




DeepSeek开发者为杭州深度求索人工智能基础技术研究有限公司,成立于2023年7月,由宁波程恩企业管理咨询合伙企业和梁文锋共同持股。梁文锋是金融圈成名已久的高手,其创立的幻方量化为国内量化私募巨头之一。2023年5月梁文锋宣布要做通用人工智能,7月DeepSeek成立,专注于AI大模型的研究与开发。
DeepSeek之所以能火爆AI圈,主要来自于两个方面:
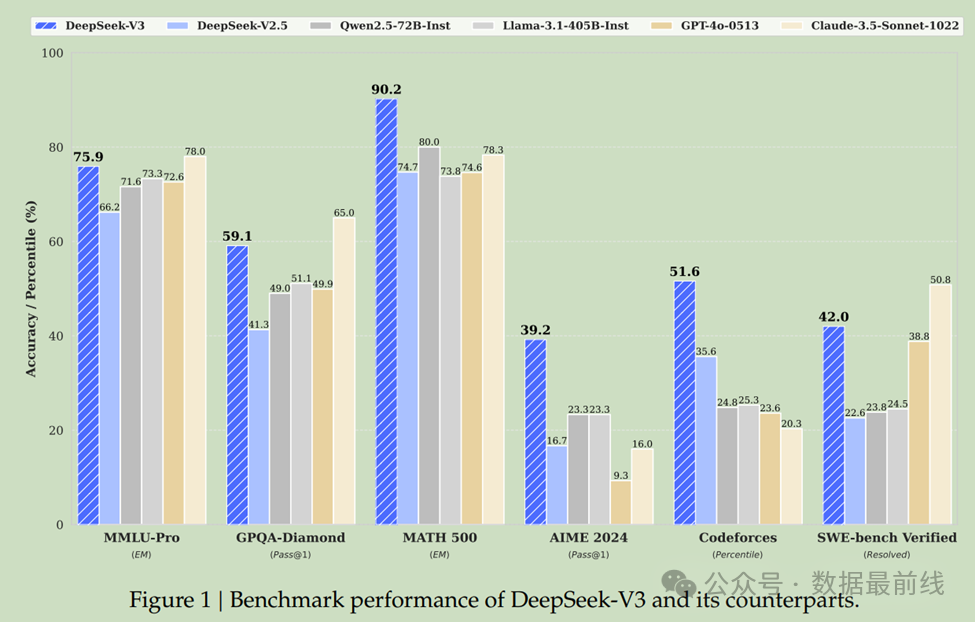
开源且强大的推理模型
2024年5月,DeepSeek发布DeepSeek-V2开源MoE模型,以其高效的性能在全球AI界掀起了一波热度; 2024年12月,仅过了7个月DeepSeek-V3发布,不仅在性能上超越了主流开源模型,还与世界顶尖的闭源模型不相上下; 2025年1月,DeepSeek发布了推理模型DeepSeek-R1正式版,在数学、代码、自然语言推理等多个关键领域展现出了令人惊叹的实力,能与OpenAI o1正式版比肩。并且同步开源模型权重,允许用户利用模型输出、通过模型蒸馏等方式训练其他模型。R1版本的推出,在海外被惊呼“这才是真正的开放的人工智能”。
DeepSeek-R1发布后不久,便登顶苹果中国地区和美国地区应用商店免费APP下载排行榜,超越了ChatGPT。
史无前例的性价比
早在DeepSeek-V2发布时,DeepSeek便拉起了行业内的价格战,其推理成本被降到每百万token仅1块钱,约等于Llama3 70B的七分之一,GPT-4 Turbo的七十分之一。
而DeepSeek V3的API定价为输入每百万tokens 0.5元(缓存命中)/2元(缓存未命中),输出每百万tokens 8元,与字节Doubao-pro-256k定价输入每百万tokens 5元,输出每百万tokens 9元的水平相当,在国产模型中性价比继续提升。
极致的性价比来自于DeepSeek创新的训练方法大大降低了训练成本,DeepSeek V3是一个拥有671B参数的MoE模型,训练总共才用了不到280万个GPU小时,而Llama 3 405B却用了3080万GPU小时。用训练一个模型所花费的成本来说,训练一个DeepSeek V3只需要花费557.6万美元,相比之下,一个简单的7B Llama 3模型则需要花费76万美元。

这也让业界普遍认为未来对GPU的需求将大大下降,全球算力板块应声下跌,甚至将DeepSeek称为“英伟达最大的空头”,以一己之力带崩美股科技板块,其影响力可见一斑。
写在最后
DeepSeek火出圈正值中国农历春节来临之际,全国人民在欢度新春佳节的同时,也深深为我国科技界取得的成就而自豪。
DeepSeek的火爆缓解了国内产业界人士的焦虑,提振了信心,未来对抗国际AI技术霸权时,DeepSeek必将是中国大模型技术复仇者联盟中的重要成员; DeepSeek的成功是通过出其不意的技术创新和独特的算法架构实现的,特别是在高端芯片受限的情况下,利用优化算法设计和资源分配,显著降低了训练成本,性能却与国际上最先进的模型想媲美,展示了中国在技术创新方面的韧性和潜力; 开源的DeepSeek允许全球开发者自由修改、使用和分发模型,为全球AI社区提供了新的研究和发展机会,向全世界展现了中国AI力量。
评论

 0 点赞
0 点赞 0 点赞 0 点赞
0 点赞 0 点赞 0 点赞
0 点赞 0 点赞 0 点赞
0 点赞 0 点赞


