




前言
锁是一种并发控制手段,用于保护共享资源的访问,避免出现数据竞争和不一致的情况。锁机制的主要目的是确保数据的一致性和完整性,防止并发操作导致的冲突和错误。通过加锁,可以确保在某一时刻只有一个线程或事务能够修改共享资源,从而避免数据损坏或程序崩溃等问题。
表级锁
表锁的语法是:LOCK TABLE <模式名>.<表名> IN <封锁方式> MODE [NOWAIT];
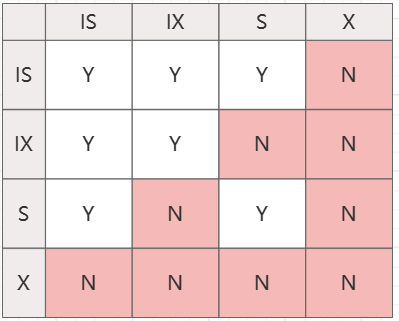
封锁方式有以下几种:
INTENT SHARE
ROW SHARE
SHARE UPDATE
INTENT EXCLUSIVE
ROW EXCLUSIVE
SHARE
EXCLUSIVE
SHARE INTENT EXCLUSIVE
SHARE ROW EXCLUSIVE
可以 用commit主动释放锁,也可以在客户端断开的时候自动释放。需要注意,以上的语法只会限制别的线程的读写,不会限定本线程接下来的操作对象。
举个例子:
-- 意向共享锁(IS)
lock table test.USERS in INTENT SHARE MODE;
lock table test.USERS in ROW SHARE MODE;
lock table test.USERS in SHARE UPDATE MODE;
以上三种封锁方式均为意向共享锁,其它事务禁止以排他锁方式(X)存取该表。可以进行对该表的并发查询、插入、更新、删除。
-- 意向排它锁
(IX)
lock table test.USERS in INTENT EXCLUSIVE MODE;
lock table test.USERS in ROW EXCLUSIVE MODE;
以上两种封锁方式均为意向排它锁,其它事务禁止对表执行共享锁(S)、排他锁(X)或共享意向排他锁(S+IX)封锁。可以进行对该表的并发查询、插入、更新、删除。
-- 共享锁
(S)
lock table test.USERS in SHARE MODE;
其他事务允许查询,但是不允许作修改。
-- 排它锁(X)
lock table test.USERS in EXCLUSIVE MODE;
其他事务做任何操作都会被阻塞。
-- 共享意向排他表封锁:(S+IX)
lock table test.USERS in SHARE INTENT EXCLUSIVE MODE;
lock table test.USERS in SHARE ROW EXCLUSIVE MODE;
一般不使用 以上命令来控制并发,毕竟锁住整个表的影响面还是太大了。
另一类的表锁就是数据字典锁了,是锁元数据的,在访问一个表的时候会自动加上,用来解决DDL并发和DDL与增删改查并发的问题,假如有这样一个这个场景,如果此时我们正在对一个表中做更新或者查询,而执行期间另一个线程要对这个表结构做变更,比如把这列删除了,那么更新或者查询的结果跟就表结构就对不上了,肯定是不行的。
因此,DM引入了字典锁,当对一个表做增删改查操作的时候,加读锁;当要对表做结构变更操作的时候,加写锁。
这个阻塞的时间默认是10S,由参数DDL_WAIT_TIME来控制。超过了10s后,被阻塞的事务就会超时退出。

虽然 字典锁 是系统默认会加的,但是身为DBA却是不能忽略的一个机制。比如,我就看到有人,给一个表加个索引,导致整个库挂了。
你肯定知道,给一个表加字段,或者修改字段,或者加索引,是需要扫描全表的数据。以免对线上服务造成影响,所以我们一般都会在业务低峰期或者干脆停机做生产变更,而实际上,有些业务是不可以停的,一个操作不慎就会出问题。我们来看一下下面的例子。
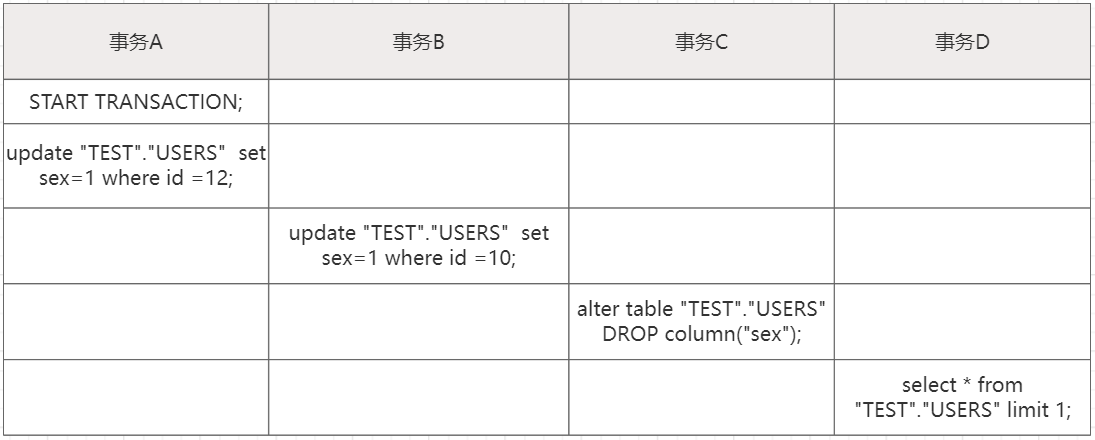
事务A先执行一个update,对表users加一个读锁,事务B同样需要读锁,可以执行。
但是事务C是需要一个写锁,因此会被阻塞,是因为事务A的读锁还没有释放,而事务C需要一个写锁只能是等待事务A释放锁。如果只有 session C 自己被阻塞还没什么关系,前面说了事务C会等待10s超时退出。
我们知道读写锁之间是互斥的,那么在事务C之后的其他事务都会被阻塞,在表现来看就是这个表完全不可以读写了。如果业务中对这个表的查询或者更新很频繁,并且应用有重试机制,那么这个库的会话就会很快爆满,CPU飙升,导致整个库挂了。
那么我们如何去安全的给一个热点表做变更呢,刚才我们说了DDL语句的等待是由参数 来控制的,我可以在会话级别上缩小这个值,那么在这个等待时间里能拿锁最好,拿不到就超时退出,后面在重试这个过程。
另外在达梦有一个非常帮的机制快速增加列的系统参数 ALTER_TABLE_OPT 。
默认值为0,意思是是否对加列、修改列、删除列操作进行优化,0:全部不优化;1:全部优化;2:打开快速加列,对于删除列和修改列与1等效;3:打开快速加列,允许指定快速列默认值,其他功能与2时相同 。
行级锁
DM没有行锁的概念,使用的事TID锁代替行锁的一种行级别的锁。
事务启动时,用自己的事务号生成的TID锁;DELETE/UPDATE记录触发的TID锁,优先使用S封锁,只有在多个事务同时更新同一行记录场景下,升级为X锁。

事务A 在执行update语句后对id=1这行加了一个TID锁,将自己的事务号赋值给TID字段,相当于上了一把TID锁,这时候事务B同样赋值给id=1这行的TID字段,但是当前被事务A持有,所以事务B被阻塞了,直到事务A commit 之后,事务B才能继续执行。
TID锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放。
所以当同一个事务中有多条语句时,需要锁定多个行,就需要业务或者DBA进行考量,将最有可能造成锁冲突的SQL语句放到最后。
死锁
死锁的关键在于:两个(或以上)的session加锁的顺序不⼀致。
用现实的问题举个例子,比如面试中,面试官问什么死锁,我回答:你给我offer我就告诉你什么死锁;面试官:你告诉我什么死锁,我才能给你offer。这就俩人就陷入无限循环等待,就是死锁。
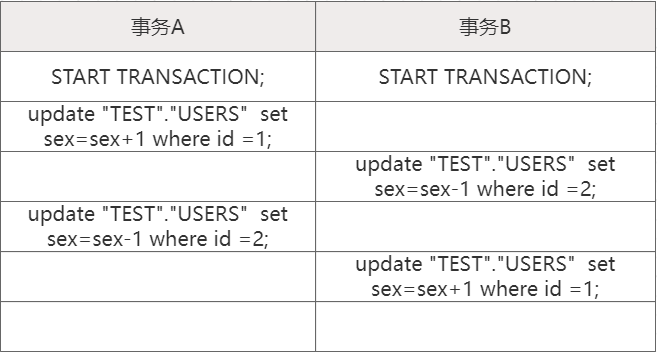
事务A持有id=1的TID锁,事务持有id=2的TID锁。然后事务A等待id=2的锁释放。事务B等待id=1的锁释放,就产生了死锁。DM数据库中有一种策略,发起死锁检测,会杀掉造成死锁的SQL,返回错误:“-6403: 死锁”。也就是杀掉事务B中第二个update。
这个参数是由 DEADLOCK_CHECK_INTERVAL 控制,默认值1000ms。
死锁检测也是需要消耗CPU资源的,就是说一个事务被锁住了,那就要去看看这个事务有没有锁住其他事务,再判断是否出现了循环等待。那么如果在高并发的场景下,很多个线程同时更新同一行,那这个期间就会消耗大量的CPU资源,通过dem你就会看到CPU飙升,但是QPS确没有多少。
针对此种现象,只能去控制并发度,DM是不可以关闭死锁检测的,同时也不建议去关闭,因为关掉死锁检测是对业务有损伤的,因为可能会出现大量的超时,这是不可接受,反而有死锁检测,回滚之后业务可以进行重试一般就没有问题了。
控制并发度,一种是客户端去做,就是控制针对同一行更新的线程数,另外一种是服务端,对于同一行的更新进行排队。这种方案需要对业务逻辑做详细设计,以及非常专业的人士才能实现。
达梦社区技术https://eco.dameng.com



