





点击蓝字关注我们
引言
1.1 背景介绍
Elasticsearch是一款强大的开源搜索引擎,广泛应用于全文搜索、日志分析等领域。S3(Simple Storage Service)是亚马逊云计算服务(AWS)提供的一种对象存储服务。使用Elasticsearch S3插件可以将数据快照存储到S3存储桶中,实现数据备份和扩展。本文将详细介绍Elasticsearch的7.10.2版本在使用S3插件进行快照数据迁移的步骤及遇到的已知问题的解决方法。
1.2 Elasticsearch 与 S3 的关系
Elasticsearch通过S3插件与S3存储桶进行交互,将数据快照存储到S3中。这种方案充分利用了S3的高可靠性、可扩展性和低成本优势,同时保持了Elasticsearch的高性能特点。
1.3 快照数据迁移的意义
快照数据迁移有助于实现数据备份、跨地域迁移、集群扩展等功能,提高数据的安全性和可靠性。
Elasticsearch S3 插件概述
2.1 S3 插件的安装与配置
①.关闭Elasticsearch集群
②.下载插件
https://artifacts.elastic.co/downloads/elasticsearch-plugins/repository-s3/repository-s3-7.10.2.zip
③.安装插件
.bin/elasticsearch-plugin install file:///opt/repository-s3-7.10.2.zip复制
④.卸载插件
sudo bin/elasticsearch-plugin remove repository-s3复制
⑤.启动Elasticsearch集群
⑥.验证插件安装情况
GET _cat/plugins复制
快照数据迁移步骤
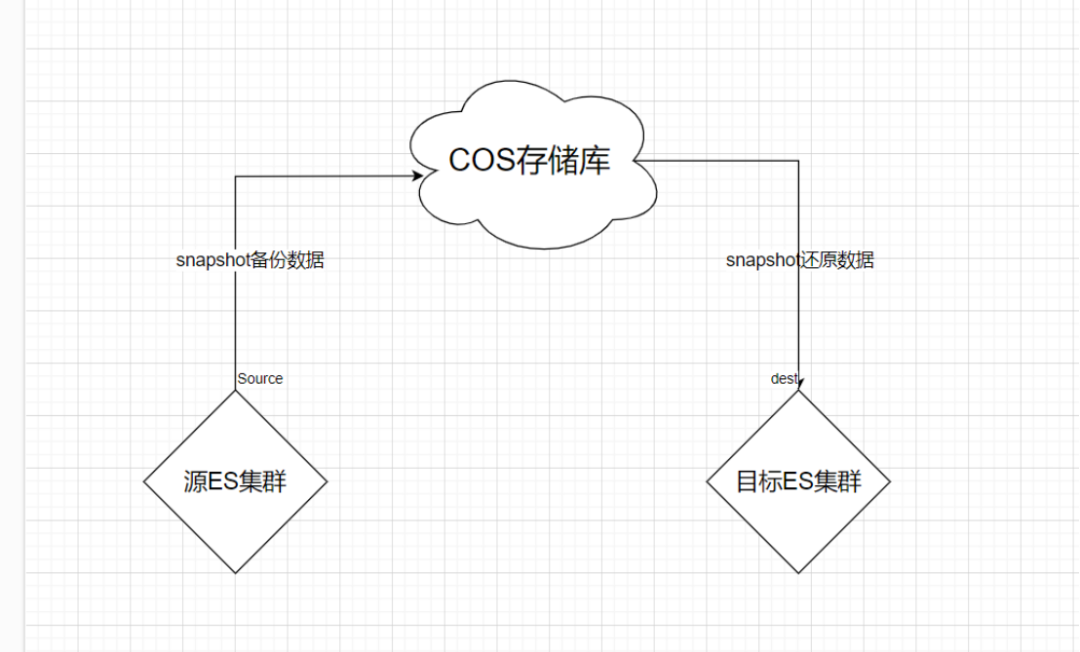
3.1 准备工作
3.1.1 创建 S3 桶:
在AWS控制台创建一个S3桶,用于存储Elasticsearch快照。
提前准备好cos存储库和bukect
"keys": [{ "user": "xxxxx","access_key": "xxxxxx","secret_key": "xxxxxx"}]bucket:xxxxxx复制
3.1.2 配置 Elasticsearch S3 插件:
在Elasticsearch集群中,配置S3插件的访问参数,如Access Key、Secret Key和S3桶地址等。
#ACCESS-KEYbin/elasticsearch-keystore add s3.client.default.access_key#SECRET-KEYbin/elasticsearch-keystore add s3.client.default.secret_key复制
注意:上述命令中的default,可以自定义名称。例如:bin/elasticsearch-keystore add s3.client.ceph-test.secret_key
请特别注意这个可自定义的default,下面仓库注册步骤中需要用到这个设置值。
3.1.3 确保Elasticsearch集群状态正常:
检查集群的健康状态,确保所有节点运行正常。
GET _cluster/healthGET _cat/health复制
3.2 创建快照
3.2.1 源集群注册存储库:
通过Kibana或Cerebro等工具进入/链接Elasticsearch集群(建议Kibana与cerebro结合使用)。
注册仓库,仓库名称可自定义(目标集群注册时需要使用相同的配置)。
PUT _snapshot/my_repository{"type": "s3","settings": {"access_key": "xxxxxxxxxxxxx","secret_key": "xxxxxxxxxxxxx","endpoint": "ip:port", # 访问cos服务的ip:port或者http/http地址"bucket": "my_repository", # 此处的bucket是在ceph中已存在的"base_path": "my_repository", # 此处的base_path可以自行设置,同一个桶中有多个路径."compress": true, #当设置为true时,元数据文件以压缩格式存储。此设置不影响默认情况下已压缩的索引文件。默认为false。"chunk_size": "200m", #如果需要,可以在快照过程中将大文件分解为块。将块大小指定为值和单位,例如:1GB、10MB、5KB、500B。默认为1GB。"max_restore_bytes_per_sec": "1024mb", # 每个节点的瓶颈恢复率。默认为无限制。请注意,恢复也会通过恢复设置进行限制。"max_snapshot_bytes_per_sec": "1024mb" # 每个节点的瓶颈快照速率。默认为每秒40mb。}}复制
3.2.2 源集群创建快照任务:
使用Elasticsearch的snapshot API创建快照任务,包括选择索引、设置快照名称等。
备份所有索引数据。
PUT _snapshot/my_repository/my_snapshot_all_1{"indices": "*","ignore_unavailable": true, #是否忽略不可用的快照,默认为false,这意味着抛出SnapshotMissingException"include_global_state": false #设置为false,可以防止将集群全局状态存储为快照的一部分。}复制
备份部分数据。
PUT _snapshot/my_repository/my_snapshot_2{"indices": "index_1,index_2,index_3","ignore_unavailable": true, #是否忽略不可用的快照,默认为false,这意味着抛出SnapshotMissingException"include_global_state": false #设置为false,可以防止将集群全局状态存储为快照的一部分。}复制
使用Cerebro简化操作
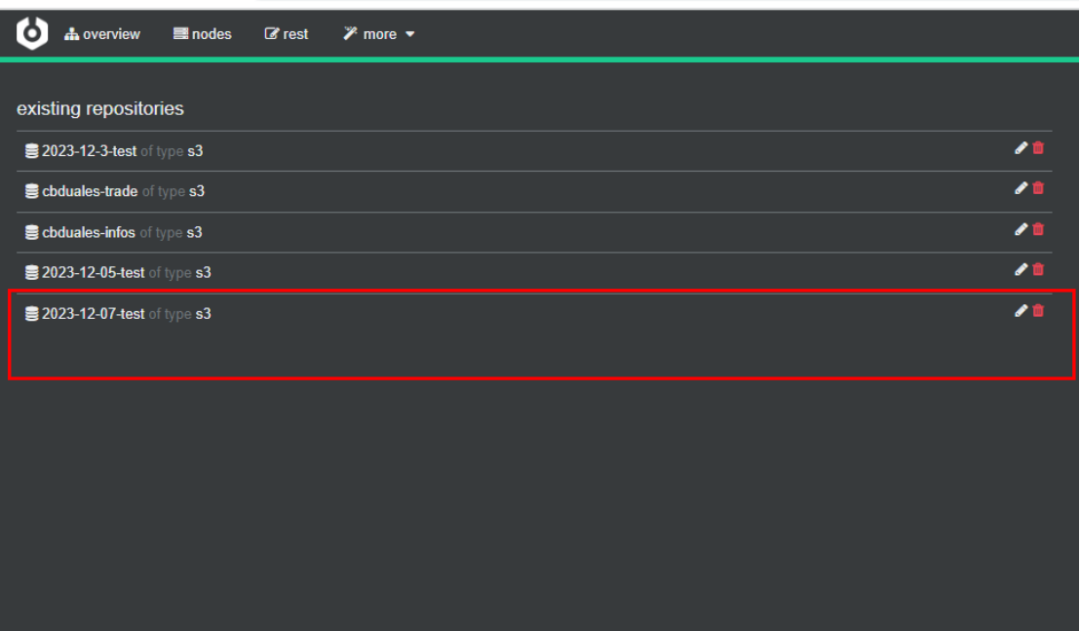
1)点击”more-->repositories”,可查看集群已存在的仓库列表:
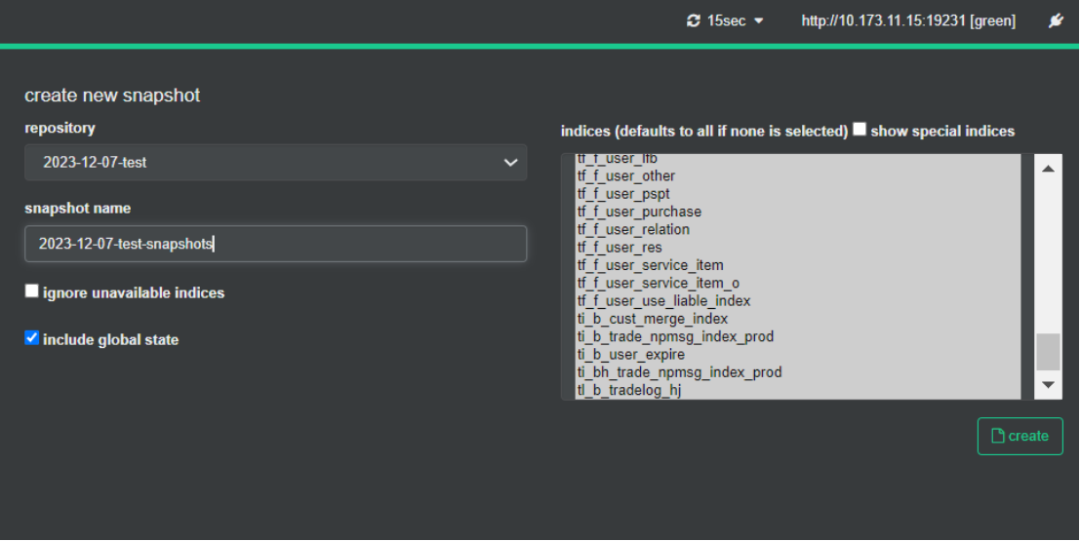
2)快照备份指定索引数据
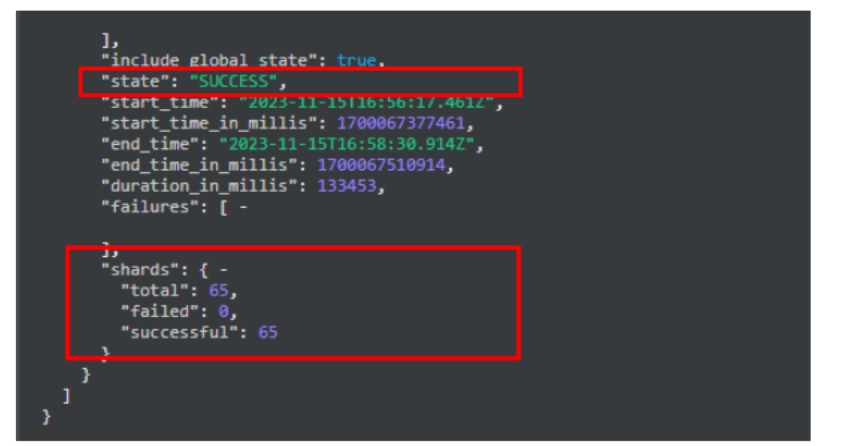
3)查看快照备份状态,确认快照备份完成
Cerebro执行命令:
GET _snapshot/仓库名/快照名
截图举例:
3.2.3 监控源集群快照创建过程:
使用get snapshot API
GET _snapshot/my_repository/my_snapshot返回以下内容:Start and end time values #开始时间和结束时间Version of Elasticsearch that created the snapshot #创建快照的Elastcisearch版本List of included indices #包含的索引列表Current state of the snapshot #快照当前状态List of failures that occurred during the snapshot #快照期间发生的故障列表复制
如下图返回
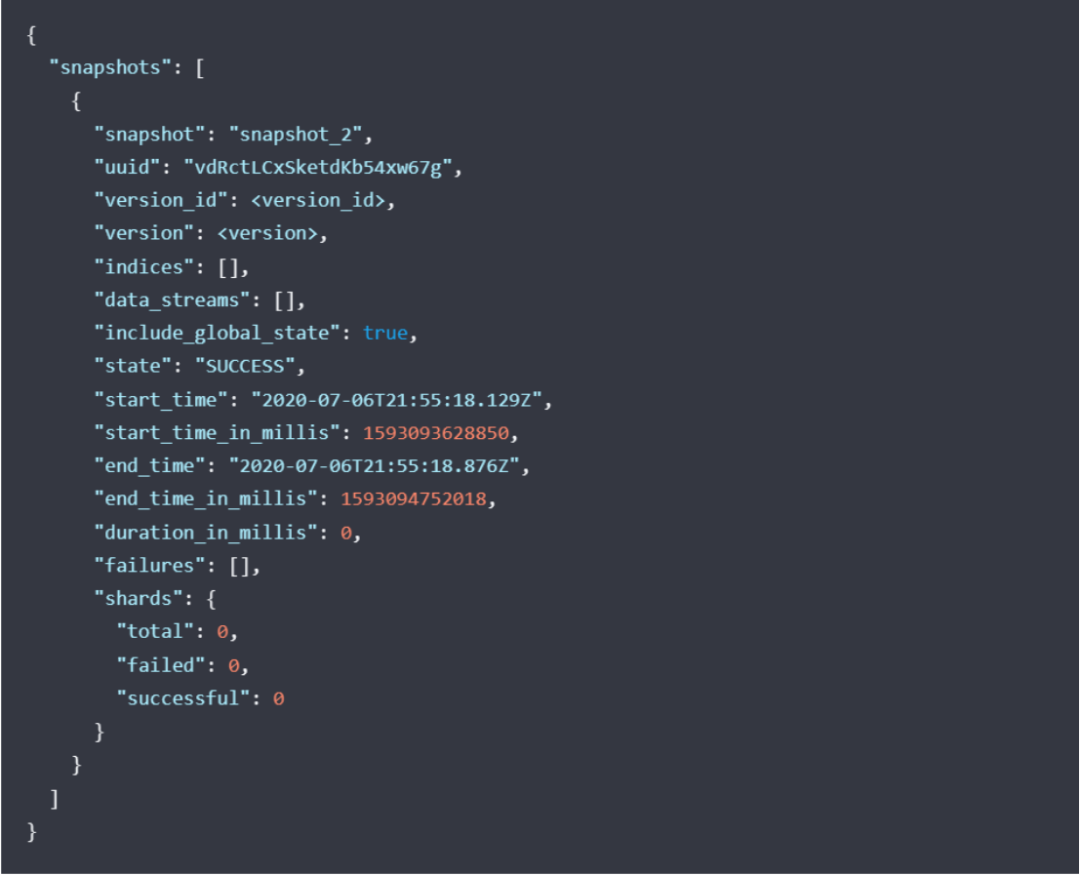
或get snapshot status API
检索参与快照的每个碎片的当前状态的详细描述。
RequestGET _snapshot/_statusGET _snapshot/<repository>/_statusGET _snapshot/<repository>/<snapshot>/_status复制
如下图返回
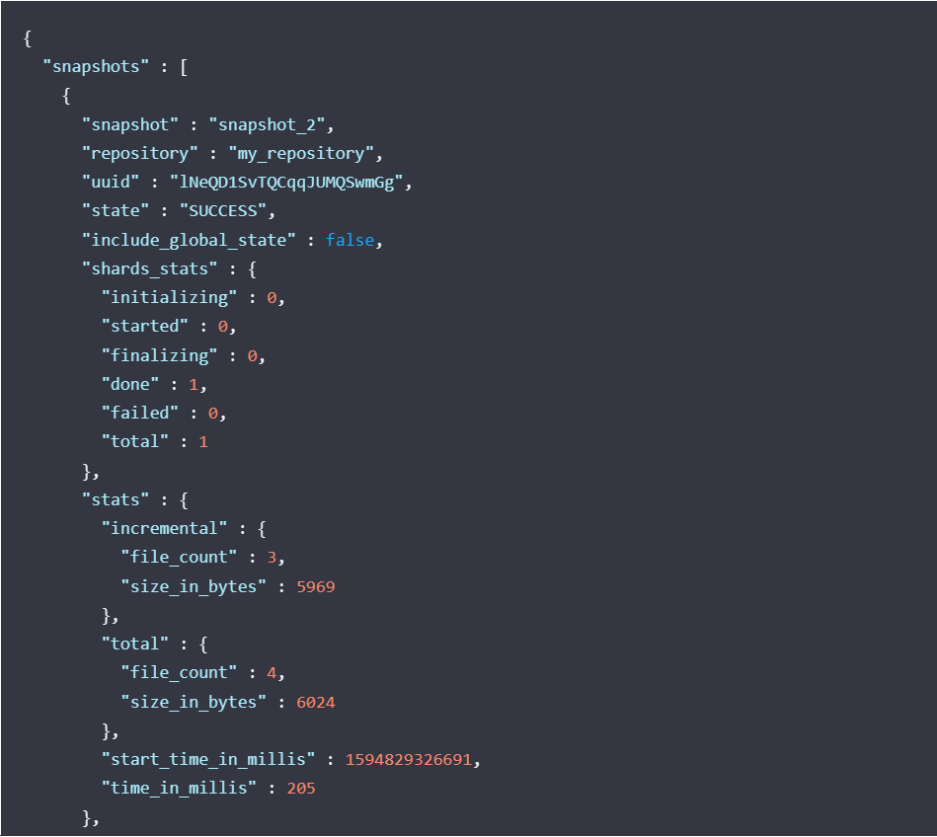
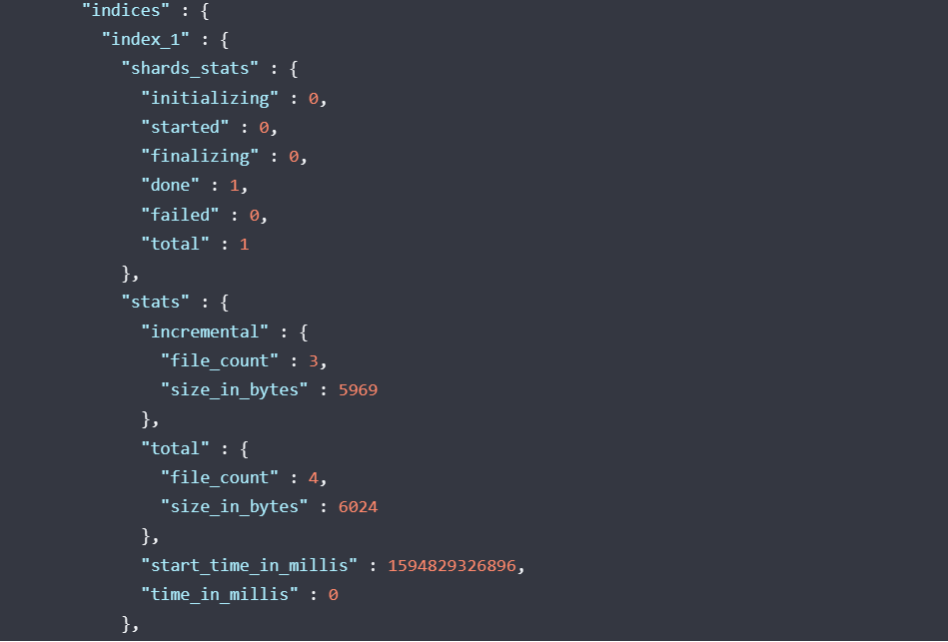
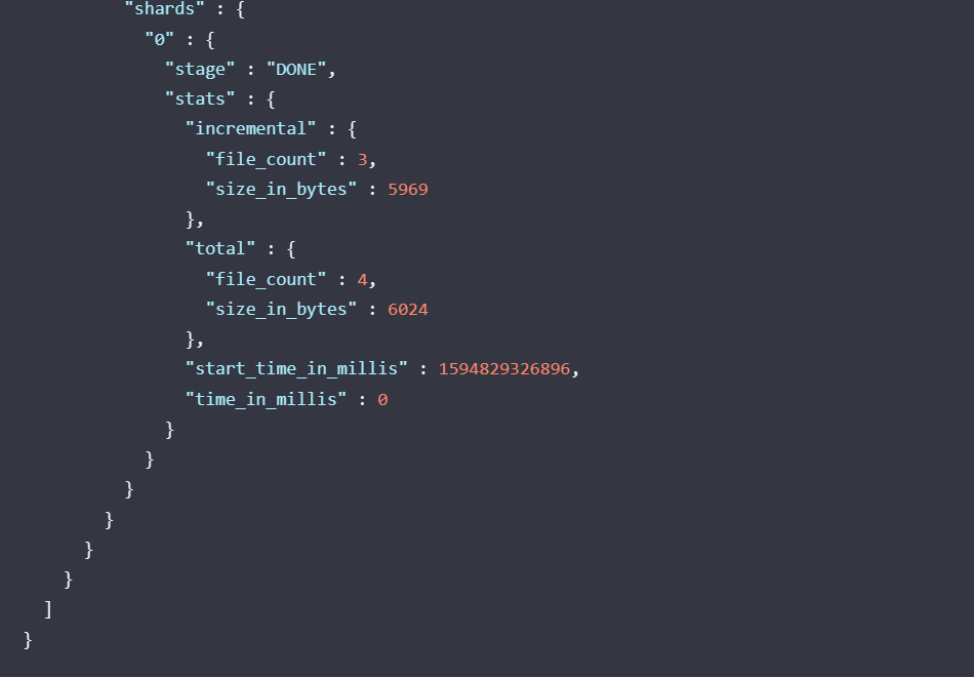
用来监控快照操作的进度。这两个API都支持阻止客户端直到操作完成的参数,这是收到操作完成通知的最简单方法。wait_for_completion
3.3 数据恢复
3.3.1 目标集群与存储桶建立连接(创建存储桶):
注册仓库,仓库名称与需要备份数据的配置一样。
PUT _snapshot/my_repository{"type": "s3","settings": {"access_key": "xxxxxxxxxxxxx","secret_key": "xxxxxxxxxxxxx","endpoint": "ip:port", # 访问cos服务的ip:port或者http/http地址"bucket": "my_repository", # 此处的bucket是在ceph中已存在的"base_path": "my_repository", # 此处的base_path可以自行设置,同一个桶中有多个路径."compress": true, #当设置为true时,元数据文件以压缩格式存储。此设置不影响默认情况下已压缩的索引文件。默认为false。"chunk_size": "200m", #如果需要,可以在快照过程中将大文件分解为块。将块大小指定为值和单位,例如:1GB、10MB、5KB、500B。默认为1GB。"max_restore_bytes_per_sec": "1024mb", # 每个节点的瓶颈恢复率。默认为无限制。请注意,恢复也会通过恢复设置进行限制。"max_snapshot_bytes_per_sec": "1024mb" # 每个节点的瓶颈快照速率。默认为每秒40mb。}}复制
3.3.2 恢复快照到目标Elasticsearch集群:
在目标Elasticsearch集群中,使用restore API将快照恢复到集群中。
还原全部数据
POST _snapshot/my_backup/snapshot_all_1/_restore{"indices": "*","ignore_unavailable": true, #是否忽略不可用的快照,默认为false,这意味着抛出SnapshotMissingException"include_global_state": false, #设置为false,可以防止将集群全局状态存储为快照的一部分。}复制
使用Cerebro简化操作
1)在目标集群导入索引数据
在目标集群选择指定快照索引(可多选),点击”restore”进行索引数据同步(可选择需要同步的索引,默认同步全部索引)
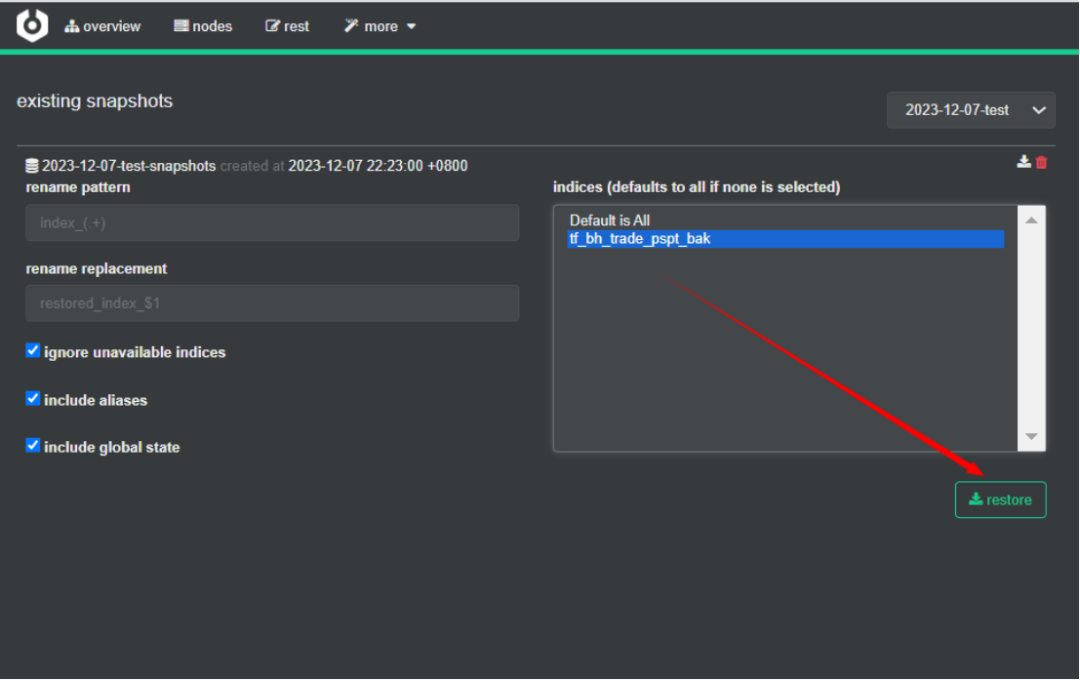
2)在kibana上确认还原结果
截图举例:
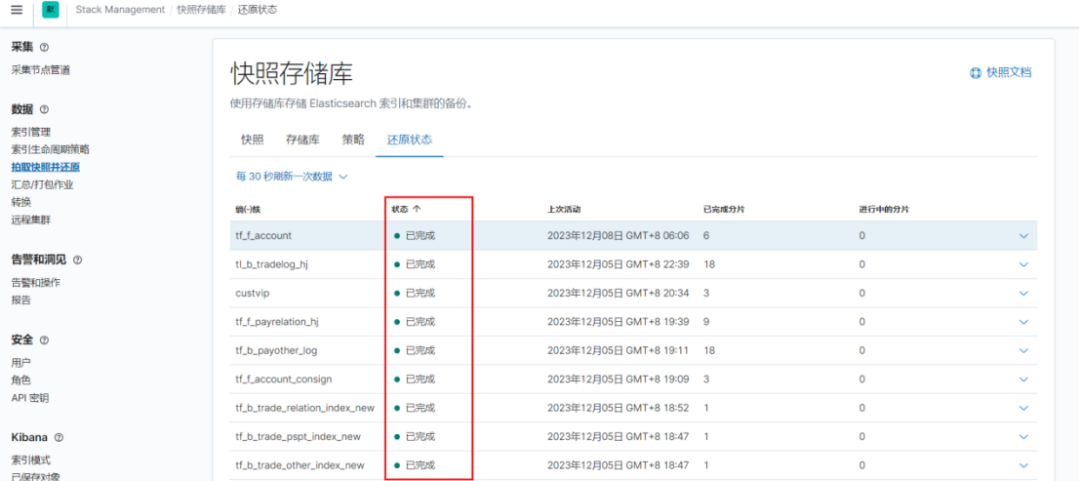
3.3.3 验证数据一致性:
检查恢复后的数据与原始数据的文档数是否一致,确保数据迁移成功。
问题详解
4.1 快照创建失败怎么办?
1. 存储配置错误:快照创建失败可能是由于存储配置错误导致的。请确保你已正确配置了存储库设置,在elasticsearch.yml文件中设置了正确的路径,并且具有正确的权限。还要确保网络连接正常,可以访问并使用指定的存储库。
解决方法:检查存储库设置,包括路径、权限和网络连接。确保路径有效并具有适当的权限。验证是否可以通过网络连接到存储库。
2. 存储空间不足:创建快照需要足够的可用存储空间。如果存储库的可用空间不足,快照创建将失败。
解决方法:检查存储库的可用空间。如果空间不足,增加存储容量或删除一些旧的快照以腾出空间。
3. 网络问题:快照创建可能因为网络连接问题而失败。如果网络不稳定或连接超时,快照创建可能会受影响。
解决方法:检查网络连接并确保网络稳定。你可以尝试延长连接超时时间或增加请求的重试次数来避免连接问题。
4. 权限不足:如果你没有足够的权限进行快照创建,操作将失败。
解决方法:确保具有适当的权限来创建快照。需要检查所使用的用户或角色是否具有适当的权限,并根据需要进
4.2 数据迁移过程中如何保证数据安全?
1.使用加密:确保在将快照数据存储在S3时,使用AWS的加密功能。这包括使用S3的server-side encryption(服务器端加密)或client-side encryption(客户端加密)。客户端加密可以通过Elasticsearch的snapshot API来启用,而服务器端加密则是AWS管理的,不需要你手动操作。
2.使用IAM角色:在Elasticsearch集群中,使用AWS Identity and Access Management(IAM)来控制对S3桶的访问。可以为Elasticsearch集群创建一个IAM角色,并赋予它必要的权限,而不是使用具有过多权限的通用用户账户。
3.权限最小化:遵循权限最小化原则,只授予Elasticsearch集群执行快照和恢复操作所必需的权限。避免使用具有过多权限的账户,以减少潜在的安全风险。
4.使用安全传输:在Elasticsearch集群和S3之间传输数据时,使用HTTPS来确保数据在传输过程中的安全。
5.监控和审计:启用AWS CloudTrail来记录对S3资源的访问活动,以便进行监控和审计。这可以帮助你在数据迁移过程中追踪数据的访问历史,并在出现问题时进行调查。
6.快照生命周期管理:在迁移完成后,合理管理快照的生命周期,包括删除不再需要的快照,以减少存储成本和潜在的安全风险。
7.数据验证:在快照恢复到Elasticsearch集群后,执行数据验证操作,确保数据的一致性和完整性。
8.灾难恢复计划:制定灾难恢复计划,以确保在数据迁移过程中发生系统故障或安全事件时能够快速恢复服务。
9.定期安全评估:在数据迁移完成后,定期进行安全评估和漏洞扫描,确保数据在新的环境中保持安全。
4.3 如何在迁移过程中避免性能影响?
1.制定一个详细的迁移计划,包括迁移的时间表、目标和步骤。将数据按照合理的批次进行分类,确定每个批次的优先级和迁移顺序。
2.确保迁移过程中有足够的资源(如带宽、存储空间)来支持数据的传输和存储。
3.如果数据量很大,建议将数据分成多个批次导入。这样可以避免一次性导入过多的数据,导致系统负载过高。通过分批导入,你可以控制导入速度,调整系统资源,确保平稳的迁移过程。
4.4 如何处理迁移后的数据不一致问题?
1. 数据一致性检查:在进行数据迁移后,进行数据一致性检查是至关重要的。你可以比较源Elasticsearch集群和目标集群之间的数据,确保两者的索引和文档数量相匹配。
2. 重建索引:如果发现数据不一致或丢失,尝试重建索引来解决问题。通过重新从源集群中的数据中创建索引并恢复数据,确保数据在迁移后是一致的。
3. 日志和错误处理:在进行迁移过程中,记录日志并处理任何可能出现的错误。如果发现迁移中的任何错误,可以根据错误信息进行逐个调查和处理,以确保数据的一致性。
4. 预先测试和验证:为了避免数据不一致问题,建议在正式迁移之前进行充分的测试和验证。创建一个测试环境,执行快照恢复流程,并验证数据的完整性和准确性。这样可以发现和解决潜在的问题,提高迁移的成功率和一致性。
5. 备份原始数据:在进行迁移之前,务必备份原始数据。这样可以在迁移过程中发生错误或数据丢失时,方便恢复原始数据并重新进行迁移。
优化与建议
5.1 快照数据迁移的最佳实践
在实际迁移之前,最好在测试环境中进行模拟迁移,验证迁移策略的有效性。
5.2 提高数据迁移效率的方法
1.优化网络稳定性
2.数据可以切块进行迁移:我们在进行数据迁移过程中由于网络带宽原因,"chunk_size"的值一直使用默认的1024m,频繁发生快照备份失败或者快照数据还原失败,根据在测试集群多次测试调整了"chunk_size"的值,提高了数据传输的成功率。
5.3 注意事项与风险防范
1.备份与恢复过程不能中断,不然会导致数据的丢失。
2.快照还原时,Elasticsearch会有5次失败重试机制,5次重试都失败,快照还原会失败。
3.快照备份之前最好对原始数据执行一次merge操作,保证数据的清洁,没有脏数据,提高数据的传输效率。
4.原始数据在备份之前最好能停止写入,等到数据迁移到备份集群之后,确保数据的一致性。
总结
6.1 本文主要内容回顾
本文主要介绍lElasticsearch使用S3插件快照数据迁移的步骤、问题及解决方案。
6.2 快照数据迁移在实际应用中的重要性
1.数据保护和恢复:Elasticsearch快照提供了一种可靠的数据保护机制。通过创建快照,可以在数据意外丢失或集群发生故障时,快速恢复到特定的数据状态。这对于确保数据的安全性和业务的连续性至关重要。
2.迁移和升级:在需要将Elasticsearch集群迁移到新的硬件或云平台,或者升级到新版本时,快照数据迁移提供了一种简便有效的方法。通过先创建快照,然后在目标环境中恢复快照,可以大大减少数据迁移的风险和复杂性。
3.并行处理和性能优化:快照迁移可以在不影响生产环境的情况下进行。通过在独立的迁移环境中处理快照,可以避免对现有业务造成干扰,同时还可以利用并行处理提高迁移效率。
4.数据一致性和完整性:快照迁移确保了数据的一致性和完整性。由于快照是数据的一个静态快照,所以在迁移过程中不会发生数据变更,保证了迁移后数据的准确性和可靠性。
5.灵活性和可扩展性:快照迁移支持多种数据源和目标,包括不同版本的Elasticsearch集群、不同的云存储服务(如Amazon S3)等。这种灵活性和可扩展性使得快照迁移成为一种广泛适用的数据迁移解决方案。
6.易于管理和监控:Elasticsearch快照迁移可以通过其自带的管理工具和监控功能进行监控和控制。例如,可以使用Elasticsearch的Snapshot API来管理和监控快照的创建、删除和恢复过程。
关于公司
感谢您关注新智锦绣科技(北京)有限公司!作为 Elastic 的 Elite 合作伙伴及 EnterpriseDB 在国内的唯一代理和服务合作伙伴,我们始终致力于技术创新和优质服务,帮助企业客户实现数据平台的高效构建与智能化管理。无论您是关注 Elastic 生态系统,还是需要 EnterpriseDB 的支持,我们都将为您提供专业的技术支持和量身定制的解决方案。
欢迎关注我们,获取更多技术资讯和数字化转型方案,共创美好未来!
 |  |
Elastic 微信群 | EDB 微信群 |
发现“分享”和“赞”了吗,戳我看看吧
