




1、问题复现
昨天在微信群里有人发了一个问题,觉得不可思议,认为是MySQL的Bug,但随后题主贴出执行计划,一看执行计划就知晓问题点了,但我觉得此问题可以扩展几个重要的知识点,我用我的本地数据做了复现。
问题是下面两个SQL
-- SQL1
select profileid,sourcebillid from(select * from erp_bill_index_ext order by sourcebillid desc) as t
-- SQL2
select profileid,sourcebillid from(select * from erp_bill_index_ext order by sourcebillid desc limit 10) as t
复制在我本地,第一个SQL执行需要0.328S,第二个SQL需要5.125S

问题是为什么加了limit 10的语句反而还要慢15倍左右,这个问题第一眼看,是觉得有点违反常理。
2、问题分析
第一个反映就是需要看执行计划


通用对比执行计划,可以获得两个重要的信息
1、第一个SQL 优化器消除了派生表
2、第一个SQL 走的是索引扫描,且是索引覆盖
看到计划,估计大家都已知晓问题,并有了解决方案
3、扩展知识点
我们来扩展一些其它知识
a.如何看优化后的语句
执行explain后,执行show warnings;
我们来看SQL1优化后的样子

SQL1优化后的语句变成了
select profileid,sourcebillid from erp_bill_index_ext order by sourcebillid desc
复制在这个例子中,派生表被优化掉了,性能有较大提升,但也有的SQL派生表被优化掉了,性能下降的很历害,那我们如何控制派生表能不能被干掉呢?
b.如何控制派生表要不要和外层合并
派生表优化官方文档
有一段文章
It is possible to disable merging by using in the subquery any constructs that prevent merging, although these are not as explicit in their effect on materialization. Constructs that prevent merging are the same for derived tables, common table expressions, and view references:
Aggregate functions or window functions (SUM(), MIN(), MAX(), COUNT(), and so forth)
DISTINCT
GROUP BY
HAVING
LIMIT
UNION or UNION ALL
Subqueries in the select list
Assignments to user variables
References only to literal values (in this case, there is no underlying table)
1、当子查询包含上述语句的时候,就不能被合并,如本例中的SQL2因为子查询有了limit所以不能合并优化
所以当你想被合并或不想合并都可以通过增加或减少上述子句来控制
比如本例中被合并的SQL1 只需要稍动一点手脚即可阻止合并,增加一个用户变量在语句中即可
select profileid,sourcebillid from(select *,@i:=0 from erp_bill_index_ext order by sourcebillid desc) as t order by profileid;
复制
2、通过hint来控制
no_merge
select /*+no_merge(t)*/
profileid,sourcebillid from(select * from erp_bill_index_ext order by sourcebillid desc) as t order by profileid;
复制
derived_merge
SET @@optimizer_switch='derived_merge =off';
explain
select
profileid,sourcebillid from(select * from erp_bill_index_ext order by sourcebillid desc) as t ;
复制
但我推荐使用set_var模式,让影响变更小,只影响当前SQL
explain
select /*+set_var(optimizer_switch='derived_merge =off')*/
profileid,sourcebillid from(select * from erp_bill_index_ext order by sourcebillid desc) as t ;
复制
c.全面禁止开发使用*
这个例子中有一个特别有意思的点:即使这位研发人员不会任何SQL优化,只要遵守不使用* 也能得到最佳结果
我们来看看刚才慢15倍的SQL2,是因为将limit 放到派生表中的原因吗? 不是,是因为子查询中用到了* 我们直接去掉*看看结果
select
profileid,sourcebillid from(select profileid,sourcebillid from erp_bill_index_ext order by sourcebillid desc limit 10) as t
复制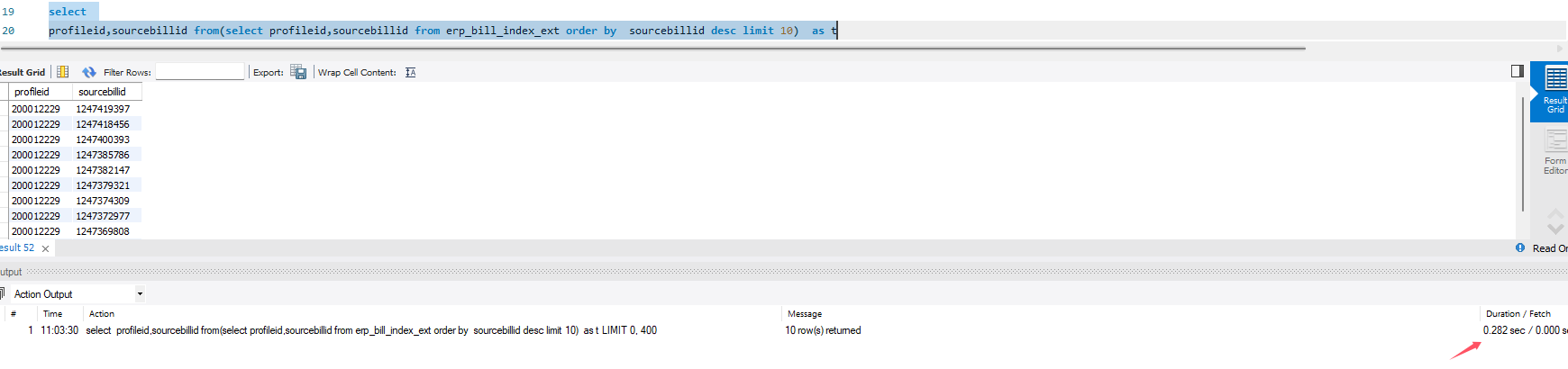
执行结果0.282S 比刚才的SQL1还要快
d.利用索引扫描与索引覆盖最后一张底牌
我们在优化SQL过程中,常常因为某些SB需求不能减少扫描行数,不能消除排序,比如产品就是我就是要查所有日期的交易记录,不限定查询时间,且还要支持按金额大小排序,还要有支付金额合计
那我们写的SQL 大概是这样的
select userid,paytotal,paydate from paylist where paydate >=xx and paydate <=xx
order by paytotal desc
复制上述SQL需求不变那么将很难减少行数,取消排序
如果paylist由于设计原因,又是一个较宽的表 那么就只有建一个paydate,userid,paytotal的组合索引,即使用户选的时间跨度很大最差也能让整个SQL走索引扫描并索引覆盖
如何建立一个好的组合索引请看我的另一篇文章MySQL联合索引最佳实践
4、解决方案
通过看执行计划,此SQL1能得到很好的性能提升,并不是合并了派生表,而是因为合并了派生表,刚好按语义消除了全表扫描。走了索引扫描且索引覆盖
那我们子查询中也做到索引扫描且索引覆盖性能就能达到最优
select profileid,sourcebillid from(select profileid,sourcebillid from erp_bill_index_ext order by sourcebillid desc limit 10) as t
复制

文章被以下合辑收录
评论

 0 点赞
0 点赞



