




DeepSeek 携手 Oracle in-memory 新特性:统计对象存储访问情况的神奇之旅
大家好,我是 JiekeXu,江湖人称“强哥”,青学会 MOP 技术社区主席,荣获 Oracle ACE Pro 称号,墨天轮 MVP,墨天轮年度“墨力之星”,拥有 Oracle OCP/OCM 认证,MySQL 5.7/8.0 OCP 认证以及 PCA、PCTA、OBCA、OGCA、金仓KCA、KCP 等众多国产数据库认证证书,今天和大家一起来看看DeepSeek 携手 Oracle in-memory 新特性:统计对象存储访问情况的神奇之旅!欢迎关注我的微信公众号“JiekeXu DBA之路”,然后点击右上方三个点“设为星标”置顶,更多干货文章才能第一时间推送,谢谢!
前 言
需求:有一个有 6 千多万的 txt 数据文件需要导入到数据库,起初同事自己将文件导入到 MySQL 数据库中,借助 DeepSeek 创建了表和索引并导入了数据,接着写出了几个 SQL,但是查询到第三个 SQL 的时候第二天早上也没出结果,于是第二天我就来活了,领导让我找一台 Oracle 闲置机器,导入数据进行测试。
所以首先需要一个 12c 以上的数据库,然后创建用户表空间等。
一、安装 Oracle 19c 数据库
因 inmemory 功能是在 Oracle 12c 以后新出的特性,故需要 12c 以上的数据库才能运行。
安装数据库软件
安装过程省略,此处仅列出简要步骤。
unzip LINUX.X64_193000_db_home.zip -d $ORACLE_HOME
cd $ORACLE_HOME
mv OPatch/ OPatch_BAK
cp -r /u01/soft/OPatch/ ./
opatch version
OPatch Version: 12.2.0.1.30
OPatch succeeded.
$ORACLE_HOME/runInstaller -ignorePrereq -waitforcompletion -silent -applyRU /u01/soft/36209493/36233126/36233263 -responseFile /home/oracle/db_install.rsp
执行 root 脚本
# sh /u01/app/oraInventory/orainstRoot.sh
# sh /u01/app/oracle/product/19.0.0/dbhome_1/root.sh
dbca 创建一个数据库实例
dbca -silent -createDatabase -templateName General_Purpose.dbc -responseFile NO_VALUE \ -gdbname test -sid test \ -createAsContainerDatabase false \ -sysPassword Oracle_19C -systemPassword Oracle_19C \ -datafileDestination '/data/test/oradata' \ -recoveryAreaDestination '/data/test/flash_recovery_area' \ -redoLogFileSize 2048 \ -storageType FS \ -characterset AL32UTF8 -nationalCharacterSet AL16UTF16 \ -sampleSchema true \ -totalMemory 28192 \ -databaseType MULTIPURPOSE \ -emConfiguration NONE
创建表空间和用户
SQL> create tablespace test datafile '/data/test/oradata/TEST/test01.dbf' size 30g;
Tablespace created.
SQL> CREATE USER test IDENTIFIED BY test
2 DEFAULT TABLESPACE test
3 QUOTA unlimited ON test
4 TEMPORARY TABLESPACE temp;
User created.
SQL> GRANT CREATE SESSION TO test ;
Grant succeeded.
SQL> GRANT CREATE table TO test ;
Grant succeeded.
SQL> GRANT CREATE VIEW TO test ;
Grant succeeded.
SQL> GRANT CREATE TRIGGER TO test ;
GRANT CREATE database link TO test ;
Grant succeeded.
Grant succeeded.
SQL> GRANT CREATE public database link TO test ;
Grant succeeded.
SQL> GRANT CREATE MATERIALIZED VIEW to test ;
Grant succeeded.
SQL> GRANT CREATE public database link TO test ;
GRANT CREATE PROCEDURE to test ;
Grant succeeded.
Grant succeeded.
SQL> GRANT CREATE sequence to test ;
Grant succeeded.
SQL> GRANT CREATE MATERIALIZED VIEW to test ;
Grant succeeded.
SQL>
SQL> GRANT CREATE public database link TO test ;
Grant succeeded.
SQL> GRANT CREATE PROCEDURE to test ;
Grant succeeded.
SQL> GRANT CREATE sequence to test ;
Grant succeeded.
二、SQLLDR导入数据
--上传整理好的日志文件数据 [root@JiekeXu test]# wc -l data.txt 62513584 data.txt [root@JiekeXu test]# head -2 data.txt 192.168.46.130 2025-03-04 01:10:00 0c002e82:18c950da549:3f2bc1:1bfd s3 GET 200 110813 2 ns1 cc-fileserver-prd-static /system/jt-receipt-icon.png bb 192.168.46.130 2025-03-04 01:10:00 0c002e82:18c950da549:3f3120:ac1 s3 GET 200 131145 4 ns1 cc-fileserver-prd-2025 /292a6fcd-85ea-4a98-bda5-5181dbc9fccf/202503/04/62f58b35-b1e0-4e2b-b291-a5994123925d.pdf --创建符合条件的表结构 CREATE TABLE test.access_logs ( id NUMBER GENERATED ALWAYS AS IDENTITY PRIMARY KEY, node VARCHAR2(500), time TIMESTAMP , request_id VARCHAR2(64) , prot VARCHAR2(10) , type VARCHAR2(10) , status NUMBER(5) , oss_size NUMBER(12) , resp_time NUMBER(5) , namespace VARCHAR2(50) , bucket VARCHAR2(128) , object VARCHAR2(4000), options VARCHAR(1000) );
创建控制文件
vim load_data.ctl LOAD DATA INFILE 'data.txt' BADFILE 'data.bad' DISCARDFILE 'data.dsc' APPEND INTO TABLE access_logs FIELDS TERMINATED BY ',' TRAILING NULLCOLS ( node, time TIMESTAMP "YYYY-MM-DD HH24:MI:SS", request_id, prot, type, status, oss_size, resp_time, namespace, bucket, object, options )
导入数据
nohup sqlldr userid=test/test control=load_data.ctl log=load_data.log > temp3.log & Table ACCESS_LOGS: 62513567 Rows successfully loaded. 17 Rows not loaded due to data errors. 0 Rows not loaded because all WHEN clauses were failed. 0 Rows not loaded because all fields were null. Space allocated for bind array: 774000 bytes(250 rows) Read buffer bytes: 1048576 Total logical records skipped: 0 Total logical records read: 62513584 Total logical records rejected: 17 Total logical records discarded: 0 Run began on Fri Mar 14 14:12:20 2025 Run ended on Fri Mar 14 14:27:01 2025 Elapsed time was: 00:14:40.66 CPU time was: 00:02:49.62
可以看见只花费了 14 分钟就插入了 6251w 条数据。
当然还有十几条错误的数据没有导入进去,因对象文件路径存在过多的百分号,varchar4000 存不下,也不是我们需要的数据,故不做处理,否则需要手动 insert 插入到表里。
insert into test.access_logs(object) values(
'/excel_tmplate/%E4%BA%A4%E6%98%93%E4%BF%A1%E6%81%AF%E6%89%B9%E9%87%8F%E6%96%B0%E5%A2%9E%E6%A8%A1%E7%89%88%EF%BC%88%E9%85%8D%E7%BD%AE%E6%A0%B8%E5%BF%83%E7%BB%8F%E5%8A%9E%E5%BD%95%E5%85%A5%2B%E8%87%AA%E5%AE%9A%E4%B9%89%E6%81%AF%E8%B4%B9%E5%85%B3%E9%97%AD%EF%BC%89.xlsx')
三、表相关设置
收集统计信息
EXEC DBMS_STATS.gather_TABLE_STATS('TEST','ACCESS_LOGS');
创建索引
--创建索引
create index idx_bucket_object_time_type on test.access_logs ('bucket','object','time','type') online;
create index idx_time_type on test.access_logs ('time','type') online;
inmemory 内存配置
--https://docs.oracle.com/en/database/oracle/oracle-database/19/inmem/intro-to-in-memory-column-store.html#GUID-B4DC96ED-0907-4974-9347-2FFBC24EBBDB
sqlplus / as sysdba
show parameter sga --21152M
--设置 INMEMORY 大小并重启数据库,注意需要大于 100M 才行。
ALTER SYSTEM SET INMEMORY_SIZE=10G SCOPE=SPFILE;
shu immediate
15:53:20 SYS@test> startup
ORACLE instance started.
Total System Global Area 2.2179E+10 bytes
Fixed Size 13642848 bytes
Variable Size 1677721600 bytes
Database Buffers 9730785280 bytes
Redo Buffers 19910656 bytes
In-Memory Area 1.0737E+10 bytes
Database mounted.
Database opened.
15:53:35 SYS@test> SHOW PARAMETER inmemory_size
inmemory_size big integer 10G
15:53:56 SYS@test> show parameter sga
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
allow_group_access_to_sga boolean FALSE
lock_sga boolean FALSE
pre_page_sga boolean TRUE
sga_max_size big integer 21152M
sga_min_size big integer 0
sga_target big integer 21152M
unified_audit_sga_queue_size integer 1048576
15:54:02 SYS@test> SELECT NAME, VALUE/(1024*1024*1024) "SIZE_IN_GB" FROM V$SGA WHERE NAME LIKE '%Mem%';
NAME SIZE_IN_GB
------------------------------ ----------
In-Memory Area 10
15:54:06 SYS@test> !free -m
total used free shared buff/cache available
Mem: 31490 1264 11512 10916 18713 18869
Swap: 16383 0 16383
15:54:18 SYS@test> show parameter cpu
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
cpu_count integer 8
cpu_min_count string 8
parallel_threads_per_cpu integer 1
resource_manager_cpu_allocation integer 0
15:54:25 SYS@test> alter system set inmemory_max_populate_servers=8;
System altered.
加载表到 inmemory 内存
alter table test.server_logs inmemory;
--移除内存
alter table test.server_logs no inmemory;
加载表到 inmemory 后,即使用列存储格式,使用 IM 列存储时,数据库可以仅扫描请求的列,从而完全避免使用磁盘。以列式格式扫描数据,仅将必要的列管道传输到 CPU,从而提高效率。每个 CPU 内核都使用 SIMD 向量指令扫描本地内存中的列。而使用缓冲区缓存时,数据库通常会扫描索引以查找产品 ID,使用 rowid 将行从磁盘提取到缓冲区缓存中,然后丢弃不需要的列值。在缓冲区缓存中以行格式扫描数据需要许多 CPU 指令,并且可能导致 CPU 效率欠佳。
查看 IM 内存使用情况
SELECT
(SELECT SUM(used_bytes) FROM v$inmemory_area) /
(SELECT value FROM v$parameter WHERE name = 'inmemory_size') * 100 "Usage (%)"
FROM dual;
-- 通过 V$IM_SEGMENTS 视图查看具体对象的内存占用
SELECT segment_name,
ROUND(bytes/(1024*1024)) "Size (MB)",
inmemory_priority,
inmemory_compression,
populate_status
FROM v$im_segments;
--INMEMORY_PRIORITY:对象的优先级(如CRITICAL, HIGH等,影响填充顺序)。
--POPULATE_STATUS:是否已加载到内存(如COMPLETED表示完成)。
-- V$INMEMORY_AREA 视图确定每个子池中的可用内存量(包括示例输出)
COL POOL FORMAT a9
COL POPULATE_STATUS FORMAT a15
SELECT POOL, TRUNC(ALLOC_BYTES/(1024*1024*1024),2) "ALLOC_GB",
TRUNC(USED_BYTES/(1024*1024*1024),2) "USED_GB",
POPULATE_STATUS
FROM V$INMEMORY_AREA;
POOL ALLOC_GB USED_GB POPULATE_STATUS
--------- ---------- ---------- ---------------
1MB POOL 6.99 6.98 DONE
64KB POOL 2.97 .01 DONE
四、DeepSeek协助
使用 DeepSeek 结合表结构让协助我们书写相关需求 SQL 用来统计数据。
在Oracle19c数据库中有如下一张表,字段含义如下:
CREATE TABLE test.access_logs (
id NUMBER GENERATED ALWAYS AS IDENTITY PRIMARY KEY, --主键,递增序列
node VARCHAR2(500), --节点IP
time TIMESTAMP , --请求时间
request_id VARCHAR2(64) , --请求ID
prot VARCHAR2(10) , --请求协议
type VARCHAR2(10) , --请求类型put/get/head
status NUMBER(5) , --状态码
oss_size NUMBER(12) , --请求大小
resp_time NUMBER(5) , --响应时间
namespace VARCHAR2(50) , --命名空间
bucket VARCHAR2(128) , --存储桶
object VARCHAR2(4000), --对象名
options VARCHAR(1000) --(可选)请求参数
);
现在需要你帮我写一条 SQL 查询 满足以下条件的对象数:
1、从2025年2月14日起在第一次 put 请求后被访问的次数大于3次
一会儿之后,便给出了我们需要的 SQL,通过 with as 的写法,我们来看看执行结果和执行计划。
WITH first_put AS (
-- 步骤 1: 获取每个对象在 2025-02-14 及之后的第一次 PUT 请求时间
SELECT
bucket,
object,
MIN(time) AS first_put_time
FROM test.access_logs
WHERE type = 'PUT' -- 过滤 PUT 请求
AND time >= TIMESTAMP '2025-02-14 00:00:00' -- 起始时间限定
GROUP BY bucket, object
)
SELECT COUNT(*) AS object_count
FROM (
-- 步骤 2: 统计每个对象在第一次 PUT 之后的访问次数
SELECT
a.bucket,
a.object
FROM test.access_logs a
JOIN first_put f
ON a.bucket = f.bucket
AND a.object = f.object
WHERE a.time >= f.first_put_time -- 仅统计第一次 PUT 之后的访问
GROUP BY a.bucket, a.object
HAVING COUNT(*) > 3 -- 筛选访问次数 >3 的对象
) subquery;
如下,SQL 查询还是很快的,看执行计划在内存中全表扫 “TABLE ACCESS INMEMORY FULL”。
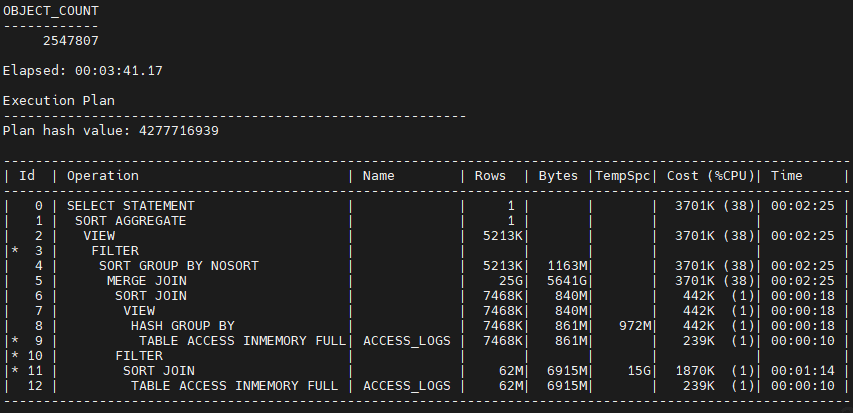

最后,通过人工核对和 DeepSeek 的协助,最终计算出来如下的结果,每一个格都需要通过 SQL 计算,也是花费了很大代价和时间,计算的具体 SQL 也就不展示了,也不算重点,直接略过了。

五、其他相关 SQL
select /*+ parallel(8) */ count(distinct(object)) from test.access_logs;
TEST@test> ALTER TABLE access_logs ADD oid VARCHAR2(4000);
TEST@test> update test.access_logs set oid=BUCKET || OBJECT ;
62513567 rows updated.
Elapsed: 00:19:45.92
TEST@test> commit;
--更新 6251w 数据仅需19分钟,表大小 12.9 GB,内存表速度还是比较快的,普通表可能需要好几个小时。
SYS@test> select sum(bytes)/1024/1024/1024 Gb from dba_segments where segment_name='ACCESS_LOGS';
GB
----------
12.9375
select sid,SERIAL#,OPNAME,TARGET,START_TIME from v$session_longops where TARGET='TEST.ACCESS_LOGS' and sid=382;
全文完,希望可以帮到正在阅读的你,如果觉得有帮助,可以分享给你身边的朋友,同事,你关心谁就分享给谁,一起学习共同进步~~~
❤️ 欢迎关注我的公众号【JiekeXu DBA之路】,一起学习新知识!
——————————————————————————
公众号:JiekeXu DBA之路
墨天轮:https://www.modb.pro/u/4347
CSDN :https://blog.csdn.net/JiekeXu
ITPUB:https://blog.itpub.net/69968215
腾讯云:https://cloud.tencent.com/developer/user/5645107
——————————————————————————

