




本文讨论 OB 的读写分离方案以及其潜在问题。
读写分离方案
“读写分离”方案在MySQL、ORACLE 数据库解决方案中经常用到,数据库通常会部署为1主2备,其中一个备库就用于只读查询。这个方案的难点在于业务什么时候将读请求路由到这个备。MySQL的读写分离开源方案有MyCat、 ProxySQL 等。
读写分离本意是将读负载很大性能不好的应用的只读请求跟主要业务的读写请求分离出去,对于只读请求应该给一个独立的访问数据库备库的连接方法。ProxySQL 试图提供一个统一的业务访问地址,然后又把读请求路由到备库。这个方案的最大问题就是有些业务是需要强一致性读(写后立读),事务提交后业务接着去读数据可能会读不到最新数据。ProxySQL 能做到的是如果这个写后读是在同一个事务里,读还是会路由到主库里。
本文倒不是要说 ProxySQL 的问题,而是借这个问题说明“读写分离”需求场景的问题。如果业务逻辑里读和写的逻辑密切相关,这种场景是不适合读写分离的。如果哪个解决方案只是单纯的将读路由到备库,那这个解决方案在这个读写混合的场景里一定有很大的问题。读写分离适合的是将报表类读密集型业务(可以简称为 AP 业务)从交易业务(简称为 TP 业务)请求里分离出去。这类业务也适合配置一个独立的只读数据源。这个独立的数据源就是读写分离方案的要点。
如果哪个业务需求既要读写分离的效果,又想只要一个统一的数据源,那他想要的太多了,多的有点过分。这对数据库或连接中间件要求太高。即使实现了,也是那种不完美的。就像 ProxySQL 那种。当然这里话也不敢说的很绝对,PolarDB PostgreSQL/MySQL 基于分布式共享存储也实现了读写分离方案并且提供的是一个统一的地址。我没有测试过,是否有问题关键看读到备库的数据是不是跟主库一致的。这里也不是为了讨论 PolarDB,只是借此说明评估读写分离方案时的考虑点。
所以业务想要读写分离,不一定是字面上的“读写分离”。很多产品只是实现了一种读写分离的效果,至于业务使用的风险,由业务自己承担。如果业务由此碰到数据问题最后分析下来质问为什么数据库会是这样的,那就没有什么道理了。
OB 的读写分离方案
接下来看 OB 里如何做读写分离。
OB 并没有读写分离这个功能,而只是当作一个解决方案去解释,是通过相关产品的参数调整实现。OB 文档也提示了,读写分离的时候读请求读到的数据不保证是最新的。一样的,使用风险业务自己承担。
OB 里备的角色相比传统数据库要复杂一点。首先 OB 标准的部署架构下数据通常是三副本的(简称3F),不标准的部署有两副本加一仲裁副本(简称 2F1A)。后者不是本文重点所以后面不再提了。三副本里一个 LEADER 副本(简称主副本)和两个 FOLLOWER 副本(简称备副本)。OB 的集群或租户还有备集群(V3 版本概念)或备租户(V4 版本概念),备租户的数据可以是单副本或者三副本,这些都是备副本。所以 OB 的读写分离方案中的读可以是读主租户的三副本中的备副本,也可以是读备租户中的数据副本(也是备副本)。除此之外,OB 在主租户的三副本之外还可以再加一个只读副本。所以那个读也可以路由到只读副本。其实用只读副本是最佳方案,不过涉及到成本,真正有这个副本的很少。本文讨论的 OB 读写分离的读备副本主要是说主租户中的备副本,读只读副本基本同理,读备租户的数据副本这个很少有(方法也有,只有业务压力非常大的时候才有必要)就不提了。
备副本数据有了,读写分离的关键依然是连接中间件,这个角色在 OB 产品里就由 ODP 最合适不过了。ODP 就是做连接、SQL 和事务路由的。路由参数非常多也是因为面临的场景挑战非常多。参数非常多,且不同版本默认行为可能还不一样,是 ODP 学习和使用最大的挑战。也间接提醒用户 ODP 版本的升级要特别注意路由方面新的行为参数的引入,以及老参数值的变化。尽量在测试环境就做好充分的测试。特别是对于那些使用了读写分离这种方案的业务,更要充分测试。
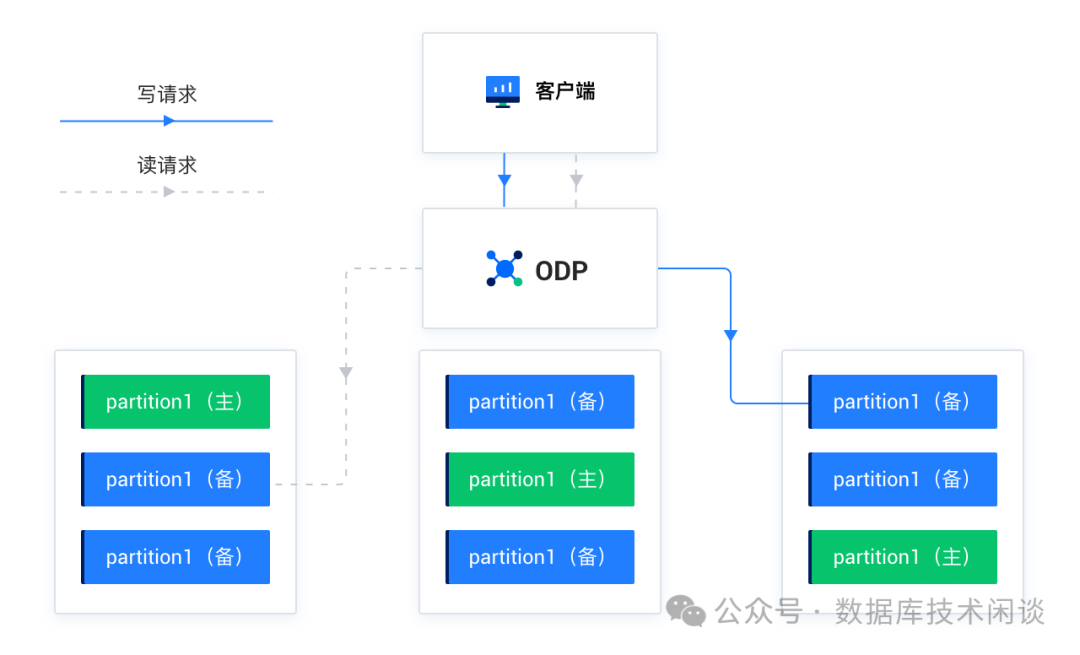
ODP 默认读都是强一致性读,指读取主副本。另外一种行为是弱一致性读,读取备副本。ODP 提供参数 obproxy_read_consistency
修改默认行为。当读取备副本的时候,ODP 还提供很多参数策略去指导究竟读哪个备副本好。比如说备副本优先还是只读取备副本(参数 proxy_route_policy
)、就近读同机房或同地域的备副本(LDC路由功能,参数 proxy_idc_name
)、读不在合并中的备副本(合并是 OB 特有的逻辑)、备副本延时最大容忍度参数等。从这么多参数就能敏感的看出通过 ODP 做读写分离这事肯定不简单。
OB 也支持在租户或会话层面(变量 ob_read_consistency
)、语句层面(HINT read_consistency(weak|strong)
)去设置默认的读行为。ODP 在路由的时候会考虑这些策略设置,进而将 SQL 请求转发到对应的 OBServer 上。
接下来就是读写分离实验部分。实验主要是直接观察 ODP 路由结果展现出来的特点,从而分析业务上可能的风险。
软件版本和环境设置
实验软件版本 OB V4.2.1.6, ODP 4.3.0 。普通的三节点集群,两个机房:hz(有zone1,zone2) 和 hz2(有zone3)。ODP 跟 OBServer 部署在一起。
SELECT z.ZONE, z.region, z.idc, z.status zone_st, s.svr_ip, s.status observer_st
FROM oceanbase.DBA_OB_ZONES z JOIN oceanbase.DBA_OB_SERVERS s ON (z.ZONE=s.ZONE )
ORDER BY z.ZONE ;复制
| ZONE | region | idc | zone_st | svr_ip | observer_st |
|---|---|---|---|---|---|
| zone1 | zj | hz | ACTIVE | 10.0.0.61 | ACTIVE |
| zone2 | zj | hz | ACTIVE | 10.0.0.62 | ACTIVE |
| zone3 | zj | hz2 | ACTIVE | 10.0.0.63 | ACTIVE |
ODP 跟 OBServer 部署在一起。为了对比测试,每个 ODP 的参数稍有不同。
| odp ip | obproxy_read_consistency | proxy_idc_name | enable_transaction_internal_routing |
|---|---|---|---|
| 10.0.0.62 | 0 (leader) | 空(默认) | True (分布式事务路由) |
| 10.0.0.61 | 1 (follower) | 空(默认) | True |
| 10.0.0.63 | 1 | hz2 (包含 zone3) | True |
proxy_idc_name
就是 ODP 就近路由的参数,设置后可以在该 ODP 管理界面下确认结果。
MySQL [(none)]> show proxyinfo idc;
+-----------------+--------------+----------------+--------------+--------------+--------------------------+--------------+
| global_idc_name | cluster_name | match_type | regions_name | same_idc | same_region | other_region |
+-----------------+--------------+----------------+--------------+--------------+--------------------------+--------------+
| hz2 | obdemo01 | MATCHED_BY_IDC | [[0]"zj"] | [[0]"zone3"] | [[0]"zone1", [1]"zone2"] | [] |
+-----------------+--------------+----------------+--------------+--------------+--------------------------+--------------+
1 row in set (0.01 sec)复制
测试数据准备
租户实例类型是 MySQL,PRIMARY_ZONE
设置为 zone1,zone2
。即主副本在前两个 zone 分散分布。方法:alter tenant obmysql primary_zone='zone1,zone2';
。
数据是 BenchmarkSQL TPC-C 生成的 16 仓数据,每个表分 4 个分区。表分组没有用(不影响测试结论)。
数据初始化后查看数据主副本的位置分布如下。
select database_name, table_id,table_name, table_type,partition_name, tablet_id,ls_id ,zone,svr_ip,role,tablegroup_name
from DBA_OB_TABLE_LOCATIONS
where database_name in ('tpccdb') and role in ('LEADER')
AND table_name IN ('bmsql_warehouse','bmsql_stock','bmsql_new_order','bmsql_item')
ORDER BY database_name, table_name, partition_name,ROLE ;复制
结果如下(过滤掉部分列)。
| 库名 | 表名 | 分区名 | zone | svr_ip |
|---|---|---|---|---|
| tpccdb | bmsql_item | NULL | zone2 | 10.0.0.62 |
| tpccdb | bmsql_new_order | p0 | zone2 | 10.0.0.62 |
| tpccdb | bmsql_new_order | p1 | zone2 | 10.0.0.62 |
| tpccdb | bmsql_new_order | p2 | zone1 | 10.0.0.61 |
| tpccdb | bmsql_new_order | p3 | zone1 | 10.0.0.61 |
| tpccdb | bmsql_stock | p0 | zone2 | 10.0.0.62 |
| tpccdb | bmsql_stock | p1 | zone2 | 10.0.0.62 |
| tpccdb | bmsql_stock | p2 | zone1 | 10.0.0.61 |
| tpccdb | bmsql_stock | p3 | zone1 | 10.0.0.61 |
| tpccdb | bmsql_warehouse | p0 | zone2 | 10.0.0.62 |
| tpccdb | bmsql_warehouse | p1 | zone2 | 10.0.0.62 |
| tpccdb | bmsql_warehouse | p2 | zone1 | 10.0.0.61 |
| tpccdb | bmsql_warehouse | p3 | zone1 | 10.0.0.61 |
其中表 bmsql_item
是复制表,三副本全同步(即备副本跟主副本数据严格一致)。语句:alter table bmsql_item duplicate_scope='cluster';
。
下面 SQL 可以查看每个仓库具体在哪个表分区里,进而知道主副本在哪个节点上。
SELECT 'p0' , no_w_id, count(*) FROM tpccdb.bmsql_new_order PARTITION(p0) WHERE no_w_id <=4 GROUP BY no_w_id
UNION
SELECT 'p1' , no_w_id, count(*) FROM tpccdb.bmsql_new_order PARTITION(p1) WHERE no_w_id <=4 GROUP BY no_w_id
union
SELECT 'p2' , no_w_id, count(*) FROM tpccdb.bmsql_new_order PARTITION(p2) WHERE no_w_id <=4 GROUP BY no_w_id
union
SELECT 'p3' , no_w_id, count(*) FROM tpccdb.bmsql_new_order PARTITION(p3) WHERE no_w_id <=4 GROUP BY no_w_id
;复制
| p0 | no_w_id | count(*) | server_ip |
|---|---|---|---|
| p0 | 4 | 9000 | 10.0.0.62 |
| p1 | 1 | 8999 | 10.0.0.62 |
| p2 | 2 | 9000 | 10.0.0.61 |
| p3 | 3 | 9000 | 10.0.0.61 |
测试 SQL 准备
下面是一个场景事务SQL。使用独立的用户 mq@obmysql#obdemo01
连接租户,方便后面 SQL 追踪。
set session autocommit=off;
SELECT count(*) FROM bmsql_new_order WHERE no_w_id = 2 AND no_d_id = 1 ORDER BY no_o_id ASC;
SELECT count(*) FROM bmsql_new_order WHERE no_w_id = 1 AND no_d_id = 1 ORDER BY no_o_id ASC;
SELECT count(*) FROM bmsql_item WHERE i_id = 29805;
DELETE FROM bmsql_new_order WHERE no_w_id = 1 AND no_d_id = 1 AND no_o_id = 2525;
SELECT count(*) FROM bmsql_item WHERE i_id = 29805;
SELECT count(*) FROM bmsql_new_order WHERE no_w_id = 2 AND no_d_id = 1 ORDER BY no_o_id ASC;
ROLLBACK;复制
这里用 set session autocommit=off
,后面事务开启的时候由第一个 DML 语句开启(租户参数 ob_proxy_readonly_transaction_routing_policy
是 false
)。如果用命令 BEGIN
开启事务,则后面查询也在事务中。这是二者的区别,对实验结果会有局部的影响。
末尾用 ROLLBACK
是为了事务可以反复跑。DELETE
语句如果修改行数为 0 ,其后面的查询会话事务ID(txid
)信息是空。这点比较奇怪,难道 OB 认为如果 DML 没有修改任何记录,则不算开启了事务。这个对观察结果会有些影响,所以我改用 ROLLBACK
。当然如果你把 SQL 改成 UPDATE
保证一直能更新记录,末尾换 COMMIT
也行。这个不影响观察结论。
要观察 ODP 的路由,就要查询 SQL 审计视图。
alter system flush sql audit global; -- 清空 SQL 审计视图
select usec_to_time(request_time) req_time, user_client_ip, client_ip, svr_ip, sid,tx_id,plan_type,query_sql,return_rows+affected_rows total_rows
from oceanbase.GV$OB_SQL_AUDIT
where 1=1 and request_type in (1,2,3)
and user_name in ('mq')
order by REQUEST_TIME DESC limit 1000;复制
字段简要说明:
svr_ip
是 SQL 被路由到的 OBServer 节点。client_ip
是 SQL 连接的 ODP IP。user_client_ip
是 obclient 或 mysql 客户端 IP。sid
是 OBServer 上的会话 ID 。tx_id
是 OB 租户里的事务 ID 。plan_type
是 SQL 类型,0:本地执行;1:远程执行;2:分布式执行。return_rows
是查询返回的记录数。affected_rows
是修改返回的记录数。
测试场景和结果
场景一:标准的 ODP 用法。
连接 ODP 10.0.0.62
。
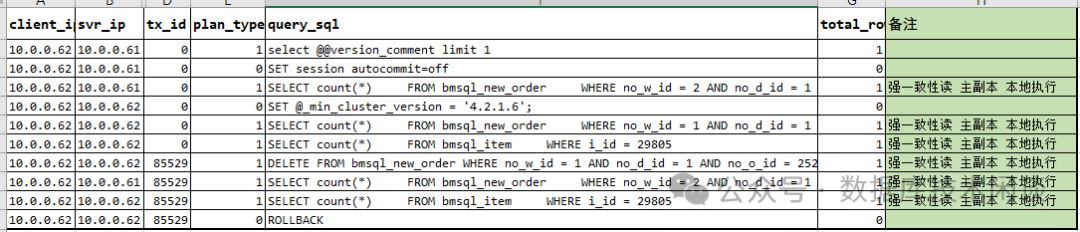
默认所有 SQL 都是强一致性读,都被 ODP 路由到主副本。这个现在都很好理解,实际上在 ODP 4.2.2 版本之前,观察到的行为并不是这样。此前的版本,当 DML 语句开启事务后,整个事务中所有读写查询都会被路由到同一个节点中。这是由于 ODP 4.2.2 版本新引入了参数 enable_transaction_internal_routing
(默认值为true
)。这个参数为 true
表示允许事务中的 SQL 独立路由。
这是一个很大的变化,将很大程度消除远程执行计划类的 SQL ,从而提升部分事务的性能。不过这个不能消除分布式执行计划(如分布式 JOIN)。所以有了这个参数后,OB 用户可以考虑将租户的 PRIMARY_ZONE
设置为多个 Zone,从而发挥多机的处理能力。
下面是关闭了 ODP 10.0.0.62
上这个分布式事务路由参数后的结果。

有差异的是最后一个查询语句,因为在事务中,所以被路由到备副本所在节点,而要强一致性读取主副本,那就是个远程执行计划。
场景二:ODP 读写分离用法
连接 ODP 10.0.0.61
。
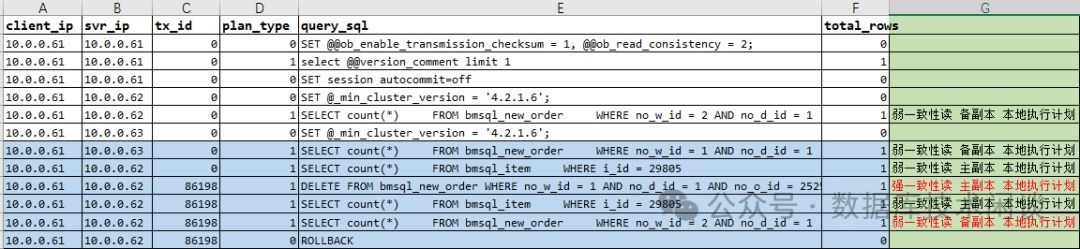
在这个结果里,有几点不一样:
表 bmsql_item
的查询是弱一致性读优先(因为 ODP 参数proxy_route_policy
=follower_first
),并不排除主副本,所以恰好读了主副本。事务的最后一个查询语句是弱一致性读,读取的是备副本。这个才是最大的风险点,是对业务影响最大的地方。
当使用 ODP 的读写分离后,ODP 单纯的就是看 SQL 是查询还是修改,对于查询语句就启用弱一致性读优先策略,完全不顾这个查询是否在事务中。这个场景的测试结果跟 OB V3.2 版本有很大的差异。这是业务需要特别留心的地方。如果是 ProxySQL 做读写分离的话,是不会将事务中的查询路由到备库的。ODP 当前版本(4.3.0)是设计如此,还是 BUG,目前还不确定。
场景三:ODP 读写分离加 LDC 路由
连接 ODP 10.0.0.63
。

这个跟前面不同的地方是弱一致性读选泽跟 ODP 同一个机房(hz2
)的 OBServer 的备副本。一样有问题的地方是事务后期的查询语句也是弱一致性读。
总结
OB 弱一致性读的数据就是可能有延时的,不保证是最新的。读写分离方案中的读的结果也是不保证最新的。话说出来很简单,都能理解。但是业务研发人员在使用的时候很可能会低估这个信息的风险。在业务隐含需要强一致性读的场景里错误的使用了读写分离的方案。如果这个业务是重要交易,那这个数据不准的结果可能就带来重大事故。



