




发布会现场感受
发布会官方讲了什么
云数据库的思考


一体化数据库

LTS 版本就是会持续的完善现有的功能,不断发布 Patch 版本。这个时间会持续 4 年(维保服务),然后个别客户有需要在跟 OB 协商继续 2 年维保支持。至于 6 年后就不是现在操心的事了(6年里足够一个产品老版本稳定了,新的业务肯定是用后面新版本的 LTS 版本)。4.2.1 依然是 LTS 版本,只是不大可能增加新功能,可能只满足于修复现有的 BUG 。4.2.5 版本功能大于 4.2.1,4.2.1 也可以在线升级到 4.2.5 版本。 4.2.1 ~ 4.2.5 包括以后的 4.2 序列版本并不只是单纯的只适合 TP 场景。它依然具备一些 AP 分析能力。虽然不支持列存,但是行存下表数据压缩比也是很高。此外,也支持很多复杂的分析函数、窗口函数等。SQL 算子有部分实现了向量化。以前的关于 OB 适合 HTAP 负载依然是对的,只不过这个 AP 指的是 R-OLAP,指在交易数据库上一些复杂的关系型分析业务场景。但不适合 M-OLAP 那种场景(比如说 ODS 业务场景,大批量的数据 ETL、多维度查询等)。同样 4.3.3 也不是说只有 AP 的能力就不适合 TP 了。TP 的基本功能在 4.3.3 版本利也是有,TP 的新功能可能会晚一两个版本出现在 AP 版本里。这是 OB 内核产品经理的解释,具体什么功能没有明说,还需要观察。不过我想基本的 OLTP 常用增删改查、事务、分区表、表组肯定都是可以用的。在 OB 大的产品发展规划上,4.2.5 以及后面版本 跟 4.3.3 以及后面版本 最终会在 OB 某个 版本汇聚到一起(就吧),这表示两个版本到时候都支持在线升级到同一个版本。那时候应该就不会区分 TP 版本和 AP 版本。还要强调的是虽然现在不严谨的说分 TP 版本和 AP 版本,本质上还是一个软件 OceanBase。这个跟其他厂商的分布式数据库有 TP 版本和 AP 版本是不完全一样的,后者那个底层可能真是两个数据库内核。 4.3.3 GA 版本是指客户可以使用的版本,不限行业场景等。这个不是 LTS 版本。OB 后面还会出 4.3.4 , 4.3.5 ...后面 定有 LTS 版本。按 OB 的版本迭代节奏和能力,最终 LTS 版本也快了。估计两三个季度就发了。
OB 虽然兼容 ORACLE 和 MySQL,只是语法功能兼容,存储引擎和事务方面完全是自己独立的设计。所以 OB 没有 MySQL的 Innodb 引擎,也没有 ORACLE 的引擎。OB 的存储引擎也并没有特殊的名字,也不支持插件式引擎。OB 的存储引擎在 4.3.0 新增了列存功能,4.3.3 进一步完善了这个列存能力。即使现在 OB 新增支持了 KV、Redis,也并没有搞出一个新的存储引擎出来,依然是 OB 已有的存储引擎。原理还是 LSM Tree,Compaction 和 Compression 功能原理还是保持不变。 一体化的 SQL执行引擎跟上面同理,区别只是 ORACLE 租户和 MySQL 租户语法规则上的不同,以及 NOSQL 语法、语义和执行路径可能会有些不同(以后再深入研究一下)。此外进一步扩大了向量化引擎算子的比例(以前是 Volcano 引擎)。 一体化的事务引擎跟上面也同理。满足事务的 ACID,即使内部是个分布式事务对业务也是透明的。不过 SQL 事务和 NOSQL 事务在一起的时候功能特性表现如何还有待后续进一步研究。
OceanBase 在 2019 年就试点过一体机。2019 年云栖大会我还给 OB 一体机站台过。(参考:2019 OB 一体机介绍)。OB 今年推出的一体机已经比当初要强大很多了,在硬件上使用国产服务器(海光)、国产IB交换机(H3C),在软件上使用了 OB 4.3.3、分布式文件系统 OSM、基于 RDMA 技术的 ONM 网络加速软件。实现了 NUMA Aware 技术动态多实例绑定,最大化提升 OB 在一体机上的性能。此外还有 ODM CDP 数据保护技术,相比 OB 租户备份还原而言,这个 CDP 恢复技术效率更高(特别适合金融证券场景)。一体机还有管控产品,在机柜上显示屏里也可以看到集群运行概况,对现场巡检也非常有好。

OB 数据库一体机里有大量的软硬件优化技术,所以也说它是一部分数据库内核研发人员的梦想。OB 数据库一体机满配在压力测试下能将 IO 物理吞吐跑到 750GB 。这个对 AP 场景是个很有吸引力的数据。有关 OB 数据库一体机技术后面我会专门分享。
4.3.3 AP 能力
OB 虽然发布了两个版本,亮点还是 4.3.3 GA 版本的 AP 能力。之所以说这个版本 AP 能力很好,是因为有多个功能:
列存能力。
列存能力首先包括表可以从行存表转换为列存表或者行列混合表。不过目前这个转换还是 OFFLINE DDL 。所以它会锁表,此外还需要数据文件利额外为表预留 6~8 倍以上的可用空间。行存下表的数据已经有很高的压缩比,到列存下还能进一步压缩。
对于行列混合存储的表,SQL 引擎能智能的选择是查询行存还是列存。此前我也有个列存的分享,详情可以查看:OB 4.3 列存功能体验。
4.3.3 还新增了列存副本。使用方法是在原有的三副本(3F)或两副本(2F1A)架构下额外增加一个只读副本。只读副本 OB 在 2.2 就支持了,只不过这次是列存模式的只读副本(这个后面研究再分享)。可以专门用于读写分离场景下,复杂查询的使用。列存副本不参与 Paxos 选举,所以不能作为高可用的候选副本。列存副本的数据同步由 OB 内部调度,不需要运维同步数据。
Json 多值索引
Json 类型也是 OB 很早就支持过了,只不过针对 Json 列的索引功能此前还是很弱。这次增加了多值索引功能,可以针对 Json 数据中的数组类数据做索引。目前这个功能还不完善,只有在建表的时候指定多值索引。详情可以查看:OB Json 类型和多值索引体验 。
Roaringbitmap 类型
Roaringbitmap 类型在大数据存储和分析的特殊业务场景中有着非常高的性价比。比如说类似业务打点分析用户行为特征的场景。即使是几亿用户的几百亿行为记录分析,使用 Roaringbitmap 类型也能快速返回结果。详情可以查看:OB Roaringbitmap 类型体验 。
外表能力
OB 4.3 开始支持外表,目前支持外表所在的介质包括本地文件系统、NFS 文件系统以及对象存储(阿里云OSS、华为云OBS 以及其他支持 S3 协议的对象存储)。外表文件可以是 CSV 文件、Parquet 文件。
外表可以直接查询,也可以跟 OB 内部表联合查询。针对 Parquet 外表,OB 还会进一步加强算子能力,比如在条件下压、索引定位方面的能力。
未来 OB 还会支持 HDFS 文件、HIVE 外表等等。外表结合物化视图一起使用,极大的方便了传统大数据平台数据迁移到 OB 数据库。
物化视图功能
OB 4.3 开始推出物化视图和物化视图日志,如今物化视图支持全量刷新和增量刷新。增量刷新目前支持的 SQL 运算算子还比较有限,包括 COUNT、MAX、MIN、AVG、SUM 等。虽然有限,也能满足很多业务大数据统计的痛点。OB 物化视图还支持实时物化视图,这个对 SQL 复杂度也有一定限制,其利用基表的物化视图日志,能快速查询返回物化视图最新数据,性能远高于普通视图。这个功能将会成为 AP 业务最常用的功能。后面我会专门分享 OB 4.3.3 物化视图的详细使用体验。
物化视图增量刷新目前的限制估计后期会进一步完善。此外,在 MySQL 租户下的物化视图由于没有兼容性约束,限制反而会少一些。
向量化引擎和AI 能力
其实这个是 4.3.3 的最新的亮点,不过我还没有测试过,暂时也没有实际体验可以分享。蚂蚁开源的 DB-GPT 可以跟 OB 结合使用,OB 社区论坛上的论坛小助手其实就是基于 DB-GPT 和 OB 构建的问答机器人。

发布会客户讲了什么
OB 的产品发布会,不能只看 OB 讲,还要看看 OB 客户讲什么。尽管这些客户是 OB 定向邀约的,公开场合的宣讲对客户自身也是有一些内在约束。所以讲的内容也要是真实的,经得起内外考验的。不是能随便讲的。
下面挑选我认为有趣的两个客户分享的总结。
金融:交行
OB 在早期对外宣传的案例总是支付宝和网商银行的异地多活单元化案例,重点就是大规模 OB 集群下的业务平台和运维平台的建设。有人说有几个人有蚂蚁那么大的体量。
实际上很多金融客户的体量虽然不及蚂蚁那么大,但是这套方案也还是有使用场地的。比如说我知道的使用过 SOFA+OB 做分库分表或单元化的客户有南京银行的互联网金融业务、建行的ECIF业务、四川农信的金融核心业务,还有就是这次分享的交行的核心业务。类似这样的分享年年有,可能没有什么新意。此前我也总结过(参考:如何基于OceanBase构建应用和数据库的异地多活)但是交行这次的分享感觉比此前的分享要务实的多,给出了很多具体的数据,所以我觉得值得一提。

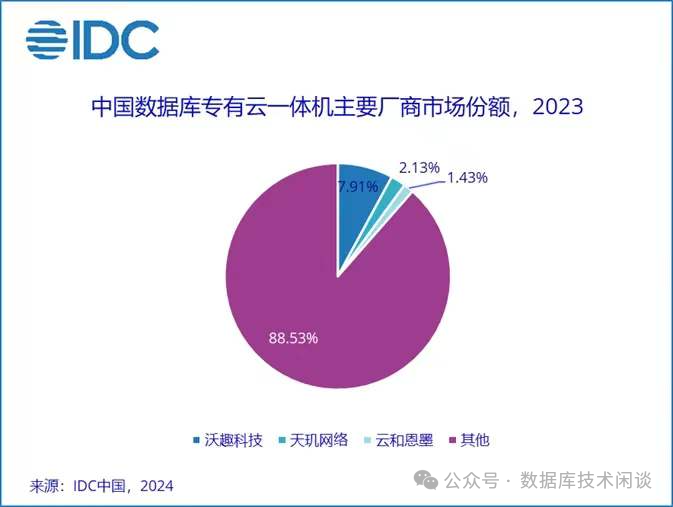
交行作为五大行之一,虽不是最大,那个体量也是不小的。所以,当交行全面推广使用 OB 后,其集群规模必然会很多。交行在实际使用 OB 时也是根据不同业务场景需求而决定 OB 的部署方案。
核心业务用三地五中心单元化架构,支持多机房部署,能够应用和数据库联动切换。这些业务都是核心业务,每个业务独立配置一到多个OB 集群,强调的就是一个“逃生”能力,OB 称之为高可用能力。在 OB 的单元化架构方案里多活和容灾是一个方案,平时多机房的流量可以配置,从单活到双活到多活,都只是一个设置的修改。
中大型复杂业务也用三地五中心部署方案,只是不需要做单元化。而中小型业务业务就共享使用一到多套 OB 集群,利用租户资源的隔离性、弹性伸缩型以及 OB 云平台统一运维能力,极大的提升了硬件资源利用率,降低了运维复杂度 同时也满足业务性能需求。
那么交行的 OB 集群规模到底多大呢?这个数据就很有意义(其他金融客户都不大愿意说)。

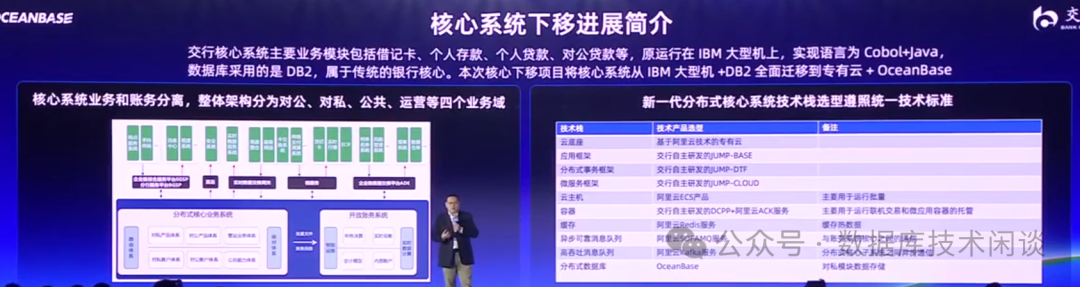

OB 的三地五中心架构里,第五个副本在异地最远,实际上是不会独立提供读写服务的(写延时会非常高)。所以业务读写 OB 主要发生在前面 4 个机房。交行这个图就很清晰的展示了这个。
所以综合起来交行的这次分享我感觉很赞。顺便说一点额外的,五大行里最早使用 OB 的是工行(资管系统)和建行(ECIF)。不过好像都没有全面推广。OB 能在交行全面推广也得益于交行的开发和运维团队在很早的时候就接触过 OB 0.4 版本并且在上面开发了属于交行的 CBase 数据库(开源地址:https://github.com/BankOfCommunications/CBASE )。OB 0.4 的时候就有 paxos 设计,以及分布式存储和事务设计。所以推测交行团队在这方面也有相对很深的理解和把控能力,后面在全面转向 OceanBase 时相对容易些。
互联网:贝壳找房
贝壳找房的业务大家都能理解,业务场景也比较复杂。但这次贝壳团队分享的却是它的一个存储领域的产品。由于我之前也在存储公司呆了一年多,所以特别留意听了一下。
贝壳机器学习平台的计算资源,尤其是 GPU,主要依赖公有云服务,并分布在不同的地理区域。为了让存储可以灵活地跟随计算资源,存储系统需具备高度的灵活性,支持跨区域的数据访问和迁移,同时确保计算任务的连续性和高效性;此外,随着数据量的增长,元数据管理的压力也在逐渐加大。贝壳在一年前选择基于 JuiceFS
的存储方案。碰到的难题大概是这套文件系统的元数据库读写非常高且延时要求很低。

贝壳调研了 OceanBase,对比 Redis ,OB 的天然的海量数据多机房同步能力、多模能力用来做元数据库非常合适。
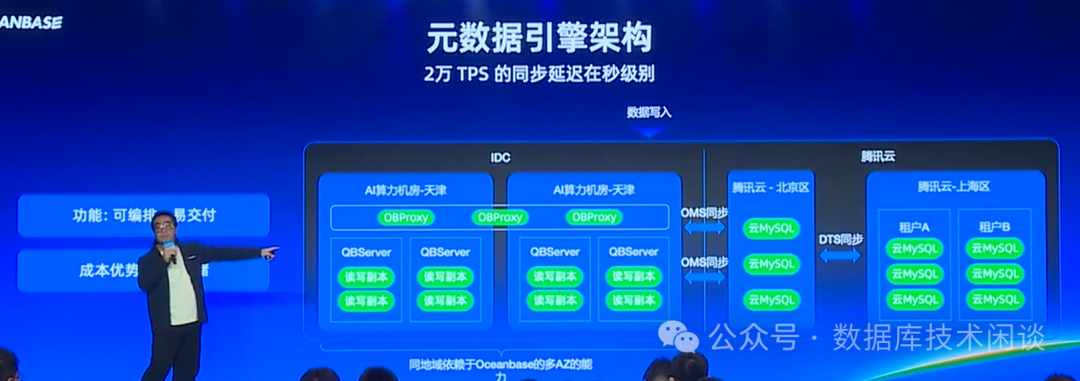
从贝壳这个元数据库架构看,其业务是本地机房和腾讯云上都有。本地机房都用 OB 搞定了,云上还在用 RDS MySQL,所以还不得不用 OMS 和 腾讯云的 DTS 做数据中转同步。这也恰好说明了前面阳老师说的单云问题。各个云厂商以及云厂商跟 IDC 之间数据库不统一给客户实际部署架构额外增加了很多复杂度。
假设贝壳在腾讯云上购买 OceanBase 或者在腾讯云 ECS 上自建 OceanBase,那么就可以利用 OB 自身的五副本能力构建横跨 IDC 和云的 OB 集群。当然推测实际上这个还是有很多挑战。涉及到现有业务的改造(RDS MySQL也不是轻易可以放弃的)、IDC 到腾讯云 VPC 网络的性能等等。
很多云产品也有元数据库。比如说阿里云的飞天、云盘、RDS、ODPS、ADB 等等产品,部署规模非常大,其元数据库读写性能和稳定性也就非常重要。这些数据库如果性能抖一抖,那影响的客户就是一大片。如果可用性还出问题,那可能是大面积的故障。近几年云厂商这些类似的故障都不少。所以,OB 作为一个元数据库对贝壳的存储产品才显得更加重要。
其他客户特别是公有云的分享也很有价值,有关 OB 公有云的体验打算后面专门分享。这里就先不说了。
其他
OB 发布会其他信息
发布会直播回放地址:https://www.oceanbase.com/conference2024 OB 官网文档地址:https://www.oceanbase.com/docs/oceanbase-database-cn OB 官网论坛地址:https://ask.oceanbase.com/
更多阅读
OB 2024年开发者大会参会总结 OB 4.3.3 AP 功能体验:RoaringBitmap 类型 OB 4.3.2 JSON 列类型和索引使用体验 OB 4.3.2 外部表使用体验 OB公有云体验三:深入使用 OB 4.3 列存表使用体验
