




内存是计算机体系中存储器系统的一部分,存储器系统是一个具有不同容量、成本和访问时间的存储设备的层次结构。CPU计算器保存着最常用的数据。靠近CPU的小的、快速的高速缓存存储器作为一部分存储在相对慢速的主存储器中的数据和指令的缓冲区域。主存缓存存储在容量较大的、慢速磁盘上的数据,而这些磁盘常常又作为存储在通过网络连接的其他机器上的磁盘或磁带上的数据的缓冲区域。
存储器层次结构是可行的,这是因为与下一个更低层次的存储设备相比来说,一个编写良好的程序倾向于更频繁地访问某一个层次上的存储设备。这就是我们常说的局部性。绝大部分存储设备和软件都依赖于局部性而进行设计和优化的。
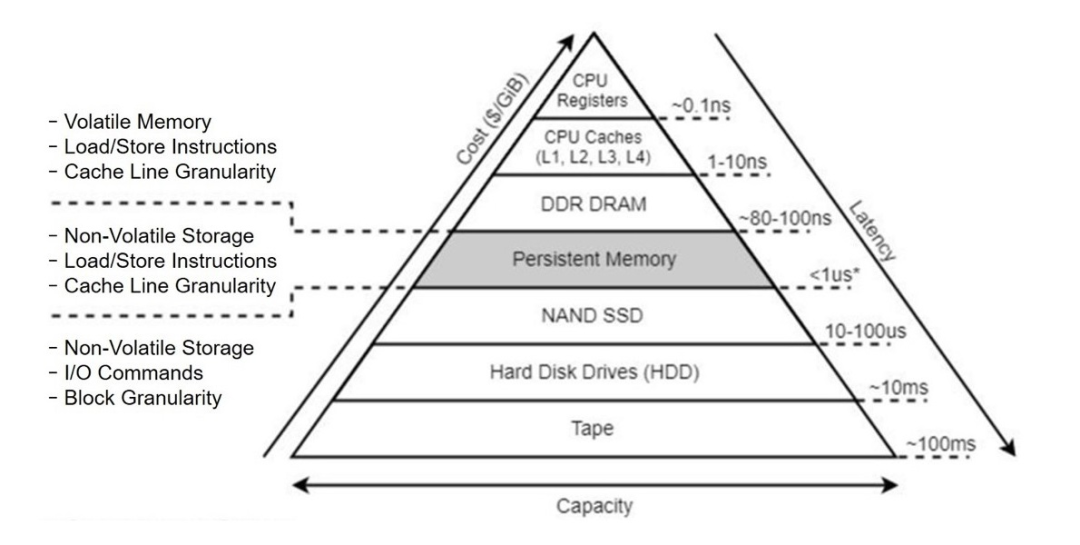
PostgreSQL的relcache,plancache,buffer pool都是利用结构或者设备完成对于局部性的应用,以提高数据库的性能。
进程的内存统计
通过/proc/postmaster/smaps查看进程映射的内存情况:
[root@iZbp1gfz9bu4kbcsfjvip5Z ~]# cat proc/107237/smaps
01648000-01692000 rw-p 00000000 00:00 0 [heap]
Size: 296 kB
KernelPageSize: 4 kB
MMUPageSize: 4 kB
Rss: 212 kB
Pss: 86 kB
VmFlags: rd wr mr mw me ac sd
7fdfdb200000-7fdfe6c00000 rw-s 00000000 00:0e 2621601 /anon_hugepage (deleted)
Size: 190464 kB
KernelPageSize: 2048 kB
MMUPageSize: 2048 kB
Rss: 0 kB
Pss: 0 kB
VmFlags: rd wr sh mr mw me ms de ht sd
# huge_pages=off
# 7f4f90a8c000-7f4f9c3de000 rw-s 00000000 00:01 4099 /dev/zero (deleted)
# Size: 189768 kB
# KernelPageSize: 4 kB
# MMUPageSize: 4 kB
# Rss: 30912 kB
# Pss: 30118 kB
# VmFlags: rd wr sh mr mw me ms sd
7fdfe6d00000-7fdfe6d07000 rw-s 00000000 00:17 10 /dev/shm/PostgreSQL.1960347178
Size: 28 kB
KernelPageSize: 4 kB
MMUPageSize: 4 kB
Rss: 4 kB
Pss: 4 kB
VmFlags: rd wr sh mr mw me ms sd
7fdff4596000-7fdff4597000 rw-s 00000000 00:01 9 SYSV000c256a (deleted)
Size: 4 kB
KernelPageSize: 4 kB
MMUPageSize: 4 kB
Rss: 4 kB
Pss: 4 kB
VmFlags: rd wr sh mr mw me ms sd复制
通过查看postmaster的smaps,可以明显看到有heap,/SYSV**,anon_hugepage(huge_pages=on),/dev/shm/**,4种内存。
分别是进程内存,内部共享内存,预分配的共享内存以及dsm元数据。
PostgreSQL的三类内存
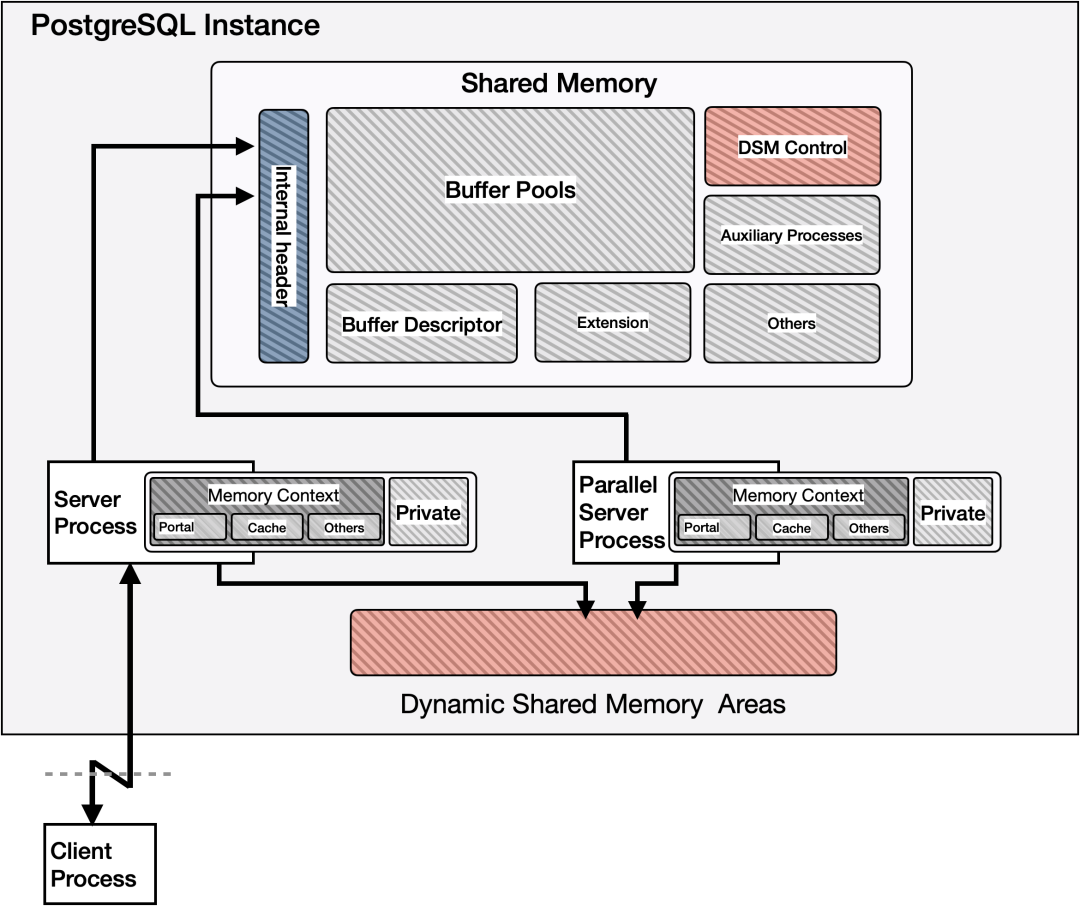
静态分配的共享内存,Shared Memory,在实例启动时建立的,为所有进程共同使用,内存地址通过fork继承到各个子进程,所有进程的内存地址相同。由多个Component组成,主要有:
Internal Header,在参数shared_memory_type为mmap时,此部分内存作为内部lock,并提供异常退出后的清理dsm的能力;如果shared_memory_type为sysv,那么所有内存都将使用sysv的形式申请,不再存在anon_hugepage的内存;同样提供以上两种能力;
Buffer Pool Block,主要存储数据page,按照一定结构组织的数据page;
Buffer Pool Desc,主要存储数据page的描述符,数据库以此作为freelist等链表使用;
Auxiliary Processes,系统进程需要的内存,比如wal buffer,clog buffer等等;
Extension,插件申请的使用共享内存;
Others,其他系统内部申请的内存块,例如LwLock等;
进程间的动态共享内存,DSM/DSA,由非PostMaster进程创建,并由多个并行进程共享。内存地址在不同进程映射到不同的地址。
Dsm Control,存储Dsm的元数据,便于对并行查询产生的Dsm文件进行处理;
DSA,实际存储进程间共享数据区域;
进程内存,建立进程时,随着操作运行而产生的内存。按照管理方式可以分为两部分
Memory Context,PostgreSQL为了避免内存泄漏,以及内存申请、释放带来的工程化问题而建立的一套内存管理机制。使用palloc pfree管理,并提供与各种范围相关的内存堆层次结构的MemoryContext,底层使用malloc/free申请/释放内存;
Private Area,PostgreSQL直接使用malloc/free申请/释放的内存区域;
静态分配的共享内存
静态分配的共享内存是一段匿名共享内存,在实例启动时根据参数设置,计算长度,申请一整段的共享内存。在内存段中,各个模块按照参数或需求大小利用偏移获取指针。在fork后,内存地址被继承到所有子进程,从而实现了所有进程共享同一内存地址的目的。
PostgreSQL没有shared memory总量大小限制,只能通过不同参数对不同模块进行设置。
/* 根据参数或者预设值计算内存长度 */
size = 100000; //防止对齐造成的内存不足
size = add_size(size, BufferShmemSize());
size = add_size(size, XLOGShmemSize());
/* might as well round it off to a multiple of a typical page size */
size = add_size(size, 8192 - (size % 8192));
/* 插件内申请共享内存 */
//RequestAddinShmemSpace(size());
/* 按照上面计算的长度申请内存 */
PGSharedMemoryCreate(size, &shim);
/* 静态内存分配器初始化 */
InitShmemAccess(seghdr);
/*
* 初始化静态分配器的hashtable,hashtable的作用是为了
* 能够快速找到内存是否已分配,避免重复分配或者错误使用
*/
InitShmemIndex();
/* 按照模块进行初始化 */
InitBufferPool();
/* 初始化分部dsm的内存(可以在设置部分共享内存作为dsm的内存使用) */
/* Initialize dynamic shared memory facilities. */
if (!IsUnderPostmaster)
dsm_postmaster_startup(shim);
/* 插件内存 */
if (shmem_startup_hook)
shmem_startup_hook();复制
内存的建立
预分配共享内存缺省情况下是通过两种方法申请建立的:
PGSharedMemoryCreate,InternalIpcMemoryCreate,SYSV的内存申请方式;
NextShmemSegID = statbuf.st_ino;
for (;;)
{
memAddress = InternalIpcMemoryCreate(NextShmemSegID, sysvsize);
shmid = shmget(NextShmemSegID, sizeof(PGShmemHeader), 0);
if (shmid < 0)
{
oldhdr = NULL;
state = SHMSTATE_FOREIGN;
}
else
state = PGSharedMemoryAttach(shmid, NULL, &oldhdr);
switch (state)
{
case SHMSTATE_ANALYSIS_FAILURE:
case SHMSTATE_ATTACHED:
ereport(FATAL);
break;
case SHMSTATE_ENOENT:
elog(LOG);
break;
case SHMSTATE_FOREIGN:
NextShmemSegID++;
break;
case SHMSTATE_UNATTACHED:
if (oldhdr->dsm_control != 0)
dsm_cleanup_using_control_segment(oldhdr->dsm_control);
if (shmctl(shmid, IPC_RMID, NULL) < 0)
NextShmemSegID++;
break;
}
if (oldhdr && shmdt(oldhdr) < 0)
elog(LOG, "shmdt(%p) failed: %m", oldhdr);
}复制
SYSV内存可以使用ipcs查看:
[postgres@ab7a9d32d2b0 home/postgres] $ipcs
------ Message Queues --------
key msqid owner perms used-bytes messages
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
0x00000072 16351232 postgres 444 1 28
0x25d207ba 18087937 postgres 600 128 25
------ Semaphore Arrays --------
key semid owner perms nsems复制
其中key=0x25d207ba的SYSV内存段是Internal Header;key=0x00000072的SYSV内存段是使用openssl链接库所使用的。
CreateAnonymousSegment,MMAP的内存申请方式(PG9.3开始使用此函数进行内存申请);
if (huge_pages == HUGE_PAGES_ON || huge_pages == HUGE_PAGES_TRY)
{
ptr = mmap();
mmap_errno = errno;
if (huge_pages == HUGE_PAGES_TRY && ptr == MAP_FAILED)
elog(DEBUG1, "mmap(%zu) with MAP_HUGETLB failed, huge pages disabled: %m",
allocsize);
}
if (ptr == MAP_FAILED && huge_pages != HUGE_PAGES_ON)
{
allocsize = *size;
ptr = mmap();
mmap_errno = errno;
}
if (ptr == MAP_FAILED)
{
errno = mmap_errno;
ereport(FATAL);
}复制
此部分内存是匿名内存,只存在一个伪内存文件/anon_hugepage (deleted)(huge_pages = on),/dev/zero (deleted) (huge_pages = off)。
Double Buffer问题
PostgreSQL文档关于缓存配置介绍:
If you have a dedicated database server with 1GB or more of RAM, a reasonable starting value for shared_buffers is 25% of the memory in your system. There are some workloads where even larger settings for shared_buffers are effective, but because PostgreSQL also relies on the operating system cache, it is unlikely that an allocation of more than 40% of RAM to shared_buffers will work better than a smaller amount.
官方推荐的内存配置为25%~40%。主要原因如下:
PostgreSQL relies on the operating system cache.
Larger settings for shared_buffers usually require a corresponding increase in max_wal_size, in order to spread out the process of writing large quantities of new or changed data over a longer period of time.
PostgreSQL依赖page cache,这部分是操作系统级的共享,cache可以在一定情况下进行快速回收,便于其他情况使用。PG本身可以利用此部分内存,提高I/O效率;
如果buffer pool本身设置过大,也会造成checkpoint需要write back更多数据,需要更长时间;
由于PG是多进程架构,过大的shared memory也会挤占进程计算空间内存,会引发OOM;
大页
PostgreSQL是多进程架构,进程拥有独立的虚拟内存,有独立的页表空间。每个页表项为8 bytes。
以128G共享内存为例:
普通4K Page需要使用,128*1024*1024/4*8/1024/1024=256MB,1000个进程就大约需要256GB;
2MB Page需要使用,128*1024/2*8/1024=512KB,1000个进程大约需要512MB;
为了避免页表带来的内存消耗,PostgreSQL 9.3开始支持hugepage。
内存分配
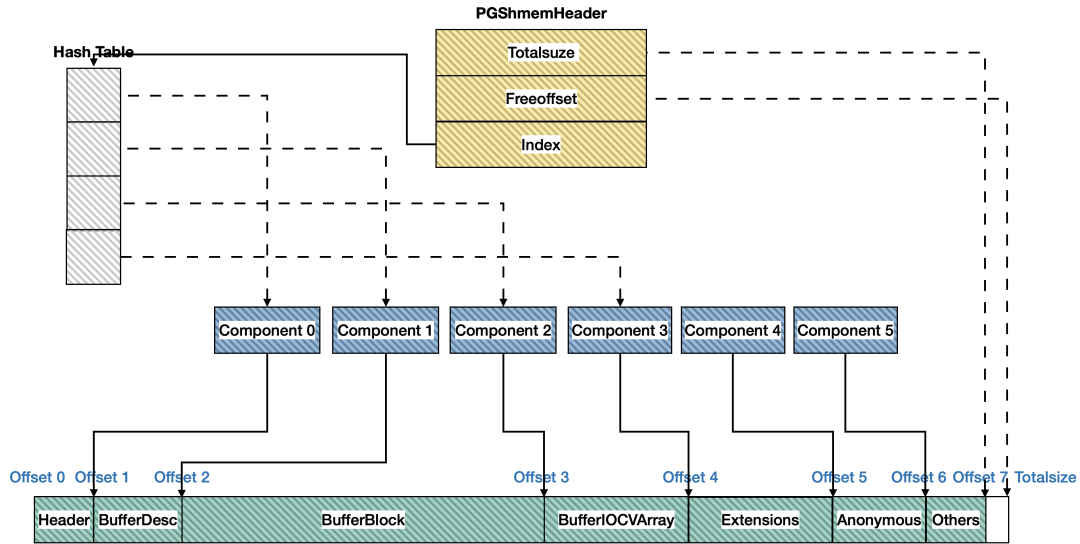
内存在实例启动时就已经申请好了,这里需要按照各个模块的长度进行设置指针偏移。
在数据库内存统计上可以分为三部分:
匿名模块,没有放入hash table统计的,包含LwLock,ProcArray等数据,称为
; 未使用的内存,即totalsize和freeoffset之间的差;
其他通过hash table统计的内存模块,包含buffer pool,extension使用的内存等待;
可以通过视图pg_shmem_allocations查看以上信息:
select * from pg_shmem_allocations;
name | off | size | allocated_size
-------------------------------------+-----------+-----------+----------------
Buffer Descriptors | 5394304 | 1048576 | 1048576
Buffer Blocks | 6442880 | 134217728 | 134217728
Buffer IO Condition Variables | 140660608 | 262144 | 262144
Proc Array | 166767744 | 528 | 640
......
......
......
<anonymous> | | 25406848 | 25406848
| 167577728 | 26744704 | 26744704
(54 rows)复制
进程间的动态共享内存
动态共享内存(DSM/DSA),在代码层次上可以分为三层:
dsm_impl,底层接口调用层,此部分可以通过参数使用mmap,posix,sysv三种方式提供内存段create、attach、detach和destroy操作;
dsm,共享内存段的管理,实际进行内存create、attach、detach和destroy操作,dsm_impl对其是透明的,不感知底层接口;dsm层管理了整个实例的动态共享内存段,提供了实例启动建立元数据内存段和实例正常/异常关闭时的内存段清理接口;
dsa,实际动态共享内存的调用接口,提供变长内存的申请、释放能力。dsm层允许创建和共享共享内存的内存段,但它不适用于处理小对象。DSA区域是一个共享内存堆,通常由一个或多个DSM段支持,可以使用dsa_allocate()和dsa_free()来分配内存。每个DSA区域管理一组DSM段,按需添加新段并在不再需要时分离它们。所有的内存段都由FreePageManager管理,将所有段按照4KB划分。
在实例启动时,建立dsm control segment,并将handle存储到Internal Header。
三种动态共享申请方式
动态共享申请方式可以通过修改参数dynamic_shared_memory_type即可,posix,mmap,sysv,默认值为posix。
三种方式的文件映射位置
PostgreSQL支持mmap,posix,sysv三种共享内存底层接口。多进程架构下的动态共享内存的基础是File-Backed的共享内存形式。通过smaps查看映射的内存文件:
cat proc/299109/smaps | grep PostgreSQL.1564447182
7face6a9a000-7face6aa1000 rw-s 00000000 00:17 12 /dev/shm/PostgreSQL.1564447182
cat proc/301053/smaps | grep SYSV
7f70c839a000-7f70c839b000 rw-s 00000000 00:01 12 /SYSV000c256a (deleted)
cat proc/301109/smaps | grep mmap
7f2f09c9b000-7f2f09ca2000 rw-s 00000000 fd:01 917508 /home/postgres/pgdb14/data/pg_dynshmem/mmap.1111001672复制
Posix,存储在/dev/shm内存文件系统,文件系统tmpfs(size = 50% RAM,huge=off)(这里的huge是指的THP),是内存文件,不会产生I/O;正常关闭时,读取元数据清理内存文件;异常关闭后,重新启动后,可以通过Internal Header找到dsm control handle,读取dsm元数据进行清理动作;
Sysv,存储在/ 目录下,是内存文件,不会产生I/O;正常关闭时,读取元数据清理内存文件;异常关闭后,重新启动后,可以通过Internal Header找到dsm control handle,读取dsm元数据进行清理动作;
Mmap,存储在数据库目录~/data/pg_dynshmem/下,是普通文件,会产生I/O;正常关闭时,读取元数据清理内存文件;异常关闭后,重新启动后,直接清理pg_dynshmem目录进行清理动作;
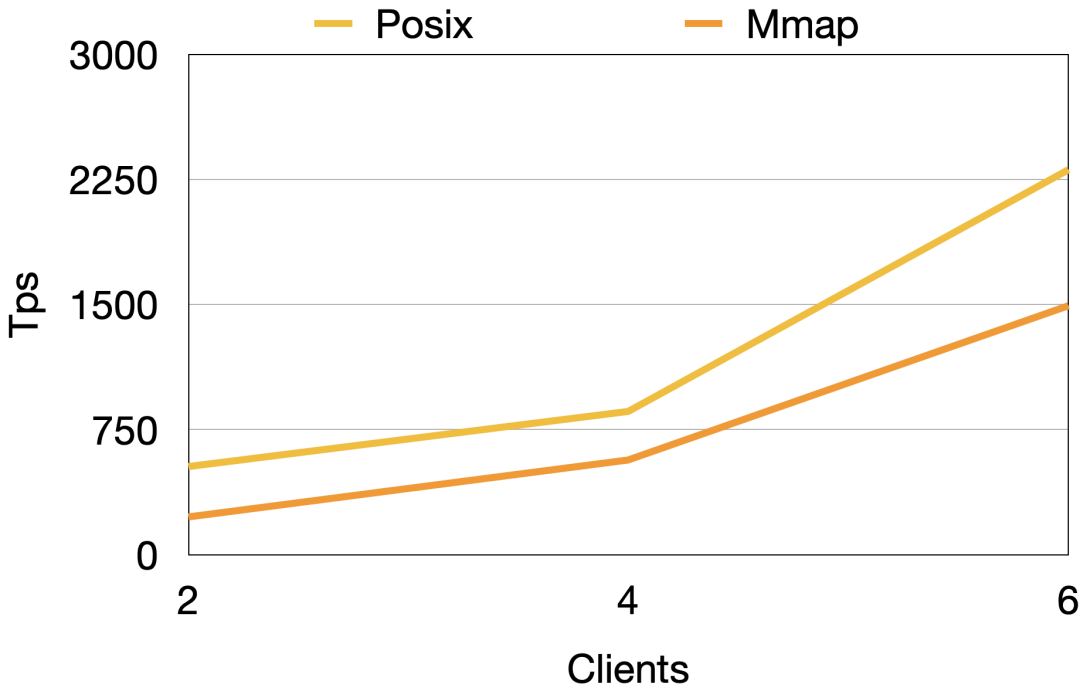
Posix和Mmap的性能对比
handle的获取
既然是File-Backed的共享内存,就需要对应的内存文件。所有的segment的name都是通过随机数设置的。
for (;;)
{
Assert(dsm_control_address == NULL);
Assert(dsm_control_mapped_size == 0);
handle = random() << 1; /* Even numbers only */
if (handle == DSM_HANDLE_INVALID)
continue;
if (dsm_impl_op(DSM_OP_CREATE, handle, segsize,
&impl_private, &address,
&mapped_size, ERROR))
break;
}复制
内存申请策略
DSM/DSA为了能够实现小块内存(即类似1 byte,2 bytes的长度)和变长内存的申请策略,使用了FreePageManager和slab算法实现的。大于8KB的分配请求通过选择一个段并在其自由页面管理器中找到连续的空闲页面来处理。较小尺寸的分配请求使用一组对象池来处理。每个池包含一定数量的16页(64KB)超级块,以与大对象相同的方式分配。大对象和新超级块的分配由单个LWLock序列化,但是从预先存在的超级块中分配小对象使用每个池一个LWLock。当前每个大小类别都有一个池和一个锁。提高并发性的每个核心池和减少结果碎片化的策略是未来研究的领域。每个超级块都使用'span'进行管理,以跟踪超级块的空闲列表。通过查找页面映射以找到地址分配的“span”来处理空闲请求,以便将小对象返回到适当的空闲列表,大对象页面可以直接返回到自由页面映射中。在分配时,选择段和超级块的简单启发式方法尝试集中占用的内存,从而增加整个超级块可以变为空闲状态并返回自由页面管理器,整个段可以变为空闲状态并返回操作系统的可能性。
FreePageManager
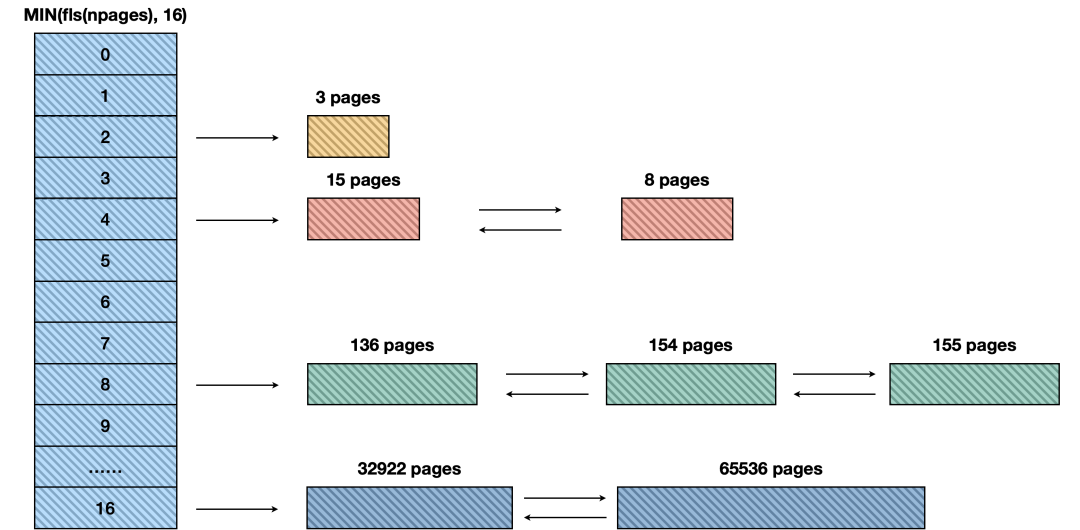
一个FreePageManager跟踪将一个segment按照4KB大小进行划分为多个pages,只能以整个页面为单位进行分配和释放,而且只有在知道其页数的情况下才能释放分配。
由于自由页面管理器只有固定数量的专用内存,并且没有底层分配器,它使用它所拥有的自由页来存储其记帐数据。它维护了多个按照页面运行大小排序的自由列表;每个自由列表的头存储在FreePageManager本身中,每个运行的第一页包含指向下一个运行的相对指针。有关自由列表如何管理的更多详细信息,请参见FreePageManagerGetInternal。
为避免内存碎片,有必要尽可能地合并相邻的页面范围;否则,即使有足够的连续空间,也可能无法满足大的分配请求。因此,通过实现内存中的B树来维护按页号排序的自由页范围。如果正在释放的范围在已有的范围之前或之后,则扩展现有范围;如果它恰好跨越了空闲范围之间的差距,则将两个现有范围与新释放的范围合并为一个巨大的自由页面范围。
slab算法
小内存分配是通过将单个内存块分成许多相等大小的小对象来处理的。可能的分配大小由以下数组定义。较大的大小类别的间隔比较小的大小类别更宽松。我们对大小类别>1kB的间隔进行了处理,以避免空间浪费:基于我们计划分配64kB块的知识,我们将最大对象大小增加到最大的8字节倍数,仍然能将相同数量的对象放入一个块中。
注意:由于这种处理方式,如果我们将来使用不同大小的块用于小内存分配,则需要重新设计这些大小类别,以使其对新大小最优。
注意:对于大小类别的最佳间隔以及分配小对象的块的大小,没有一个正确答案。一些分配器(如tcmalloc)使用比我们这里更紧密间隔的大小类别,而其他一些分配器(如aset.c)使用更宽松的类别。更紧密地间隔大小类别可以避免在单个块内浪费内存,但也意味着可能存在更多未填充的块。
SA中出现了满度( fullness class )这一概念,用来表示一个 superblock 的使用率。满度一共有4个等级,分别用0,1,2,3表示,每一个满度级别表示25%的使用率,因为满度为0表示使用了0-25%的空间,为1表示使用了25%-50%的空间,为3表示全满。
在DSA中,将满度为1的 superblock 称为 active superblock。每一次小内存分配总是会从满度为1的 superblock 链表的头节点中进行分配,具体逻辑详见函数 ensure_active_superblock
。需要注意的是,除了全满的superblock,其余满度并不一定是严格满足的,我们只需要满足当前 superblock 的满度不小于其逻辑上所属的满度即可。
active superblock 是满度类1的 superblock,而不是满度为0的 superblock,这看起来可能有些奇怪,但使用其他分配器的经验表明,通常从适度满的块中分配比从几乎空的块中分配要好。因为那些几乎要空的块很有可能会变为全空(这样我们就可以进行内存回收了)。

两种伪指针
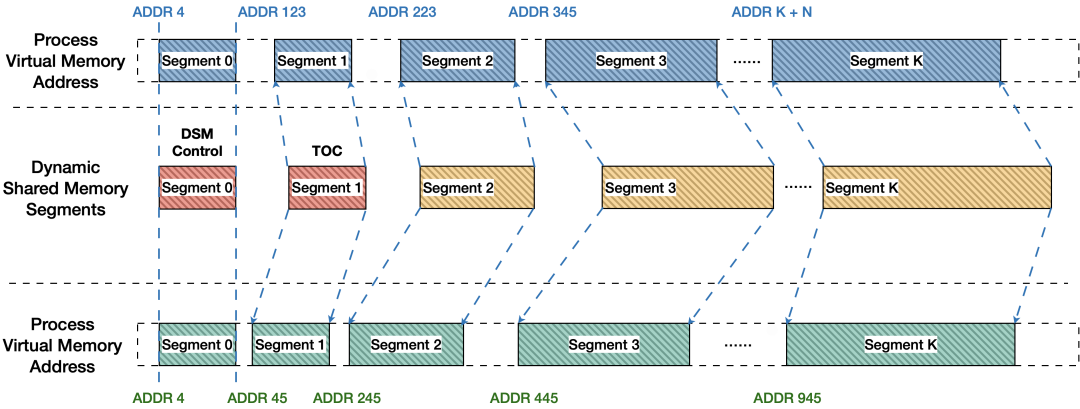
Linux系统为了每个进程提供了独立的虚拟地址,这也使得多进程架构下的PG,每个进程都拥有独立的虚拟地址。并行查询进程的不同进程除了在实例启动时映射的dsm control元数据内存段地址相同外,其他内存段在不同进程映射的地址不保证相同。因此,每个进程都是用结构保存各个segment在本进程映射的起始地址。
/* Backend-local state for a dynamic shared memory segment. */
struct dsm_segment
{
dlist_node node; /* List link in dsm_segment_list. */
ResourceOwner resowner; /* Resource owner. */
dsm_handle handle; /* Segment name. */
uint32 control_slot; /* Slot in control segment. */
void *impl_private; /* Implementation-specific private data. */
void *mapped_address; /* Mapping address, or NULL if unmapped. */
Size mapped_size; /* Size of our mapping. */
slist_head on_detach; /* On-detach callbacks. */
};复制
并行查询进程之间的关系为兄弟进程,而非父子进程,因此无法通过fork继承内存地址,PG提供了shm_toc的机制来存储并行进程间共享的segment信息。每个并行查询建立时都会一个shm_toc的segment。
[root@iZbp1gfz9bu4kbcsfjvip5Z shm]# ll
总用量 10856
-rw------- 1 postgres postgres 26976 7月 23 17:07 PostgreSQL.1437329304
-rw------- 1 postgres postgres 196736 7月 23 17:08 PostgreSQL.803802886
-rw------- 1 postgres postgres 10886144 7月 23 17:08 PostgreSQL.2759238328
[root@iZbp1gfz9bu4kbcsfjvip5Z shm]#复制
(1)dsa_pointer
DSA指针是一种可以跨进程共享的指针,其是一个 uint64 类型的变量。可以使用dsa_get_address方法将一个dsa指针转化为一个本地指针。而构建一个DSA指针的方法如下所示:
/* Build a dsa_pointer given a segment number and offset. */
#define DSA_MAKE_POINTER(segment_number, offset) \
(((dsa_pointer) (segment_number) << DSA_OFFSET_WIDTH) | (offset))复制
可以看出,DSA指针实际上就是一个 segment_number 加上一个offset,根据 segment_number 和 offset 就可以唯一确定一个共享内存的地址。dsa_pointer被dsa.c使用来提供多段相对指针,并在其高bit位上进行 segment index 的编码。
(2)Relative pointer(相对指针)
相对指针用于存储一个地址,该地址可能是相对于进程的地址空间的基址,也可能是相对于其中映射的某个动态共享内存段。
#define relptr(type) union { type *relptr_type; Size relptr_off; }复制
这个宏定义创建了一个联合体,其中包含了一个指向type类型的指针(relptr_type)和一个Size类型的偏移量(relptr_off)。这样做的目的是为了实现相对指针的功能,即将相对于某个内存区域基地址的偏移量存储在一个Size类型的变量中,而不是直接存储一个指针。
通过使用联合体,可以将relptr_off和relptr_type视为同一个存储位置的两个视图。当需要存储一个相对指针时,可以将指针转换为偏移量,并将偏移量存储在relptr_off中。当需要解引用相对指针时,可以将偏移量转换为指针,并将指针存储在relptr_type中。
这种技术的一个优点是,可以将相对指针作为一个类型来处理,而且可以在类型检查时发现相对指针的错误使用。但是,由于使用了联合体,因此必须注意不要同时访问relptr_off和relptr_type,否则可能导致错误的结果。
从上面的定义可以看出来,相对指针实际上就是一个偏移量offset,因为我们的基址是不确定的。相对指针的type信息是为了类型安全,我们从来不会将relptr_type作为一个变量来使用,我们需要的只是 relptr_type 变量的类型 type 用来保证类型安全。
#define relptr_access(base, rp) \
(AssertVariableIsOfTypeMacro(base, char *), \
(__typeof__((rp).relptr_type)) ((rp).relptr_off == 0 ? NULL : \
(base) + (rp).relptr_off - 1))
#else
/*
* If we don't have __builtin_types_compatible_p, assume we might not have
* __typeof__ either.
*/
#define relptr_access(base, rp) \
(AssertVariableIsOfTypeMacro(base, char *), \
(void *) ((rp).relptr_off == 0 ? NULL : (base) + (rp).relptr_off - 1))
#endif复制



