




Vertica 分区功能可根据一列或多列中的值将一个大表划分为较小的部分。正如您将在本文中了解到的,分区可以简化数据生命周期管理,并提高其谓词包含在分区表达式中的查询的性能。
本文档回答了您可能对 Vertica 数据库中的分区有疑问的最重要的问题。这些问题分为以下几类:
- 分区基础知识
- 分区和存储裁剪
- 分区和 ROS 文件以及 ROS 容器
- 重新分区和重组
- 分区限制注意事项
1、分区基础知识
1.1 分区如何工作?
假设您需要为数据创建保留策略。例如,您可能只需要保留数据五年。您想删除所有超过五年的数据。
Vertica 分区功能可以轻松高效地管理这些数据。让我们看看它是如何工作的。
假设您有一个名为 trade 的表,其中包含以下数据:
- 交易日期 (tdate)
- 股票代码 (tsymbol)
- 交易时间 (ttime)
使用以下 CREATE TABLE 语句,指定 Vertica 根据交易发生的年份对数据进行分区:
CREATE TABLE trade (
tdate DATE NOT NULL,
tsymbol VARCHAR(8) NOT NULL,
ttime TIME)
PARTITION BY EXTRACT(year FROM tdate);
当您将数据加载到交易表中时,Vertica 会根据分区表达式(在此示例中为日历年)对数据进行分区:
PARTITION BY EXTRACT(year FROM tdate)
通过此分区,您可以使用分区管理功能轻松管理可能需要移动或删除的数据子集。
对于交易表示例,假设您首先加载 2008 年的数据。Vertica 将数据存储在 ROS(读取优化存储)容器中。
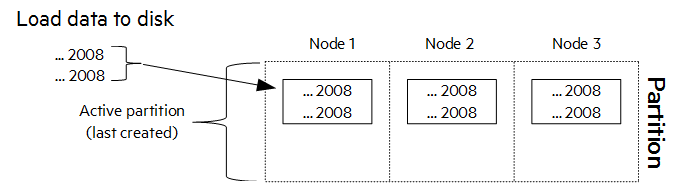
Vertica 创建一个分区,用于存储 2008 年数据的所有 ROS 容器。最近创建的分区称为活动分区。下图显示了加载到分区中的两行 2008 年数据。
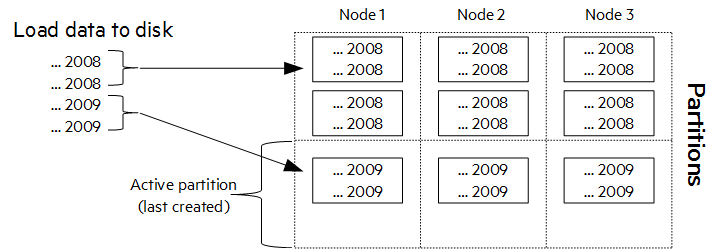
当您第一次加载 2009 年数据时,Vertica 将创建一个新分区,该分区将成为活动分区。在下图中,Vertica 将两行 2009 年数据加载到新分区中。非活动分区包含可能不需要经常访问的数据。
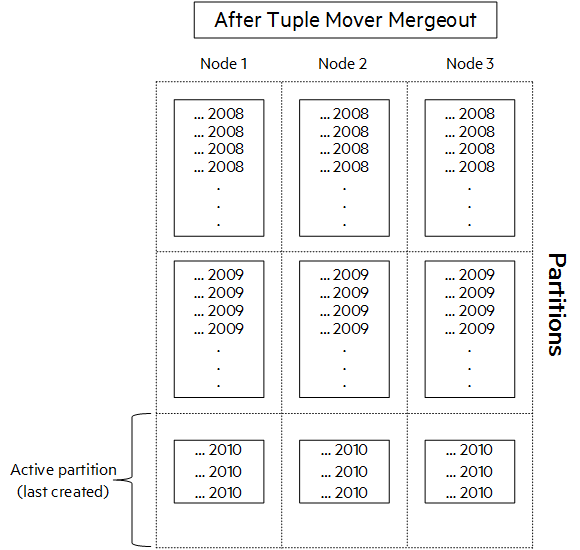
执行合并时,对于不活动的分区,Tuple Mover 会将所有 ROS 容器合并到一个 ROS 容器中。在活动分区中,Tuple Mover 使用基于分层的算法来组合 ROS 容器。
下图显示了 2008 和 2009 分区的组合 ROS 容器以及活动分区中新加载的数据。
1.2 分区与分段的区别
分段可帮助您在集群中的节点之间均匀分割数据,以利用 MPP(大规模并行处理)架构。
分区有助于将每个节点上的数据组织到不同的存储容器中。分区可减少 I/O 并提高查询性能。
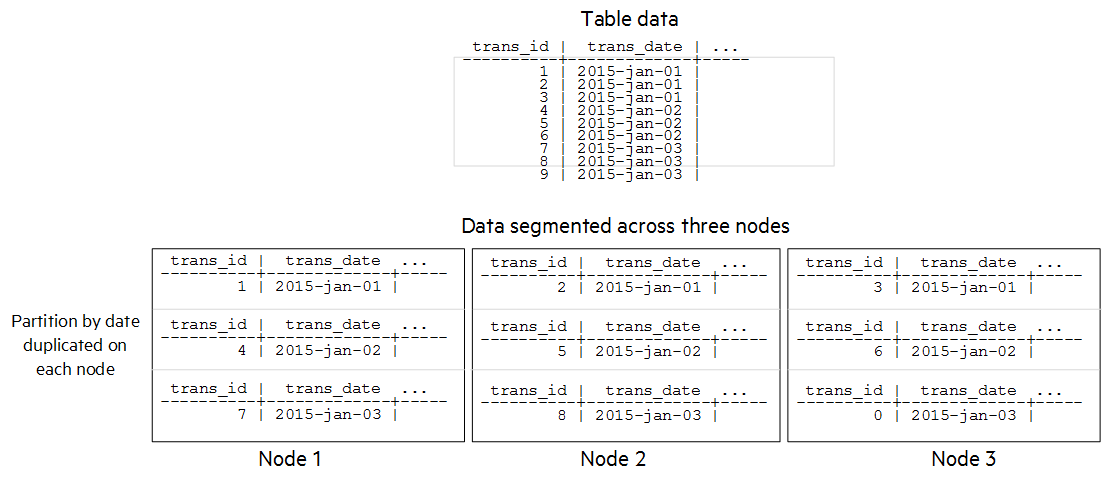
假设事实表至少有以下两列:
- 交易ID(trans_id)
- 交易日期 (trans_date)
创建事实表时,您应该:
- 对 HASH (trans_id) 上的表投影进行分段,以在所有节点上均匀分布数据。
- 按日期对表进行分区。
通过此表定义,每个分区的数据均匀分布在所有集群节点上。此分段允许针对特定分区的查询并行执行。以下简单示例显示了数据的分布方式:
1.3 什么是活动分区?
如前所述,表的活动分区是最后创建的分区,而不是最后更新的分区。活动分区包含经常加载的数据。
您可以通过更改 ActivePartitionCount 配置参数来更改每个表的活动分区数。默认值为 1。
Tuple Mover 将非活动分区的存储容器合并到单个 ROS 容器中,为每个分区创建一个 ROS 容器。 Tuple Moves 使用 strata 算法合并活动分区的存储容器,该算法决定如何合并数据。
如果您经常将数据加载到最后两个分区,请将ActivePartitionCount更改为2。这是一个全局配置参数,会影响每个表。如果将其设置为 2,Tuple Mover 将分层算法应用于最后两个创建的分区。
增加 ActivePartitionCount 可减少 Tuple Mover 操作的数量。但是,您的投影中可能会出现过多的 ROS 容器。
使用以下查询查找投影的活动分区:
SELECT DISTINCT partition_key
FROM strata
WHERE projection_name ILIKE '%sktest%'
AND schema_name ILIKEe '%public%';
partition_key
---------------
5
8
9
(3 rows)
1.4 哪些表需要做分区?
Vertica 建议您仅对大型事实表进行分区。不要对小表或维度表进行分区。这样做会创建大量 ROS 容器,这会快速增加目录大小并影响查询性能。
1.5 如何归档很少使用的数据?
您可能需要长期保留数据以用于历史目的,而不是删除数据。
如果是这种情况,请考虑为历史分区和旧分区创建存储策略。您可以将较旧的分区存储在速度较慢且较便宜的存储上。此选项可以释放速度较快且成本较高的存储,以便快速检索经常访问的分区。
有关详细信息,请参阅 Vertica 文档中的创建存储策略。
1.6 定义分区表达式时需要考虑哪些因素?
为表定义分区表达式时,请考虑以下事项:
- 数据保留策略
- 常用查询谓词
- 分区粒度对每个节点每个投影的 ROS 容器数量以及每个节点的 ROS 文件总数的影响
2、分区和存储裁剪
2.1 分区如何影响数据生命周期管理?
对 Vertica 数据库中的大型事实表进行分区可以使数据生命周期管理更加轻松并提高查询性能。
Vertica 提供以下功能:
- 从表中删除一个分区数据。
- 将很少使用的分区数据移至存档表。
- 将很少使用的分区数据移至较便宜的存储。
- 从存档中恢复分区数据。
使用分区和关联的 SQL 功能来管理您的数据保留策略。
2.2 什么是存储裁剪以及它与分区有何关系?
不同分区的数据会被隔离到单独的存储容器中。因此,在分区字段上使用谓词的查询可以从 Vertica 存储裁剪功能中显著受益。继续阅读以了解存储裁剪的工作原理。
在查询规划阶段,数据库优化器会识别不包含该查询所需数据的存储容器。优化器将此信息基于每个容器的分区列的最小值和最大值。在查询处理过程中,Vertica执行引擎会略过不相关的数据存储容器,减少I/O并提高查询性能。
假设您有一个包含三年数据的表,并按月分区,共有36个分区。这里有四种情况:
| 查询口径 | 存储裁剪 |
|---|---|
| 查询分析特定周或月的数据。 | Vertica 可以裁剪剩余 35 个分区的存储容器。 |
| 查询分析三个月的季度数据。 | Vertica 使用属于三个分区的存储容器(每个分区一个)并裁剪其余的。 |
| 查询谓词条件不是分区。 | 此查询没有有效利用存储修剪,因为谓词列的数据可能存在于多个分区中。 示例:表按 transaction_date 分区,但查询谓词为 zip_code 列。 |
| 查询在与分区列相关的列上有一个谓词。 | 此查询在适用的情况下利用存储修剪。 示例:查询条件有一个关于ship_date 的谓词。 Ship_date 通常与 transaction_date 在同一个月或之后的一个月。在这种情况下,Vertica 可以修剪这两个月除两个分区之外的所有分区。 |
2.3 如何知道我的查询是否利用了分区和存储裁剪?
要查找查询的修剪存储容器的数量,请执行以下步骤:
1、分析查询以获取 transaction_id 和 statements_id:
PROFILE SELECT * FROM <_table_name_> WHERE <_column_name_> BETWEEN 5 AND 7;
NOTICE 4788: Statement is being profiled
HINT: Select * from v_monitor.execution_engine_profiles where transaction_id=54043195528458555 and statement_id=1;
NOTICE 3557: Initiator memory for query: [on pool general: 19543 KB, minimum: 19543 KB]
NOTICE 5077: Total memory required by query: [19543 KB]
C1
----
6
7
5
(3 rows)
2、检查该事务的 QUERY_EVENTS 系统表,并确定查询计划指示在该查询执行时从处理中消除分区的位置:
SELECT node_name , event_details
FROM query_events
WHERE event_type = 'PARTITIONS_ELIMINATED'
AND transaction_id = 54043195528458555
AND statement_id=1;
node_name | event_details
------------------+-----------------------------------------------------------
v_vmart_node0003 | Using only 1 stores out of 3 for projection public.tab_b0
v_vmart_node0002 | Using only 1 stores out of 5 for projection public.tab_b0
v_vmart_node0001 | Using only 1 stores out of 2 for projection public.tab_b0
(3 rows)
3、分区和 ROS 文件以及 ROS 容器
3.1 ROS 文件和 ROS 容器有什么区别?
当使用 COPY 语句加载数据,并添加 /*+DIRECT*/ 时,Vertica 为每列创建一个 ROS 文件。 ROS 容器是 ROS 文件的逻辑分组。 Vertica 通过 COPY DIRECT 或 Tuple Mover 操作创建了 ROS 容器。
3.2 为什么我应该考虑每个节点每个投影的 ROS 容器数量?
Vertica 将分区数据隔离到不同的存储容器中。由于 Vertica 不会跨分区合并数据,因此拥有太多小分区可能会使存储容器的数量接近 ROS 容器的最大数量:1024。
如果您达到特定投影的此限制,并尝试将新数据加载到该投影中,则加载会失败并出现“Too many ROS containers”错误。如果出现该错误,请执行以下操作之一:
- 使用 ALTER_PARTITION 将分区表达式更改为更细粒度的分区方案。
- 使用 MOVE_PARTITION 将旧分区移动到存档表。
3.3 每个节点的 ROS 容器总数如何影响我的数据库?
每个节点的 ROS 文件数量为:
(# storage containers) x (# columns per projection)
ROS 文件的数量可能是造成较大 Catalog 大小的主要原因。拥有较大的 Catalog 会消耗系统内存并减慢其他数据库操作的速度,例如系统表查询、数据库启动、数据库备份和临时恢复。
如果每个节点包含 100 万个 ROS 文件,则 Catalog 大小约为 3-4GB。在重新启动该节点之前,该节点不会释放该内存。
让我们看两个用例。
3.4 案例一:Catalog 大
你有一个数据库:
- 1,000 个表
- 每个表有 2 个 Projection
- 每个表 50 列(平均)
- 每个节点 50 个 ROS 容器
- 每个节点大约有 500 万个 ROS 文件。
您有 2000 个投影和 5,000,000 个 ROS 文件:
(1000 tables) x (2 projections per table) = 2000 projections (50 columns) x (2000 projections ) = 10,0000 x (50 ROS per projection) = 5,000,000 ROS files
您可以按日期对 300 个表进行分区并保留数据一年。这样做允许您使用 Vertica 分区管理功能管理单个日期的数据。然而,这使得 ROS 数量又增加了约 1000 万,使目录大小增加了一倍:
(300 tables) x (2 projections) = 600 projections (365 days) x 600 = 219,000 x (50 columns) = 10,900,000 ROS files
在这种情况下,您有两个选择:
- 按日期分区会为每个节点的每个投影添加至少 365 个 ROS 容器,因此您只需要按日期分区少量表。避免对小表进行分区,如果可能,请按周或月对大多数表进行分区。
- 如果需要按日期分区,请确定可以通过将类似表合并为一个表来减少 ROS 容器数量的位置。Schema 通常继承自旧式 OLTP 系统,该系统按地理位置将表拆分为多个表以提高查询性能。为获得最佳结果,请将这些表合并为一个表。
3.5 案例二:每个 Projection 有太多 ROS 容器
您有一个数据库:
- 100个表
- 每个表 2 个 Projection
- 每个表 50 列
- 每个节点 50 个 ROS 容器
- 每个节点大约 500,000 个 ROS 文件
您有 200 个投影和 500,000 个 ROS 文件:
(100 tables) x (2 projections per table) = 200 projections (Average of 50 columns) x (200 projections) = 10,000 x (50 ROS containers per projection) = 500,000 ROS files
假设您要按日期对 10 个表进行分区并将数据保留三年。这样做允许您使用分区管理功能管理单个日期的数据。在这种情况下,您可能不会积累大量 ROS 文件。但是,加载数据时,可能会遇到 ROS Pushback(1024 个 ROS 容器)。
1 table x (365 x 3) daily for 3 years = 1095 ROS containers for inactive partitions
因此,活动分区中没有空间可供接收数据。
或者,如果您按周分区:
1 table x (52 x 3) weekly for 3 years = 156 ROS containers for inactive partitions
这种替代方案创建的 ROS 容器明显减少。在这种情况下,请考虑按周而不是按日期对数据进行分区。
在规划未来数据增长时请考虑这些问题。您的组织可能会将其他分析应用程序的数据移至 Vertica,或者在查看数据库的存储优化和性能功能后决定保留更多数据。
4、重新分区与数据重组
4.1 可以对未分区表进行分区吗?可以更改表的分区表达式吗?
您可以使用以下命令对现有表进行分区或更改表的分区表达式:
=> ALTER TABLE <_table_name_> PARTITION BY <_partition_expression_>
当您运行此语句时,存储容器的任何现有分区键信息将立即被删除。您必须使用 REORGANIZE 关键字根据新的分区表达式重建此信息。
注意:当有节点宕机时不要更改表分区。
4.2 当我使用 REORGANIZE 关键字时会发生什么?
单独或一起使用 PARTITION BY 和 REORGANIZE 关键字对表进行分区或重新分区,如下所示:
=> ALTER TABLE <table_name> PARTITION BY <partition_expression> REORGANIZE;
当您运行此语句时,Vertica 将删除所有现有分区键、对表重新分区并重新组织表。
数据重组操作是在后台运行的 Tuple Mover 进行。重组操作以块的形式读取数据,以免影响数据库性能。然后,REORGANIZE 根据新的分区方案将数据写入 ROS 容器,并将分区键添加到 ROS 容器对象。
4.3 我可以推迟重组吗?这样的延迟会产生什么影响?
为了最大限度地降低正在运行的数据库的性能,重新组织一次仅适用于 ROS 容器的子集。
重新分区后延迟重组操作会导致以下限制:
- 您无法在分区表达式已更改但未重新组织的表上运行分区函数。
- 对于分区表,没有分区键的 ROS 容器不参与 Tuper Mover 合并。这可能会导致 ROS Pushback。
重新分区后尽快重新组织数据。监视重组操作的进度,直到针对已更改表上锚定的所有投影完成该操作。
4.4 如何监控重组流程的状态?
使用以下系统表监视重组后台进度:
- VS_TUPLE_MOVER_OPERATIONS
- PARTITION_STATUS
- PARTITION_REORGANIZE_ERRORS
要查看给定表的分区历史记录,请查询系统表 CATALOG_EVENTS。
4.5 怎么删除表分区?
要更改表以使其不再分区,请使用以下语句:
=> ALTER TABLE <table_name> REMOVE PARTITIONING;
从表中删除分区后,Vertica 会像对待任何其他非分区表一样对待该表。 Vertica 使用 Strata 算法合并 ROS 容器。
5、分区限制注意事项
5.1 每个表的分区数量有限制吗?
每个表的分区数量没有限制。然而,不同的分区数据被隔离到不同的 ROS 容器中。 Vertica 将每个节点每个投影的 ROS 容器数量限制为 1024 个,因此该限制本质上是每个表 1024 个分区。
Vertica 防止单个 COPY DIRECT 语句加载超过 1024 个分区。
如果您有超过 365 个分区(大约是限制的三分之一),请观察每个投影的 ROS 容器计数并监控 Tuple Mover 合并操作。对于超过 365 个分区,您可能需要重新考虑该表的分区方案或将未查询的分区移至存档表。
5.2 如何查询内存中数据库 Catalog 的大小?
以下查询返回数据库目录的大小:
SELECT /*+label(databaseCheck_DB_Basic_Information_Catalog_Size)*/
nvl(n.subcluster_name,'Enterprise Mode') subcluster_name,
foo.node_name,
now() AS Check_Time,
MAX(catalog_size_in_MB) AS Catalog_size_in_MB
FROM
(
SELECT
node_name,
SUM((dc_allocation_pool_statistics_by_second.total_memory_max_value -
dc_allocation_pool_statistics_by_second.free_memory_min_value))/(1024*1024) AS
Catalog_size_in_MB
FROM
dc_allocation_pool_statistics_by_second
GROUP BY
1,
TRUNC((dc_allocation_pool_statistics_by_second."time")::TIMESTAMP,'SS'::VARCHAR(2))
) foo left join nodes n on foo.node_name = n.node_name
GROUP BY 1,2
ORDER BY 1,2;
5.3 如何检查分区数量是否导致 Catalog 过大?
有几种情况可能会导致数据库目录过大。大型 Catalog 是指 10 GB 或更大。
以下查询返回具有最大 ROS 容器的前 50 个投影。如果您发现结果中的表已分区且分区计数很高,请考虑修改分区方案,以便 Vertica 创建更少的分区。
SELECT s.node_name,
p.table_schema,
s.projection_name,
COUNT(DISTINCT s.storage_oid) storage_container_count,
COUNT(DISTINCT partition_key) partition_count,
COUNT(r.rosid) ros_file_count
FROM storage_containers s
LEFT OUTER JOIN PARTITIONS p ON s.storage_oid = p.ros_id
JOIN vs_ros r ON r.delid = s.storage_oid
GROUP BY 1, 2, 3
ORDER BY 4 DESC
LIMIT 50;
