




InfluxDB CTO Paul 在 2020/12/10 号在其官方博客发表一篇文章:Announcing InfluxDB IOx – The Future Core of InfluxDB Built with Rust and Arrow,介绍了一个新项目 InfluxDB IOx,InfluxDB 的下一代时序引擎。在时序数据库领域,InfluxDB 是当之无愧的佼佼者,常年在 DB-Engine TimeSeries 分类下名列第一。因此,InfluxDB 的一举一动,也备受关注。
InfluxDB 素来就有重写引擎的“传统”,在介绍 IOx 项目之前,先来回顾下其发展历程。
重写历程
在 Inside the InfluxDB storage engine 讲稿中有详细介绍 InfluxDB 要解决的问题以及迭代历史,不了解时序的读者可以先参考,这里只总结其迭代过程:
使用基于 LSM 的 LevelDB 来开发存储引擎,但是有下面几个问题
删除代价高;
需要打开过多的文件句柄;
接着换成了基于 mmap COW B+Tree 的 BoltDB,问题有如下几个:
写吞吐不高;
不支持压缩;
不再基于开源项目,从头自研 TSM 引擎,这也是现在使用的引擎。主要特点:
与 LSM 类似,主要有三个组件:WAL、memory cache(类似 memtables)、Index files(类似 SSTables);
为了加速查询,除了专门存储压缩数据的模块外,还有个单独的索引模块 TSI,其核心数据结构是一个倒排索引;
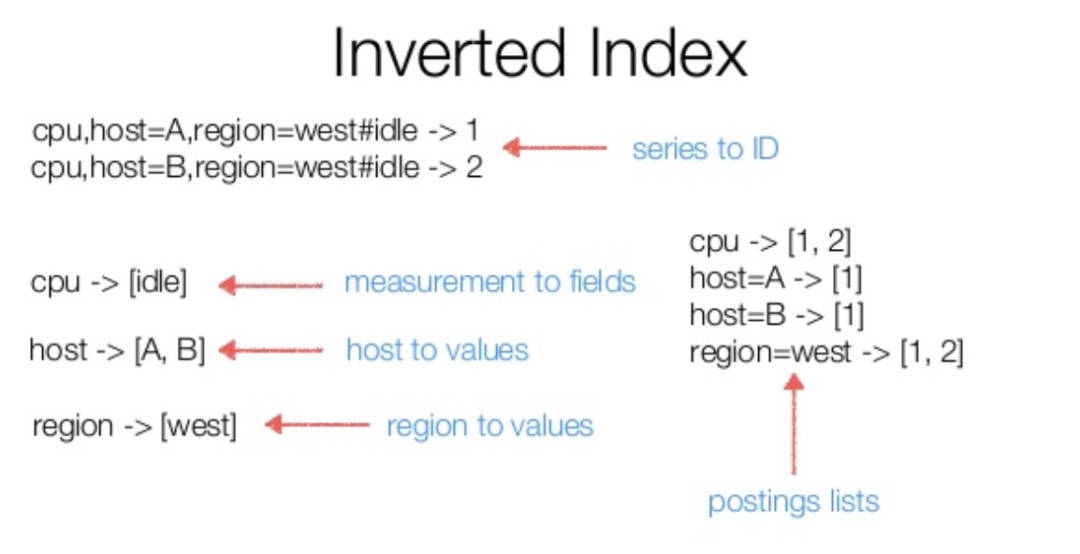
InfluxDB 迭代这么多次,个人觉得主要是两方面原因:
随着时间推移,时序场景的使用越来越复杂;
数据量越来越多,现有架构不足以支持;
由此,InfluxDB 开始着手新一代引擎的开发,也就是今天的主角:InfluxDB IOx。
InfluxDB IOx
IOx 发音为 eye-ox,iron oxide(氧化铁)的简写,与锈(Rust)相呼应。
开源模式
比较有意思的是,该文章一开始花了很大篇幅来讲述 InfluxDB 公司应该如何基于开源产品来盈利。
InfluxDB 现在的策略是开源单机版,闭源分布式版本。Paul 认为这种模式不利于其长远发展,主要原因有:
闭源分布式版本意味着放弃了这个市场,也就是说会有更多竞品出来争夺这个市场;
基础性软件如果功能受限,就会导致一部分用户放弃使用它;
因此 InfluxDB 想要真正成为被广大开发者接受的基础软件,必须开源更多组件,而不是闭门造车。只有这样才能吸引更多用户;同时,使用的开源协议必须对商业公司友好,否则商业公司不会采纳,云托管厂商不会托管它,而是会开发他们自己的版本,这样就导致了社区的分裂,因此 IOx 采用 MIT & Apache 2 双协议开源方式。
全部组件都开源,公司如何盈利呢?文章中提到:系统的设计不仅仅是整体架构是否合理,也需要考虑如何进行商业化。那么 IOx 是如何设计的呢?
联邦式(federated)的 share-nothing 架构
用户对所有服务有绝对的控制权,这也就意味着用户需要一些额外的工具来辅助其管理集群。简单来说,这些工具可以是 shell 脚本与 cron 定时任务,在更复杂的场景下,就需要专业工具的支持了。而这就是 InfluxDB 的赢利点。
感觉这一点可以用 Hadoop 与 Cloudera 类比,接触过大数据的读者应该会比较清楚,Hadoop 生态内的系统安装、运维是个很繁琐的事情。而使用 Cloudera,安装就是鼠标点几下的事,并且安装后有丰富的监控图表、运维工具,非常方便。
就在写这篇文章的同时,HN 上又出现与这个的话题相关的热贴 AWS announces forks of Elasticsearch and Kibana,只能说开源路漫漫其修远兮,InfluxDB 还需上下而求索。
Why IOx
上面讲述了 InfluxDB 今后的商业运作模式,那么这次为什么又要从头开始重写整个系统呢?毕竟 InfluxDB 公司已经成立七年,已经有了不少商业用户。在文章中提到现有设计主要有以下几个致命性问题:
无法解决时间线膨胀的问题;
由于索引与数据分开存储,导致高效的数据导入导出功能难以实现;
在云原生环境下,对内存管理要求比较严格,这意味 mmap 不再适用,而且 InfluxDB 需要支持无本地盘的运行模式;
上述这三个问题都是现有设计的核心之处,因此要想支持现阶段需求,重写是个比较好的选择。决定了重写,下一步就是技术栈的选择,InfluxDB 选择了 Rust + Apache Arrow 来构建下一代产品。
Why Rust
Rust 是新时代的系统语言,无 GC,可以做到对内存的严格控制。其次,Rust 独特的所有权机制不仅可以避免内存使用的诸多问题,而且还可以避免很多并发问题;此外,Rust 有完善的依赖管理系统,原生支持 async/await,很多公司(比如:微软/AWS) 都已经在生产环境使用。
此外值得关注的是,Arrow 子项目 DataFusion 模块,它是个用 Rust 实现的通用查询引擎,支持 SQL 与 DataFrame 两种接口。
我大概看了下 DataFusion 的实现,质量非常高,核心开发者 Andy Grove 在查询引擎方面具有十多年的功底,整个项目的设计也非常漂亮,从 LogicalPlan 到 PhysicalPlan 也支持不少优化,在它基础之上来构建自己的引擎再合适不过。后面我们也会尝试下,看看是否有机会在 CeresDB 中引入 DataFusion,对 OLAP 的支持也是 CeresDB 后面的发力点。
Why Apache Arrow
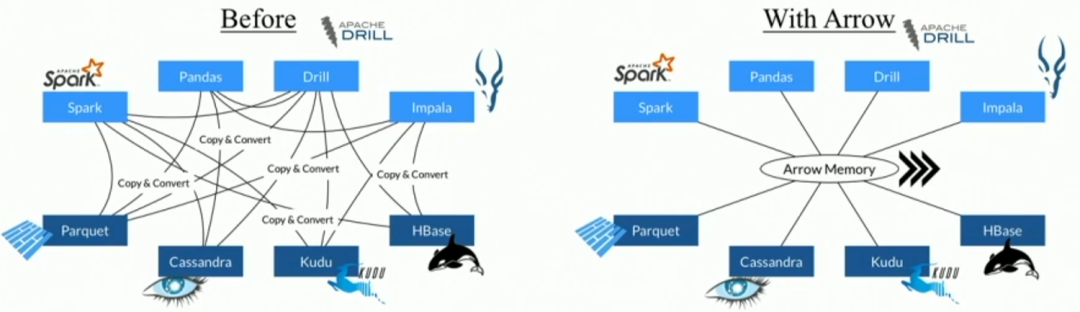
Apache Arrow 是一个通用性的基于内存的列式数据格式标准,它诞生的目的就是解决不同系统间如何高效交换数据。在大数据生态内,Parquet 是最为流行的文件存储格式,那为什么还需要 Arrow 呢?主要原因就在于 Parquet 主要是磁盘设计,磁盘的 IO 一般是整个系统的瓶颈,因此 Parquet 采用压缩来减小体积,在读取时,通过消耗一些 CPU 来补偿压缩带来优势;而对于内存而言,吞吐量不再是瓶颈,反而 CPU 资源更加珍贵。
根据 Daniel Abadi 的实验,对于内存数据结构而言,行存/列存的区别不是很大,这是由于 CPU 的处理速度(12GB/s)小于内存到 CPU 的传输速度(30GB/s)。因此不论是行存还是列存,从内存中输送 0.25GB 还是 1.5GB 数据到 CPU 中,都不会对结果有大的影响。
Arrow 由此应运而生,有如下特点:
专门为内存设计的(无压缩之类耗 CPU 的操作);
与语言无关的,有多种语言的实现;
对现代硬件友好,可以充分利用硬件的特性,比如 SIMD;
同时,比较特别的是这个项目的启动形式与其他项目也不相同,是由 5 个 Apache Members、6 个 PMC Chairs 和一些其它项目的 PMC 及 committer 构成,他们直接找到 ASF 董事会,征得同意后直接以顶级 Apache 项目身份启动。
IOx 之所以选择 Arrow,是因为 Paul 认为专为时序场景优化的列存数据库是 InfluxDB 的未来,下面就来分析其原因。
Why Columnar database
列存数据库的主要场景是 OLAP,而时序数据库算是 OLAP 的一个特殊场景。
OLAP won’t just be about large scale analytical queries, but also about near real-time queries answered in milliseconds. 出处见文末
对 InfluxDB 而言,它把指标作为一个表,指标的 tags + fields + timestamp 作为列,持久化时采用 Parquet 格式,一个表对应一个 Parquet 文件,根据 InfluxDB 测试,这种数据组织方式的压缩效果与现在 TSM 的类似。
此外,所有的数据都会分区,规则由用户自定义(一般为时间)。每个分区内,会记录一份概要(summary)文件,主要包含该分区内有哪些表,表有哪些列,以及每列的统计值(比如,max/min/count),查询时根据这个概要文件来缩小数据范围(即剪枝)。下面是 IOx 中数据的分布:
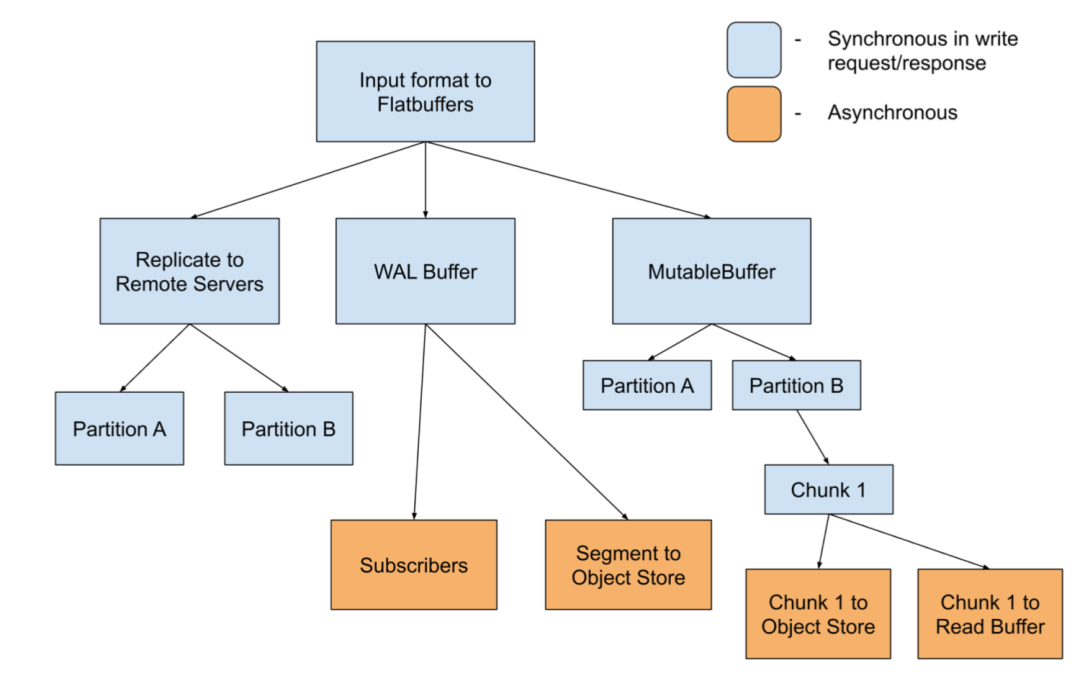
这里来分析一下上述设计是如何解决 Why IOx 中提到的三个问题:
对于时间线膨胀问题,IOx 不再单独维护倒排索引,取而代之的是每个分区的概要文件,相当于对之前的倒排索引也做了分片。在分区选择合理的情况下,概要文件的大小是比较可控的;
分区的概要文件仅仅是加速查询的辅助手段,读取数据时可以完全跳过概要文件,这样就为高效的数据导入导出提供了基础。如果仅仅把 TSM 中索引做分区处理,虽然也能解决时间线膨胀的问题,但 TSM 中的数据是编码后的,不读取索引文件就没法解析数据,这间接限制了高效的数据导入导出;
查询时,可以根据 LRU 之类的算法加载概要文件,更利于内存控制;
市面上的列存数据库多如牛毛,InfluxDB 为什么重新造一个轮子呢?Paul 认为主要有以下两个原因:
在查询层,需要支持字典压缩;基于窗口的聚合函数是一等成员,且需要特殊优化;
在持久化层,希望做到存储计算分离;
存储与计算的分离是近几年流行的方式,这一方面归功于像 S3 对象存储逐渐流行,另一方面是网络带宽有了质的提高,万兆网卡(10Gb/s 即 1.25GB/s)也是云厂商的标配,这并不比本地 SSD 差多少,再加上本地缓存、剪枝技术,真正需要读取的数据并不是很多。Snowflakes 是在这个方向上先驱者,早在 2016 发表的论文 The Snowflake Elastic Data Warehouse 就阐述了相关思想。推荐读者阅读。
对 IOx 而言,Arrow + DataFusion 为实现一个高性能列存数据库提供了坚定的基础,其开放的特性也符合 InfluxDB 迎合开源的设计初衷。Paul 认为开发者使用的工具处于不断的变化中,以 S3 为代表的对象存储已经取代 Hadoop 生态系统;容器化和 K8S 彻底改变了系统的部署与编排方式;下一个在大数据方向上的变革很有可能就是 Arrow 以及其关联项目,它们会是未来构建分析场景的基石。
此外,采用列存数据库不仅可以吸取这个领域上已经比较成熟的技术,扩大使用场景。
总结
在这个 Hacker News 的讨论贴上看,与 IOx 类似的项目其实不少,比如 Durid, Dremio, ClickHouse,每个项目出来时会宣传自己多牛叉,记得之前在 TerarkDB 完整开源及我的一些思考中看到过一个梗:
Oracle 平均每个月被干趴下一次
想想这种“震惊体”也是无奈之举,否则怎么在如今信息爆炸的时代去推广自己的产品呢?不过我觉得 IOx 还是具有创新性的,相比其他类似项目来说,IOx 是个开放式的系统,对于 InfluxDB 不擅长的领域,用户可以用合适的工具来处理存储在 S3 上的 Parquet 文件,比如数据分析师可以继续用 Pandas,大数据工程师可以继续用 Spark。这种开放性才是真正的利器。
IOx 项目现在还处于起步期,感兴趣的读者可以相对容易地参与进去。最后,用原文的一段话来总结此文:
Open source is about creating a cambrian explosion in software that creates value that far outstrips what a single vendor manages to monetize. Open source is not a zero sum game. A larger community and ecosystem brings more opportunity to all vendors.
欢迎来到「蚂蚁智能运维」的世界。本公众号由蚂蚁集团技术风险中台团队出品,面向关注智能运维、技术风险等技术的同学,将不定期与大家分享云原生时代下蚂蚁集团在智能运维的架构设计与创新方面的思考与实践。
蚂蚁技术风险中台团队,负责蚂蚁集团的技术风险底座平台建设,包括智能异常检测、资金核对、性能容量、全链路压测以及风险数据基础设施等平台和业务能力建设,解决世界级的分布式处理难题,识别和解决潜在的技术风险,参与蚂蚁双十一等大型活动,通过平台能力保障整体蚂蚁系统在极限请求量下的高可用和资金安全。
关于「智能运维」有任何想要交流、讨论的话题,欢迎留言告诉我们。
PS:技术风险中台正在招聘技术专家,欢迎加入我们,有兴趣联系 techrisk-platform-hire@list.alibaba-inc.com
参考
Announcing InfluxDB IOx – The Future Core of InfluxDB Built with Rust and Arrow:https://www.influxdata.com/blog/announcing-influxdb-iox/
DB-Engine TimeSeries:https://db-engines.com/en/ranking/time+series+dbms
Inside the InfluxDB storage engine:https://www.slideshare.net/influxdata/inside-the-influx-db-storage-engine
AWS announces forks of Elasticsearch and Kibana:https://news.ycombinator.com/item?id=25865094
并发问题:https://blog.rust-lang.org/2015/04/10/Fearless-Concurrency.html
DataFusion:https://arrow.apache.org/blog/2019/02/04/datafusion-donation/
Daniel Abadi 的实验:http://dbmsmusings.blogspot.com/2017/10/apache-arrow-vs-parquet-and-orc-do-we.html
https://www.influxdata.com/blog/apache-arrow-parquet-flight-and-their-ecosystem-are-a-game-changer-for-olap/
剪枝:https://en.wikipedia.org/wiki/Decision_tree_pruning
http://pages.cs.wisc.edu/~remzi/Classes/739/Spring2004/Papers/p215-dageville-snowflake.pdf
TerarkDB 完整开源及我的一些思考:https://zhuanlan.zhihu.com/p/338893564
Apache Arrow:一种适合异构大数据系统的内存列存数据格式标准:https://tech.ipalfish.com/blog/2020/12/08/apache_arrow_summary/
浅谈OLAP系统核心技术点:https://zhuanlan.zhihu.com/p/163236128
分布式系统 in 2010s :存储之数据库篇:https://pingcap.com/blog-cn/distributed-system-in-2010s-1/
从大数据到数据库:https://zhuanlan.zhihu.com/p/97085692
