





👆 立即咨询 TiDB 企业版 👆

本文通过两个例子,介绍了如何利用 PingCAP 开源项目 AutoFlow 实现从部署到配置的完整流程,包括数据库连接、模型设置、知识库创建及聊天引擎配置,实现一行代码不用写的问答机器人快速搭建,让开发者能够轻松上手并快速探索智能问答解决方案,为构建本地知识库问答机器人提供有力支持。
基于 AutoFlow 快速搭建与TiDB 向量搜索
的本地知识库问答机器人
背景知识
AutoFlow 是 PingCAP 开源的一个基于 Graph RAG、使用 TiDB 向量存储和 LlamaIndex 构建的对话式知识库聊天助手。https://tidb.ai 也是 PingCAP 基于 AutoFlow 实现的一个 TiDB AI 智能问答系统,我们可以向 tidb.ai 咨询任何有关 TiDB 的问题,比如 "TiDB 对比 MySQL 有什么优势?"

基于 TiDB 实现问答系统的基本流程
在技术实现上,tidb.ai 背后主要使用到 TiDB 的 Graph RAG 技术、TiDB 向量检索功能以及 LLM 大模型的使用。实际上,在 AutoFlow 出来之前,我们也可以通过 python 编程开发的方式基于 LLM+RAG+TiDB 实现一套问答系统。主要的开发流程如下:
准备私域文本数据
对文本进行切分
通过 Embedding 将文本转为向量数据
把向量数据保存到 TiDB
获得用户输入问题并进行向量化,然后从 TiDB 中进行相似度搜索
将上述片段和历史问答作为上下文,与用户问题一起传入大模型,最后输出结果
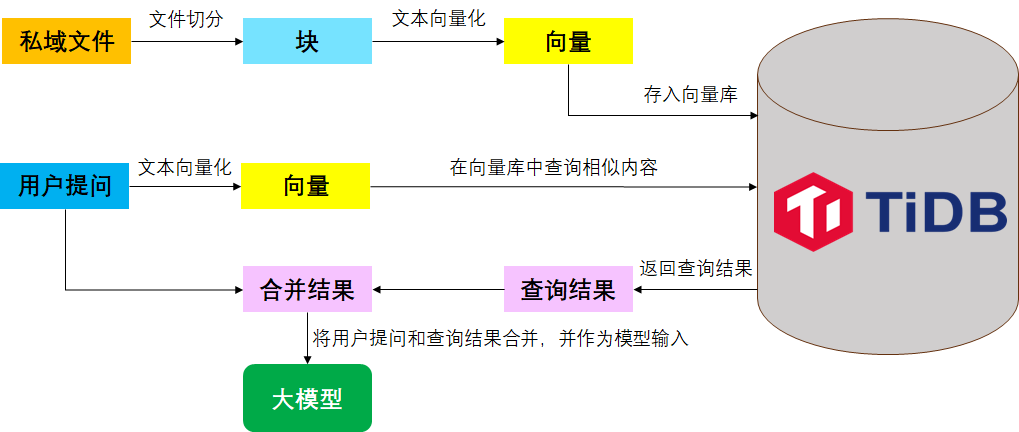
基于 AutoFlow 搭建本地知识库问答系统
用 Python 开发问答系统时,一般需要结合大模型常用开发框架如 Langchain,可导入多种文件和网址。若想增加 Web 界面,需引入 Gradio 或 Streamlit 等前端工具。不过,使用开源的 AutoFlow,即使没有开发背景,也能轻松搭建问答系统。以下将演示具体搭建过程。
环境准备
Docker 环境:需要确保 AutoFlow 运行的机器上具备 Docker 运行环境,因为 AutoFlow 项目中的应用是基于 docker 容器环境运行的。
AutoFlow 项目:AutoFlow 是一个开源的 github 项目,地址为 https://github.com/pingcap/autoflow。下载之后需要在 AutoFlow 根目录下配置相关信息,包括 TiDB 数据库连接信息、EMBEDDING 维度等。
带向量功能的 TiDB 环境:TiDB 最新发布的 v8.4 版本,支持向量搜索功能(实验特性)。向量搜索是一种基于数据语义的搜索方法,可以提供更相关的搜索结果。有关 TiDB 向量搜索功能,参考https://docs.pingcap.com/zh/tidb/v8.4/vector-search-overview 。
智谱 AI API Key:注册并登录智谱 AI 平台 https://bigmodel.cn/,在个人中心->API kys 添加新的 API Key 并复制保存。注意,如果免费创建的用户已经超过一定的时效期限,API Key 将是无效的。
数据初始化
运行数据迁移以创建所需的表并创建初始管理员用户。

当看到如上输出结果时,说明初始化这一步已经成功(注意保存好红色字体中的密码以备后面使用)。这时我们去 TiDB 数据库中查看,发现 tidbai_test 这个库中已经自动创建出了相应的表并有一些初始化数据,符合预期。
启动知识库应用
运行 docker compose 命令启动知识库应用程序。
网页访问和配置知识库应用
应用启动成功后,我们可以直接通过默认的 3000 端口访问相应的界面进行下一步操作了。使用默认管理员用户 admin@example.com 以及上述应用启动打印的密码进行登录。
登录成功后,会弹出提示框,后面我们只要按照提示框一步步进行相应配置即可。
配置 LLM
配置 Embedding 模型
配置数据来源
查看索引创建进度
体验智能问答
至此,我们已经完成了配置数据源并完成了向量化存储及向量索引的创建。在网页的左侧菜单栏中,我们可以点击 Datasources 查看当前数据源, LLMs 查看当前 LLM,Embedding Model 查看 Embedding 模型。
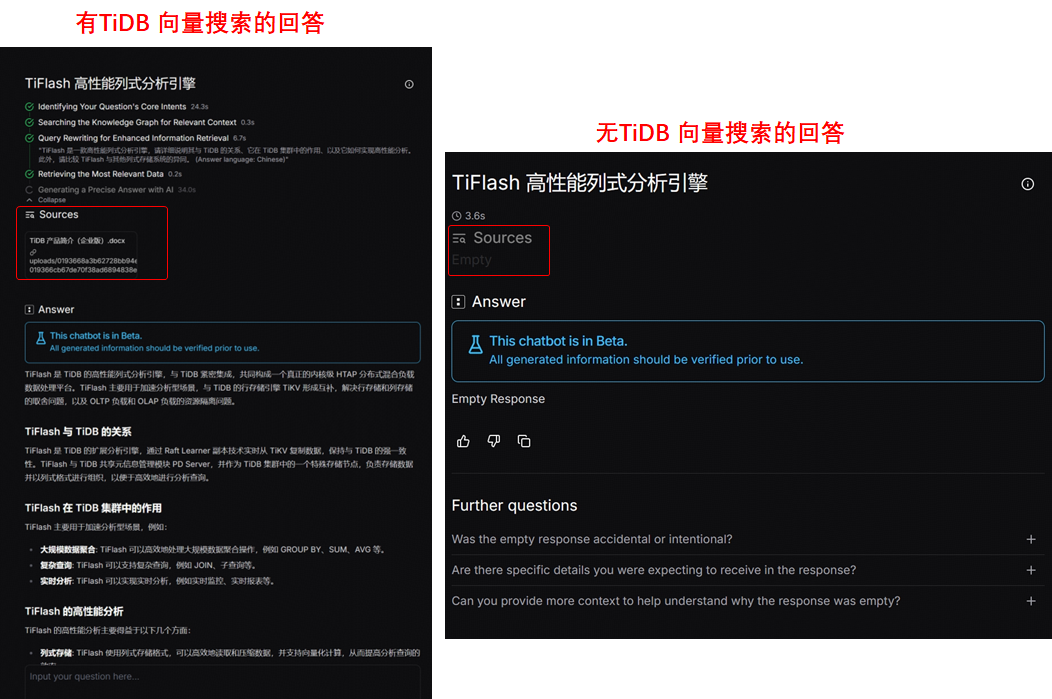
我们现在也可以开始向自己搭建的 tidb.ai 咨询有关 TiDB 的问题了,比如提问 "TiFlash 高性能列式分析引擎"。从结果可以看出,本地知识库问答机器人引用导入的文档并作出了相似回答,而假如我们删除数据源之后再提出相同的问题,它的回答是 Empty Response。
下图对比充分说明了 TiDB 向量搜索在基础 LLM 大模型的增强能力。
点击此处丨查看原文
一行代码不用写,用 Autoflow + Gitee AI
搭建本地知识库问答机器人
准备工作
Docker Compose
AutoFlow 的部署和使用需要 Docker Compose,未安装的开发者请在部署 AutoFlow 前准备好 Docker 环境。
TiDB Cloud Serverless
由于在部署 AutoFlow 时需要配置 TiDB 数据库,开发可选择 v8.4 版本以上的 TiDB 数据库(支持向量搜索功能),或和马建仓一样直接选择 TiDB Cloud Serverless ,可以快速实现数据库的部署。
Gitee AI 访问令牌
AutoFlow 可通过 API 的方式调用模型提供方的模型,所以需要准备好 Gitee AI 访问令牌供配置 AutoFlow 时使用。前往 工作台 - 设置 - 访问令牌 ,点击新建访问令牌,选择对应的资源包即可(马建仓这里推荐全模型资源包)。
AutoFlow 部署
克隆项目到本地
复制并编辑 .env 文件
迁移数据库架构
使用初始数据引导数据库
启动服务
打开浏览器访问 http://localhost:3000 即可访问部署好的 AutoFlow 服务。
AutoFlow 配置
大语言模型配置
在左侧管理选项中选择 Models - LLMs ,点击 + NEW LLM ,为要使用的大语言模型起一个名字,并选择 Gitee AI 为模型提供方。选择后,会自动选择使用的大语言模型(默认为 Qwen2.5-72B-Instruct ),开发者只需在 Gitee AI API Key 处填入刚才生成的 Gitee AI 访问令牌,点击 Creat LLM 即可。
向量模型配置
和配置大语言模型的流程相似,选择 Models - Embedding Models 后进行相同的设置即可。
知识库配置
模型相关信息配置完成后就可以进行知识库的配置了,选择左侧 Knowledge Bases ,填写知识库名称及描述,选择刚才创建的大语言模型和向量模型后即可创建知识库。
创建完成后,我们就可以创建数据源了,AutoFlow 支持本地文件、网页、Sitemap 三种数据源。
AutoFlow 支持上传 Markdown 、 PDF 、 Word、 PPT 、 Excel 、 TXT 文件,上传完成后点击 Creat 即可创建数据源。
创建知识库后进行的是建立知识库索引的工作,AutoFlow 会自动完成这部分工作, Vector Index 显示全为绿色时即为索引建立完成。
聊天引擎配置
最后一步,我们需要配置聊天引擎(Chat Engine)。点击 Chat Engines - New Chat Engine 即可进入下图页面。在聊天引擎配置中,必须配置项为名称、使用的大语言模型以及所连接的知识库。
配置名称及模型
至此,一个简单的基于本地知识库的问答机器人就部署完成了。完成配置后,可进入 Settings 为你的问答机器人进行个性化设置,设置自己的网页标题、Logo、预设提问等等。
点击此处丨查看原文
👇 立即咨询 TiDB 企业版 👇
