自动检查相应的权限和配置。
- 也可使用 check-task 命令手动前置检查上游的 MySQL 实例配置是否符合 DM 的配置要求。
配置好后,可以先使用check-task检查下配置项。
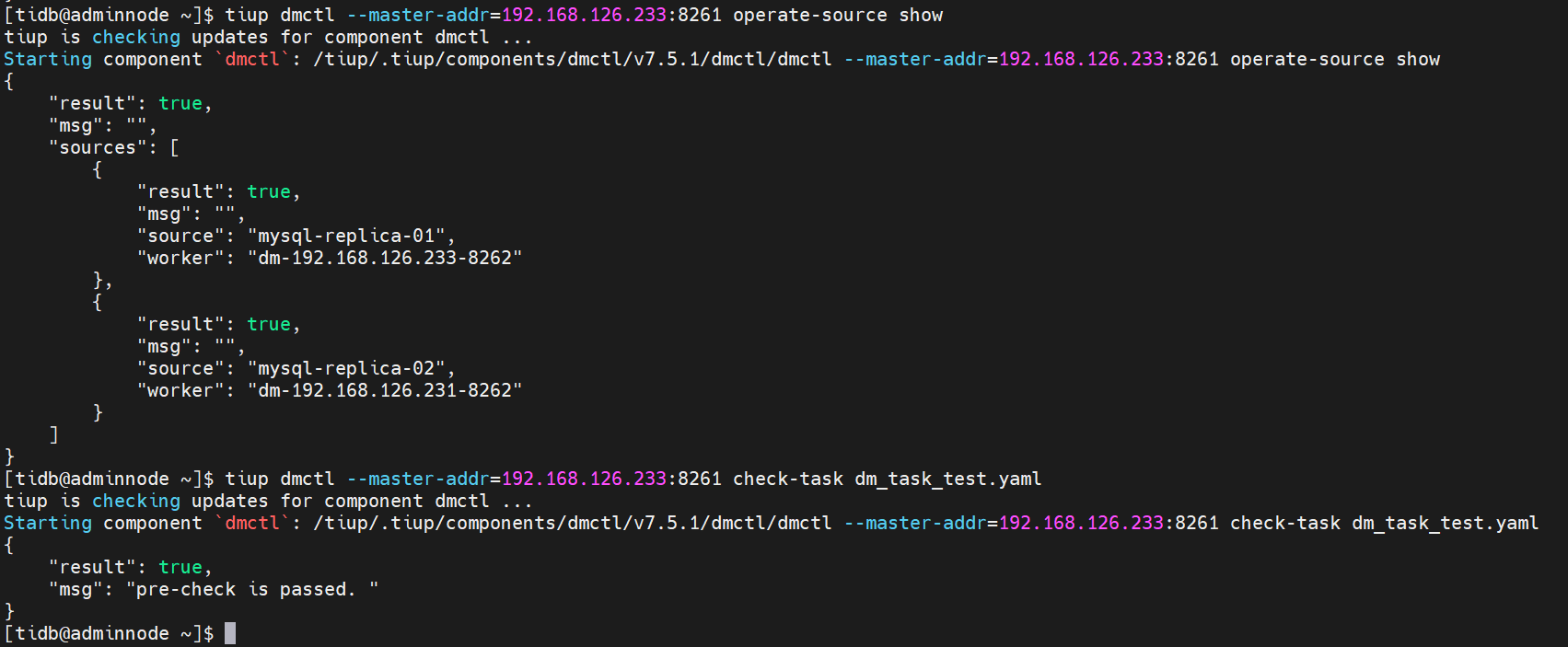
tiup dmctl --master-addr=192.128.126.233:8261 check-task dm-task.yaml
返回pre-check is passed.说明检查通过。
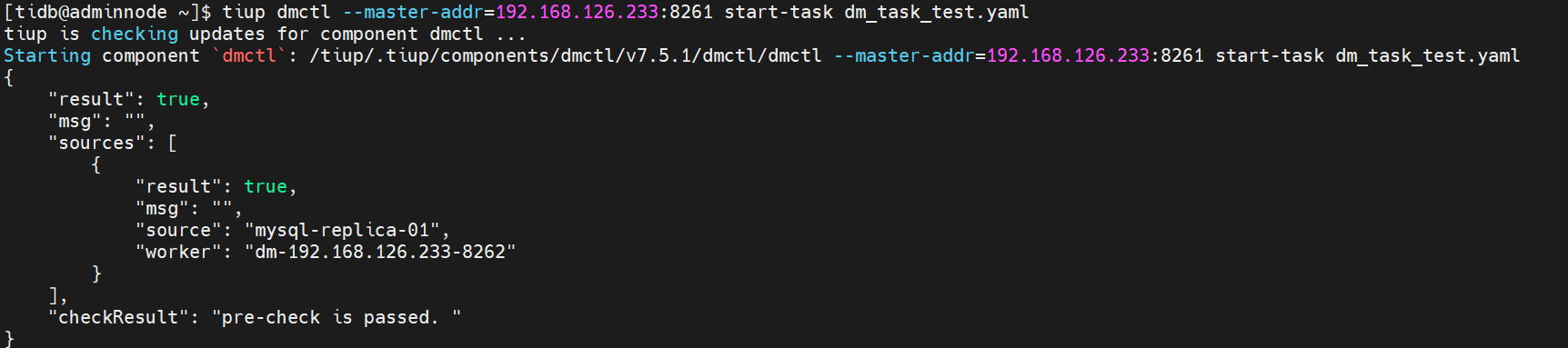
使用 tiup dmctl 执行以下命令启动数据迁移任务。
tiup dmctl --master-addr 192.168.126.233:8261 start-task dm-task. yaml
运行结果:
4、暂停与恢复
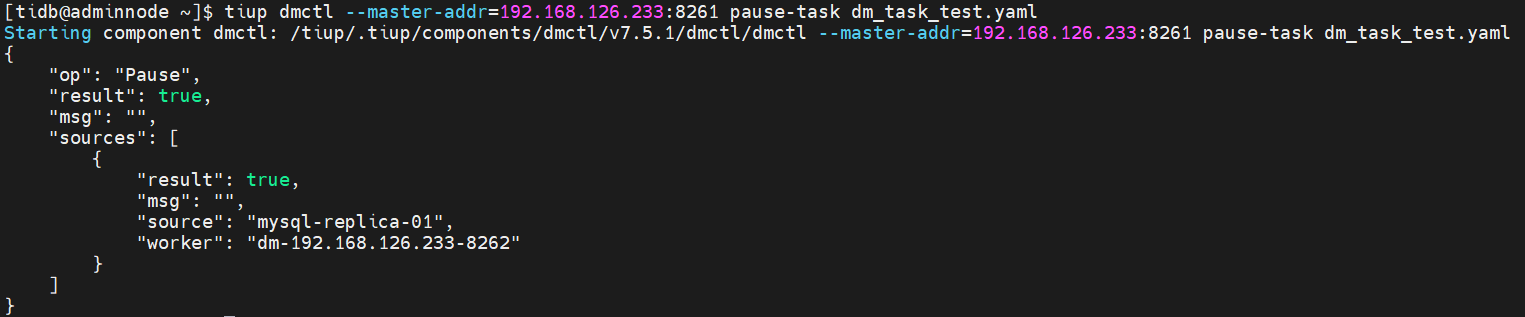
暂停任务
tiup dmctl --master-addr=192.168.126.233:8261 pause-task dm-task. yaml
恢复任务
tiup dmctl --master-addr=192.168.126.233:8261 resume-task dm-task. yaml
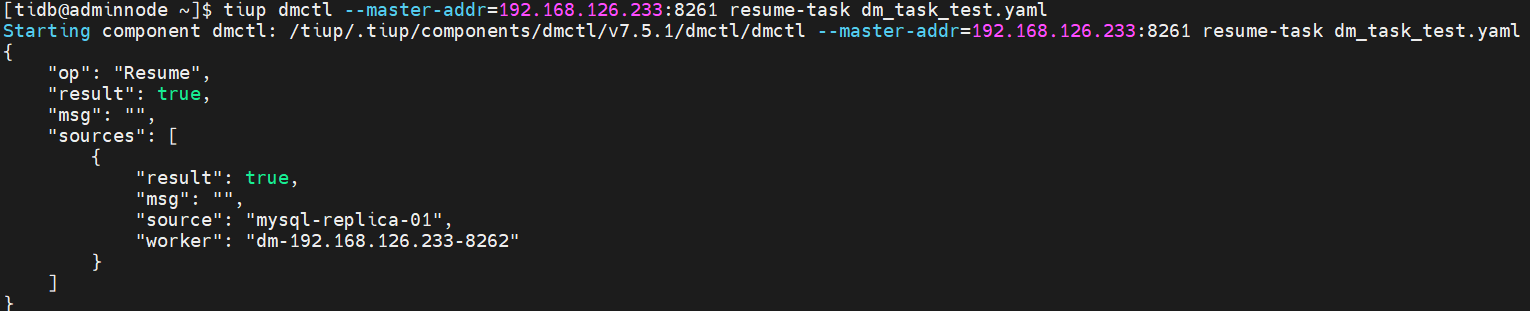
停止任务
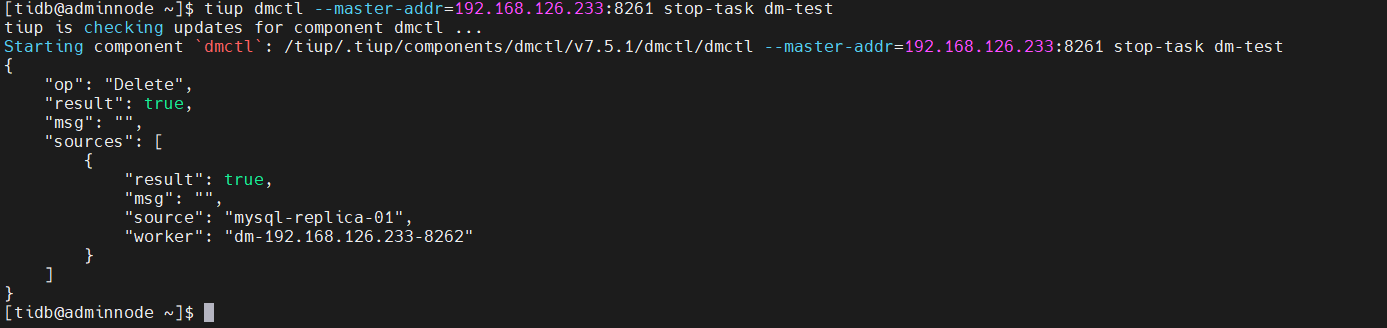
注意
有关 pause-task 与 stop-task 的区别如下:
- 使用 pause-task 仅暂停迁移任务的执行,但仍然会在内存中保留任务的状态信息等,且可通过 query-status 进行查询;使用 stop-task 会停止迁移任务的执行,并移除内存中与该任务相关的信息,且不可再通过 query-status 进行查询,但不会移除已经写入到下游数据库中的数据以及其中的 checkpoint 等 dm_meta 信息。
- 使用 pause-task 暂停迁移任务期间,由于任务本身仍然存在,因此不能再启动同名的新任务,且会阻止对该任务所需 relay log 的清理;使用 stop-task 停止任务后,由于任务不再存在,因此可以再启动同名的新任务,且不会阻止对 relay log 的清理。
- pause-task 一般用于临时暂停迁移任务以排查问题等;stop-task 一般用于永久删除迁移任务或通过与 start-task 配合以更新配置信息。
5、查看任务状态
如需了解 DM 集群中是否存在正在运行的迁移任务及任务状态等信息,可使用 tiup dmctl 执行 query-status 命令进行查询:
tiup dmctl --master-addr ${advertise-addr} query-status ${task-name}
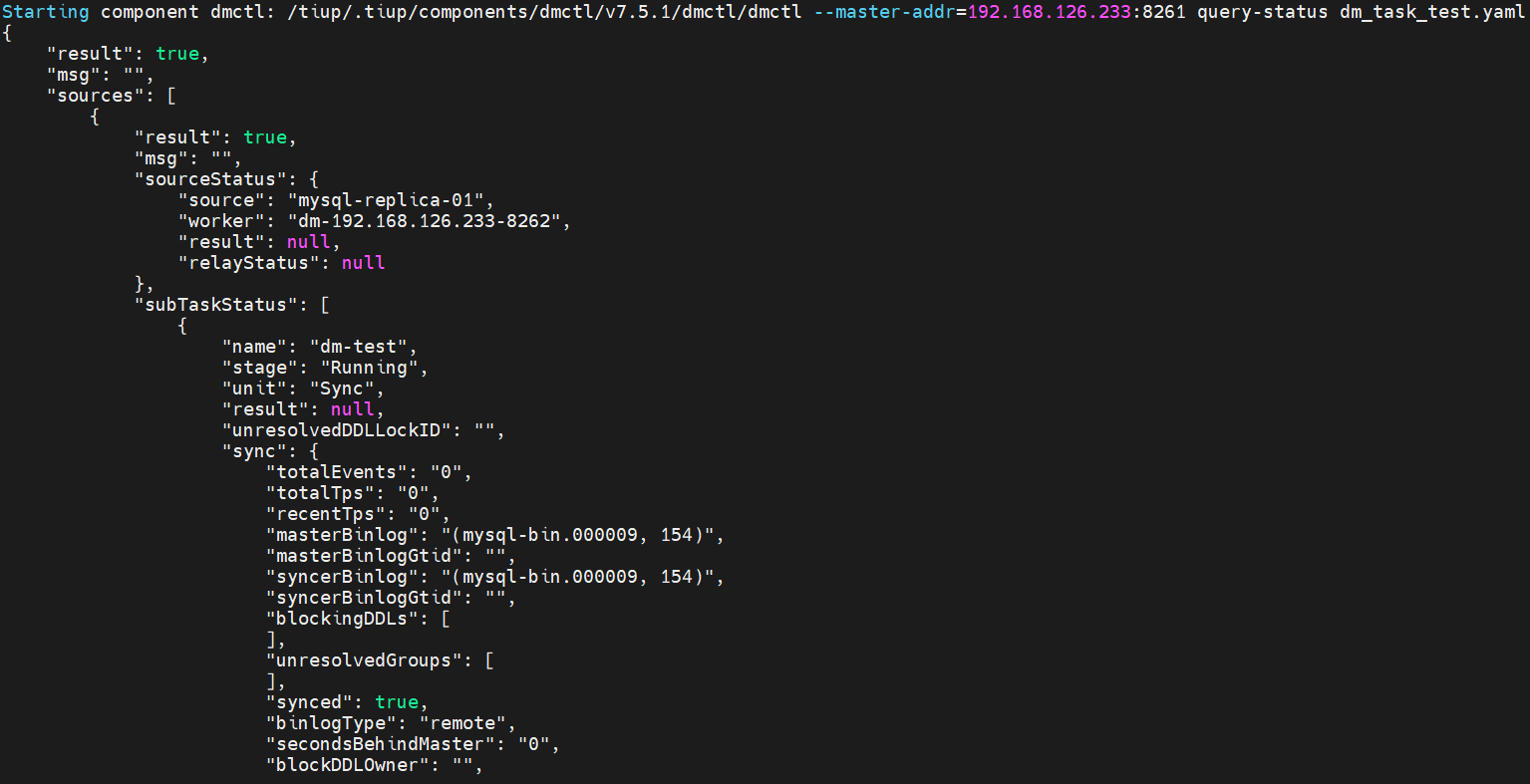
此外还有
6、监控任务与查看日志(日常巡检)
方法一:执行 query-status 命令查看任务运行状态以及相关错误输出。详见查询状态。
方法二:如果使用 TiUP 部署 DM 集群时正确部署了 Prometheus 与 Grafana,如 Grafana 的地址为 172.16.10.71,可在浏览器中打开 http://172.16.10.71:3000 进入 Grafana,选择 DM 的 Dashboard 即可查看 DM 相关监控项。
方法三:通过日志文件查看 DM 运行状态和相关错误。
DM 在运行过程中,DM-worker、DM-master 及 dmctl 都会通过日志输出相关信息。各组件的日志目录如下:
- DM-master 日志目录:通过 DM-master 进程参数 --log-file设置。如果使用 TiUP 部署 DM,则日志目录默认位于 /dm-deploy/dm-master-8261/log/。
- DM-worker 日志目录:通过 DM-worker 进程参数 --log-file 设置。如果使用 TiUP 部署 DM,则日志目录默认位于 /dm-deploy/dm-worker-8262/log/。
7、DM 集群数据源和任务配置的导出导入(元信息备份)
导出命令
tiup dmctl config --master-addr=192.168.126.233:8261 export
不指定默认到./ configs

导入
tiup dmctl config --master-addr=192.168.126.233:8261 import
不指定默认到./ configs

8、DM 性能配置优化
- 全量导出
- rows
- chunk-filesize
1.全量导出相关的配置项为 mydumpers,下面介绍和性能相关的参数如何配置。
设置 rows 选项可以开启单表多线程并发导出,值为导出的每个 chunk 包含的最大行数。开启后,DM 会在 MySQL 的单表并发导出时,优先选出一列做拆分基准,选择的优先级为主键 > 唯一索引 > 普通索引,选出目标列后需保证该列为整数类型(如 INT、MEDIUMINT、BIGINT 等)。
rows 的值可以设置为 10000,具体设置的值可以根据表中包含数据的总行数以及数据库的性能做调整。另外也需要设置 threads 来控制并发线程数量,默认值为 4,可以适当做些调整。
DM 全量备份时会根据 chunk-filesize 参数的值把每个表的数据划分成多个 chunk,每个 chunk 保存到一个文件中,大小约为 chunk-filesize。根据这个参数把数据切分到多个文件中,这样就可以利用 DM Load 处理单元的并行处理逻辑提高导入速度。该参数默认值为 64(单位为 MB),正常情况下不需要设置,也可以根据全量数据的大小做适当的调整。
注意
mydumpers 的参数值不支持在迁移任务创建后更新,所以需要在创建任务前确定好各个参数的值。如果需要更新,则需要使用 dmctl stop 任务后更新配置文件,然后再重新创建任务。
mydumpers.threads 可以使用配置项 mydumper-thread 替代来简化配置。
如果设置了 rows,DM 会忽略 chunk-filesize 的值。
- 全量导入
- pool-size
2.全量导入相关的配置项为 loaders,下面介绍和性能相关的参数如何配置。
pool-size 为 DM Load 阶段线程数量的设置,默认值为 16,正常情况下不需要设置,也可以根据全量数据的大小以及数据库的性能做适当的调整。
注意
loaders 的参数值不支持在迁移任务创建后更新,所以需要在创建任务前确定好各个参数的值。如果需要更新,则需要使用 dmctl stop 任务后更新配置文件,然后再重新创建任务。
loaders.pool-size 可以使用配置项 loader-thread 替代来简化配置。
- 增量复制
- worker-count
- batch
3.增量复制相关的配置为 syncers,下面介绍和性能相关的参数如何配置。
worker-count 为 DM Sync 阶段并发迁移 DML 的线程数量设置,默认值为 16,如果对迁移速度有较高的要求,可以适当调高改参数的值。
batch 为 DM Sync 阶段迁移数据到下游数据库时,每个事务包含的 DML 的数量,默认值为 100,正常情况下不需要调整。
注意
syncers 的参数值不支持在迁移任务创建后更新,所以需要在创建任务前确定好各个参数的值。如果需要更新,则需要使用 dmctl stop 任务后更新配置文件,然后再重新创建任务。
syncers.worker-count 可以使用配置项 syncer-thread 替代来简化配置。
worker-count 和 batch 的设置需要根据实际的场景进行调整,例如:DM 到下游数据库的网络延迟较高,可以适当调高 worker-count,调低 batch。
9、DM 数据迁移后的数据校验
在完成数据迁移后,建议对新旧数据进行数据一致性校验。TiDB 提供了相应的同步工具 sync-diff-inspector 来帮助你完成数据校验工作。
通过管理 DM 中的同步任务,sync-diff-inspector 可以自动管理需要进行数据一致性检查的 Table 列表,相较之前的手动配置更加的高效。具体参考基于 DM 同步场景下的数据校验。
七、问题总结
1、如何处理不兼容的 DDL 语句?
tiup dmctl --master-add r 192.168.126.233:8261 handle-error test skip
2、自增主键冲突处理
当使用TiDB Data Migration(以下简称 DM) 对分库分表进行合并迁移的场景中,可能会出现自增主键冲突的情况,建议采用以下两种处理方式:
1.去掉自增主键的主键属性。
2.使用联合主键。
3、任务配置变更处理
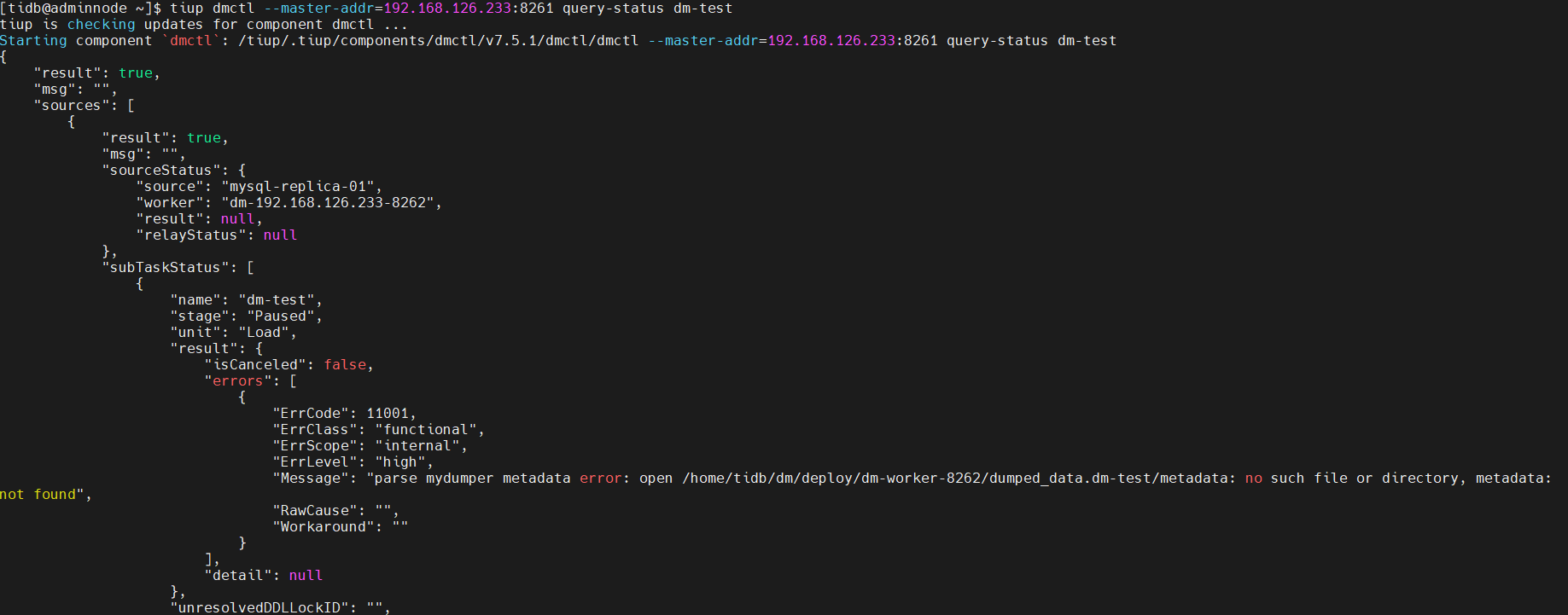
解决办法:
配置变更,停止任务,重新开始。
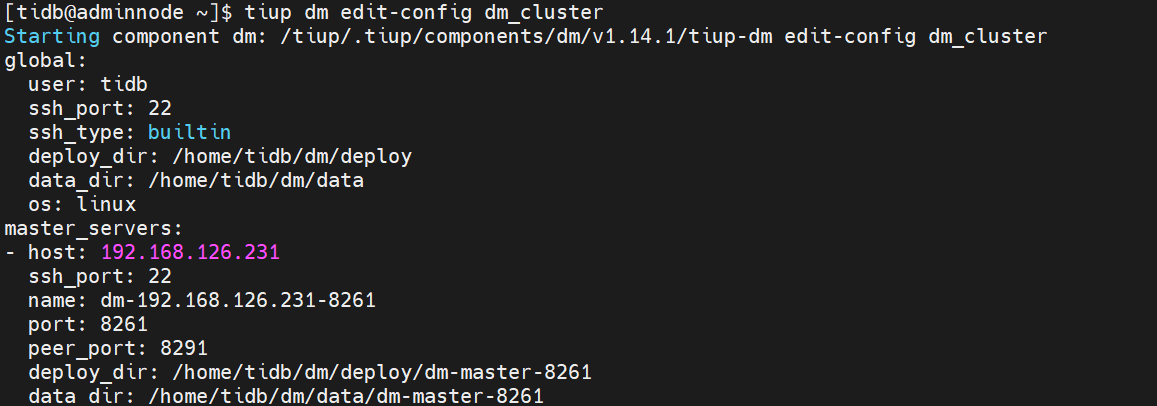
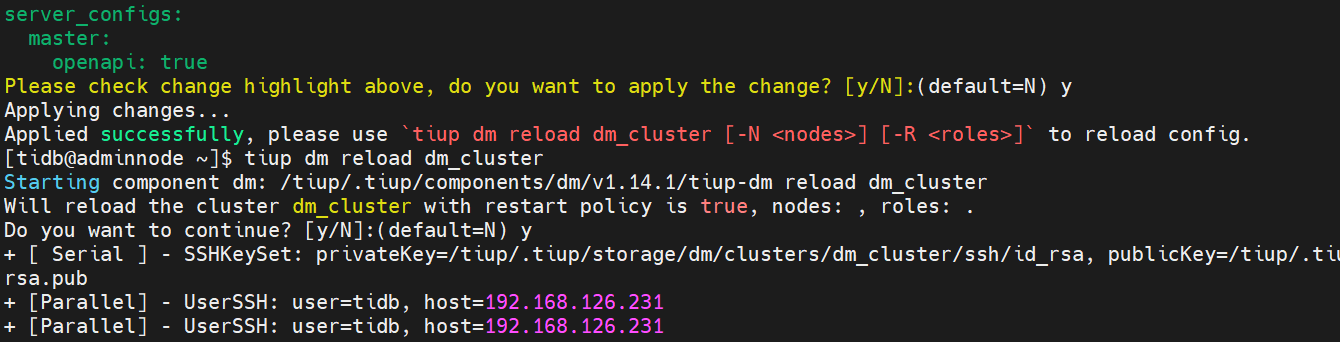
4、DM WebUI管理没有开启OpenAPI
编辑配置手工开启
tiup dm edit-config dm_cluster
tiup dm reload dm_cluster
5、DM迁移限制
如果你想把上游多个 MySQL 数据库实例合并迁移到下游的同一个 TiDB 数据库中,且数据量1 TiB 级别以下,你可以使用 DM 工具进行分库分表的合并迁移。
若要迁移分表总和 1 TiB 以上的数据,则 DM 工具耗时较长,可以使用TiDB Dumpling 和 Lightning工具。
DM迁移数据之后无法对新旧数据进行一致性校验,可以使用TiDB 提供了相应的同步工具 sync-diff-inspector。
评论

 0 点赞
0 点赞