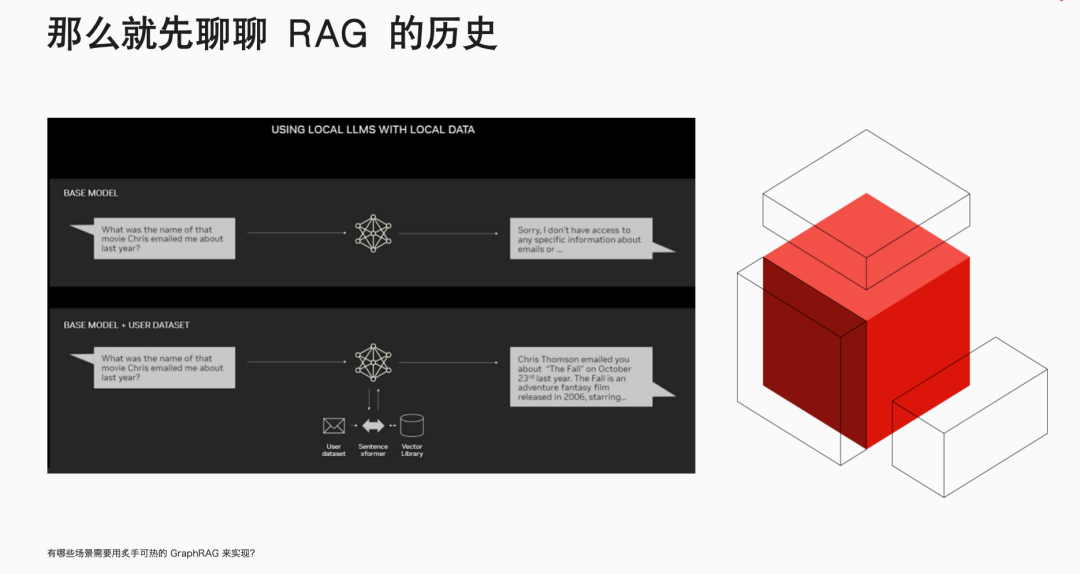
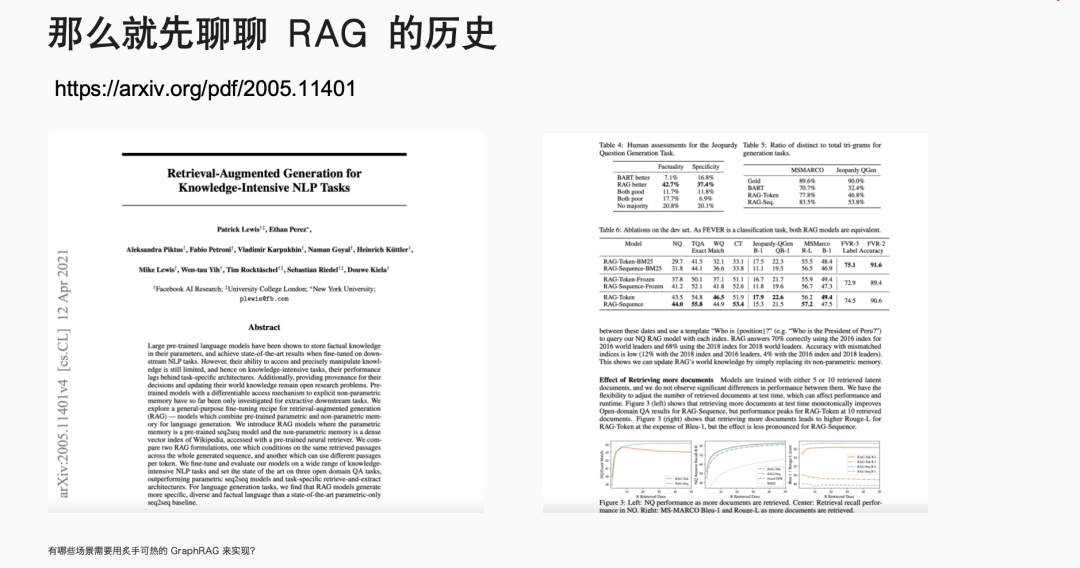
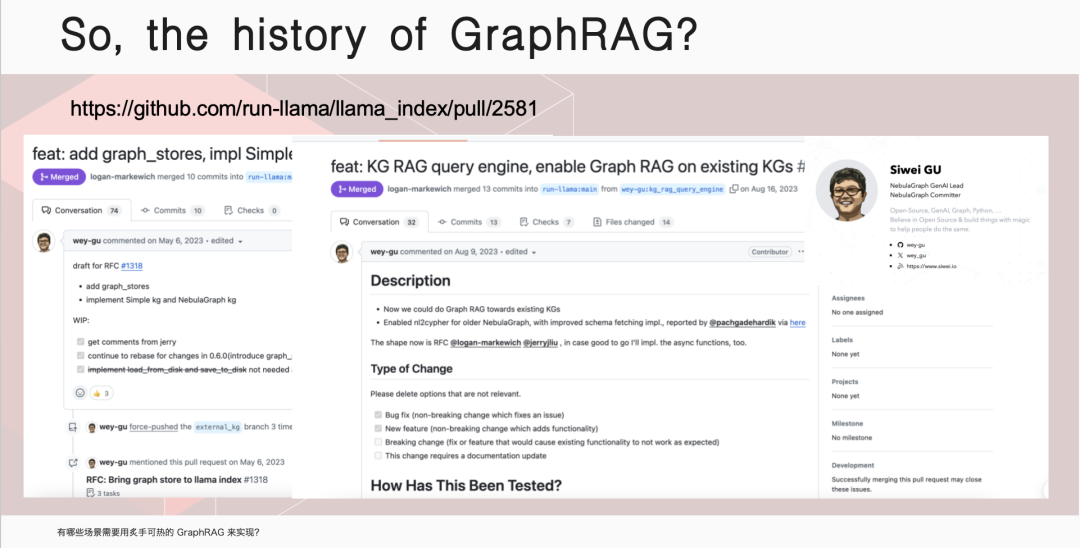
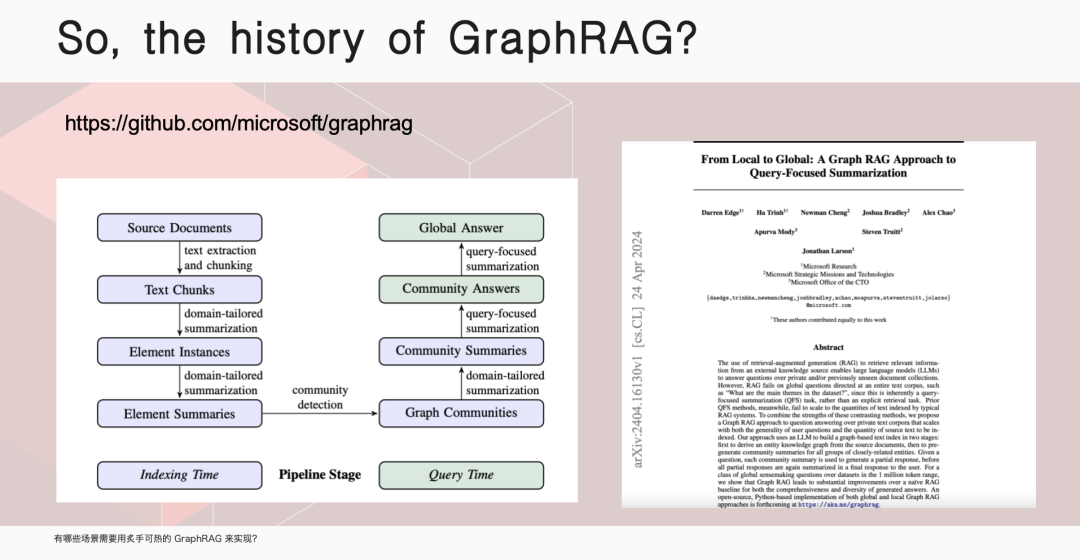
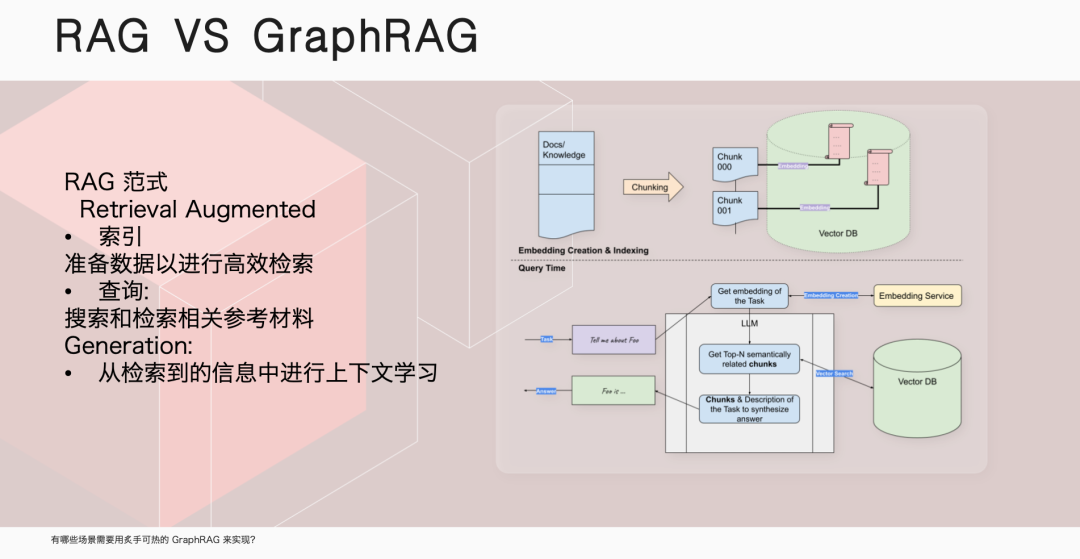
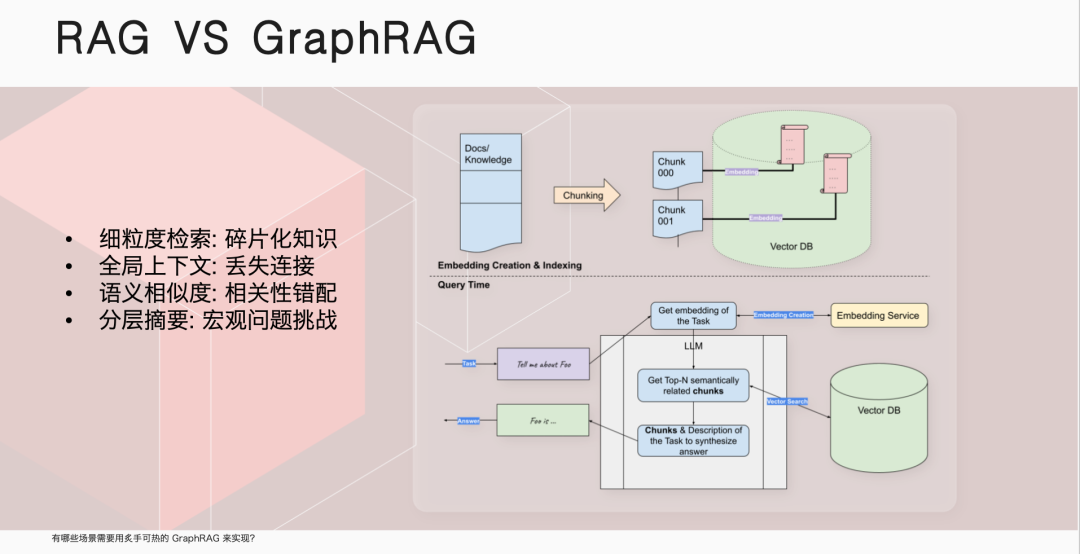
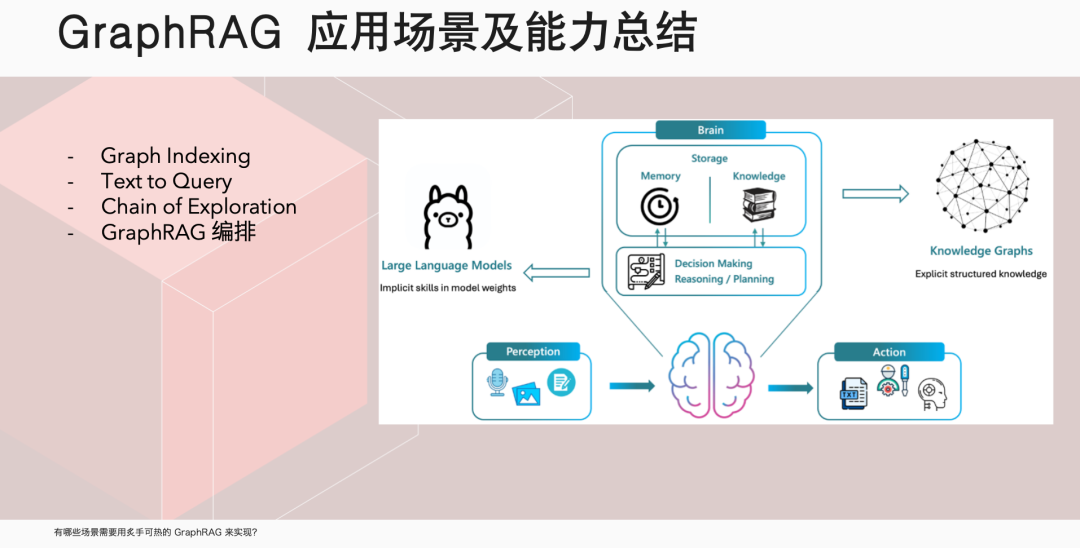
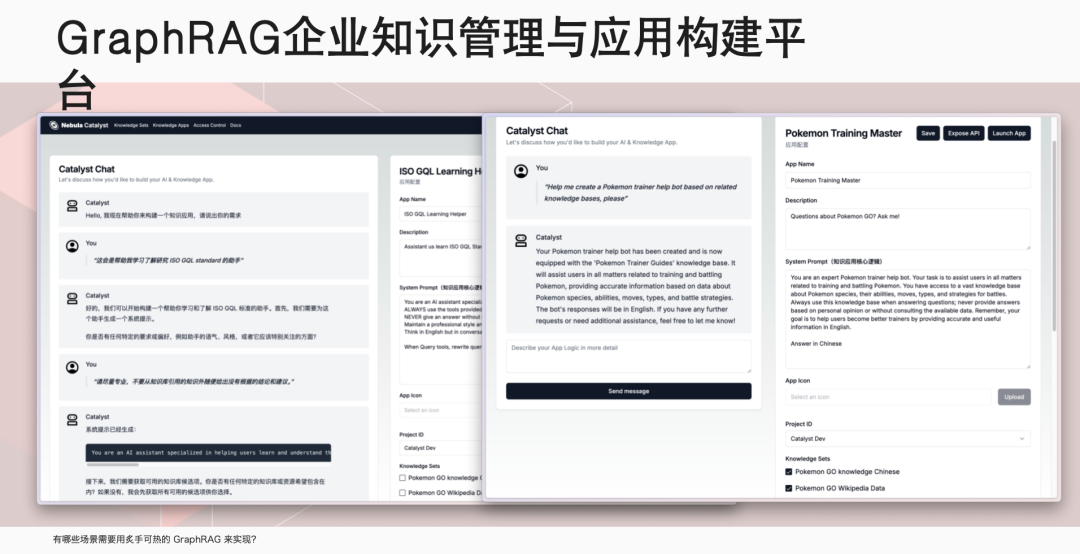
伊洪,NebulaGraph 社区布道师,跑步爱好者、开源爱好者。GitHub @yihong0618, 5.7k followers ,超 3w 个 commits. 云风作为中国程序员圈的先驱,曾在一篇文章中写道:“无论我们想学什么,都应该从学习它的历史开始。”这篇文章的许多观点都对我影响深远。今天,我们就从 RAG 的历史开始聊起。在传统大模型中,就是一个 model: 我问一个问题,经过该大模型,给出一个回答。那 RAG 则是我的问题会经历一个向量数据库,根据检索到的信息给出答案。向量数据库的广泛使用已经很久了,淘宝搜索、以图搜图或者谷歌、百度搜索,背后都是它在发挥关键作用。具体而言,RAG(Retrieval Augmented Generation)是一种结合了检索和生成的范式。它通过检索相关参考材料,然后从检索到的信息中进行上下文学习,以生成回答。它能够通过检索相关文档来增强生成模型的能力,从而在问答系统中提供更准确和丰富的回答。RAG 的历史可以追溯到 2020 年,那时还没有 GPT-3.5,人们普遍认为 GPT 只是一个玩具,因为它非常昂贵。在这个时期,Facebook 的 AI Research 团队发表了一篇论文,标志着 RAG 的诞生。这篇论文使用的是 GPT-2 模型,研究人员发现,将大型语言模型与自然语言处理相结合,可以产生非常好的效果。2022 年 3 月,OpenAI 公布了自己的 API, 这使得大家开始思考如何利用这个 API 来实现更多的功能,这时向量数据库的潜力被重新发现。大家意识到,通过向量数据库或者在传统数据库中加入向量类型,可以实现 RAG 的功能。例如,我有一个文档,先靠 OpenAI 或者其他大模型,转换成向量,储存在向量数据库里。这时我提出问题,大模型将其转换为向量,在向量数据库中查找最匹配的段落,组织语言后生成最终答案。通过这样的方式,有效解决大模型在专业领域知识不足的问题。随着向量数据库的兴起,图数据库公司也开始思考如何利用自己的技术来实现类似 RAG 的功能。NebulaGraph GenAI Team Leader 古思为提出了将图数据库与 RAG 结合的想法,并向 LlamaIndex 提了第一个PR,将 KG-RAG 转变为 GraphRAG. 这个转变意味着人们开始探索使用图模型来增强 RAG 的功能,利用图数据库的搜索强度可能比传统的向量更好,能够起到一定的 RAG 作用。微软在 2024 年 4 月份发布了 GraphRAG 的第一篇论文,市场上很多项目开始从 RAG 向 GraphRAG 迁移。这一转变的原因是 RAG 存在一些问题,而 GraphRAG 在某些领域存在突出优势。刚我们已经提到,在处理查询时,RAG 会利用大型语言模型,将查询转换为向量形式,然后在向量数据库中检索相关信息,并通过上下文学习生成回答。市场上对这一过程进行了多种优化,例如 rerank, 它使用大型语言模型对检索结果进行再次排序,以提高回答的相关性。然而,RAG 在处理细粒度检索和全局上下文搜索时存在局限性,如知识碎片化和上下文丢失问题。例如,在《红楼梦》中搜索林黛玉「哭泣」的原因可以找到结果,但搜索她「不笑」则无法找到答案,因为书中并没有提供相关信息。这些问题限制了 RAG 在企业级应用中的准确性和可靠性,因为企业需要的是接近 100% 的准确率,而 RAG 往往只能达到 95% 的准确率,这在商业环境中是不够的。相比之下,GraphRAG 不依赖于向量数据库,而是利用图数据库来存储和检索信息。它通过大型语言模型抽取文档中的主要关系和实体,并将它们转换为图结构存储在图数据库中。这种方法不仅提高了检索的强度,还能够更好地处理全局上下文搜索和领域知识集成的问题。GraphRAG 通过图索引、文本到查询的转换以及链式探索(Chain of Exploration)来增强模型的探索能力,类似于传统 RAG 中的思考量,但增加了探索量。这种基于图的方法可以利用图数据库找到真正的重组关系,实现更复杂的 AI 编排工具,满足市场上对高精度和高可靠性的需求。何时推荐使用 GraphRAG呢?我们可以考虑以下几种情况。首先,当面对高度离散的数据时。例如,企业可能拥有大量分散的文档和多年的杂乱数据库,GraphRAG 能够帮助整合这些信息,构建起企业知识图谱,从而实现更深层次的数据理解和利用。其次,当需要对全局信息进行理解时。以《红楼梦》为例,如果我们想要对书中的人物关系和情节有全面的理解,GraphRAG 能够提供全局的视角,帮助我们捕捉到更细微的联系和深层次的内涵。此外,领域知识的集成是 GraphRAG 的另一个重要应用场景。在职业招聘领域,GraphRAG 可以帮助匹配求职者的技能、工作经验与职位要求,从而提高招聘效率;在医学领域,GraphRAG 能够通过分析个体的特定特征来预测疾病,这对于精准医疗和个性化治疗方案的制定具有重要意义。NebulaGraph 已经在实际项目中应用了 GraphRAG. NebulaGraph 利用 GraphRAG 做 index, 对企业内部文档进行问答集的构建,旨在为企业提供高效、智能且易用的知识解决方案。通过引入知识级概念和 Meta Agent 概念,该平台显著降低了员工的使用门槛,使他们能够通过聊天式交互轻松构建知识应用,实现低心智负担的操作。在探讨 GraphRAG 技术时,我们不得不提到它的一个主要缺点——成本。GraphRAG 的高成本主要源于其初始化阶段,特别是当使用像 GPT-4 这样的先进模型来构建索引并存储在图数据库中时。然而这种成本在技术发展的不同阶段有所变化。正如我们刚开始提到的,GPT-3 曾因其高昂的价格而让许多用户望而却步,然而随着 GPT-3.5 的推出,成本有所下降。 GPT-4 问世后,人们只会在发布后的一段时间内觉得过于昂贵。随着时间的推移,成本将进一步降低,更多经济实惠甚至免费的模型会陆续出现。尽管 GraphRAG 的初期投入可能较大,但这种成本在很大程度上是一次性的:贵,但只贵一次。对于拥有大量文档和数据的企业来说,一旦构建了 GraphRAG 模型并将其存储在数据库中,这些数据和模型就成为了企业的长期资产。随着时间的推移,这些资产可以被反复利用,从而分摊了初始成本。此外,GraphRAG 带来的效率提升和知识管理优势,使得这种投资在长期看来是合理的。因此,尽管 GraphRAG 的启动成本较高,但它为企业提供了一种强大的工具,以实现更智能的数据管理和决策支持,这在当今的数据驱动型经济中至关重要。
🙋活动推荐
诚邀您参加【NebulaGraph x Airwallex 图数据库与风控】上海站,一场聚焦于图数据库与 GraphRAG 在风控领域创新应用的 nMeetup,点击海报了解活动详情,点击「阅读原文」报名~

🔍相关阅读
首发完整版教程,MCP 集成至 LlamaIndex 的技术实践
NebulaGraph MCP Server 正式开源!探索 AI+图数据库无限可能
GraphRAG vs DeepSearch?GraphRAG 提出者给你答案
NebulaGraph 的 GraphRAG 进展、实践
VLDB 2024|NebulaGraph RAG 正式官宣
基于 NebulaGraph ,构建属于你的 Graph RAG
如果你觉得 NebulaGraph能帮到你,或者你只是单纯支持开源精神,可以在 GitHub 上为 NebulaGraph 点个 Star!每一个 Star 都是对我们的支持和鼓励✨
https://github.com/vesoft-inc/nebula