




Whoami:5年+金融、政府、医疗领域工作经验的DBACertificate:OCP、PCPSkill:Oracle、Mysql、PostgreSQLPlatform:CSDN、墨天伦、公众号(呆呆的私房菜)复制
阅读本文可以了解PostgreSQL数据库索引相关内容,包含索引概述、索引类型及其HOT机制。
索引是对数据库表中一列或多列的值,通过不同的规则进行排序的一种存储结构。使用索引可以快速访问数据库表中的特定信息。
索引有如下几个特点:
1. 快速检索:索引可以显著提高数据的检索速度,它允许数据库引擎快速定位到数据存储位置,而不需要扫描整个表;
2. 排序:索引通常按照一定顺序存储数据,这使得对数据进行排序查询变得非常快速;
3. 可更新性:索引可以根据数据库中数据的变化而更新,以保持其有效性;
4. 维护成本:索引会增加数据库操作的维护成本,尤其是在数据插入、更新和删除时;
5. 性能影响:索引可以提高查询性能,但是过多的索引或不当的索引设计可能会对数据库性能产生负面影响。
PostgreSQL提供了丰富的索引类型,具体如下:
B-Tree索引:
1.存储数据的键值和指向表中数据行的指针。
2. 适用于全键值搜索、键值范围查询以及排序操作;
3. 可以高效处理多列索引,并且可以用于数据的唯一性约束;
testdb=> CREATE TABLE employees (testdb(> id SERIAL PRIMARY KEY,testdb(> first_name VARCHAR(50),testdb(> last_name VARCHAR(50),testdb(> birth_date DATE,testdb(> hire_date DATE,testdb(> department_id INTtestdb(> );CREATE TABLEtestdb=> CREATE INDEX idx_department ON employees USING btree (department_id);CREATE INDEXtestdb=> INSERT INTO employees (first_name, last_name, birth_date, hire_date, department_id) VALUEStestdb-> ('John', 'Doe', '1980-01-01', '2005-06-15', 101),testdb-> ('Jane', 'Smith', '1985-02-02', '2006-07-16', 102),testdb-> ('Alice', 'Johnson', '1990-03-03', '2010-08-17', 101),testdb-> ('Bob', 'Brown', '1975-04-04', '2007-09-18', 103),testdb-> ('Charlie', 'Davis', '1988-05-05', '2012-10-19', 102);INSERT 0 5testdb=> analyze employees;ANALYZEtestdb=> explain (analyze, buffers) SELECT * FROM employees WHERE department_id = 101;QUERY PLAN----------------------------------------------------------------------------------------------------Seq Scan on employees (cost=0.00..1.06 rows=2 width=27) (actual time=0.006..0.007 rows=2 loops=1)Filter: (department_id = 101)Rows Removed by Filter: 3Buffers: shared hit=1Planning:Buffers: shared hit=36Planning Time: 0.116 msExecution Time: 0.017 ms(8 行记录)复制
Hash索引:
1. 使用哈希表来存储索引键和指向数据行的指针;
2. 适用于等值查询,即查找具有特定键值的行;
3. hash索引不支持范围查询,因为hash表不保留键的顺序;
4. 不适用于处理大量重复键值场景。
testdb=> CREATE TABLE departments (testdb(> department_id SERIAL PRIMARY KEY,testdb(> department_name VARCHAR(255) NOT NULLtestdb(> );testdb=> DO $$testdb$> DECLAREtestdb$> i INT;testdb$> j INT;testdb$> k INT; -- 用于生成唯一部门IDtestdb$> dept_names CONSTANT VARCHAR(255)[] := ARRAY[testdb$> 'HR', 'Finance', 'IT', 'Marketing', 'Sales',testdb$> 'Research and Development', 'Customer Support',testdb$> 'Operations', 'Legal', 'Management'testdb$> ];testdb$> num_depts CONSTANT INT := array_length(dept_names, 1); -- 部门名称的数量testdb$> BEGINtestdb$> -- 外层循环控制10000组,每组10条记录testdb$> FOR i IN 1..10000 LOOPtestdb$> -- 重置k值,每组循环使用相同的起始IDtestdb$> k := (i - 1) * 10 + 1; -- 计算每组循环的起始IDtestdb$> FOR j IN 1..10 LOOPtestdb$> -- 计算部门名称索引,确保索引在数组范围内testdb$> INSERT INTO departments (department_id, department_name)testdb$> VALUES (k, dept_names[(j - 1) % num_depts + 1]);testdb$> -- 准备下一次迭代的部门IDtestdb$> k := k + 1;testdb$> END LOOP;testdb$> END LOOP;testdb$> END $$;DOtestdb=> CREATE INDEX idx_department_name_hash ON departments USING HASH (department_name);CREATE INDEXtestdb=>testdb=> analyze departments ;ANALYZEtestdb=>testdb=> explain SELECT department_id, department_name FROM departments WHERE department_name = 'IT';QUERY PLAN-----------------------------------------------------------------------------------------Bitmap Heap Scan on departments (cost=9.55..22.05 rows=200 width=13)Recheck Cond: ((department_name)::text = 'IT'::text)-> Bitmap Index Scan on idx_department_name_hash (cost=0.00..9.50 rows=200 width=0)Index Cond: ((department_name)::text = 'IT'::text)(4 行记录)# 在PostgreSQL数据库中,当哈希索引用于查询时,查询优化器可能会选择将索引扫描的结果转换为位图,然后使用位图来访问表中对应的行。# 这是 PostgreSQL 内部优化机制的一部分,旨在提高查询效率。复制
GIST索引:
1. 多维索引,类似于B-Tree的结构,但每个节点都可能包含多个键值;
2. 适用于空间数据类型,如点、线和多边形;
3. 支持复杂的空间查询,如相交、包含和覆盖等;
4. 可以用于自定义数据类型和操作符,使其非常灵活。
testdb=> CREATE TABLE locations (testdb(> location_id SERIAL PRIMARY KEY,testdb(> point_value POINT -- 存储点类型数据testdb(> );CREATE TABLEtestdb=> INSERT INTO locations (point_value)testdb-> SELECT POINT(x, x + 10)testdb-> FROM generate_series(1, 100000) AS s(x);INSERT 0 100000testdb=> CREATE INDEX ON locations USING GIST (point_value);CREATE INDEXtestdb=> EXPLAIN SELECT location_id, point_valuetestdb-> FROM locationstestdb-> WHERE point_value <@ BOX(POINT(0, 0), POINT(100010, 10010));QUERY PLAN-------------------------------------------------------------------------------------------Bitmap Heap Scan on locations (cost=5.06..271.70 rows=100 width=20)Recheck Cond: (point_value <@ '(100010,10010),(0,0)'::box)-> Bitmap Index Scan on locations_point_value_idx1 (cost=0.00..5.03 rows=100 width=0)Index Cond: (point_value <@ '(100010,10010),(0,0)'::box)(4 行记录)复制
SP-GisST索引:
扩展索引结构,与Gist类似,用于支持多种不同的非平衡数据结构;如四叉树、k-d树、基数树。
适用于可以递归地将空间分割为不相交区域的结构,特点是构建一个非平衡的树结构,其中节点分支较少但深度较大,因此适合在内存中工作。但是由于通常存储于磁盘上,所以该索引需要将节点映射到磁盘页面,以减少I/O操作;
支持排除约束,支持index-only扫描;
不支持排序和唯一索引,不支持在多个列上创建;
使用一致性函数来确定搜索过程中访问哪些子节点。
GIN索引:
1. 倒排索引,适用于全文搜索和数组类型的索引;
2. 允许对数组中的每个元素进行索引,并支持对数组元素的查询;
3. 适用于包含大量元素的数组或需要全文搜索的文本字段;
4. 它通过为每个元素创建一个单独的索引项来工作,从而提高搜索效率。
testdb=> CREATE TABLE array_data (testdb(> id SERIAL PRIMARY KEY,testdb(> num_array INTEGER[] NOT NULLtestdb(> );CREATE TABLEtestdb=> INSERT INTO array_data (num_array)testdb-> SELECT ARRAY[generate_series(1, 100), generate_series(1, 100) + 50]testdb-> FROM generate_series(1, 100000);INSERT 0 10000000testdb=> CREATE INDEX gin_idx ON array_data USING GIN (num_array);CREATE INDEXtestdb-> WHERE num_array @> ARRAY[10];QUERY PLAN------------------------------------------------------------------------------Bitmap Heap Scan on array_data (cost=687.29..89608.44 rows=101000 width=33)Recheck Cond: (num_array @> '{10}'::integer[])-> Bitmap Index Scan on gin_idx (cost=0.00..662.04 rows=101000 width=0)Index Cond: (num_array @> '{10}'::integer[])(4 行记录)复制
多列索引:
1. 索引定义在数据表的多个字段上
2. 只有B-Tree、GIST、GIN和BRIN支持多列索引,最多可以声明32个字段;
3. 多列索引适用于SQL比较的固定场景,一般不建议创建超过3个字段以上的索引。
| 多列索引类型 | 使用说明 |
| B-Tree | 索引字段的子集均可用于查询条件,但只有多列索引中的第一个索引字段(最左边)被包含时,才可以获得最高效率 |
| GiST | 只有当第一个索引字段被包含在查询条件中,才能决定该查询会扫描多少索引数据,而其他索引字段上的条件只是会限制索引返回的条目,如果第一个索引字段上的大多数数据都有重复的键值,那么效率就会比较低 |
| GIN | 不会受到查询条件中使用了哪些索引字段子集的影响,无论那种组合,效率都是相同的 |
testdb=> CREATE TABLE products (testdb(> product_id SERIAL PRIMARY KEY,testdb(> product_name VARCHAR(255) NOT NULL,testdb(> category VARCHAR(100),testdb(> price NUMERIC NOT NULLtestdb(> );CREATE TABLEtestdb=> INSERT INTO products (product_name, category, price)testdb-> SELECT 'Sample Product', 'Sample Category', ROUND((RANDOM()::numeric * 10000), 2)testdb-> FROM generate_series(1, 1000000);INSERT 0 1000000testdb=> EXPLAIN SELECT product_id, product_name, category, priceFROM productsWHERE category = 'Sample Category' AND price > 8000;QUERY PLAN--------------------------------------------------------------------------------------------------Bitmap Heap Scan on products (cost=7302.49..19700.28 rows=203519 width=41)Recheck Cond: (((category)::text = 'Sample Category'::text) AND (price > '8000'::numeric))-> Bitmap Index Scan on multi_col_idx (cost=0.00..7251.62 rows=203519 width=0)Index Cond: (((category)::text = 'Sample Category'::text) AND (price > '8000'::numeric))(4 行记录)复制
唯一索引:
1. 只有B-Tree索引可以被声明为唯一索引;
2. 如果声明为唯一索引,就不允许出现多个索引值相同的行(NULL值相互间不相等)
表达式索引
1. 主要用于在查询条件中存在基于某个字段的函数或表达式的结果与其他值进行比较时;
例:create index idx_t1_lower_col1 on t1 (lower(col1));select * from t1 where lower(col1) = 'test1';# 如果仅在col1字段上创建索引,那么查询在执行时会直接进行全表扫描复制
2. 如果是唯一索引的情况下,那么它会禁止创建col(1)数值只是大小写有区别的数据行,以及col1数值完全相同的数据行;
3. 表达式上的索引可以用于强制那些无法定义为简单唯一约束的约束;
4. 表达式索引对于检索速度远比插入和更新速度重要的情况下非常有用。
函数索引
1. 优化器需要知道给operator的参数值才能通过pg_statistic中统计到的表柱状图来计算走索引还是走全表扫描或者其他计划的开销最小,如果传入的是个变量,则通常不能使用索引扫描。
2. 作为过滤条件的函数,immutable和stable的函数在优化器计算cost前会把函数值算出来。而volatile的函数,是在执行sql的时候运算的,所以无法在优化器计算执行计划的阶段得到函数值,也就无法和pg_statistic中的信息比对到底是走索引还是全表扫描或者其他计划。
tips:函数的稳定性级别有3种:1. immutable:这类函数不会修改数据库,并且对于相同的输入参数,无论何时调用都会返回相同的结果;2. stable:这类函数不会修改数据库,但它们保证的是在单个事务或查询执行过程中,对于相同的输入参数会产生一致的输出;3. volatile:这种函数行为不稳定,它们可能会修改数据库,并且在相同的输入参数下,每次调用都可能返回不同的结果。如random()和timeofday()这类函数就属于volatile。testdb=> CREATE TABLE users (testdb(> user_id SERIAL PRIMARY KEY,testdb(> email VARCHAR(255) NOT NULLtestdb(> );CREATE TABLEtestdb=> INSERT INTO users (email)testdb-> SELECT 'user' || generate_series(1, 100000) || '@example.com';INSERT 0 100000testdb=> CREATE INDEX email_domain_idx ON users (RIGHT(email, CHAR_LENGTH(email) - strpos(email, '@')));CREATE INDEXtestdb=> SELECT user_id, emailtestdb-> FROM userstestdb-> WHERE RIGHT(email, CHAR_LENGTH(email) - strpos(email, '@')) = 'example.com';testdb=> EXPLAIN SELECT user_id, emailtestdb-> FROM userstestdb-> WHERE RIGHT(email, CHAR_LENGTH(email) - strpos(email, '@')) = 'example.com';QUERY PLAN-------------------------------------------------------------------------------------------------------------------------------------Bitmap Heap Scan on users (cost=8.17..715.06 rows=500 width=520)Recheck Cond: ("right"((email)::text, (char_length((email)::text) - strpos((email)::text, '@'::text))) = 'example.com'::text)-> Bitmap Index Scan on email_domain_idx (cost=0.00..8.04 rows=500 width=0)Index Cond: ("right"((email)::text, (char_length((email)::text) - strpos((email)::text, '@'::text))) = 'example.com'::text)(4 行记录)复制
1. Access Method:访问方法定义了如何在PostgreSQL数据库中创建和使用索引。PostgreSQL支持多种类型的访问方法,每种访问方法都有特定的使用场景和优化目标。
2. Operator Class:操作符类定义了特定数据类型如何与索引一起使用。它指定了一组操作符和函数,这些操作符和函数是索引访问方法在执行索引操作时所需要的。包括用于比较和排序数据的操作符,以及可能需要额外的支持函数。例如,B-Tree索引访问方法需要知道如何对数据进行排序,因此它需要一个操作符类来定义用于排序符和相应的支持函数。
3. 数据库planner配置:
如果下面参数都是off,都不会走索引扫描enable_bitmapscan = onenable_hashjoin = onenable_indexscan = on复制
4. 索引成本参数配置:
# 随机页面扫描random_page_cost = 4.0# 索引扫描带来的索引的tuple开销cpu_index_tuple_cost = 0.005# 数值越大越倾向于走索引,因为数值越大数据可能都在os cache里,因此随机页面的成本就降低了effective_cache_size = 128MB复制
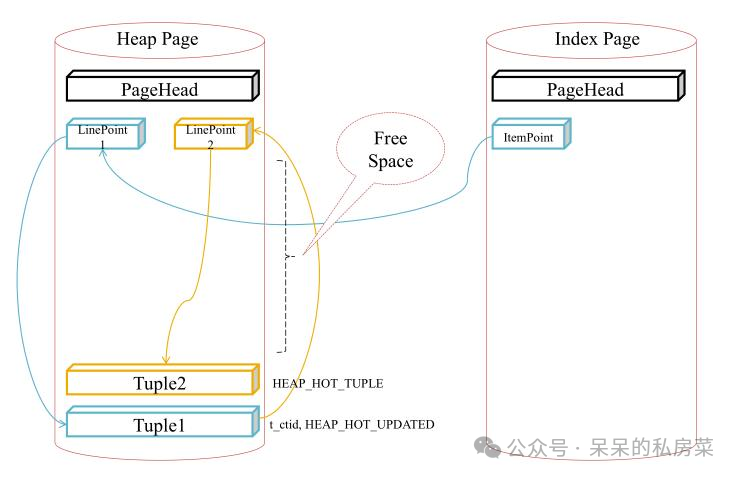
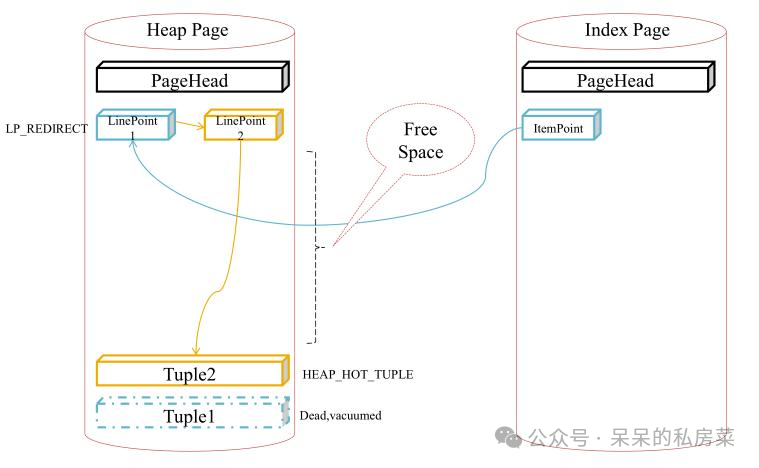
1. HOT在PostgreSQL 8.3版本中实现:当更新的行与旧行存储在同一个表页中时,HOT能够有效使用索引页和表页;
2. HOT降低了vacuum处理的必要性;
3. 当用HOT更新行时,如果更新的行与旧行将存储在同一个表页中,则PostgreSQL不会插入相应的索引元组,从而减少更新写入所消耗的资源;
PostgreSQL会在修剪过程中在适当的时候清理dead tuple,这种处理称为碎片整理(defragmentation)碎片整理的成本低于正常的vacuum处理的成本,因为碎片整理不涉及删除索引元组复制
4. HOT不可用的情况
1. 当更新的元组存储在另一个不存储旧元组的页中时,指向元组的索引元组也被插入到索引页中;
2. 当索引元组的key值被更新时,新的索引元组被插入到索引页中。
本文内容就到这啦,阅读完本篇,相信你对PostgreSQL的索引相关的知识有了更深的理解了吧!我们下篇再见!

