




一、数据表的排序、聚合命令、分组
1. 排序(order by):
★、使用order by子句,对查询结果进行排序。
★、order by 指定排序的列 asc(升序)/desc(降序)。
★、order by 子句一般位于select语句的结尾。
SELECT product_name,weight FROM products_info ORDER BY weight DESC;
2. 聚合命令 :
①.distinc:对某一列数据去重
语句:select distinct 列名 from 表名; -- 显示此列不重复的数据
②. count :统计总行数
count(*):包括所有列,返回表中的总行数,在统计结果的时候,不会忽略值为Null的 行数。
count(1):包括所有列,1表示一个固定值,没有实际含义,在统计结果的时候,不会 忽略列值为Null的行数,和count(*)的区别是执行效率不同。
count(列名):只包括列名指定列,返回指定列的行数,在统计结果的时候,不统计列值 为Null,即列值为Null的行数不统计在内。
count(distinct 列名):返回指定列的不重复的行数,在统计结果的时候,会忽略列值为 NULL的行数(不包括空字符和0),即列值为NULL的行数不统计在内。
count(*)、count(1)、count(列名)执行效率比较:
★. 如果列为主键,count(列名)优于count(1)
★. 如果列不为主键,count(1)优于count(列名)
★. 如果表中存在主键,count(主键列名)效率最优
★. 如果表中只有一列,则count(*)效率最优
★. 如果表中有多列,且不存在主键,则count(1)效率优于count(*)
③ MAX :最大值
④ MIN :最小值
⑤ AVG :平均值
⑥SUM :
select max(列名) from 表名;
select min(列名) from 表名;
select avg(列名) from 表名;
select sum(列名) from 表名;
- 也可以跟where子句
⑦ limit :
语法:select * from 表名 limit m,n;
★、其中m是指从哪行开始,m从0取值,0表示第一行。
★、n是指从第m+1条开始,取n条。
★、select * from 表名 limit 0,2(从第一行开始,显示两行结果)
★、如果只给定一个参数,它表示返回最大的行数目:select * from table limit 5;查询前5行
★、limit n 等价于 limit 0,n
3. 分组 GROUP BY:
★、使用group by子句对列进行分组。
★、然后还可以使用having子句过滤,having通常跟在group by后,它作用于组。不★、加having过滤:
select 列名,聚合函数 from 表名 where 子句 group by 列名;
★、加上having过滤:
select 列名,聚合函数 from 表名 where 子句 group by 列名 having 聚合函数 过滤条件;
★、注意:
使用group by后只能展示分组的列名+聚合函数结果,因为其余列已经基于分组这一 列合并。
select sum(price), count(user_id), product_id from order_info_table group by product_id having count(user_id) > 2;
二、数据表的连接查询、子查询
1. 两张表连接查询:
①、INNER JOIN(内连接) :获取两个表中字段匹配关系的行的所有信息。
语法:SELECT * FROM [表名] a INNER JOIN [表名] b ON a.[列名] = b.[列名];
例如:
SELECT * FROM user_info_table a INNER JOIN order_info_table b ON a.user_id =
b.user_id;
SELECT * FROM user_info_table a INNER JOIN order_info_table b ON a.user_id =
b.user_id WHERE b.user_id IS NULL;
②、LEFT JOIN(左连接) :获取左表所有行的信息,即使右表没有对应匹配的行的信息。右表没有匹 配的部分用NULL代替。
语法:SELECT * FROM [表名] a LEFT JOIN [表名] b ON a.[列名] = b.[列名];
SELECT * FROM products_info a LEFT JOIN suppliers_info b ON a.supplier_id =
b.supplier_id;
③、RIGHT JOIN(右连接) :与左连接相反,用于获取右表所有记录,及时左表没有对应匹配的行的 所有信息,左表没有匹配的部分用NULL代替。
语法:SELECT * FROM [表名] a RIGHT JOIN [表名] b ON a.[列名] = b.[列名];
SELECT * FROM products_info a RIGHT JOIN suppliers_info b ON a.supplier_id =
b.supplier_id;
2、子查询(嵌套查询):
嵌套在其他查询中的查询。
语句:select 列名1 from 表1 where 列名2 in (select 列名2 from 表2 where 列名3 = 某某 某);
注意:一般在子查询中,程序先运行嵌套在最内层的语句,再运行外层。因此在写子查询语 句时,可以先测试一下内层的子查询语句是否输出了想要的内容,再一层一层往外测试,增 加子查询的正确率。
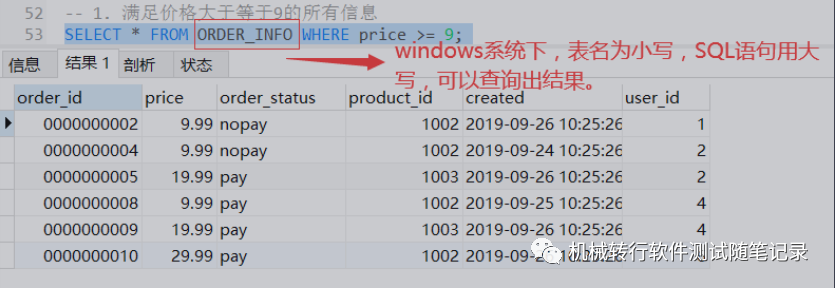
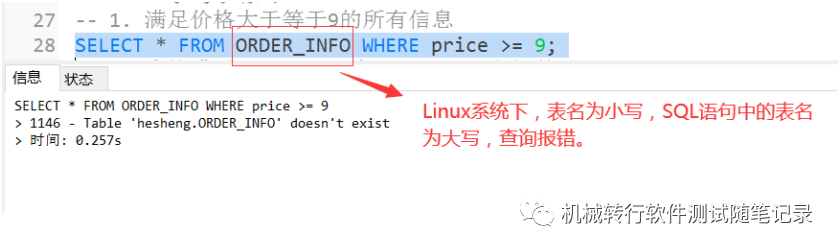
补充: 数据库名和表名在windows中是大小写不敏感的,而在大多数类型的UNIX系统中大小写是敏感 的。
如果您觉得文章还不错,请 点赞、分享、在看、收藏 一下,因为这将是我持续输出更多优质文章的最强动力!
没有关注的小伙伴,扫描下方二维码 或 点击公众号名片,获取更多精彩!如有任何问题或想技术探讨等,请扫描作者微信交流!

