




前面我们初步了解了TiDB的设计理念以及基础架构,在分布式存储层,TiDB包括TiKV行存储以及TiFlash列存储,其中TiKV主要用来支撑OLTP类型的业务,TiFlash则更适合OLAP分析类场景。后面笔者决定用两篇文章来分别讲述TiKV和TiFlash,本文主要介绍TiKV。
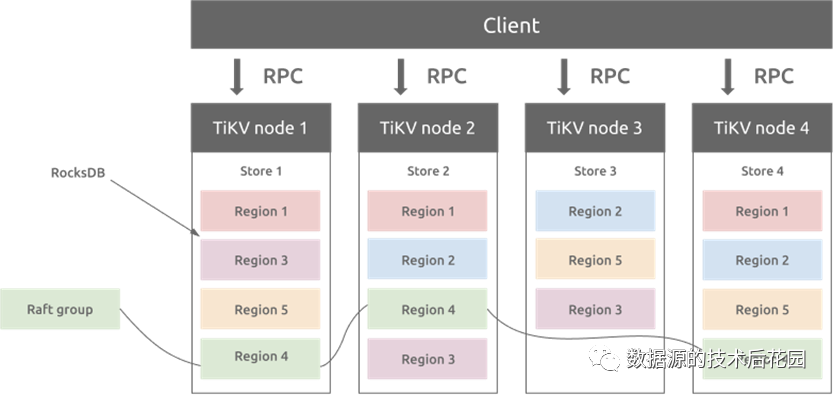 |
行存储TiKV由多个TiKV服务器组成,使用Raft在TiKV服务器之间复制Regions。每个TiKV服务器都包含不同Region的Leader或Follower。在每个TiKV上,数据和元数据被持久化到RocksDB,RocksDB是一个可嵌入的、持久化的键值存储。每个Region有一个可配置的最大大小,默认为96MB。每个服务器的Raft Leader负责处理相应Region的读/写请求。
Raft算法响应读写请求时,在Leader和Follower之间的基本执行过程为:
(1)Region Leader接收来自SQL引擎层的请求。
(2)Leader将请求追加到它的日志中。
(3)Leader将新的日志条目发送给Followers,Followers将这些条目追加到自己的日志中。
(4)Leader等待Followers做出反应,如果半数以上节点成功响应,Leader就提交请求并在本地应用它。
(5)Leader将结果发送给客户端,并继续处理传入的请求。
以上过程虽然可以保证数据的一致性和高可用性,但由于这些步骤是顺序发生,因此并不能提供高效的性能。为了实现高读/写吞吐量,在TiKV中实现了多项优化。
一.写优化
优化点1:上述过程中的(2)和(3)可以并行执行,如果一定数量的Follower成功追加日志而即使Leader追加日志失败,此时仍然可以提交。
优化点2:Leader发送日志后不需要等待Follower响应,可以假设成功,并使用预测的日志索引发送进一步的日志。如果出现错误,Leader调整日志索引,重新发送复制请求。
优化点3:应用已提交日志条目的Leader可以由另一个线程异步处理。
基于以上优化,Raft流程更新为:
(1)Leader接收SQL引擎层的请求。
(2)Leader将相应日志发送给Follower,并在本地并行追加日志。
(3)Leader继续接收来自客户端的请求并重复步骤(2)。
(4)Leader提交日志并发送给另外一个线程来应用。
(5)Leader应用日志后,将结果返回给客户端。
二.读优化
为了保证从Leader读取数据的序列化语义,需要为每个读请求发出一个日志条目,并在返回之前等待该条目被提交。但这个过程比较昂贵,为了提高性能,可以避免日志同步阶段。Raft保证一旦Leader写入成功后就可以响应任何读请求,而不需要跨服务器同步日志。但Leader选举后可能会发生Leader角色在Raft组中移动的情况,为了实现对Leader的读取,TiKV实现以下读取优化。
(1)读索引。当Leader响应读请求时,将当前提交索引记录为本地读索引,并向Follower发送心跳以确认其Leader角色。一旦它的应用索引大于或等于读索引,就可以返回该值。这种方法提高了读性能,但会带来一定的网络开销。
(2)租约读取。Leader和Follower约定一个租期,在租期内Follower不发出选举请求,这样Leader就不会被改变。在租期内,Leader可以在不连接Follower的情况下响应任何读请求。如果每个节点的CPU时钟相差不大,这种方法比较合适。
(3)跟随者读(Follower read)。Follower响应客户端读请求,当Follower收到读请求后,它会向Leader请求最新的读索引,如果本地应用的索引大于或等于读索引,则Follower可以将该值返回给客户端,否则必须等待应用日志。跟随者读可以减轻热点Leader的压力,从而提高读性能。
三.管理海量Regions
海量Regions分布在不同服务器上,可能存在节点之间不均衡的情况。服务器也可能会出现被添加或移出的情况。TiDB使用Placement Driver(PD)调度Regions的副本数量及位置。PD初始化时通过心跳从存储引擎上获取Region的位置信息,之后监视每个服务器上的工作负载,并在不影响应用的情况下将热Regions迁移到不同的服务器。
维护大量Regions涉及心跳和管理元数据,导致大量网络和存储开销。为优化此问题,可以根据Region负载繁忙程度,调整发送心跳的频率。
四.动态Region拆分与合并
当Region访问过多会导致负载不均,这样的Region应该分割成更小的Region便于均衡负载。另一方面,太多小的Region可能很少访问但是系统仍然需要维护心跳和元数据,这些Region应该进行合并。注意,为了保持Region之间的顺序,只合并键空间相邻的Region。Region的拆分和合并由PD动态的向TiKV发送命令完成。
Region拆分过程类似Raft中的普通更新请求,步骤如下:
(1)PD向Region的Leader发出split命令。
(2)Leader接收到split命令后,将命令转换为日志,并将日志复制到所有Follower节点。
(3)当多数派复制日志完成后Leader提交split命令,并将命令应用于Raft组的所有节点。应用过程包括更新原始Region的范围和epoch元数据,并创建新的Region以覆盖剩余的范围。
(4)对于分割Region的每个副本,将创建一个Raft状态机并开始工作,形成一个新的Raft组。原始Region的Leader将拆分结果报告给PD。此时分割完成。
如上,Region分割因为只需要更改元数据,所以开销很低。Region的合并过程是PD移动两个Region的所有副本,将它们放在不同的服务器上,然后通过两个阶段操作在每个服务器上本地合并两个Region的相同副本;之后停止一个Region的业务,并与另一个Region合并。
