【作者简介】
本人医疗行业DBA,从业7年,精通oracle底层;会文件、触发器加密的勒索恢复、asm磁盘组不能mount及各种灾难恢复,后面将利用空闲时间将自己工作中遇到的问题及整理的资料分享给更多愿意学习和提升自己的dba。
【正文】
一、磁盘头介绍
一个ASM DISK的最前面4096字节为disk header,对于ASM而言是block 0 (blkn=0)。ASM disk header描述了该ASM disk和diskgroup的属性,通过对现有disk header的加载,ASM实例可以知道这个diskgroup的整体信息。
ASM磁盘头在不同版本下备份情况是不一样的,对于对于10.2 到11.1.0.6的ASM,备份通常使用dd,kfed方式定期备份;11.2版本我们在AU1倒数第二个块上又有一份冗余,当出现问题后可以使用该块来修复磁盘头,在12c后整个AU 0都被完整的复制到了AU11,也就是说出现问题后可以通过两个备份来恢复,如果这些备份都无效,我们甚至可以重建磁盘头,信息来源于磁盘目录、asm alert日志。。。
本文将从以下几个方面来进行介绍:
1)磁盘头信息解析
2)磁盘头不同版本备份方式
3)当出现问题,备份无用的情况下,手工构建磁盘头应该修改哪些值才能将磁盘组mount起来
二、磁盘头信息解析
下面用kfed来读取disk header:
[root@hisdb01 ~]# kfed read dev/asmdata1|grep kfbh.type
kfbh.type: 1 ; 0x002: KFBTYP_DISKHEAD
当使用kfed时,不指定AU,默认就是读取AU 0,BLOCK 0 (asm 中block编号是从0开始的),如果指定AU 0 ,BLOCK 0也是和上面得到同样的结果:
[root@hisdb01 ~]# kfed read dev/asmdata1 aun=0 blkn=0|grep kfbh.type
kfbh.type: 1 ; 0x002: KFBTYP_DISKHEAD


下面的信息是在同一个diskgroup中的所有disk的header上均会复制一份的:
Disk group name and creation timestamp
Physical sector size of all disks in the disk group
Allocation unit size
Metadata block size
Software version compatibility
Default redundancy
Mount timestamp
下面的信息是每一个asm disk独有的:
ASM disk name (not OS path name)
Disk number within disk group
Failure group name
Disk size in allocation units
三、磁盘头元数据校验
我们可以使用kfed find命令校验AU[0]中所有块的元数据类型是否正常。如果出现非以下结果的块,说明ASM元数据有所损坏。
[root@hisdb01 ~]# kfed find dev/asmdata1 aun=0
Block 0 has type 1
Block 1 has type 2
Block 2 has type 3
...
Block 254 has type 3
Block 255 has type 3
注:以上只是检验元数据块的类型是否正常,如果元数据块中内容有误,目前还是没有办法可以直接检查出来。
四、磁盘头备份和恢复
ASM磁盘头的重要性无庸置疑,通过观察ASM磁盘头各项含义后,我们发现ASM磁盘头并不类似其他ASM File一样经常变化修改,这使得对ASM磁盘头的备份具体有行性。
4.1 对于10.2 到11.1.0.6的ASM,磁盘头的备份方法就是dd或者kfed。
1)dd 备份恢复
备份:
for i in ` ls dev/asm*`
do
e=`echo $i|cut -d "/" -f3`
dd if=$i of=/home/grid/${e}_$(date +"%Y-%m-%d") bs=4096 count=1
done
dd if=/dev/asmdata1 of=/home/grid/asmdata1_$(date +"%Y-%m-%d") bs=4096 count=1
dd if=/dev/asmdata2 of=/home/grid/asmdata2_$(date +"%Y-%m-%d") bs=4096 count=1
模拟损坏:
dd if=/dev/zero of=/dev/asmdata1 bs=4096 count=1 conv=notrunc
dd if=/dev/zero of=/dev/asmdata2 bs=4096 count=1 conv=notrunc
此时再挂载磁盘组报错:
SQL> alter diskgroup data mount;
alter diskgroup data mount
*
ERROR at line 1:
ORA-15032: not all alterations performed
ORA-15017: diskgroup "DATA" cannot be mounted
ORA-15040: diskgroup is incomplete
校验磁盘头:
[root@hisdb01 ~]# kfed read dev/asmdata1 aun=0 blkn=0
kfbh.endian: 0 ; 0x000: 0x00
kfbh.hard: 0 ; 0x001: 0x00
kfbh.type: 0 ; 0x002: KFBTYP_INVALID
kfbh.datfmt: 0 ; 0x003: 0x00
kfbh.block.blk: 0 ; 0x004: blk=0
kfbh.block.obj: 0 ; 0x008: file=0
kfbh.check: 0 ; 0x00c: 0x00000000
kfbh.fcn.base: 0 ; 0x010: 0x00000000
kfbh.fcn.wrap: 0 ; 0x014: 0x00000000
kfbh.spare1: 0 ; 0x018: 0x00000000
kfbh.spare2: 0 ; 0x01c: 0x00000000
7FC75612E400 00000000 00000000 00000000 00000000 [................]
Repeat 255 times
KFED-00322: file not found; arguments: [kfbtTraverseBlock] [Invalid OSM block type] [] [0]
kfed输出全是0,说明asm磁盘头被覆盖或者损坏了;
for i in ` ls dev/asm*`
do
echo $i
kfed read $i aun=0 blkn=0|grep kfbh.type
done
使用前面的dd备份恢复:
[root@hisdb01 ~]# dd if=/home/grid/asmdata1_2023-02-07 of=/dev/asmdata1 bs=4096 count=1 conv=notrunc
[root@hisdb01 ~]# dd if=/home/grid/asmdata2_2023-02-07 of=/dev/asmdata2 bs=4096 count=1 conv=notrunc
重新挂载磁盘:
SQL> alter diskgroup data mount;
Diskgroup altered.
2)kfed 备份恢复
[root@hisdb01 ~]# kfed read dev/asmdata1 text=/home/grid/asmdata1.txt
[root@hisdb01 ~]# kfed write dev/asmdata1 CHKSUM=YES aus=1048576 text=/home/grid/asmdata1.txt
注意:如果既无dd备份业务kfed备份,则只能手动修改磁盘头,后面有详细介绍;
[root@hisdb01 ~]# kfed repair dev/asmdata1 aus=1048576
4.2 11.1.0.7之后
1)自动备份
从10.2.0.5、11.1.0.7、11.2之后ASM磁盘头会自动备份到AU#1的倒数第二个block。对于AU size是1MB的DISKGROUP,每个AU包括block数量=1024KB/4KB=256个,因此备份信息位于AU#1的第254号block(block从0号开始)。当然可以计算得到:
for i in ` ls dev/asm*`
do
ausize=`kfed read $i|grep ausize|tr -s ' '|cut -d ' ' -f2`
blksize=`kfed read $i|grep blksize|tr -s ' '|cut -d ' ' -f2`
let n=$ausize/$blksize-2
echo -n $i";"
echo $ausize $n
done
/dev/asmdata1;1048576 254
/dev/asmdata10;4194304 1022
/dev/asmdata11;4194304 1022
/dev/asmdata2;1048576 254
/dev/asmdata6;4194304 1022
/dev/asmdata7;4194304 1022
/dev/asmdata8;4194304 1022
/dev/asmdata9;4194304 1022
/dev/asmdisk1;4194304 1022
/dev/asmdisk2;4194304 1022
/dev/asmdisk3;4194304 1022
/dev/asmdisk4;1048576 254
/dev/asmdisk5;1048576 254
/dev/asmdisk6;1048576 254

2)手工恢复
++破坏
[root@hisdb01 ~]# dd if=/dev/zero of=/dev/asmdata1 bs=4096 count=1 conv=notrunc
[root@hisdb01 ~]# dd if=/dev/zero of=/dev/asmdata2 bs=4096 count=1 conv=notrunc
++挂盘
SQL> alter diskgroup data dismount force;
Diskgroup altered.
SQL> alter diskgroup data mount;
alter diskgroup data mount
*
ERROR at line 1:
ORA-15032: not all alterations performed
ORA-15017: diskgroup "DATA" cannot be mounted
ORA-15040: diskgroup is incomplete
++修复磁盘头
[root@hisdb01 ~]# kfed repair dev/asmdata1 aus=1048576
[root@hisdb01 ~]# kfed repair dev/asmdata2 aus=1048576
或者
kfed read dev/asmdata1 aus=1048576 aun=1 blkn=254 > asmdata1headerbak
kfed merge dev/asmdata1 aus=1048576 aun=0 blkn=0 text=asmdata1headerbak
++挂盘
SQL> alter diskgroup data mount;
Diskgroup altered.
4.3 手工重构磁盘头信息
针对10g和11gR1,由于ASM没有自动备份磁盘头。在某些磁盘维护操作时很容易误删除磁盘头数据,此时就只能通过手工重构磁盘头。
重构磁盘头主要需要修改下列值:
kfbh.endian
kfbh.block.obj
kfdhdb.driver.provstr
kfdhdb.dsknum
kfdhdb.grptyp
kfdhdb.dskname
kfdhdb.grpname
kfdhdb.fgname
kfdhdb.crestmp.hi
kfdhdb.crestmp.lo
kfdhdb.mntstmp.hi
kfdhdb.mntstmp.lo
kfdhdb.dsksize
kfdhdb.fstlocn
kfdhdb.altlocn
kfdhdb.f1b1locn
kfdhdb.grpstmp.hi
kfdhdb.grpstmp.lo
4.3.1 手工构建磁盘头(磁盘组中包含了多个磁盘,其中一个磁盘被破坏)
set line 200
col diskgroup_name for a15
col path for a40
select a.name diskgroup_name,a.type,a.allocation_unit_size/1024/1024 unit_mb,a.voting_files,b.name disk_name,b.path from v$asm_diskgroup a,v$asm_disk b where a.group_number=b.group_number;

--通过上图,可以看到,磁盘组data包含了两块磁盘,/dev/asmdisk4,/dev/asmdisk5
--下面把磁盘组data的/dev/asmdisk5破坏掉
dd if=/dev/zero of=/dev/asmdisk5 bs=4096 count=1 conv=notrunc


--再次查看视图,发现只有磁盘组和磁盘的关系在,其余值在没有mount情况下都是看不到的;

[root@hisdb01 ~]# find u01 -name alert*.log
/u01/app/grid/diag/asm/+asm/+ASM1/trace/alert_+ASM1.log
/u01/app/grid/diag/asmtool/user_grid/host_1152405500_80/trace/alert_+ASM1.log
/u01/app/11.2.0/grid/log/hisdb01/alerthisdb01.log
/u01/app/oracle/diag/rdbms/orcl/orcl1/trace/alert_orcl1.log
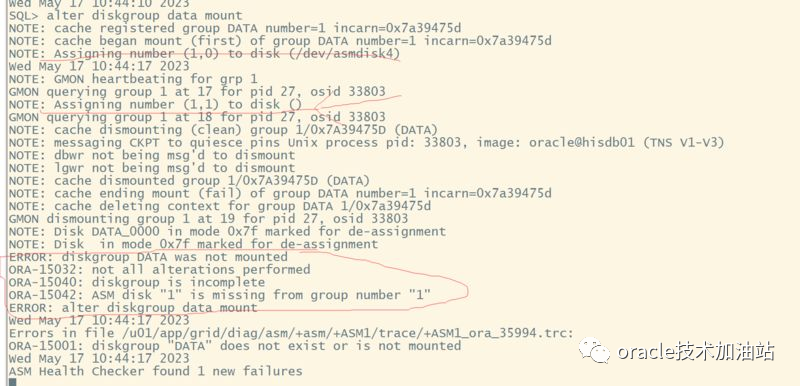
--查看asm alert日志,发现data磁盘组mount时候,只发现了、dev/asmdisk4,导致mount失败
[root@hisdb01 ~]# kfed find dev/asmdisk4 aus=1048576
Block 0 has type 1
Block 1 has type 2
Block 2 has type 3
...
[root@hisdb01 ~]# kfed find dev/asmdisk5 aus=1048576
Block 1 has type 2
Block 2 has type 3
...
通过find检查,发现block 0 没有了,说明这个块有问题;
通过kfed读取,同样报错
[root@hisdb01 ~]# kfed read /dev/asmdisk5 aun=0 blkn=0 aus=1048576|more

查看data磁盘组中的/dev/asmdisk磁盘还是正常的;
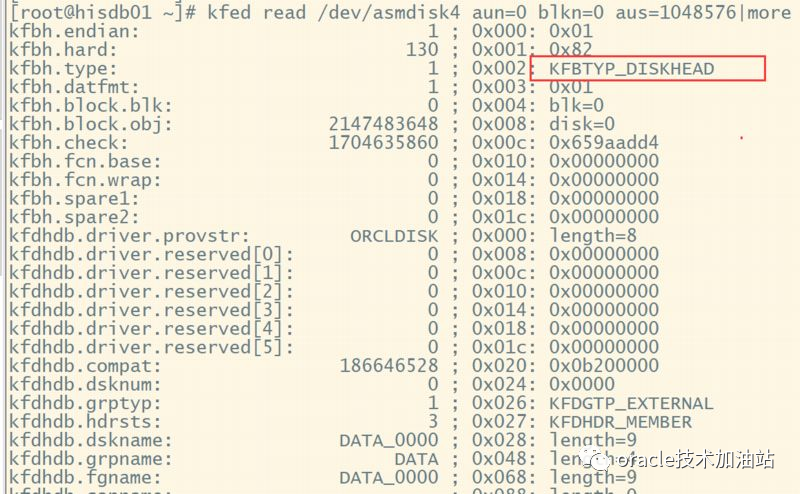
[root@hisdb01 ~]# kfed read /dev/asmdisk4 aun=0 blkn=0 aus=1048576|more
所以这个时候你会想到,用好的磁盘头去恢复坏的磁盘头,也就是通过/dev/asmdisk4的磁盘头修复/dev/asmdisk5的磁盘头
那么需要哪些信息才能把磁盘头恢复正常呢?


--搜索alert日志看能否找到部分信息
[root@hisdb01~]# cat /u01/app/grid/diag/asm/+asm/+ASM1/trace/alert_+ASM1.log|egrep -i "/dev/asmdisk5" -A 5
什么是disk directory目录,如果获得?
diskgroup中由哪几个asm disk组成,核心就是要找到asm disk directory。disk directory的类型为KFBTYP_DISKDIR。该类型block记录了一个diskgroup中所有的asm disk信息,包括disk的编号、名称、创建时间和容量等
经过多次测试,发现disk directory 只在同一个磁盘组中的某个盘上面,比如我的DATA磁盘组包含了/dev/asmdisk4和/dev/asmdisk5磁盘,disk directory 目录在/dev/asmdisk5,disk directory会包含磁盘组所有磁盘的信息,可以通过如下的脚本获得(如果包含多个磁盘组,可以把磁盘循环把磁盘名字带进去,找到disk directory 在哪个目录),经过测试DATA磁盘组在/dev/asmdisk5上面。
或者先通过0号磁盘的文件目录定位
[root@hisdb01 ~]# kfed read /dev/asmdisk4 aun=0 blkn=0 aus=1048576|grep f1b
kfdhdb.f1b1locn: 2 ; 0x0d4: 0x00000002
[root@hisdb01 ~]# kfed read /dev/asmdisk4 aun=2 blkn=2 aus=1048576|egrep "block|disk|au"|egrep -v "65535|4294967295"
kfbh.block.blk: 2 ; 0x004: blk=2
kfbh.block.obj: 1 ; 0x008: file=1
kfffde[0].xptr.au: 2 ; 0x4a0: 0x00000002
kfffde[0].xptr.disk: 1 ; 0x4a4: 0x0001
--第一个for循环au,前20个
--第二个for循环blkn,如果是1M的au,0-255,如果是4M的au,0-1023,根据实际情况调整
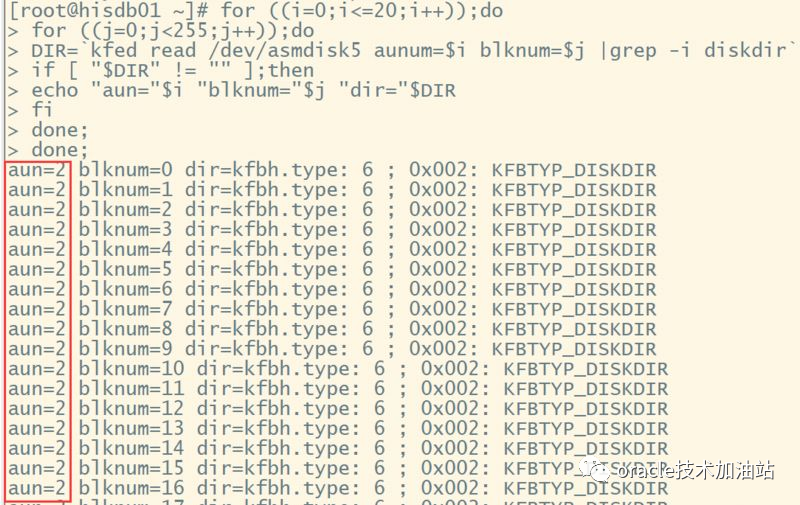
for ((i=0;i<=20;i++));do
for ((j=0;j<255;j++));do
DIR=`kfed read /dev/asmdisk5 aunum=$i blknum=$j aus=1048576|grep -i diskdir`
if [ "$DIR" != "" ];then
echo "aun="$i "blknum="$j "dir="$DIR
fi
done;
done;
...

可以可能到,DISK directory 在/dev/asmdisk5上面,使用kfed read /dev/asmdisk5 aun=2
--每个磁盘组的磁盘只包含自己磁盘组和磁盘的磁盘目录信息;
for ((j=0;j<255;j++));do
DIR=`kfed read /dev/asmdisk5 aun=2 blknum=$j |grep dskname|grep -v "length=0"|tr -d " "|sed "s/.dskname:/=/"|cut -d";" -f 1|paste -d ";" - -`
if [ "$DIR" != "" ];then
echo "blknum="$j "dir="$DIR
fi
done;

--通过上面的扫描可以发现磁盘目录的信息都在块1,其中kfddde[0] 表示的是data 0号磁盘的信息,同理kfddde[1] 表示的是data 1号磁盘的信息,怎么判断我们这个磁盘是data 0还是data 1呢?
--实际上再查看一下正常的磁盘头过滤出磁盘号就能判断出来了;kfed read /dev/asmdisk4 aun=0 blkn=0 aus=1048576|egrep -i "dskname|dsknum"

--通过实际对比,我们知道了,要从实际磁盘目录中拿数据的位置:/dev/asmdisk5 aun=2 blkn=0 的 kfddde[1] 结构体中;
[root@hisdb01 ~]# kfed read /dev/asmdisk5 aun=2 blkn=0 aus=1048576|egrep -i "kfbh.type|kfddde\[1\]"
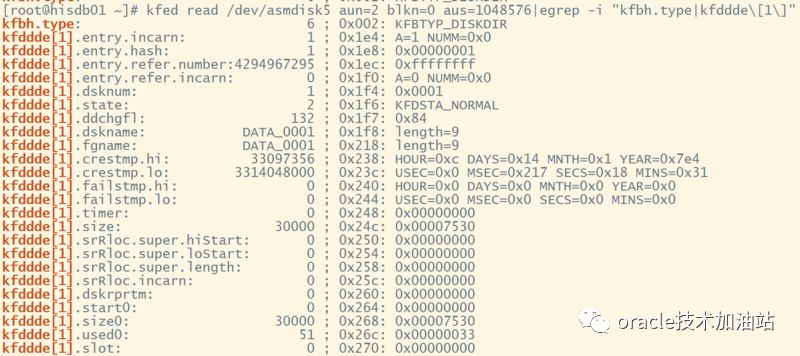
--实际修改值:
[root@hisdb01 ~]# vi ok.txt

--最后通过merge方式,把上面的值,合并到头部信息
[root@hisdb01 ~]# kfed merge /dev/asmdisk5 text=ok.txt
--
SQL> alter diskgroup data mount;
alter diskgroup data mount
*
ERROR at line 1:
ORA-00600: internal error code, arguments: [kfcMount35], [2], [1], [], [], [], [], [], [], [], [], []
[root@hisdb01 ~]# kfed read /dev/asmdisk5 aun=1 blkn=254 > 254.txt
[root@hisdb01 ~]# kfed read /dev/asmdisk5 aun=0 blkn=0 > 0.txt
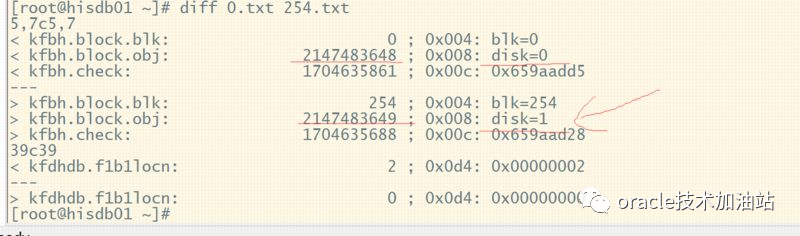
--通过对比,发现还有一个值需要修改,kfbh.block.obj,将2147483648 ; 0x008: disk=0 修改为:2147483649 ; 0x008: disk=1
[root@hisdb01 ~]# vi ok.txt
[root@hisdb01 ~]# kfed merge /dev/asmdisk5 text=ok.txt
--mount还是报错
SQL> alter diskgroup data mount;
alter diskgroup data mount
*
ERROR at line 1:
ORA-00600: internal error code, arguments: [kfcMount35], [2], [1], [], [], [], [], [], [], [], [], []
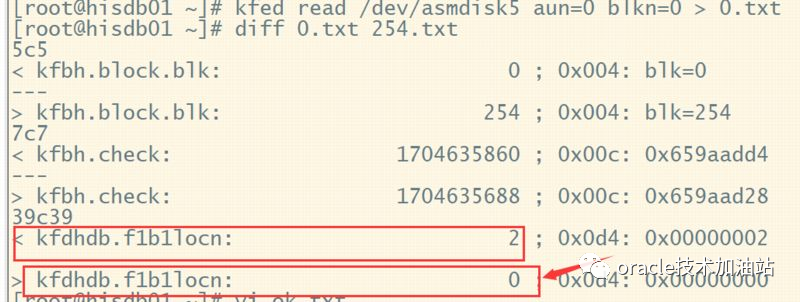
--通过对比,发现还要修改f1b1的值为0才行;
4.3.2 手工构建磁盘头(磁盘组中只有1个磁盘,其中磁盘头被破坏)
set line 200
col diskgroup_name for a15
col path for a40
select a.name diskgroup_name,a.type,a.allocation_unit_size/1024/1024 unit_mb,a.voting_files,b.name disk_name,b.path from v$asm_diskgroup a,v$asm_disk b where a.group_number=b.group_number;

--通过上图,可以看到,磁盘组fra包含了1块磁盘,/dev/asmdisk6
--下面把磁盘组fra的/dev/asmdisk6破坏掉
dd if=/dev/zero of=/dev/asmdisk6 bs=4096 count=1 conv=notrunc
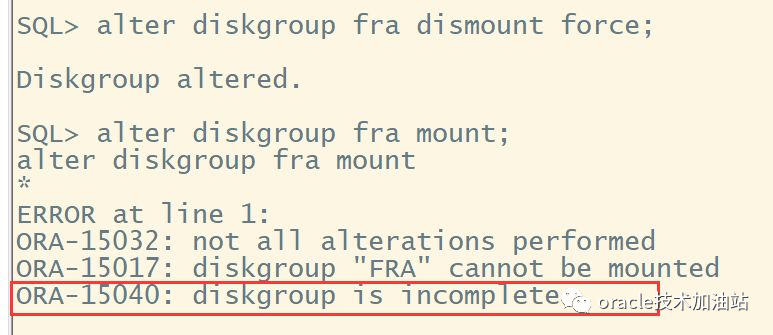
[root@hisdb01 ~]# kfed find /dev/asmdisk6 aus=1048576
Block 1 has type 2
Block 2 has type 3
Block 2 has type 255
通过find检查,发现block 0 没有了,说明这个块有问题;
通过kfed读取,同样报错
[root@hisdb01 ~]# kfed read /dev/asmdisk6 aun=0 blkn=0 aus=1048576|more

[root@hisdb01 ~]# find /u01 -name alert*.log
/u01/app/grid/diag/asm/+asm/+ASM1/trace/alert_+ASM1.log
/u01/app/grid/diag/asmtool/user_grid/host_1152405500_80/trace/alert_+ASM1.log
/u01/app/11.2.0/grid/log/hisdb01/alerthisdb01.log
/u01/app/oracle/diag/rdbms/orcl/orcl1/trace/alert_orcl1.log
--文件目录定位
--第一个for循环au,前20个
--第二个for循环blkn,如果是1M的au,0-255,如果是4M的au,0-1023,根据实际情况调整
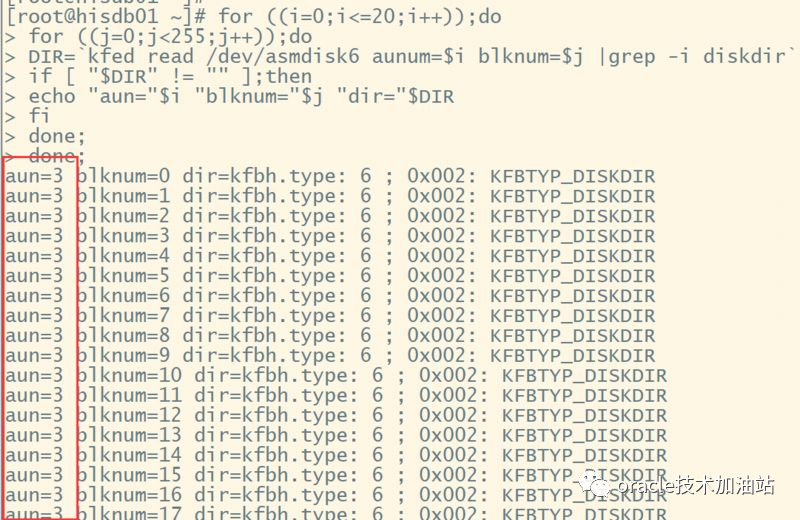
for ((i=0;i<=20;i++));do
for ((j=0;j<255;j++));do
DIR=`kfed read /dev/asmdisk6 aunum=$i blknum=$j aus=1048576|grep -i diskdir`
if [ "$DIR" != "" ];then
echo "aun="$i "blknum="$j "dir="$DIR
fi
done;
done;
...

可以可能到,DISK directory 在/dev/asmdisk6上面,使用kfed read /dev/asmdisk6 aun=3 (因为磁盘只有一个,所以磁盘目录信息必然是在这个磁盘里面)
--每个磁盘组的磁盘只包含自己磁盘组和磁盘的磁盘目录信息;
--这里可以看到,只有一个磁盘
for ((j=0;j<255;j++));do
DIR=`kfed read /dev/asmdisk6 aun=3 blknum=$j |grep dskname|grep -v "length=0"|tr -d " "|sed "s/.dskname:/=/"|cut -d";" -f 1|paste -d ";" - -`
if [ "$DIR" != "" ];then
echo "blknum="$j "dir="$DIR
fi
done;

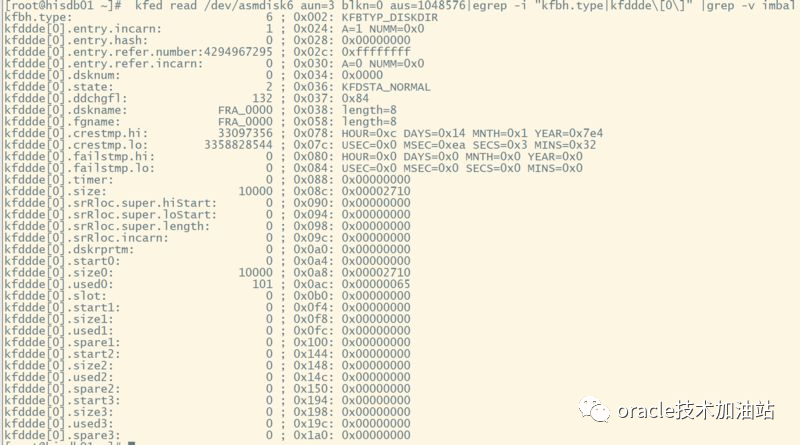
--通过实际对比,我们知道了,要从实际磁盘目录中拿数据的位置:/dev/asmdisk6 aun=3 blkn=0 的 kfddde[0] 结构体中;
[root@hisdb01 ~]# kfed read /dev/asmdisk6 aun=3 blkn=0 aus=1048576|egrep -i "kfbh.type|kfddde\[0\]" |grep -v imbal
--随便找一个好的其它磁盘组的文件头,然后拿来当作模板修改为现在磁盘的文件头;

[root@hisdb01 ~]# kfed read /dev/asmdisk4 aun=0 blkn=0 aus=1048576 text=ok.txt
[root@hisdb01 ~]# vi ok.txt
[root@hisdb01 ~]# kfed read /dev/asmdisk6 aun=1 blkn=254 aus=1048576 > 254.txt
[root@hisdb01 ~]# diff ok.txt 254.txt
[root@hisdb01 ~]# kfed merge /dev/asmdisk6 text=ok.txt