





系统性能优化是一个非常宽泛的话题,它贯穿于业务逻辑设计、库表设计、迭代、交付运维整个全链路生命周期.带宽、负载均衡、业务逻辑、服务器性能、数据库性能、交换机性能、缓存策略...,每一个节点的不合理设计,都有可能带来严重的问题,小到个别接口不可用,大到多个子系统当机,每一项都可以作为一个专题进行大篇幅的方案讨论,当我们在每一个节点都实现了集群、冗余的同时,又加以制度与流程的约束之后,系统的健壮性大幅度提升.但是对于运维人、架构师来讲,还是不够的,系统是否具有熔断、服务降级、快速修复、自我修复这些功能和机制,才是能让运维工程师睡好觉的关键因素.2018年在上海与天天拍车运维总监强哥喝酒的时候,他说了一句话,“运维工程师心态不安,一定是某个环节存在缺失,流程、方法、制度、工具中的一个或者几个不完善”,强哥说的对:)
回归正题,今天聊聊一个不常见,但是出现会致命的故障场景,《数据库服务器CPU偶发性激增超载,进而导致服务失效的问题》,偶发表示不常见,但绝对不是偶然,谈这个问题之前,先界定一个场景,就是发生的前提,《系统具有比较完善SQL审核制度》,那种不需要审核就上线,SQL随意写,连表满天飞还接入oltp的行为,就算了,天天都发生的当机不叫当机,叫生活.毕竟工程师和工程师是不一样的.你说是吧,EH.
现象:
个别接口响应时间增加,用户明显感知
CPU负载短时间内激增
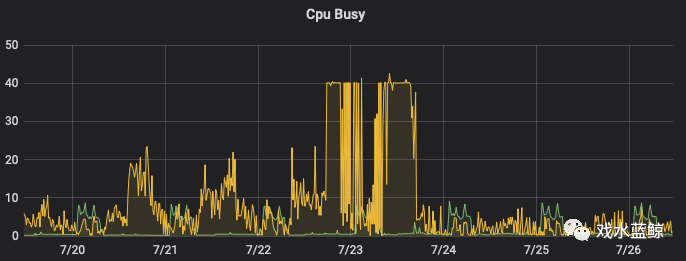
定位:
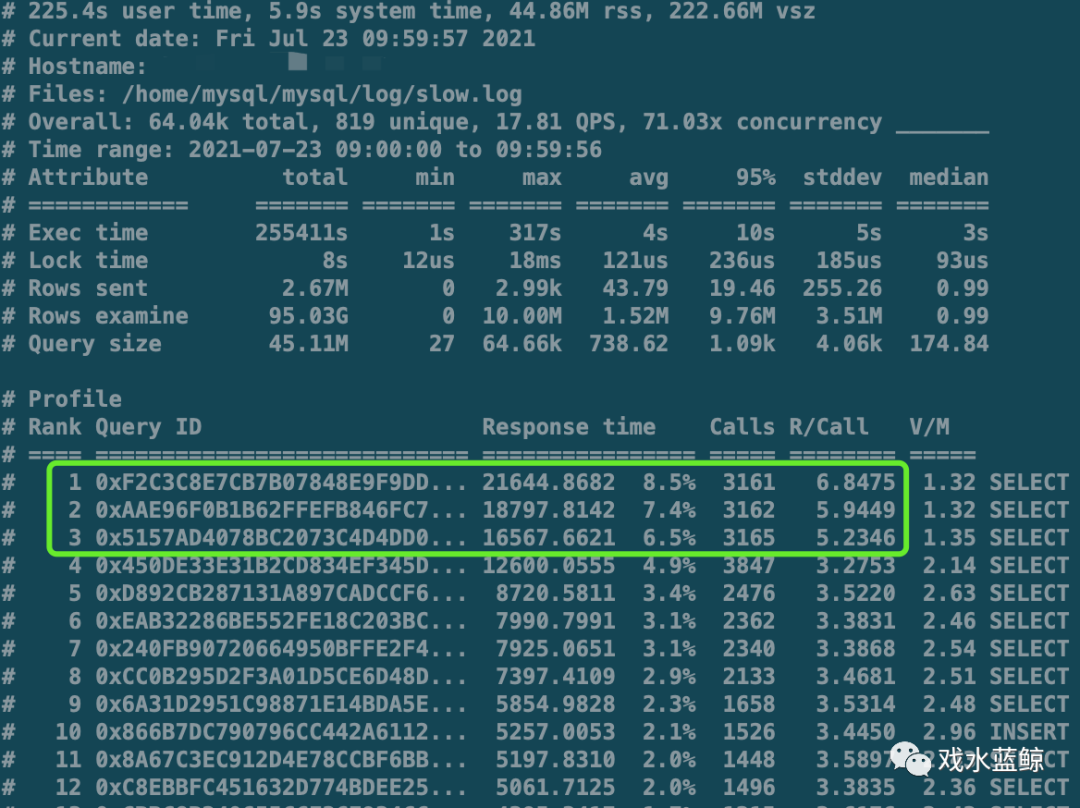
使用pt工具,进行第一轮分析.解决95%的场景.
对pt结果集进行二次分析,解决剩下的4%.
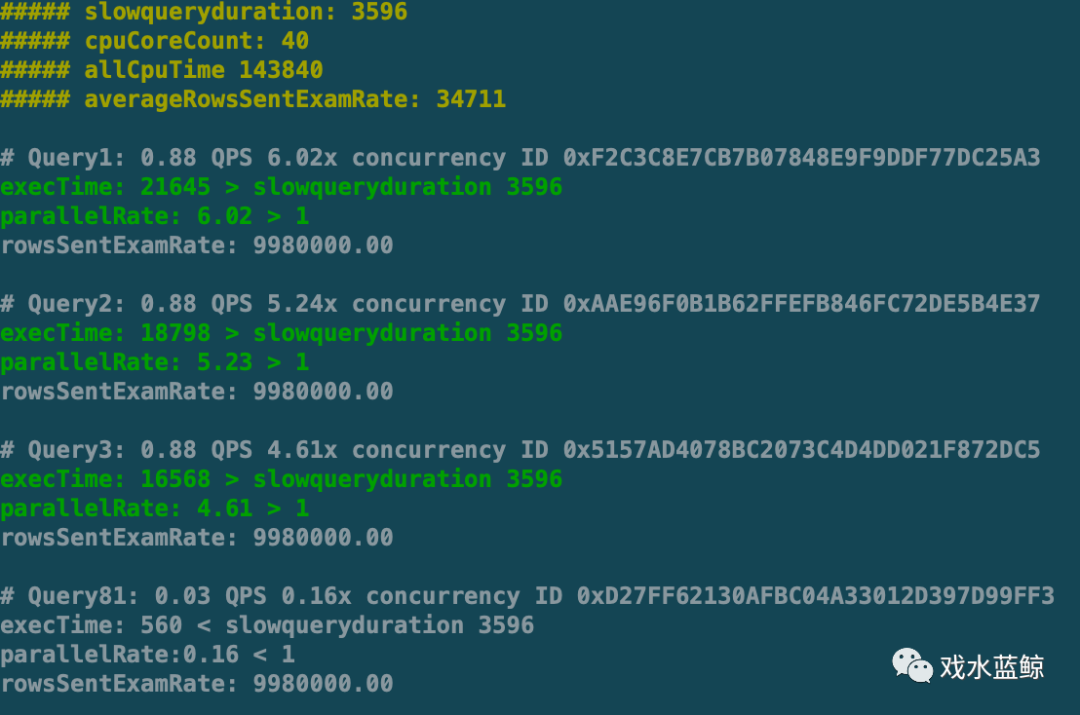
说到这里,一定有人会问,这个4%是什么?这个问题,在我曾经面试过的不止50人的中级高级dba中,没有一个人遇到过,也就无从回答,或许是遇到了,没有发现.那就是《检索和发送的行数比》.从业多年,这样的场景,遇到过3次.如果某位dba很幸运,遇到了这个场景,然后还是按照排列去撸前面的几个sql.很快你就会发现,前面的几条sql单独执行效率很高,看执行计划,合理使用索引过滤数据.这个时候dba心态是通常崩溃的,系统服务中断中,问题找不到.这类场景可以用一句成语来描述《城门失火殃及池鱼》,至于谁是城门谁是鱼,显而易见.二次分析结果如下,脚本附于文末.
使用tcpdump,解决最后的1%
剩下的这个1%,从业多年,只遇到过一次,因为之前MySQL版本的问题,慢查询阈值不能设置小于1秒,慢查询文件没有输出.cpu超载.数据库连接打满.这个时候使用tcpdump抓取数据包.再使用pt进行解析.会发现,小于1s的sql语句超级多,问题找到.
tcpdump -s 65535 -x -nn -q -tttt -i eth0 port $port -c 50000 -w tcpdump.pcap
tcprstat -l $IP -p $port -t 1 -r tcpdump.pcap
pt-query-digest --type=tcpdump tcpdump.pcap > slow_report10.log
对于95%以上的该当机场景,使用pt工具一轮分析,就可以定位问题的原因,按照排序,第一个或者前面几个SQL语句一定是罪魁祸首,撸了它们,问题迎刃而解.
解决:
首先说说可能触发上述当机事件的事件有哪些
上线操作.平稳运行的系统突然发生类似事件,十有九之,有上线,立即回滚
营销活动.瞬间并发激增,又分为两种场景
良性激增,纯粹因为qps激增导致超载,解决方案:
系统保留足够的资源以用来应付突发性需求
运营部门活动前知会技术部门,做好扩容等应对工作,所以说,保证系统SRE,并不完全是技术部门的工作.
非良性激增,触发隐患SQL,瞬间被放大,解决方案:
短期解决:接口限流,最好可以做到动态限流,牺牲掉一部分用户感受保障整个系统的安全
长期解决:微服务化,功能剥离,代码层剥离,数据层也要剥离.牺牲自己,保障全局.
撰写本文的目的,是解决低效SQL并发激增造成的当机的场景,言归正题,优化SQL是一件老生常谈的事情,不再赘述
formatter一下,尤其较为复杂的SQL.清晰看出逻辑
查看表结构,索引结构
查看执行计划
检查列值区分度
经过上面四板斧,SQL为什么低效耗时,应该已经了然于胸,怎么优化凭个人本事,核心思路:《检索最少的记录得到想要的数据》.至于如何做到,理论知识+实操经验永远是真理.
到这里,还想再说一句,在我面试过的所有dba中,只有一个人正确回答了这个问题.《一条SQL语句里面,一个表最多会用到几条索引》,知道了正确的答案和MySQL取数的过程,那么SQL应该如何写才能发挥出聚簇索引表的优势,就是很简单的事情.
防范:
运维工程师需要的技能特别多,也特别繁杂,如果使用书籍来衡量的话,估计要几十本,但是做的事情确是很简单,就三条
1.争取不出事 2.出事出小事 3.快速恢复
个中心酸,只有我们这些OP们才知道.
如何防范
规则:严格的SQL军规
制度:严格的上线审核制度,不通过坚决不上线,上线权利必须在OP手里
工具:脚本化,半自动化,最好做到自动化审核,非交互式操作
写在最后:
即使我们有流程制度工具方法的各种保障措施,也不可能将所有问题和隐患杜绝在上线之前,比如说列值分布偏差,测试环境数据不充足,不能命中低效数据的场景,不知道有几位同行能够听得懂我这句话.听得懂的,肯定是资深运维工程师.所以说,全链路保障系统SRE,是运维工程师的价值所在.
屏蔽问题、快速发现问题、快速解决问题.我们一直在路上!
脚本:
#!/bin/bash
#####################################################################
#@@@ Author : bluewhalew(playful_bluewhale@hotmail.com)
#@@@ Name : Analysis_SlowQuery_E_S.sh
#@@@ Describe : analyze slowquery filr sent rows and examine rows
#@@@ Created in : 20170421
#@@@ Modified in : 20210513
#@@@ Para : $1 is slow query analyzed file(pt)
#@@@ Para : $2 is cpu core counts
#####################################################################
if [ $# != 2 ]; then
echo "para counts is false"
else
CurrentPwd=`pwd`
dir=$CurrentPwd/`date +%Y%m%d%H%M%S`
if [[ -d $dir ]] ; then
rm -fr $dir
else
mkdir -p $dir
fi
cd $dir
startTime=`date -d \`cat ../$1|grep "# Time range:"|awk 'NR == 1'|awk '{print $5}'\` +%s`
endTime=`date -d \`cat ../$1|grep "# Time range:"|awk 'NR == 1'|awk '{print $7}'\` +%s`
duration=$(($endTime - $startTime))
allCpuTime=`expr $(($endTime - $startTime)) \* $2`
echo -e "\033[33m##### slowqueryduration: $duration\033[0m" >> totalResult.log
echo -e "\033[33m##### cpuCoreCount: $2\033[0m" >> totalResult.log
echo -e "\033[33m##### allCpuTime $allCpuTime\033[0m" >> totalResult.log
#sleep 10
cat ../$1|grep "# Rows sent"|awk 'NR>1 { if($8 ~/M$/) print $8*1000000; else if ($8 ~/k$/) print $8*1000; else print $8}' > RowsSent.log
cat ../$1|grep "# Rows examine"|awk 'NR>1 { if($8 ~/M$/) print $8*1000000; else if ($8 ~/k$/) print $8*1000; else print $8}' > RowsExamine.log
t1=`cat ../$1 |sed -n 12p|awk '{if($7 ~/M$/) print $7*1000000; else if ($7 ~/k$/) print $7*1000; else print $7}'`
t2=`cat ../$1 |sed -n 13p|awk '{if($7 ~/M$/) print $7*1000000; else if ($7 ~/k$/) print $7*1000; else print $7}'`
t3=`cat ../$1 |sed -n 6p`
echo $t3 " " `echo "sclae=2; $t2/$t1" | bc` > result.log
awk 'BEGIN{cnt_a=0;cnt_b=0;}FNR==NR{a[cnt_a++]=$0;next} {b[cnt_b++]=$0} END{cnt=0;cnt_max=cnt_a<cnt_b ? cnt_b:cnt_a;for(;cnt<cnt_max;++cnt){print a[cnt]","b[cnt]}}' RowsSent.log RowsExamine.log >RowsSentExame.log
cat RowsSentExame.log |awk 'BEGIN{FS=","}{if ($1 != 0) printf "%.2f\n",$2/$1;else print $2}' > RowsSentExamRate.log
#cat RowsSentExame.log |awk 'BEGIN{FS=","}{printf "%.2f\n",$2/$1}' > RowsSentExamRate.log
cat ../$1|grep "concurrency, ID" > ID.log
awk 'BEGIN{cnt_a=0;cnt_b=0;}FNR==NR{a[cnt_a++]=$0;next} {b[cnt_b++]=$0} END{cnt=0;cnt_max=cnt_a<cnt_b ? cnt_b:cnt_a;for(;cnt<cnt_max;++cnt){print a[cnt]","b[cnt]}}' ID.log RowsSentExamRate.log |sed 's/,/ /g'|sed 's/ \+/ /g'|sort -t ' ' -k 13nr >> result.log
averageRowsSentExamRate=`cat result.log|awk 'NR == 1'|awk '{print $NF}'`
echo -e "\033[33m##### averageRowsSentExamRate: $averageRowsSentExamRate\033[0m" >> totalResult.log
echo " " >> totalResult.log
rowCount=`cat result.log|wc -l`
for (( id=2; id<=$rowCount; id++ ))
do
queryId=`cat result.log |awk 'NR == '$id''|awk '{print $2 " " $3}'`
cat result.log |grep "$queryId"|awk '{print $1 " " $2 "" $3 " " $4 " " $5 " " $6 " " $7 " " $8 " " $9}' >> totalResult.log
execTime=`cat ../$1 |grep -A 7 "$queryId"|sed -n '$p'|awk '{print $5}'|sed 's/s//g'`
parallelRate=`awk 'BEGIN{printf "%.2f\n",'$execTime'/'$duration'}'`
rowsSentExamRate=`cat result.log |grep "$queryId"|awk '{print $NF}'`
if [[ $duration -gt $execTime ]]; then
echo "execTime: $execTime < slowqueryduration $duration" >> totalResult.log
else
echo -e "\033[32mexecTime: $execTime > slowqueryduration $duration\033[0m" >> totalResult.log
fi
echo $parallelRate | awk '{if($0 < 1) print "parallelRate:'$parallelRate' < 1"; else print "\033[32mparallelRate: '$parallelRate' > 1\033[0m"}' >> totalResult.log
echo "rowsSentExamRate: $rowsSentExamRate" >> totalResult.log
echo " " >> totalResult.log
done
more totalResult.log
fi

