




作者介绍
林檐,专注探索如何利用大语言模型(LLM)技术,来自动化地从非结构化的医案数据中抽取知识,构建中医药领域的知识图谱,挖掘知名老中医医案经验。

背景

知识图谱构建流程图
Step1:准备样本数据
将经过数据预处理的 1081 条医案数据作为样本数据。
Step2:定义抽取目标
根据定义的本体构建的知识图谱模式层设定抽取目标,如疾病、相关疾病、症状、检查、舌象、脉象、配伍等关键信息,针对抽取目标类型,只能定抽取规则。
Step3:自动抽取知识
根据定义的抽取目标制定 Prompt 提示模板,采用“示范案例+关系列表”的提示模板引导大语言模型对医案数据进行自动化抽取,生成三元组。
以下是一个具体的 Prompt 示例:
“假如你是一个中医的关系抽取大语言模型,对鼻炎患者的症状和相关疾病进行关系抽取,抽取医案示范:“鼻炎近来密帘三天,弊病当然发作,涕多,涕难擤。头痛。鼻塞。鼻粘膜水肿,有分泌物。舌薄苔,脉浮紧。桑叶6g,薄荷6g,桔梗6g,石菖蒲6g,路路通10g,荆芥6g,白芷6g,苍耳子10g,金荞麦10g,蔓荆子10g。”。输出格式为[(“鼻炎”,“症状”,“涕多”),(“鼻炎”,“症状”,“涕难擤”),(“鼻炎”,“症状”,“头痛”),(“鼻炎”,“症状”,“鼻塞”),(“鼻炎”,“检查”,“鼻粘膜水肿”),(“鼻炎”,“检查”,“有分泌物”),(“鼻炎”,“舌象”,“舌薄苔”),(“鼻炎”,“脉象”,“脉浮紧”),(“鼻炎”“配伍”,“石菖蒲6g”),(“鼻炎”,“配伍”,“路路通10g”),(“鼻炎”,“配伍”,“荆芥6g”),(“鼻炎”,“配伍”,“白芷6g”),(“鼻炎”,“配伍”,“苍耳子10g”),(“鼻炎”,“配伍”,“金荞麦10g”),(“鼻炎”,“配伍”,“蔓荆子10g”)],学习上述抽取格式,抽取下列病案,以三元组格式输出,给定的句子为:“***”。给定关系列表:[‘症状’, ‘相关疾病’, ‘配伍’, ‘舌象’, ‘检查’, ‘脉象’],请给出关系列表中的关系。如果不存在则输出:无。
Step4:清洗抽取结果
利用正则表达式对自动化抽取生成的三元组数据进行清洗,去除错误、冗余、不相关和不完整的三元组,确保数据的准确性和可靠性。
Step5:存储三元组
将最终获取到的三元组数据存储到 NebulaGraph 数据库中。
在利用大语言模型抽取知识的过程中,为了保证其可靠性,本文直接将疾病和中药抽取成对应的三元组,在写入知识图谱的过程中进一步分解,保证图谱的合理性。同时在利用大语言模型抽取知识的过程中将中药实体及属性联合抽取,如某一个鼻炎患者的处方中,金荞麦的剂量10g抽取为(“鼻炎”,“配伍”,“金荞麦10g”)。本文在存储三元组之前,利用正则表达式对实体和对应属性进一步抽取。例如(“鼻炎”,“配伍”,“金荞麦10g”)抽取为(“鼻炎”,“配伍”,“金荞麦”)和(“金荞麦”,“剂量”,“10g”),在下文中具体展示构建的知识图谱。
利用 NebulaGraph 构建知识图谱
算法伪代码 构建提示模板,相关案例和关系列表 编写连接 NebulaGraph 的函数 for i :=0 to N do 遍历医案数据 将数据和模板生成问题 将问题传给LLM,获得对应的答案 清洗答案,删除不必要的三元组 构建当前医案的患者、检查、症状、处方的id for j:= 0to M do 遍历三元组列表
if relation'=="配伍”:判断·三元组中的中药是否包含剂量单位属性,有的话,进行属性抽取,将抽取结果写入图谱。Else:直接写入图谱。end for复制
实验
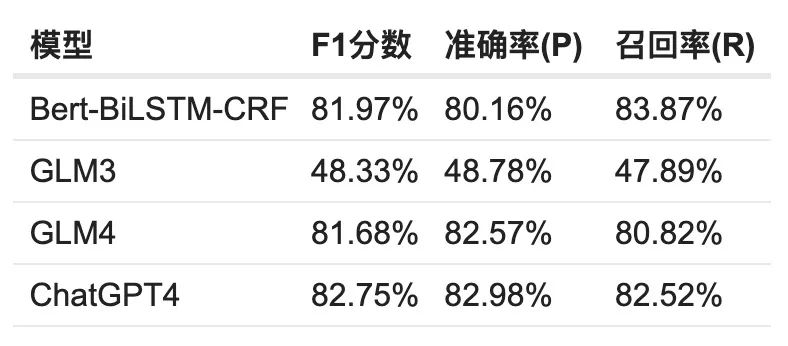
知识图谱展示
✦
如果你觉得 NebulaGraph能帮到你,或者你只是单纯支持开源精神,可以在 GitHub 上为 NebulaGraph 点个 Star!每一个 Star 都是对我们的支持和鼓励✨
https://github.com/vesoft-inc/nebula
✦
✦

扫码添加
可爱星云
技术交流
资料分享
NebulaGraph 用户案例集
案例推荐:
知识图谱案例:
苏宁基于 NebulaGraph 构建知识图谱的大规模告警收敛和根因定位实践
金融风控案例:
图数据库 Nebula Graph 在 BOSS 直聘的应用
360数科:基于 NebulaGraph 打造智能化的金融反欺诈系统
NebulaGraph 助力金蝶征信产业图谱深挖企业关系链,实现银行批量获客
智能运维案例:
58 同城基于 NebulaGraph 一键部署运维架构的实践
苏宁基于 NebulaGraph 构建知识图谱的大规模告警收敛和根因定位实践
大数据/图平台:
OPPO:通过 NebulaGraph 建设全局图数据库平台
数据治理:
微众银行:利用 NebulaGraph 进行全局数据血缘治理的实践
安全:




