1、环境介绍
操作系统 | CentOS Linux release 7.9.2009 (Core) |
数据库 | Oracle 19.20.0.0.0 |
数据库角色 | DG 数据库 |
CPU | 48核 96线程 |
内存 | 503G |
2、故障现象
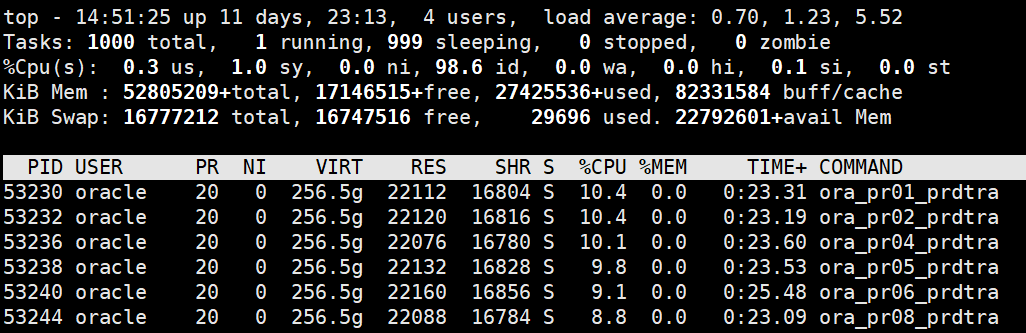
通过top命令,发现数据库服务器CPU使用率比较高,load average 部分显示的平均负载在60以上。
该dg数据库为最新搭建的,还未正式上线,不存在任何的用户连接。
3、故障处理
1)关闭日志应用
alter database recover managed standby database cancel;复制在关闭dg数据库的日志应用后,服务器的负载很快便会释放。

2)调整SGA参数配置
查看服务器内存占用,总体使用率并不高,但考虑到在配置服务器内核参数时,启用了大页内存,初步怀疑可能与大页内存分配过小,配置不合理,导致内存管理出了问题,进而影响到cpu的负载,故先对数据库SGA参数进行了降低处理。
alter system set sga_target=90G scope=spfile;
alter system set sga_max_size=90G scope=spfile;
alter system set db_cache_size=60G scope=spfile;
alter system set shared_pool_size=20G scope=spfile;复制将sga_target、sga_max_size 从256G 降低至90G
将db_cache_size 从154G 降低至60G
将shared_pool_size 从52G 降低至20G
重启数据库,使参数生效
shutdown immediate;
startup;复制3)启动日志应用
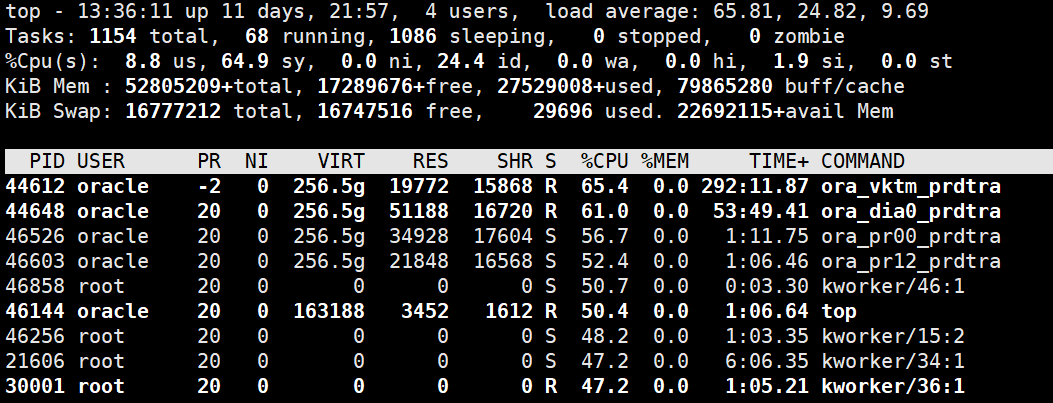
alter database recover managed standby database disconnect from session;复制调低SGA参数配置后,再次启动数据库的日志应用,此时服务器cpu使用率及平均负载依旧很高。
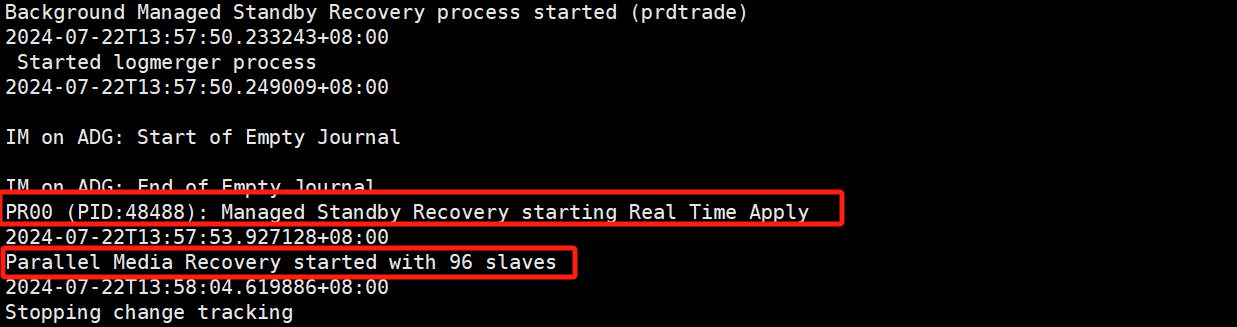
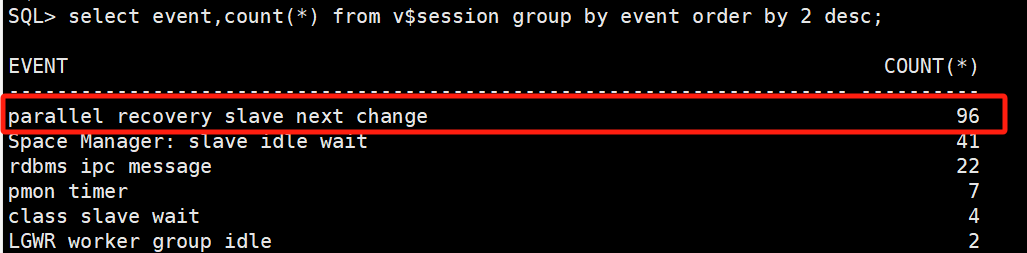
观察数据库alert日志,发现在启动日志应用后,伴随着mrp进程,还启动了96个并行的用于镜像恢复的子进程,这些进程恰好是cpu占用高的进程,且96正好对应服务器逻辑cpu个数。
select event,count(*) from v$session group by event order by 2 desc;复制查询数据库等待事件,存在名为” parallel recovery slave next change”的等待事件,数量为96.
ps -ef|grep ora_pr|grep -v "grep "|wc -l复制
4)调整cpu_count 参数
将cpu_count 参数降低一半,从96降低至48,用于限制数据库使用cpu的个数。
alter system set cpu_count=48 scope=spfile;复制重启数据库
shutdown immediate;
startup;复制5)再次启动日志应用
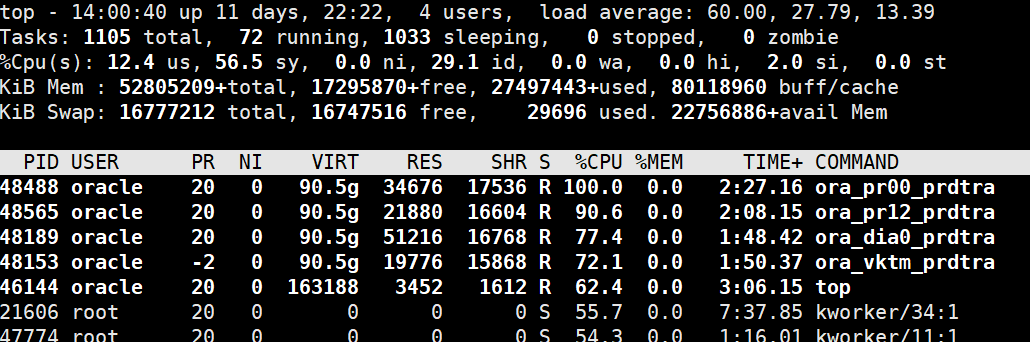
alter database recover managed standby database disconnect from session;复制观察alert日志,可以看到,伴随着mrp进程,本次只启动了48个进程用于镜像恢复。
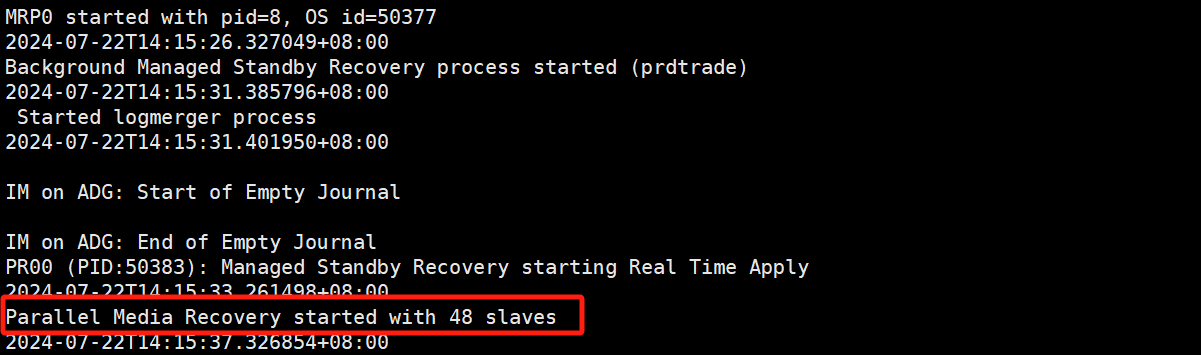
观察服务器负载,整体负载有所下降,已经降到了30左右,约为负载高峰时的一半。
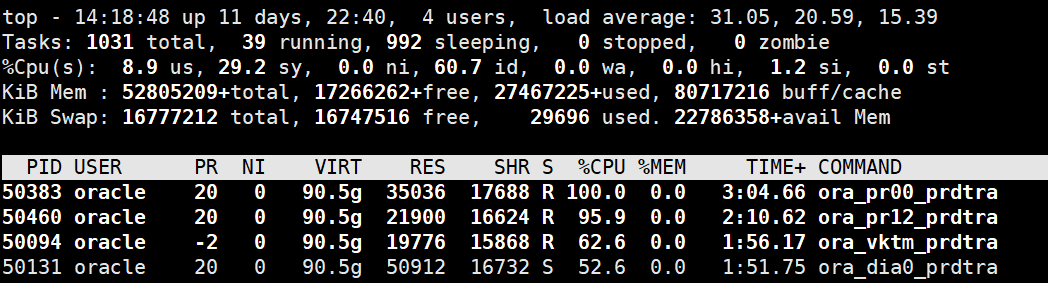
ps -ef|grep ora_pr|grep -v "grep "|wc -l复制
select event,count(*) from v$session group by event order by 2 desc;复制查询数据库等待事件,名为” parallel recovery slave next change”的等待事件个数已经降至48,与上述的cpu_count的参数以及alert日志记录相匹配
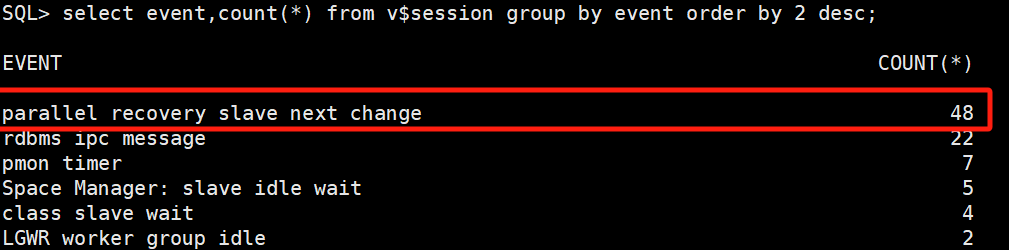
即启动日志应用的mrp 进程后,数据库还会根据可以使用的cpu个数,来启动相应的用于镜像恢复的进程。其在服务器中对应为ora_pr 开头的进程,在数据库中对应为” parallel recovery slave next change”等待事件的个数。
6)重启日志应用并配置并行
经过上述分析调整,在降低cpu_count 参数后,服务器的负载可以有明显的降低。故可以通过在启动日志应用时,添加 parallel 参数,进而限制日志应用的并行度,减少启动的进程,达到降低cpu 使用率的目的。
这里先将上述调整过的SGA等参数调回原值,并重启数据库。
alter system set sga_target=256G scope=spfile;
alter system set sga_max_size=256G scope=spfile;
alter system set db_cache_size=154G scope=spfile;
alter system set shared_pool_size=52G scope=spfile;
alter system set cpu_count=96 scope=spfile;
shutdown immediate;
startup;复制本案例中,实际数据量较小,共配置了8个并行来启动日志应用
alter database recover managed standby database parallel 8 disconnect from session;复制调整数据库日志应用的并行度后,服务器的cpu使用率以及负载已经降至正常状态,问题解决。