




导读

一、公司背景

二、业务背景与图数据库迁移
1
业务背景
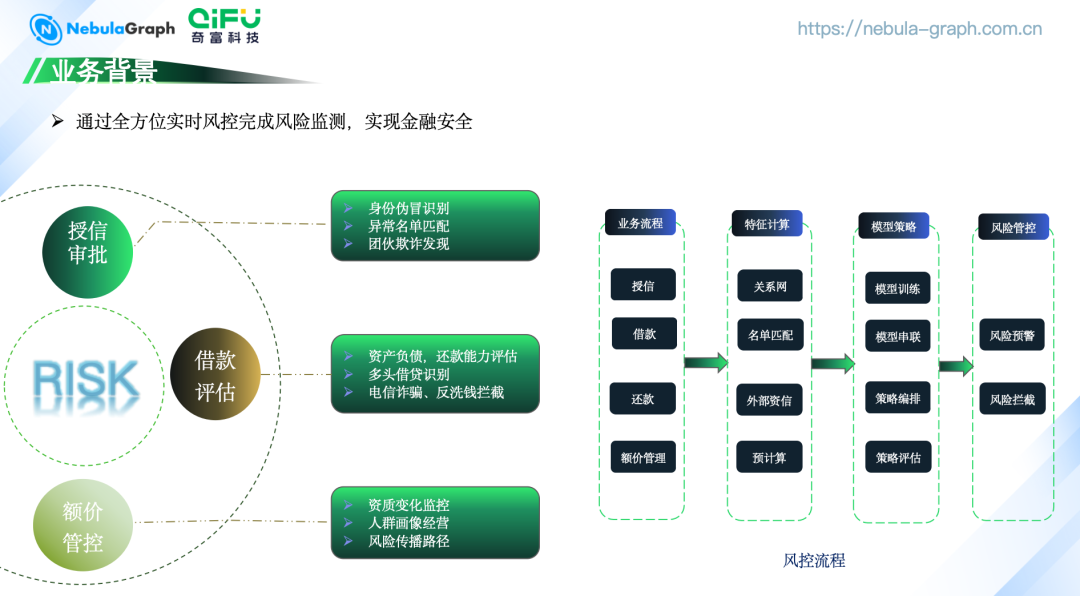
2
图数据迁移史
2017 年 6 月:使用 Neo4j, 适用于业务量较小时的轻便部署。当时使用的是非商业单机版,随着数据量的增长,单机部署模式的局限性显现:一是缺乏主备服务,二是集群部署能力受限,有单点故障的风险。 2018 年 3 月:使用 AgensGraph, 它是基于 PostgreSQL 实现一主多从架构。当业务数据量增长至 10 亿点和 60 亿边时,AgensGraph 无法满足业务需求:其数据存储是非分布式的,数据都存在一台机器上;数据量越大,查询性能越低,严重影响了查询效率。 2019 年 8 月:为解决存储能力和查询性能的痛点,更换为 JanusGraph. 它的数据存储基于 HBase, 查询基于 ES, 实现了分布式数据存储和水平扩展。使用快一年后遇到了两个主要问题:首先,作为实时风控系统,业务需要短时间内计算用户特征并将其应用于策略执行,但是 JanusGraph 在查询关系网时性能不足,导致特征计算组装缓慢,影响了业务流程。其次 JanusGraph 的查询无法下推,需要先通过 ES 索引到具体节点,再从 HBase 查询所有数据,这导致了巨大的网络传输开销。此外,当查询触及超级节点时,由于底层缺乏过滤机制,需要从 HBase 查询并加载所有相关数据到内存中进行计算和过滤。这些问题促使我们寻求更优的图数据库解决方案。 2020 年 6 月:为了解决刚提到的 IO 无法下推和超级节点的问题,我们开始寻找新的图数据库解决方案。这时候 NebulaGraph v1.0 发布,我们邀请了 NebulaGraph 的同学到奇富科技分享,了解到 NebulaGraph 是一个主从分布式的存储架构,支持存算分离和信息扩容。与 JanusGraph 相比,不仅可以大大降低我们的数据存储成本,还能解决 IO 无法下推和超级节点的问题。另外 NebulaGraph 支持我们的一些过滤条件在底层计算的时候就过滤掉,并且通过超级节点底层优化,在底层配置了一个特殊的参数,我们可以设置点关联最大的一个边,或者点的最大数量,去解决超级节点膨胀的问题。因此,我们选择了 NebulaGraph 作为金融风控业务的最佳解决方案。 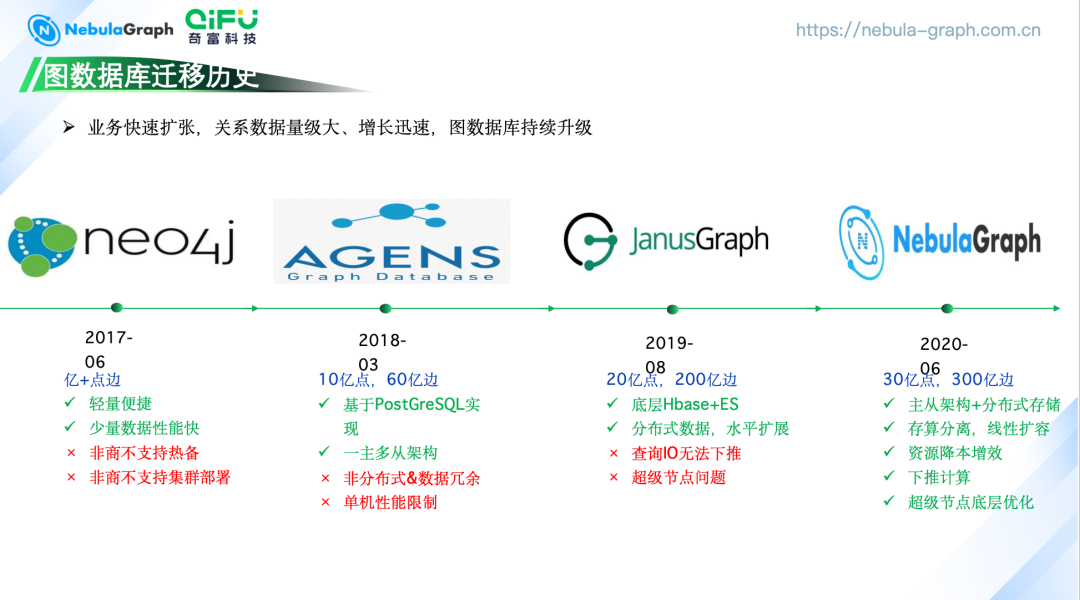
三、图平台架构
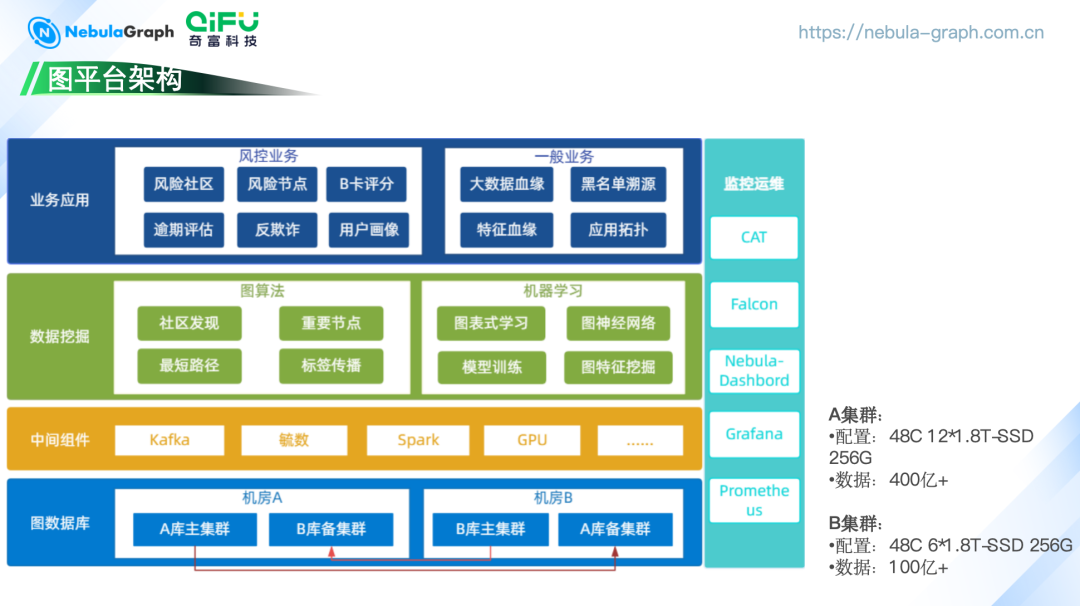
图数据库层:部署了两套 NebulaGraph 集群,分别位于机房 A 和机房 B, 实现了跨机房的高可用性。A、B 集群的数据存储量分别达到了 400 亿+ 和 100 亿+。 中间组件层:包括 Kafka、Spark、GPU 等,用于数据同步和处理。Kafka 用于主从数据同步,而 Spark 和 GPU 则用于大规模数据处理和机器学习任务。 数据挖掘层:在这一层,我们利用图算法进行数据发现、重要节点、标签传播等。另一方面,会将图数据导入到我们的大数据集群进行机器学习,如图神经网络、模型训练、图特征挖掘等。 业务应用层:利用 NebulaGraph 支持风控业务,如风险社区、风险节点、B卡评分、逾期评估、反欺诈等,也用于支持一般业务,如大数据血缘、黑名单溯源、特征血缘等。 监控运维层:使用 Prometheus、CAT、Falcon 和 Nebula-Dashboard 等工具进行监控和运维,确保实时监控系统稳定的运行。
四、NebulaGraph 的应用实践
1
反欺诈

设备关联风险:监控设备使用情况,识别多人短时间内使用同一设备进行申请的异常行为。 身份信息关联风险:检测身份信息的急剧变动,以发现潜在的身份伪冒风险。 社交关系风险:通过分析用户的社交网络,评估用户可能所处的行业,从而侧面评估其信用风险。 名单关联风险:通过用户与风险名单的关联程度,评估用户的风险概率。
爆发式传播预警拦截:在风险行为呈现爆发式传播时,及时发出预警并进行拦截。 风险人库溯源:通过图数据库的查询能力,快速追溯风险行为的源头,实现风险的精准定位。
2
图挖掘
一阶二阶关联聚合:通过分析客户的直接和间接关联,衍生出图特征指标。这种方法已经帮助公司计算出上千个图指标,这些指标被应用于 100 多个模型和策略中。然而,随着新指标的发掘,其边际收益呈现出递减的趋势。 大数据平台结合图算法:为了克服边际收益递减的问题,我们将图数据同步到 HIVE, 并利用大数据集群运行全图算法,如 PAGERANK(网页排名算法)、LOUVAIN、GAT(图注意力网络)、GNN(图神经网络)等,帮助公司发现了 92 万个风险社区和超过 100 万个风险节点。 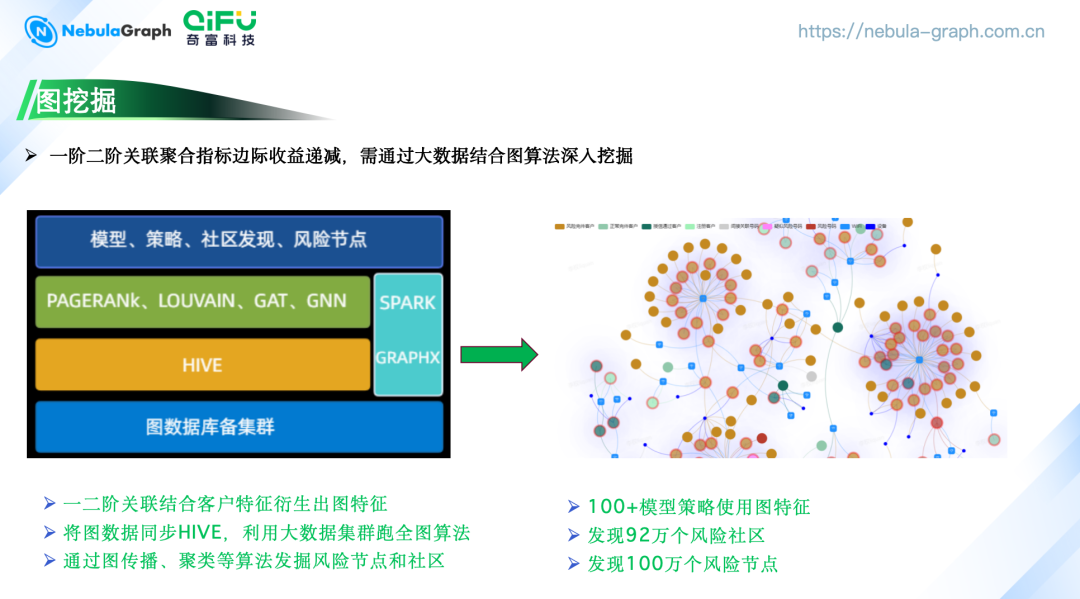
3
图+大模型

信息提取与情感分析:我们利用大模型对财报、用户经营数据、图片等非结构化数据进行信息提取,并通过持续的用户对话进行情感分析,识别用户的具体诉求。 知识图谱与图计算:通过大模型提取的关键信息,进一步对图的点边进行建模,构建了金融知识图谱。这一图谱不仅加深了大模型对业务的理解,而且通过提示词优化和语料训练,使得大模型能帮助我们快速地掌握小微企业的经营变化和行业信息背景,对业务进行全方位的深入理解。
4
特征、策略血缘
在特征管理和策略血缘方面的实践,充分利用了图数据库的天然可解释性,为风控领域提供了一种直观且高效的特征追溯和管理方法。
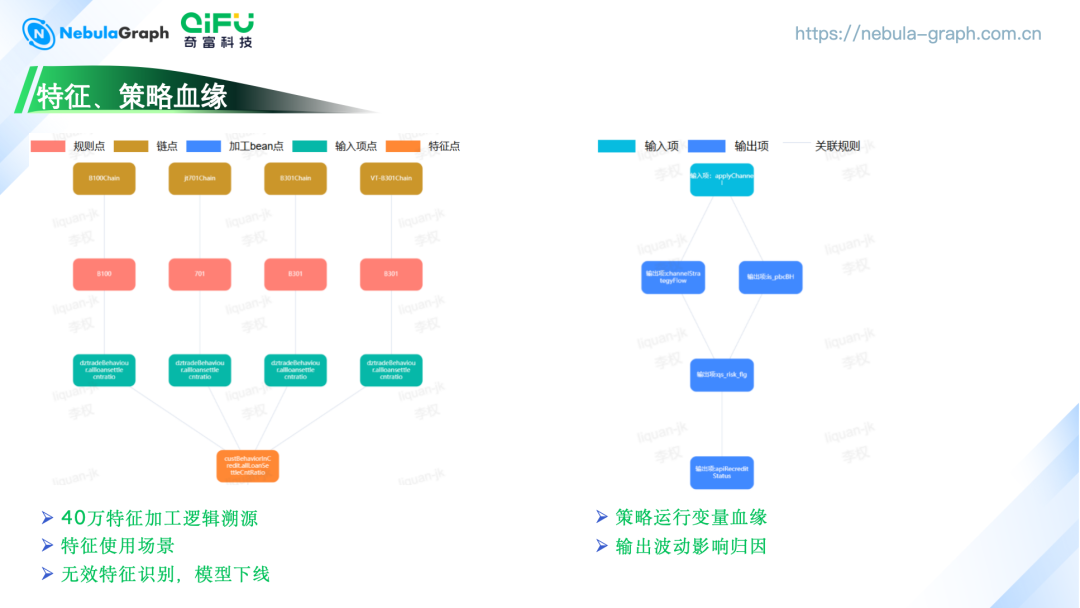
1. 特征血缘管理
特征变量管理:我们已经积累了超过 40 万个特征变量,每个特征都有明确的取数来源和加工逻辑,以及应用的业务场景。
直观表达:通过 NebulaGraph, 构建一个直观的表达方式,快速识别每个特征所属的领域和链路,这在传统关系数据库中往往需要多表关联查询,且不够直观。
无效特征管理:NebulaGraph 使得识别和管理无效或需要下线的特征变得更加有效。
2. 策略血缘分析
变量关系构建:通过图谱构建了输入变量、中间变量和最终输出变量之间的关系,这对于理解策略的内部计算和结果输出至关重要。
影响归因:当策略输出出现波动时,图谱能够快速进行影响归因分析,帮助团队迅速定位问题原因。
5
大数据血缘&应用拓扑
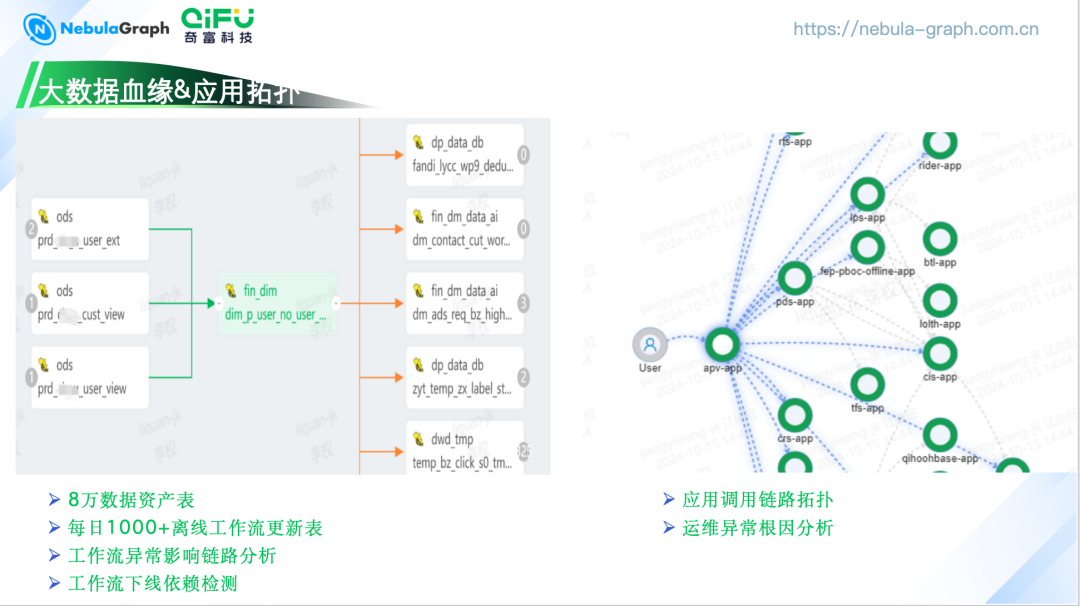
数据资产表管理:我们管理着 8 万张数据资产表,这些表通过每日 1000+ 的离线工作流进行更新和迭代。 工作流异常影响分析:当数据同步出现问题时,可以快速定位受影响的下游表和业务,实现一阶、二阶甚至多阶的链路影响分析。 工作流下线依赖检测:在调整或下线工作流时,评估其对其他工作流或业务的在影响,确保变更管理的安全性。
应用调用链路拓扑:通过 NebulaGraph 展示应用间的调用关系,帮助理解和分析应用间的交互和依赖。
运维异常根因分析:在发生运维异常时,NebulaGraph 能我们快速定位问题根源,提高故障恢复的效率。
五、未来展望
✦
如果你觉得 NebulaGraph能帮到你,或者你只是单纯支持开源精神,可以在 GitHub 上为 NebulaGraph 点个 Star!每一个 Star 都是对我们的支持和鼓励✨
https://github.com/vesoft-inc/nebula
✦
✦

扫码添加
可爱星云
技术交流
资料分享
NebulaGraph 用户案例集
案例推荐:
知识图谱案例:
苏宁基于 NebulaGraph 构建知识图谱的大规模告警收敛和根因定位实践
金融风控案例:
360数科:基于 NebulaGraph 打造智能化的金融反欺诈系统
NebulaGraph 助力金蝶征信产业图谱深挖企业关系链,实现银行批量获客
智能运维案例:
58 同城基于 NebulaGraph 一键部署运维架构的实践
苏宁基于 NebulaGraph 构建知识图谱的大规模告警收敛和根因定位实践
大数据/图平台:
OPPO:通过 NebulaGraph 建设全局图数据库平台
数据治理:
微众银行:利用 NebulaGraph 进行全局数据血缘治理的实践
安全:
