




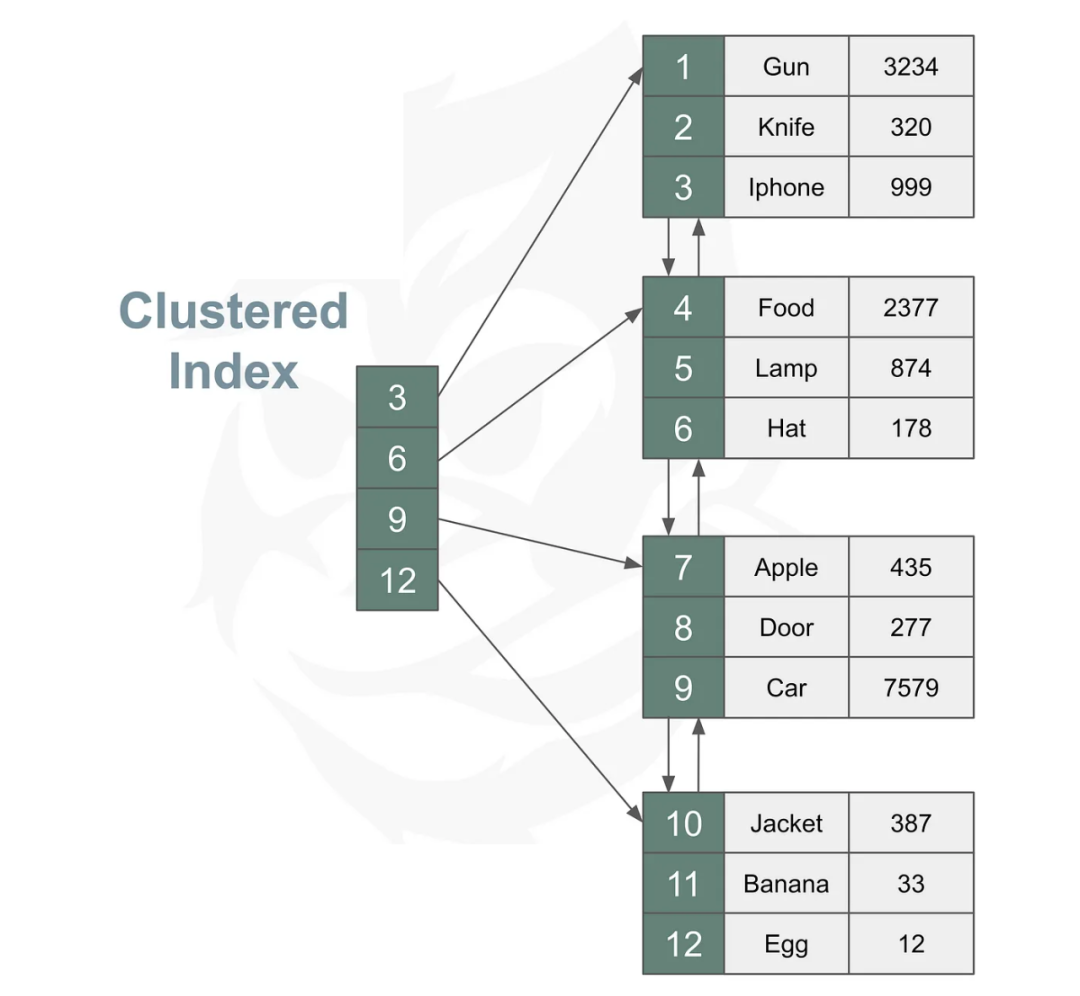
今天聊聊MySQL中的clustered index,它是InnoDB用来组织和存储数据的一种结构,它并不仅仅是一个索引,而是对数据的物理存储方式的一种描述。
InnoDB中的数据是以B+ tree形式存储的,每张表默认都会有一个索引,这就是聚集索引,它由表中的主键负责创建。
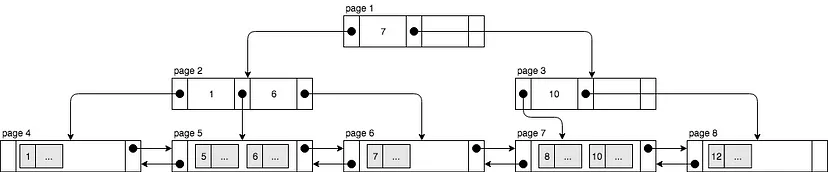
聚集索引中,每个节点都是一个page(InnoDB存储数据的最小单位),node存储key值和指向子节点的指针,叶子节点存储原始数据和附近节点的指针。
这样设计的好处是什么呢?
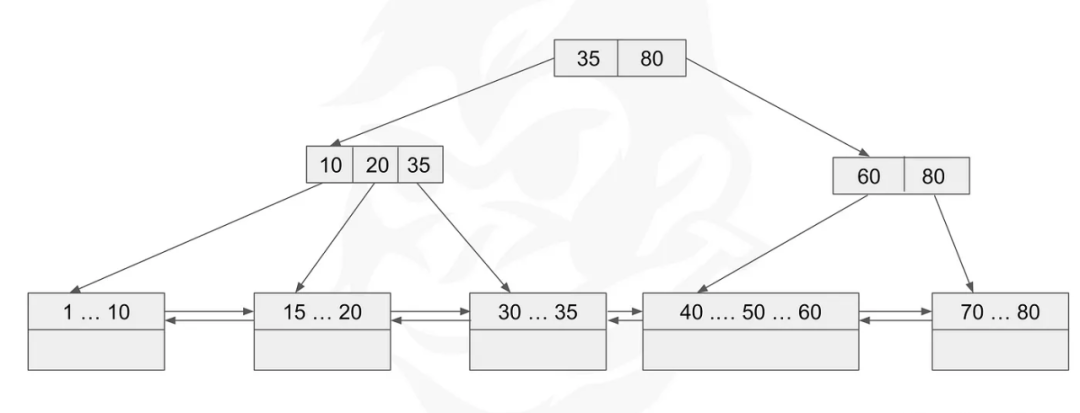
表按照clustered index的key排序,相近的node互相指针相连:
关系比较近的资料会在同一个page中,所以可能读取一个page,就能拿到所有数据,比如上图7和8对应的key就在一个node中 range query查询比较快,不用整个tree扫描,只要找到最小key所在的node,然后根据指针一致找到next node就可以了,比如上图5-10对应key的值。
既然clustered index的key值会影响range query、page空间使用率、插入的效率,所以设计一个恰当的clustered index很重要:
primary key存在,则clustered index就是它 primary key不存在,选第一个NOT NULL的唯一索引 两个都没有,则选择一个隐藏的字段(自增值)作为clustered index
clustered index和第二索引关系很大,后面会介绍下!
文章转载自虞大胆的叽叽喳喳,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
【专家有话说第五期】在不同年龄段,DBA应该怎样规划自己的职业发展?
墨天轮编辑部
1324次阅读
2025-03-13 11:40:53
MySQL8.0统计信息总结
闫建(Rock Yan)
495次阅读
2025-03-17 16:04:03
2月“墨力原创作者计划”获奖名单公布
墨天轮编辑部
466次阅读
2025-03-13 14:38:19
SQL优化 - explain查看SQL执行计划(一)
金同学
394次阅读
2025-03-13 16:04:22
MySQL突然崩溃?教你用gdb解剖core文件,快速锁定“元凶”!
szrsu
372次阅读
2025-03-13 00:29:43
MySQL生产实战优化(利用Index skip scan优化性能提升257倍)
chengang
330次阅读
2025-03-17 10:36:40
MySQL数据库当前和历史事务分析
听见风的声音
296次阅读
2025-04-01 08:47:17
MySQL 生产实践-Update 二级索引导致的性能问题排查
chengang
240次阅读
2025-03-28 16:28:31
一键装库脚本3分钟极速部署,传统耗时砍掉95%!
IT邦德
239次阅读
2025-03-10 07:58:44
MySQL8.0直方图功能简介
Rock Yan
233次阅读
2025-03-21 15:30:53
