




JSON 数据类型是 MySQL 5.7.8 开始支持的。在此之前,只能通过字符类型(CHAR,VARCHAR 或 TEXT )来保存 JSON 文档。MySQL 8.0版本中增加了对JSON类型的索引支持。可以使用CREATE INDEX语句创建JSON类型的索引,提高JSON类型数据的查询效率。
存储JSON文档所需的空间与存储LONGBLOB或LONGTEXT所需的空间大致相同。在MySQL 8.0.13之前,JSON列不能有非空的默认值。JSON 类型比较适合存储一些列不固定、修改较少、相对静态的数据。MySQL支持JSON格式的数据之后,可以减少对非关系型数据库的依赖。
实战:假设有这样一个去求,某个图书管理系统的业务是存图书,根据图书的属性查询图书。图书的属性有很多,我们暂且假设有10个熟悉吧。包含标题、作者、流派、出版年份、出版商、ISBN、语言、页数、评分和价格等属性。
怎么存储数据呢?
方式1:反三范式,建立宽表,把所有的属性全部列出来。
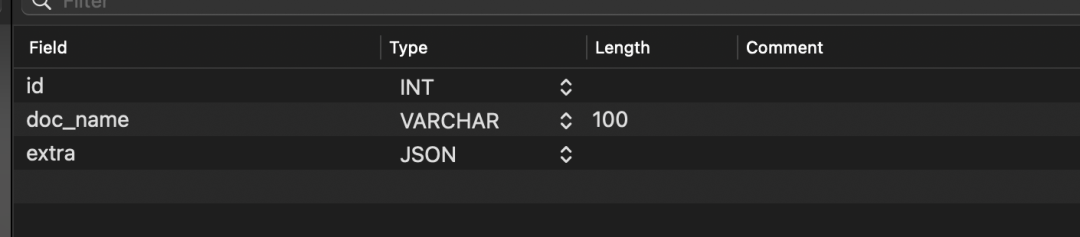
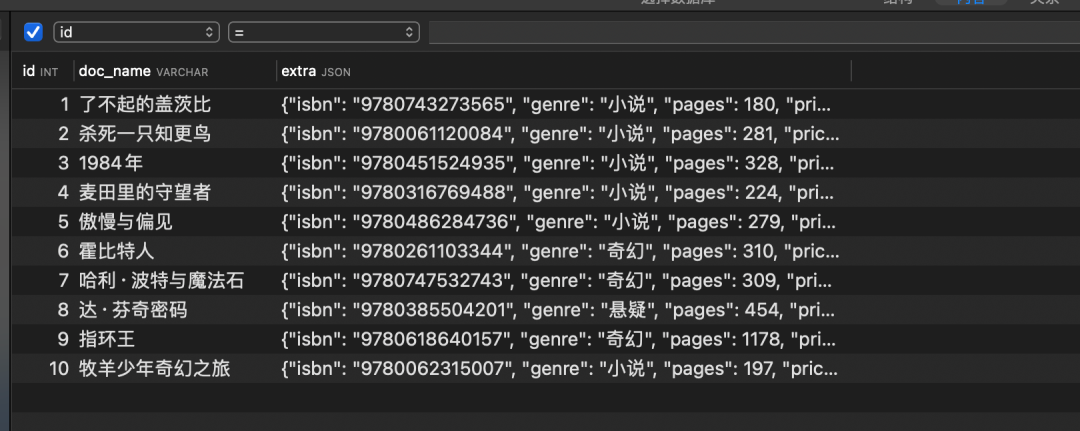
模拟插入十行数据。
INSERT INTO `document` (`id`, `doc_name`, `extra`)
VALUES
(1, '了不起的盖茨比', '{\"isbn\": \"9780743273565\", \"genre\": \"小说\", \"pages\": 180, \"price\": 10.99, \"title\": \"了不起的盖茨比\", \"author\": \"F·斯科特·菲茨杰拉德\", \"rating\": 4.2, \"language\": \"英语\", \"publisher\": \"斯克里布纳\", \"publication_year\": 1925}'),
(2, '杀死一只知更鸟', '{\"isbn\": \"9780061120084\", \"genre\": \"小说\", \"pages\": 281, \"price\": 12.5, \"title\": \"杀死一只知更鸟\", \"author\": \"哈珀·李\", \"rating\": 4.5, \"language\": \"英语\", \"publisher\": \"利普丘克\", \"publication_year\": 1960}'),
(3, '1984年', '{\"isbn\": \"9780451524935\", \"genre\": \"小说\", \"pages\": 328, \"price\": 9.99, \"title\": \"1984年\", \"author\": \"乔治·奥威尔\", \"rating\": 4.6, \"language\": \"英语\", \"publisher\": \"塞克与沃尔堡\", \"publication_year\": 1949}'),
(4, '麦田里的守望者', '{\"isbn\": \"9780316769488\", \"genre\": \"小说\", \"pages\": 224, \"price\": 11.25, \"title\": \"麦田里的守望者\", \"author\": \"J.D.塞林格\", \"rating\": 4.0, \"language\": \"英语\", \"publisher\": \"小布朗\", \"publication_year\": 1951}'),
(5, '傲慢与偏见', '{\"isbn\": \"9780486284736\", \"genre\": \"小说\", \"pages\": 279, \"price\": 8.75, \"title\": \"傲慢与偏见\", \"author\": \"简·奥斯汀\", \"rating\": 4.7, \"language\": \"英语\", \"publisher\": \"T.埃格顿\", \"publication_year\": 1813}'),
(6, '霍比特人', '{\"isbn\": \"9780261103344\", \"genre\": \"奇幻\", \"pages\": 310, \"price\": 14.99, \"title\": \"霍比特人\", \"author\": \"J.R.R.托尔金\", \"rating\": 4.8, \"language\": \"英语\", \"publisher\": \"乔治·艾伦与温恩\", \"publication_year\": 1937}'),
(7, '哈利·波特与魔法石', '{\"isbn\": \"9780747532743\", \"genre\": \"奇幻\", \"pages\": 309, \"price\": 13.5, \"title\": \"哈利·波特与魔法石\", \"author\": \"J.K.罗琳\", \"rating\": 4.9, \"language\": \"英语\", \"publisher\": \"布鲁姆斯伯里\", \"publication_year\": 1997}'),
(8, '达·芬奇密码', '{\"isbn\": \"9780385504201\", \"genre\": \"悬疑\", \"pages\": 454, \"price\": 16.75, \"title\": \"达·芬奇密码\", \"author\": \"丹·布朗\", \"rating\": 4.3, \"language\": \"英语\", \"publisher\": \"道布尔戴\", \"publication_year\": 2003}'),
(9, '指环王', '{\"isbn\": \"9780618640157\", \"genre\": \"奇幻\", \"pages\": 1178, \"price\": 24.99, \"title\": \"指环王\", \"author\": \"J.R.R.托尔金\", \"rating\": 4.7, \"language\": \"英语\", \"publisher\": \"乔治·艾伦与温恩\", \"publication_year\": 1954}'),
(10, '牧羊少年奇幻之旅', '{\"isbn\": \"9780062315007\", \"genre\": \"小说\", \"pages\": 197, \"price\": 11.0, \"title\": \"牧羊少年奇幻之旅\", \"author\": \"保罗·柯艾略\", \"rating\": 4.6, \"language\": \"英语\", \"publisher\": \"哈珀柯林斯\", \"publication_year\": 1988}')复制
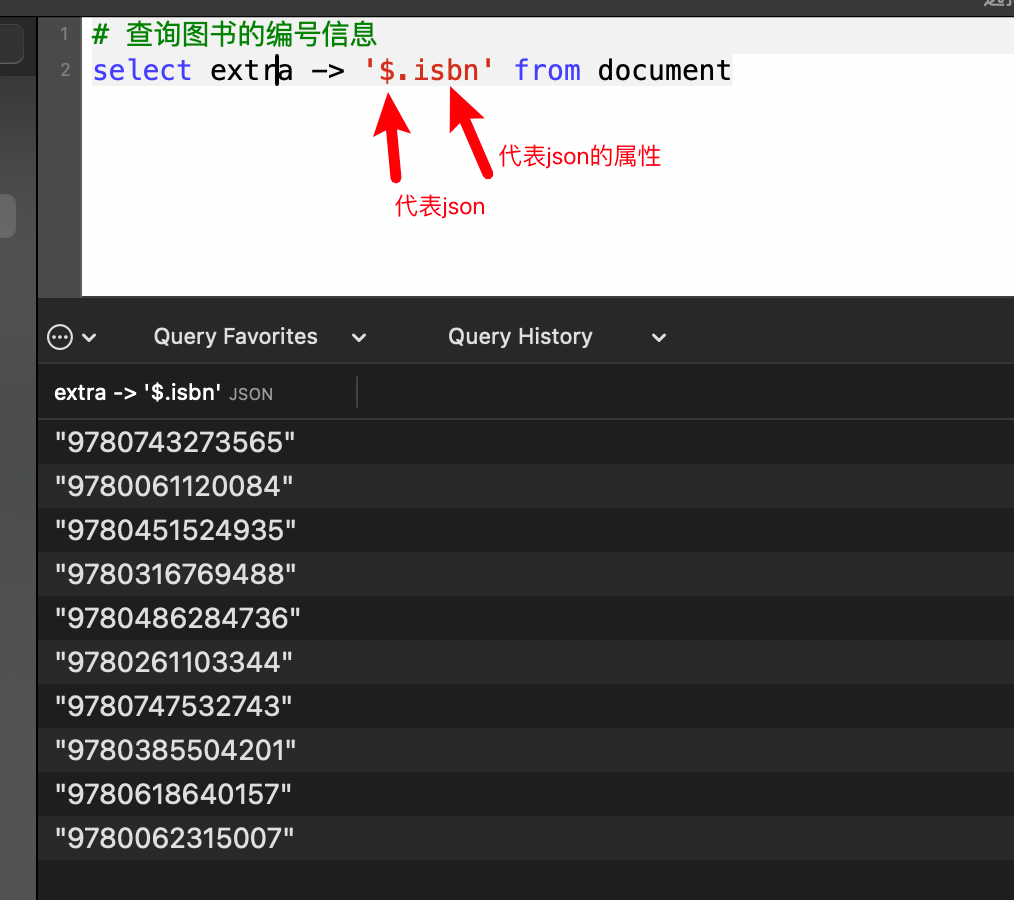
# 查询图书的编号信息
select extra -> '$.isbn' from document复制
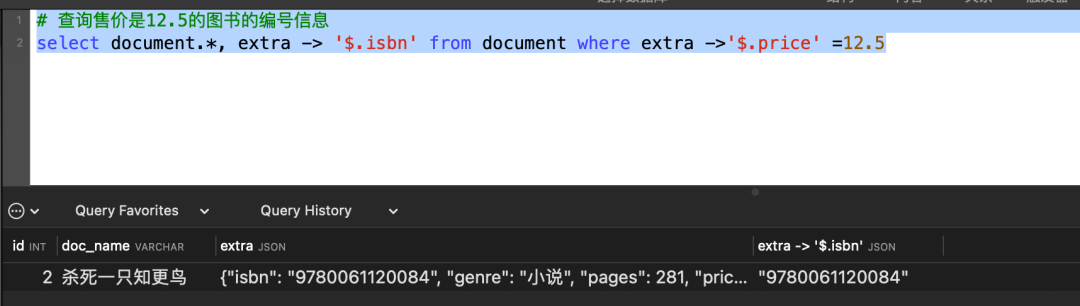
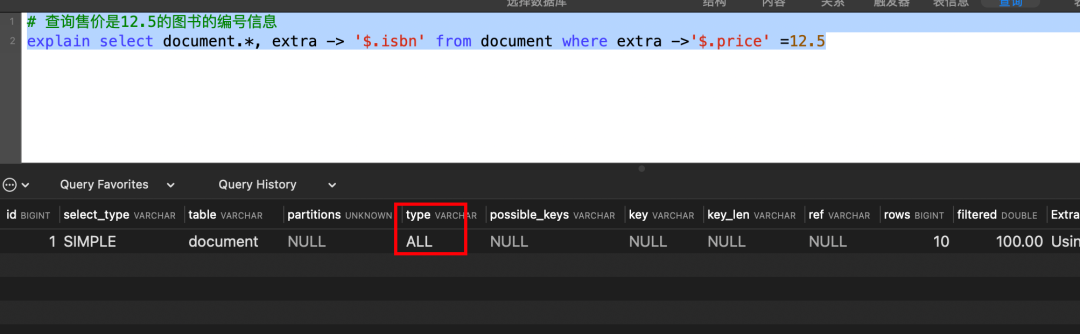
# 查询售价是12.5的图书的编号信息
select document.*, extra -> '$.isbn' from document where extra ->'$.price' =12.5复制
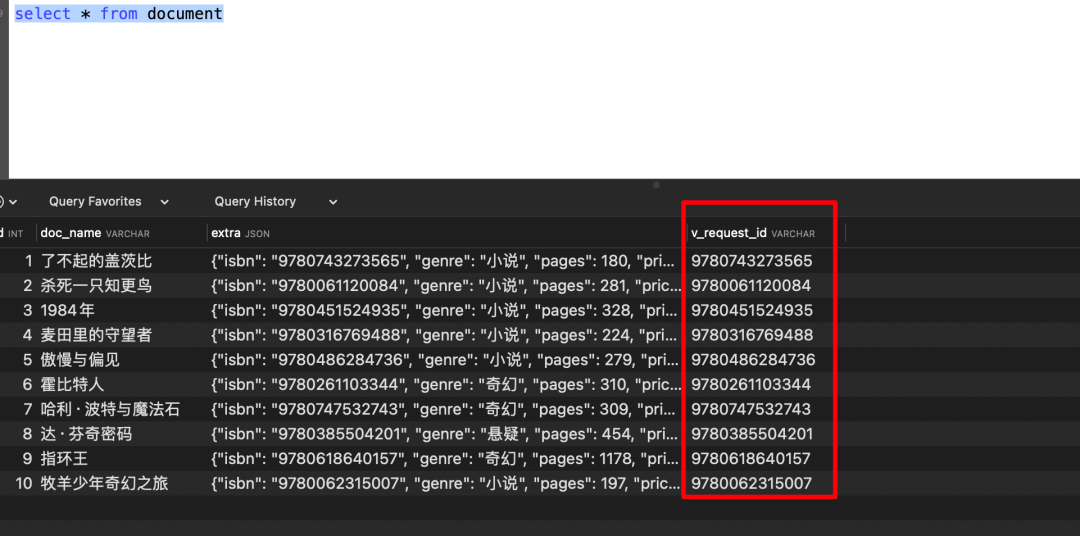
ALTER TABLE document
Add Column `v_request_id` varchar(32)
GENERATED ALWAYS AS (json_unquote(json_extract(`extra`,_utf8mb4'$.isbn'))) VIRTUAL NULL;复制
这条 SQL 语句:用于向名为 document 的表中添加一个名为 v_request_id 的虚拟列。我来详细解释一下:
ALTER TABLE document: 这是告诉数据库你要修改名为 document 的表的结构。
ADD COLUMN v_request_id varchar(32): 这部分是指定要添加的新列的名称和数据类型。在这里,我们添加了一个名为 v_request_id 的列,其数据类型为 varchar(32),即最大长度为 32 个字符的字符串。
GENERATED ALWAYS AS (json_unquote(json_extract(extra,_utf8mb4'$.isbn'))) VIRTUAL NULL: 这是定义虚拟列的部分。让我分解一下:
GENERATED ALWAYS AS: 这表示我们要创建一个根据其他列计算得出的虚拟列,它的值不会存储在数据库中,而是根据特定的计算公式动态生成。
(json_unquote(json_extract(extra,_utf8mb4'$.isbn'))): 这是计算虚拟列值的表达式。在这里,我们使用了 JSON 函数 json_extract 来从名为 extra 的 JSON 列中提取 .isbn 键对应的值,并使用 json_unquote 函数来解析 JSON 字符串。换句话说,我们从 extra 列中提取出的 JSON 数据中找到 isbn 键,并将其作为虚拟列的值。
VIRTUAL NULL: 这表示虚拟列的存储类型是虚拟的,不会实际存储任何数据。因为虚拟列是根据其他列的值动态计算生成的,所以不需要为其分配存储空间。
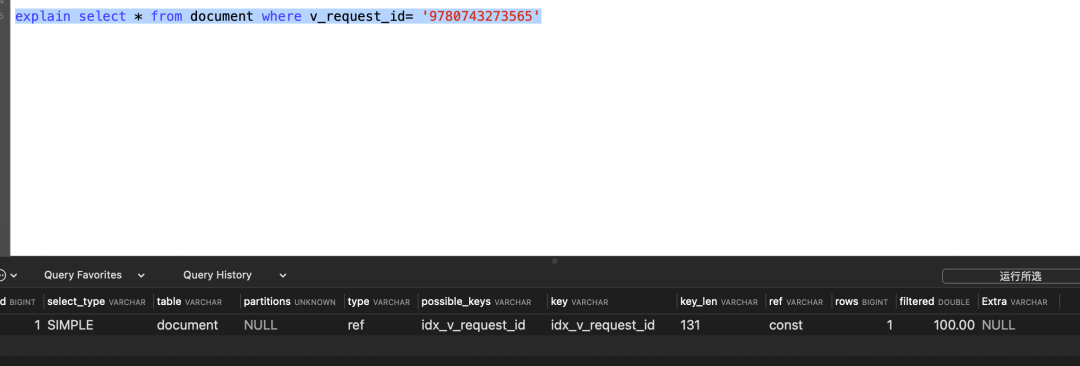
同理我们可以添加更多的虚拟列,并设置索引,来提升查询效率。
---THE END---


