👆 立即咨询 TiDB 企业版 👆

在金融行业数字化转型的浪潮中,TiDB 分布式数据库凭借其卓越的性能和灵活的架构,为金融机构提供了强有力的支撑。
本文将通过杭州银行、某商业银行以及头部银行的创新实践案例,展示 TiDB 分布式数据库的数据模拟环境构建、容器云下 TiDB 的架构设计以及 TiDB 在多集群数据路由和联邦查询等方面的应用。这些案例充分体现了 TiDB 在解决金融行业数据管理难题、提升业务效率和保障数据安全方面的重要价值,助力金融机构在数字化转型的道路上更进一步。
杭州银行:分布式场景下快速构建
数据模拟环境的探索与实践
01
传统的数据准备挑战及对策

常用方案挑战:分布式数据库数据准备测试场景中,常用两种方案:一是基于数据还原和日志前滚,即先还原生产环境备份数据,再应用变化日志,最后脱敏处理。但需跨网络域操作、手工还原日志,步骤繁琐、可靠性差,恢复时间长,难以快速多次模拟目标。二是基于准实时逻辑复制,搭建逻辑复制库同步数据,需求来时停止同步、脱敏、启用读写模式。不过,违反网络域隔离,重新准备数据要初始化逻辑复制库,操作耗时,同样不能快速多次模拟目标。
应对策略:杭州银行用存储快照方案提升数据模拟环境构建效率,创建生产存储数据卷快照并挂载至其他节点,提供便捷、快速的快照数据环境。因分布式数据库属 Share Nothing 架构,生产集群使用本地 NVME 盘无法快照映射,银行在生产环境部署集中式存储的分布式数据库复制集群,配置单副本,从生产集群逻辑复制数据至复制集群,数据需求时创建可写快照映射给镜像快照集群并启动。该方案隔离快照任务影响,减少数据容量需求,实现生产数据单向摆渡、网络域隔离,存储快照数据实时性强、操作便捷,基于数据库逻辑复制和集群数据闪回特性确保数据一致性和完整性。
02
数据模拟环境落地方案
准备复制集群阶段:在生产环境,集中式存储分配 LUN 给复制集群,配置“一致性组”,创建 LVM VG 及条带LV存放用户数据。部署用主机名或域名,模拟测试配置单副本节省空间、提升性能。搭建复制链路,实时同步并开启 Syncpoint 检查点,满足长时间历史回溯需求时,确认数据版本和事务号记录期限符合业务需要。
创建镜像快照集群阶段:在数据持续复制过程中,生产环境存储创建“一致性组”可写快照映射给镜像快照集群节点,首次需恢复数据库集群的 Systemd 服务等信息。若有历史回溯需求,确认存储只读快照保存期限。快照挂接后,启动镜像快照集群,读取最新事务号并执行 Flashback Cluster 操作。
环境准备操作阶段:在恢复到数据一致性事务号后,该阶段将进行数据库用户密码重置,完成数据脱敏作业,以及配置业务字典数据,同时进一步按需扩展计算节点。
模拟环境重置阶段:夜间任务后,镜像快照集群节点停止服务并卸载磁盘,视需求重复操作。杭州银行利用集中式存储单副本分布式逻辑复制集群,快速构建数据模拟环境,满足数据一致性和时效性要求,保障数据安全。脚本嵌入作业平台,支持日间模拟夜间任务和生产报文回放,预知生产环境问题。未来,引入 CDM 技术,推动数据副本技术应用,提升业务价值。
点击此处丨阅读原文
商业银行基于容器云的分布式
数据库架构设计与创新实践
01
项目背景
某商业银行新一代金融云建设,选定 TiDB 分布式数据库集群上云应用系统超 100 个,覆盖银行多个重要业务领域,需两地三中心部署、同城双活,满足高可用和灾备要求。原私有部署需 300-600 台物理机,亟需建立低成本、便捷的 TiDB 云化平台支持服务体系,降低部署、测试、运维成本。
目前业内主流的 OP(私有)TiDB 部署方案,基于独立物理服务器,存在以下问题:
数据库使用成本高
单独为业务系统建设数据库,不符合成本效益,同时形成多个数据孤岛;同时带来资源利用率低问题
业务上线、变更速度慢
运维管理难度高
02
分布式数据库云化架构目标
TiDB + TiDB Operator 适配 K8s 联邦集群,提供金融级高可用数据支撑;实现同城及两地三中心高可用;
基于 TiDB Operator,构建集群运维管理功能,涵盖部署、扩缩容、备份恢复、参数变更、监控告警等全生命周期管理;
TiDB 云平台具备在各种物理资源上融合部署能力,大幅节约整体使用成本。
03
整体架构
基于上述要求,TiDB 云化建设整体架构:
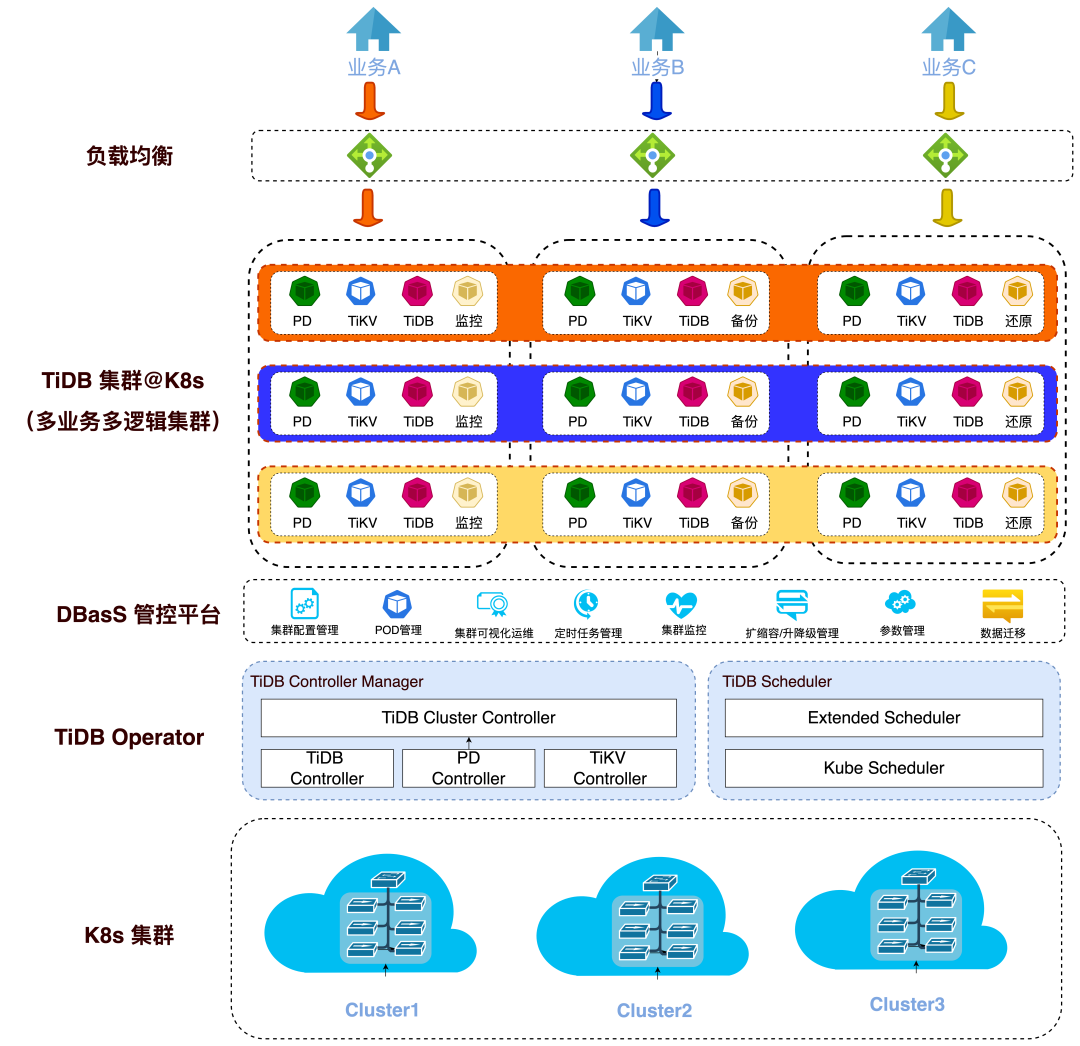
整体设计特点:
系统底座构建在支持跨 Region 的 K8s 集群服务上。
增强 TiDB-Operator,提升 Pod 独立生命周期管理和在线扩容能力,新增 IP 固定特性。
DBASS 管控平台为云用户、运营、运维、开发人员提供 TiDB 云平台可视化管理、运维、监控及开发测试任务:
提供 TiDB 资源池,按需供给各类规格的 TiDB 逻辑集群,实现多业务隔离和资源利用率提升。
04
挑战
基于 K8s+Operator 构筑数据库容器化方案落地过程中,将会面临以下几方面技术难度:
K8s 灾备能力:从近期云厂商多起重大故障来看,冗余的 K8s 集群可用性远高于单一K8s集群,需要有效利用多 K8s 集群技术;
TiDB 高可用部署:TiDB 数据库需要保障 K8s 集群下数据一致和高可用;
多业务隔离能力:需要满足该银行业务体量,支持小库归集、多业务隔离部署和资源隔离能力要求;
存储:容器的分布式存储不适用于数据库,需提供满足数据冗余和 DB IO 性能的存储方案;
运维便捷性:原生 K8s 主要针对 CI/CD 应用,对数据库运维支撑不足。方案需降低运维成本,无缝对接现有数据库运维生态及工具。
05
解决方案
K8s 灾备能力:K8s 集群采用联邦集群技术在单数据中心部署 3 套集群,解决单点故障。主集群统一管理成员集群资源,成员集群仅访问自身资源。
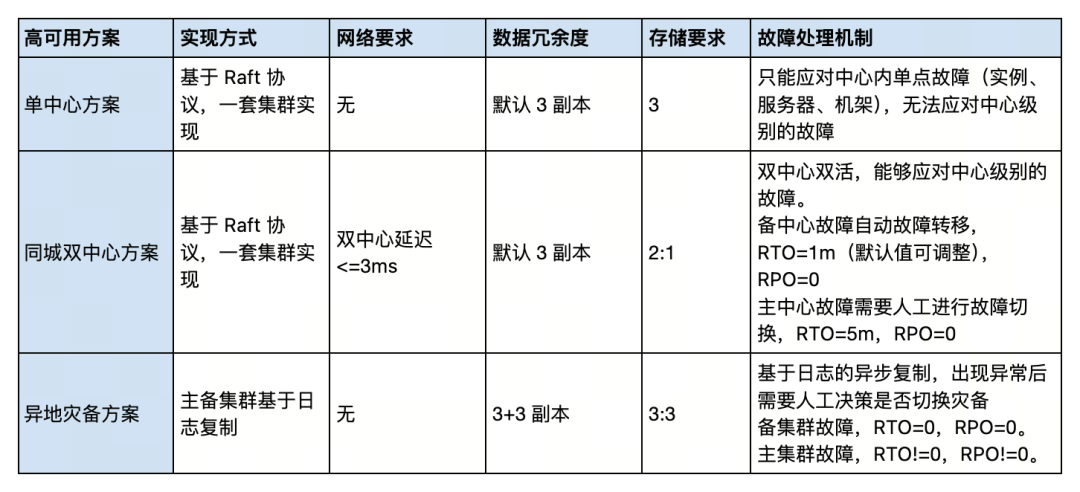
TiDB 高可用部署:根据业务重要程度,该商业银行对应用项目有 A/B/C 三种分类,其中,重要等级为 B/C 类的应用项目,可采用单中心方案。重要等级为 A 类的应用项目,可采用同城双中心+异地灾备部署方案;部分高等级 B 类系统,可采用同城双中心(不需要提供异地灾备)。高可用方案能力总结如下:
多业务隔离能力:在 TiDB 云化平台上,利用 K8s 命名空间和资源配额实现业务资源隔离,通过节点选择、污点容忍度、亲和/反亲和等调度能力,解决 TiDB 计算和存储服务混合部署时的干扰问题。
存储:为保障数据库容器的磁盘 IO 和吞吐量,系统设计提供两种方案:一是开源云原生存储,但依赖网络资源;二是本地存储 LocalPV,虽数据冗余保护不足,但性能高。考虑到 TiDB 的 TiKV 服务自动维护多副本、采用 Multi-Raft 架构,支持高可用和自动故障转移,最终选择本地存储方案,实现 TiDB 云化持久化,兼顾数据高可用性和存储成本优化。
06
运维便捷
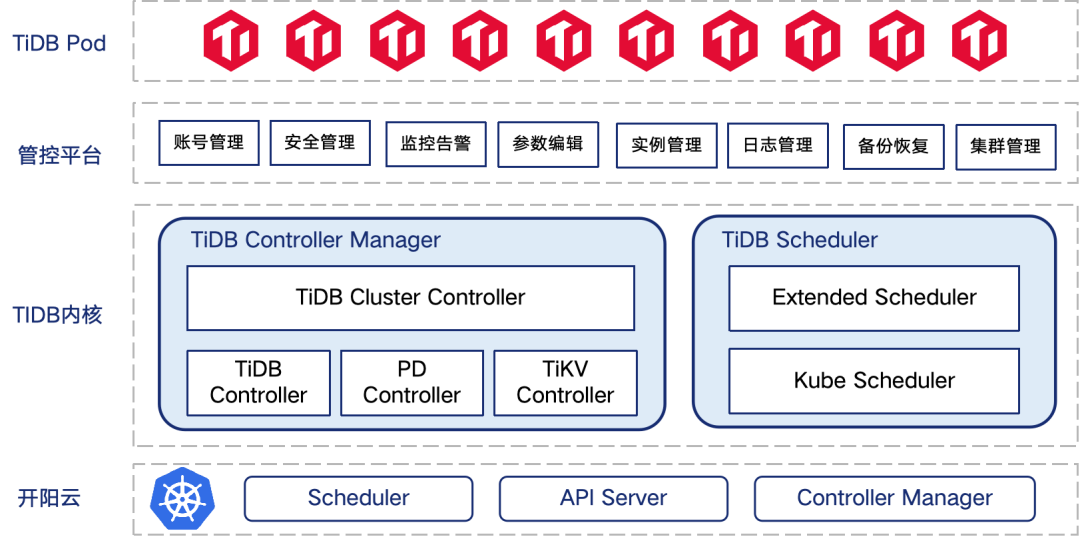
分钟级部署 TiDB,支持单中心、同城双中心、两地三中心等多种模式;保证应用程序在开发、测试和生产环境中运行一致;
运维全可视化操作,简单直观,有效减少人为运维失误;
无缝对接行内现有容器化 TiDB 集群、TiDB 远程容灾、TiDB 镜像管理平台、TiDB 数据库管理等平台。
07
系统收益
验证了分布式数据库 + 容器云的创新方案,一套 TiDB 集群支持多个业务,简化技术栈;
充分利用 K8s 和 TiDB 架构特点,实现了金融业务在容器平台的高可用;
解决了运维自动化能力建设的瓶颈,实现自动化运维,为将来智能化运维奠定基础;
较 OP 部署模式,数据库部署硬件资源节约 80% 以上;解决了传统部署模式下总体拥有成本高、资源利用率不高、部署密度低等问题;
解决了传统虚拟化部署产生的基础环境不稳定、不支持资源弹性伸缩及 Pod 是否高效稳定运行有状态类应用等问题。
点击此处丨阅读原文
基于时间维度水平拆分的多 TiDB 集群统一数据路由/联邦查询技术的实践
01
需求背景
某头部银行客户交易明细查询场景覆盖 2014 年至今,数据规模达单副本 500TB,日均增量超 1 亿。为提升业务敏捷性,选择 TiDB 分布式数据库,具备高可用、高并发、易扩展等能力。
TiDB 通过多副本+Multi Raft 协议实现可用性与性能平衡,副本数至少 3 个,部分业务需 5 副本。面对大数据规模,数据架构按交易时间水平拆分,不同集群对应不同资源规格和副本数,通过应用层数据路由和联邦查询组件实现跨库 SQL 访问。
02
整体设计与选型策略
该案例的跨库访问场景涵盖了银行领域该类场景的所有业务。梳理后共包括以下几类访问模式:
按时间路由-分页追加归并:根据查询时间范围和分页信息定位集群,跨集群追加归并结果集,处理数据散落、跳页等复杂场景,降低多集群 IO 影响;
按时间路由-汇总归并:针对实时收支分析等汇总查询,按查询时间范围确定集群范围,将多个集群结果在归并模块中按分组条件汇总;
轮询路由-追加/汇总归并:对于单笔/多笔查询、修改,按非交易时间字段轮询集群,遍历所有记录,查询类追加归并结果,修改类汇总归并。
在场景分类的基础上,还需要结合集群间数据生命周期管理策略的要求进一步细化相关设计:
集群拆分和容量规划:将 TiDB 数据按热度分为热、温、冷三类集群,热集群存储最近一年数据,温集群存储一年前至特定年份少量数据,冷集群存储更长时间数据。仅热、温集群间进行数据转储 ETL 作业,简化管理运维,热集群容量稳定,温集群预留扩展空间;
集群间数据冗余设计:热、温集群 ETL 作业存在时延,为避免客户查不到数据,引入名义时间、冗余时间、实际时间概念。热集群名义最小时间为 [now - 365d],冗余时间设为 1 天,实际存储服务最小时间为 [now - 365d - overlapping],温集群服务最大时间也为此值,合理冗余时间可覆盖 ETL 边界场景。
该案例业务复杂,涉及多种维度组合,技术上需灵活数据分片和冗余。传统数据路由组件难以满足定制化需求且维护成本高,故采用自研轻量级数据路由 SDK 组件。
03
核心技术实现
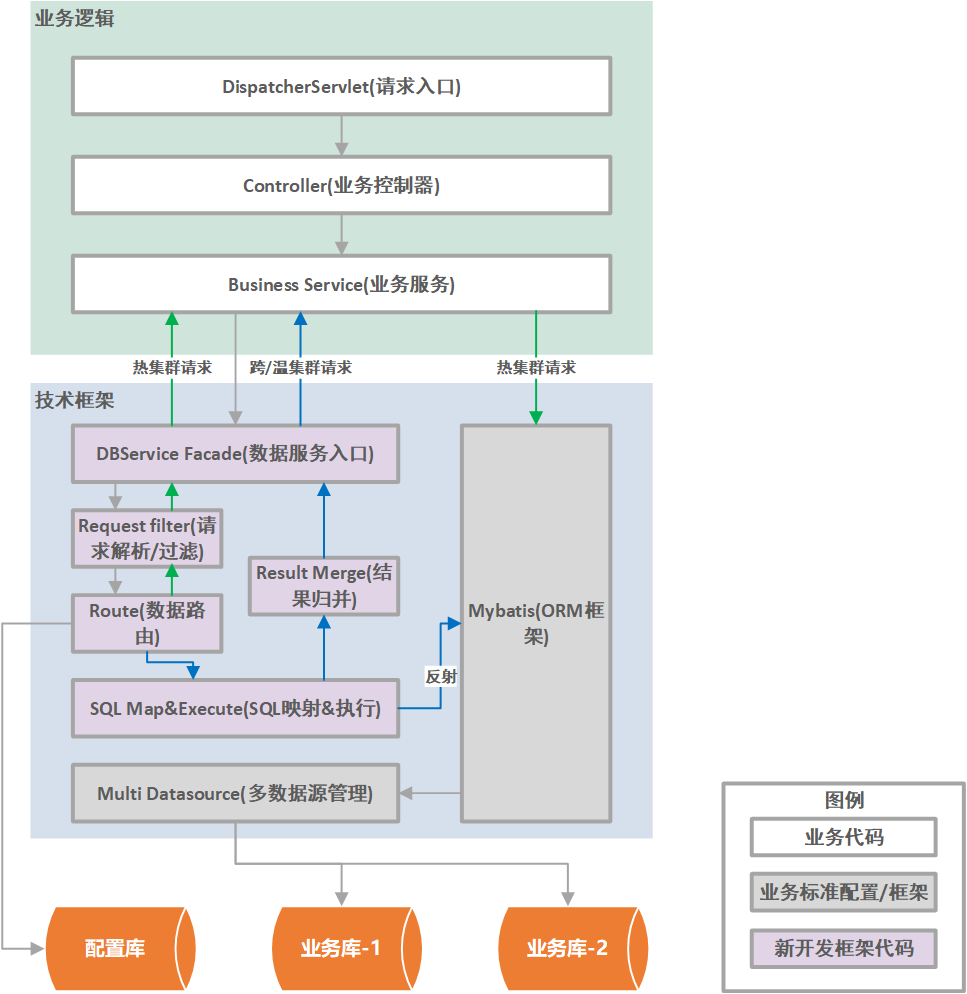
整体逻辑架构包括了应用框架、业务代码、以及以 jar 包形式集成在应用框架和业务代码中的数据路由 SDK。各部分简要说明如下:
应用框架:基于现有开发框架(如 Spring Boot)增加多数据源配置,包括多个集群的 Spring Bean 定义、以及继承 spring-jdbc AbstractRoutingDataSource 抽象类并实现 determineCurrentLookupKey 方法以提供多数据源的切换能力;
业务代码:ORM 框架 SQL 预留动态参数供路由组件改写,调用方式改为路由组件入口方法。仅访问热集群或无需改写 SQL 参数时,直接执行原始 ORM 操作。跨集群时,路由组件反射调用 Mybatis mapper 业务 SQL,处理结果后返回;
路由组件
配置管理:包括参数配置和路由配置,基于应用框架文件定制化设置启用状态、数据源、事务管理器、重试、SQL 打印、特殊查询阈值、路由热更新等,同时设定集群日期范围、类型、排序顺序、版本信息等,启动时加载至 JVM 内存,版本变更触发热更新;
动态路由解析:采用两段式,第一段根据业务类型、查询日期范围确定涉及集群,第二段热集群透传回调原始 SQL,多集群场景结合业务类型、时间排序等因素;
多数据源 SQL 执行:热集群透传回调原始 SQL,多集群按排序在各集群执行 SQL,改写参数、切换数据源,通过反射执行,非查询类场景涉及事务管理,个别 DML 操作未用分布式事务,结果集按集群追加合并;
结果集归并:分页查询简单场景顺序追加,复杂场景按排序字段重排序,用插入排序;聚合查询中,sum、count 等算子汇总比较,avg 算子先累加 sum、count,再计算平均值;单笔/多笔操作时,单笔无需归并,多笔场景追加或汇总归并。
04
总结与展望
该组件与 TiDB 结合,实现超大规模数据管理,支持多维度灵活访问,平衡集群关键指标,提升扩展能力,未来可进一步优化提升。
点击此处丨阅读原文
点击进入金融专区!
与 PingCAP 一同打造创新的金融数据基础平台,
加速数字化和智能化转型!