




3.2 GPUDirect 技术
3.2.1 GPUDirect 1.0 (NIC)
在CUDA 3.1中引入的GPUDirect 1.0允许GPU和网卡(NIC)共享相同的固定内存区域。在此之前,GPU和NIC在系统内存中有各自独立的固定内存区域。
因此,为了在节点之间传输GPU数据,GPU首先将数据复制到其固定内存区域,然后由CPU将数据复制到NIC的内存区域,只有这样NIC才能访问数据并将其发送到网络,如图2-1所示。GPU到NIC固定内存区域的中间CPU发起的复制增加了CPU开销,并且增加了GPU通信的延迟。GPUDirect 1.0引入了一个共享的GPU-NIC固定内存区域,从而避免了中间的CPU发起复制。
3.2.2 GPUDirect 2.0 (点对点通信)
随着UVA的引入,CUDA 4.0版本增加了对同一节点中共享相同PCIe Root Complex 的GPU之间直接点对点通信的支持。这一功能被封装在一种名为GPUDirect 2.0或GPUDirect P2P的技术中。GPU现在可以通过PCIe直接访问彼此的内存,而不再需要通过主机进行数据中转,从而首次建立了直接的GPU到GPU的数据传输路径。这些变化导致了两种新的通信机制的出现:
P2P DMA拷贝:通过cudaMemcpy调用,触发源GPU和目标GPU内存之间的DMA传输。
P2P直接加载/存储:GPU可以通过解引用指向远程GPU缓冲区的指针,直接访问数据。
当NVLink技术引入时,GPUDirect P2P还增加了对NVLink的支持(见第3.4节)
GPUDirect P2P提供了两个主要好处:
消除了通过主机传输时需要的冗余GPU ↔ CPU拷贝和主机缓冲区。
通过避免在主机上维护通信缓冲区并提供一种新的通信机制(P2P直接加载/存储),GPUDirect P2P提高了多GPU编程的便利性
需要注意的是,P2P DMA拷贝在没有UVA支持的情况下也能工作。如果未启用UVA,P2P DMA拷贝可以通过cudaMemcpyPeer()变种来显式指定目标GPU。然而,P2P直接加载/存储在没有UVA的情况下无法工作,因为直接访问远程GPU的指针假设了统一地址空间.
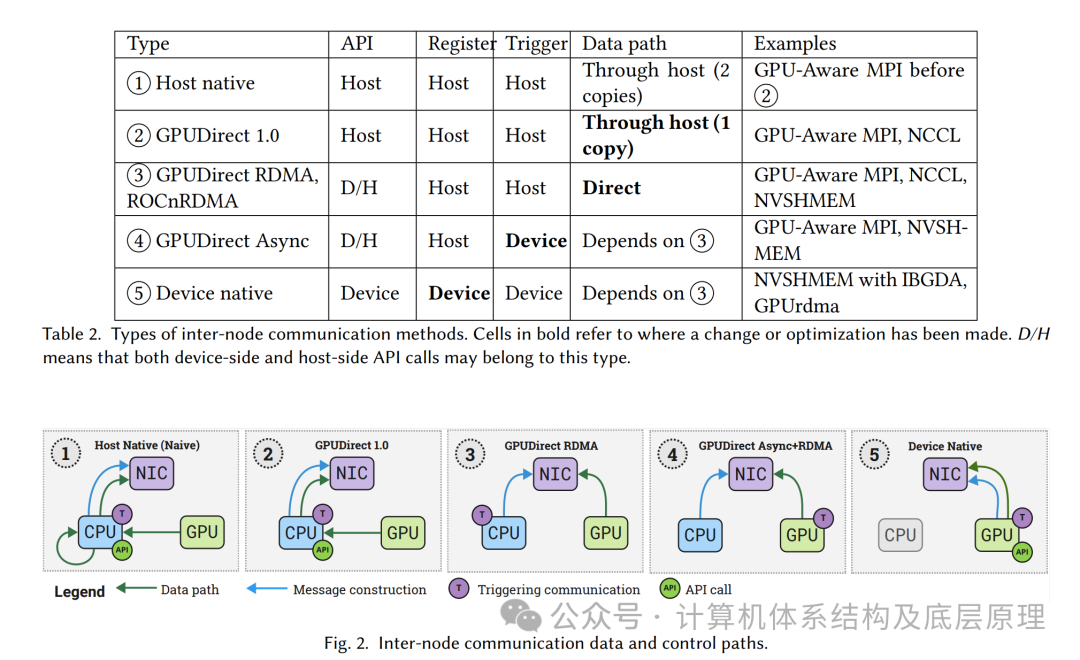
3.2.3 GPUDirect RDMA
随着CUDA 5.0中GPUDirect RDMA的引入,跨节点之间的NVIDIA GPU直接通信成为可能。GPUDirect RDMA通过标准的PCIe功能,促进了GPU与第三方设备之间的直接通信通道。该技术通过PCIe内存资源暴露GPU内存的部分区域,称为基址寄存器(BAR)区域,使得网卡(NIC)可以直接读取/写入GPU内存,而无需经过主机。类似地,AMD也提供了ROCm RDMA(以前称为ROCnRDMA)GPUDirect RDMA对数据路径进行了几项优化,主要通过消除额外的主机内存拷贝,减少GPU与NIC交互时的固有延迟,增加带宽,并降低CPU开销。GPUDirect RDMA的支持已集成到多个领先的通信库中,包括GPU感知的MPI实现、NCCL和NVSHMEM
3.2.4 GPUDirect Async
虽然之前的GPUDirect技术主要集中在改善数据路径,GPUDirect Async则优化了GPU与网卡(NIC)之间的控制路径。该技术在CUDA 8.0中引入,允许GPU发起和同步网络传输,从而减少了CPU在关键路径中的参与。GPUDirect Async的工作原理是让CPU预先注册消息,然后GPU内核通过在NIC上触发“门铃”来启动这些消息。因此,GPU可以在通信被触发时继续执行,而不需要像以前那样暂停并等待CPU发起通信。
尽管GPUDirect Async在将控制路径从CPU转移出去方面取得了进展,但它仍未完全将控制路径转移到GPU,因为通信仍然局限于内核启动边界。实际上,GPU只能发起CPU预先注册的消息。进一步的GPUDirect Async改进作为NVSHMEM库中的IBGDA传输的一部分得到了实现(见第4.3.1节)
3.3 GPUNetIO
GPUNetIO是NVIDIA提出的一种技术解决方案,作为DOCA(Datacenter-On-a-Chip Architecture)[27]的一部分。DOCA是一个完整的软件框架,旨在促进为NVIDIA BlueField数据处理单元(DPU) 开发应用程序的过程。在非RDMA网络上,GPUNetIO允许GPU发送、接收和处理网络数据包。在RDMA网络(包括RoCE和InfiniBand)上,从DOCA v2.7开始,GPUNetIO不仅允许GPU在内核边界上执行RDMA发送和接收,还可以在内核执行的任何时刻进行。
简而言之,GPUNetIO允许GPU与网卡(NIC)进行交互,而不需要CPU在关键路径上的干预。
在RDMA网络上,GPU内核可以等待(以阻塞或非阻塞模式)RDMA接收操作的完成。在非RDMA网络上,GPUNetIO提供了信号量,可以在内核中显式地用于与NIC同步,处理数据包的发送和接收。信号量还可以用于在GPU内核与CPU之间同步(如果数据包处理在CPU和GPU之间分配)或在多个CUDA内核之间同步(如果数据包处理跨多个内核)。
3.4 现代GPU中心互连
NVLink是一种专有的互连技术,旨在促进NVIDIA GPU之间的高带宽和低延迟直接访问。其设计解决了PCIe带宽的限制,PCIe在GPU加速应用中已被证明是传输瓶颈。表3展示了每一代NVLink的规格。
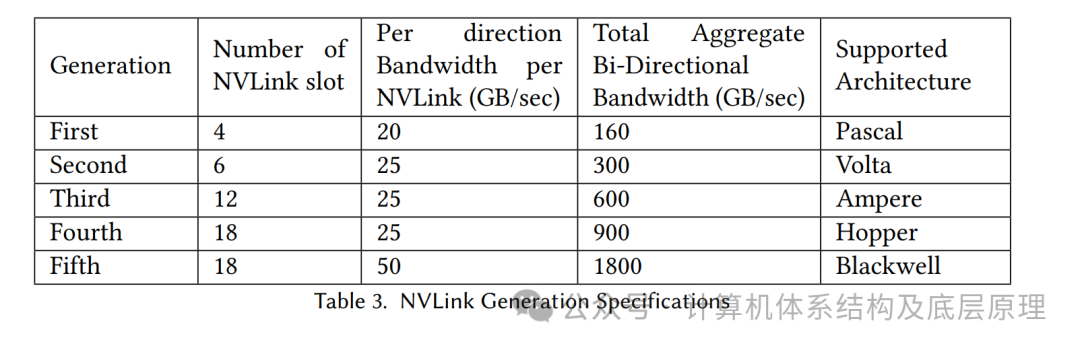
此外,NVLink也曾用于将GPU与IBM Power8和Power9 CPU连接,但随着Grace Hopper Superchip的推出,NVLink作为芯片间(C2C)互连技术被使用,提供900 GB/sec的双向带宽。随后,随着Grace Blackwell Superchip的推出,NVLink-C2C用于将Grace CPU与2个Blackwell GPU连接,提供总计3.6 TB/sec的双向带宽。第五代NVLink在NVIDIA Blackwell上为每个GPU提供1.8TB/s的双向吞吐量,在最多576个GPU之间提供高速通信。
尽管通过GPUDirect P2P,GPU之间的直接点对点通信已经通过PCIe建立,但由于PCIe的带宽较低,这种通信受到了严重瓶颈。NVLink的引入优化了NVIDIA GPU之间的带宽,使得P2P通信成为一种可行的节点内通信机制,并大幅度将数据路径倾向于GPU。然而,NVLink的一个缺点是它不是自路由的,这意味着如果任何两个GPU之间没有直接的NVLink连接,通信必须通过中间GPU进行路由。这个限制通过NVSwitch克服,NVSwitch是一种背板技术,可以实现所有GPU之间的全互联。例如,一个DGX-2节点包含16个V100 GPU,这些GPU通过NVLink和NVSwitch实现全互联。从第三代开始,NVSwitch支持SHARP(之前的NVSWITCH 文章有专门介绍),将allreduce操作卸载到NVSwitch,从而使allreduce操作能够以全线速率运行。
AMD也提供了一种名为xGMI/Infinity Fabric的专有互连技术。然而,它目前缺乏类似NVSwitch的技术。尽管最多可以将8个MI300X GPU连接成一个全互联网格,但NVSwitch最多可以连接64个GPU。最近,Ultra Accelerator Link (UALink)联盟成立,旨在开发一种更开放的共享内存加速器互连,兼容多种技术和供应商。
3.5 厂商机制讨论
3.5.1 GPUDirect P2P 和直接加载Load 存储 Store 对编程的影响
GPUDirect P2P的引入标志着多GPU执行范式的重大转变,使得GPU之间能够通过内核内部的加载和存储操作进行直接通信。基于直接加载/存储的通信提供了几个好处。
首先,它允许程序员将通信与计算内联,这可能减少代码的复杂性并提高程序员的生产力。程序员不再需要依赖独立的通信和计算模型,而是可以将它们结合在GPU内核中。
其次,直接加载/存储利用了GPU提供的高度并行性,能够比DMA拷贝实现更高的带宽和更低的延迟。
第三,直接加载/存储可以通过GPU固有的延迟隐藏能力,隐式地将通信与计算重叠。考虑到GPU提供的高并行性以及现代互连技术提供的日益增高的带宽,GPU不仅能隐藏本地内存的延迟,还能隐藏远程内存的延迟。这一点对程序员来说是另一大好处,因为实现重叠的方式从程序员通过流和事件手动实现的软件方法,转变为硬件自动实现的重叠。由于通信/计算重叠的责任由程序员转移到硬件,另一个影响是,随着硬件在隐藏内存延迟方面的改进,重叠性能也会随之提升。
第四,直接加载/存储扩展了可以通过多个GPU加速的应用范围。传统上,具有细粒度通信模式的应用在多GPU系统上往往扩展性差,因为计算通常需要中断并同步,以便CPU发起通信。通过内核中的直接加载/存储,GPU可以很好地适应细粒度的通信模式。
尽管直接加载/存储带来了许多改进,但也存在一些固有的挑战。首先,一个基本挑战是通信和计算争夺相同的有限资源,因为它们现在都需要大量的GPU线程来推动进程。这在通信作为独立内核实现时尤为突出。如果计算内核首先启动,它可能会垄断所有GPU资源,阻止通信内核的启动,实际上消除了任何重叠的可能性。通过以更高的优先级启动通信流来缓解这个问题,可以确保通信流始终首先被调度。需要注意的是,P2P DMA拷贝没有这个问题,因为它们使用GPU的DMA/拷贝引擎——一个物理上独立的资源——进行通信。
其次,类似于单GPU内存访问,P2P直接加载/存储对内存合并非常敏感,随机的非合并访问比合并访问的性能要差得多。这种非合并的直接读取可能会暴露远程内存的延迟,超出了GPU调度器隐藏的能力,最终导致执行停顿。类似地,偶发的非合并直接写入在子缓存行粒度下可能会极大地低估互连的使用效率
3.5.2 GPUDirect RDMA的限制
GPUDirect RDMA的一个显著限制是,在内核运行期间,GPU和网卡(NIC)内存之间的一致性无法得到保证。一致性仅通过返回控制权给CPU,拆除当前内核并启动一个新内核来保证,从而将通信限制在内核边界内。这也意味着,将持久内核与GPU发起的节点间通信结合使用,最终会导致数据正确性问题。Chu等人通过从NIC向GPU内存发起PCIe读取操作来绕过这个限制,这样可以刷新之前写入到GPU的NIC数据,并保证内存排序。从CUDA 11.3版本开始,CUDA也提供了cudaDeviceFlushGPUDirectRDMAWrites() API,类似地可以用于强制一致性。尽管这个方法有用,但CUDA仍依赖CPU来确保GPU-NIC一致性。相比之下,AMD在持久内核的设备端通信中明确解决了GPU-NIC一致性问题,并将提议的修复集成到ROCM SHMEM中。我们将在第5.3节中进一步讨论这一问题,特别是在无CPU网络环境中的处理。
3.5.3 在GPU中心通信中启用触发功能
在第2节介绍的类型3(GPUDirect/ROCn RDMA)中,CPU仍然负责系统的初始配置、数据传输准备和启动传输。第一阶段包括设置网络接口和加载GPU驱动程序。CPU注册GPU内存与支持RDMA的NIC。这种主机注册允许NIC直接访问GPU内存,从而避免了数据传输过程中的中间CPU步骤。在第二阶段,CPU分配GPU内存缓冲区并确保它们的对齐。这些缓冲区将用于高效的数据传输进出GPU。接着,CPU设置GPU流和事件,这些流和事件管理和排序数据传输,并确保工作任务的编译。流用于排队操作,确保操作按照正确的顺序执行。然而,对于真正低延迟的应用来说,这个成本可能仍然是一个瓶颈,因为该机制依赖于通过流进行的多个同步点。
第2节中定义的类型4和类型5中的GPU触发通信通过消除上述描述的同步成本,促进了计算和通信控制路径的卸载,转移到GPU上。在这里,触发操作发挥着至关重要的作用,因为它们是特殊的任务,只有在满足特定条件时才会执行。
在流触发(ST)策略中,这些操作通过GPU控制处理器(GPU CP)管理数据传输和同步,从而减少了CPU的参与。延迟执行是另一个关键方面,在这种方式下,CPU创建具有延迟执行语义的命令描述符,并将其附加到NIC命令队列中。当GPU控制操作指定的条件得到满足时,这些描述符会被执行。例如,HPE Slingshot 11 NIC支持这些延迟操作,包括在硬件计数器达到给定阈值时触发的发送和接收通信。通过启用特定的命令队列(例如,Libfabric延迟工作队列)可以实现这一点。GPU控制处理器和NIC之间的同步确保了通过特殊机制(例如,在NVIDIA DOCA中通过GPUNetIO信号量实现)成功完成通信操作。
未完待续...
本文相关论文存放在知识星球

-----------------------------------------------------------------------------
相关文档和资料统一存放在知识星球,加入获得更多相关资料
本文根据以下资料撰写,加入星球可获得更多1500+详细资料

互动群加入,目前已经满200,先加微信后再加入

