蛇年新气象,祝各位运维人开工大吉!作为开年技术首秀,今天我们要揭秘一个非常实用的运维数据联合分析技能:如何用 GreptimeDB 打通指标与日志分析,开启实时智能监控的"上帝视角" !
作为新一代云原生时序数据库,GreptimeDB 能统一处理指标(Metric)、日志(Log)、事件(Event)和追踪(Trace)数据,从边缘到云端,帮助企业实时获取数据洞察。自去年升级的 v0.9 版本起,全新日志管道功能正式出道!不仅支持日志搜索,还优化了自带的智能视图和数据流,完全具备了企业级事件分析的应用能力。
本文将以微服务监控中最棘手的 RPC 服务为实战场景,手把手教你如何用 SQL 联合分析指标与日志数据,并构建智能实时告警链路。
💡 实战装备清单:
本地部署:GreptimeDB,GitHub 五分钟极速安装: https://github.com/GreptimeTeam/greptimedb/releases/tag/v0.11.3 云端体验:GreptimeCloud 免费版 (无需信用卡一键注册使用) SQL 运行客户端:MySQL 客户端 GreptimeDB 内置 Dashboard
接下来,让我们一起开启今天的演示,探索 GreptimeDB 的强大功能吧!
步骤 1:创建请求指标表
首先,创建一个请求指标表:
create table app_metrics (
ts timestamp time index,
dc string,
host string,
latency double,
primary key (dc, host)
);
ts
:指标采集的时间戳。dc
:数据中心名称。host
:应用服务器主机名。latency
:RPC 请求延迟。
其中,dc
和 host
作为主键和标签语义类型。
步骤 2:创建应用日志表
接下来,创建应用日志表:
create table app_logs (
ts timestamp time index,
host string,
dc string,
`path` string,
`error` string FULLTEXT,
primary key (dc, host)
);
ts
:日志时间戳。host
:应用服务器主机名,与app_metrics.host
相同。path
:RPC 请求的 URL 路径。error:日志错误信息,启用了 FULLTEXT
选项以支持日志搜索。
其中,主键与 app_metrics
表相同。
步骤 3:插入模拟数据
接下来,插入一些模拟数据,以模拟采集的指标和错误日志。这些数据模拟了请求延迟的变化,包括正常范围内的延迟和异常高的延迟。
INSERT INTO app_metrics (ts, dc, host, latency) VALUES
('2024-07-11 20:00:00', 'dc1', 'host1', 100.0),
('2024-07-11 20:00:01', 'dc1', 'host1', 100.5),
('2024-07-11 20:00:02', 'dc1', 'host1', 101.0),
('2024-07-11 20:00:03', 'dc1', 'host1', 101.5),
('2024-07-11 20:00:04', 'dc1', 'host1', 102.0),
('2024-07-11 20:00:05', 'dc1', 'host1', 102.5),
('2024-07-11 20:00:06', 'dc1', 'host1', 103.0),
('2024-07-11 20:00:07', 'dc1', 'host1', 103.5),
('2024-07-11 20:00:08', 'dc1', 'host1', 104.0),
('2024-07-11 20:00:09', 'dc1', 'host1', 104.5),
--- 请求的延迟开始变得不稳定并明显增高。
('2024-07-11 20:00:10', 'dc1', 'host1', 150.0),
('2024-07-11 20:00:11', 'dc1', 'host1', 200.0),
('2024-07-11 20:00:12', 'dc1', 'host1', 1000.0),
('2024-07-11 20:00:13', 'dc1', 'host1', 80.0),
('2024-07-11 20:00:14', 'dc1', 'host1', 4200.0),
('2024-07-11 20:00:15', 'dc1', 'host1', 90.0),
('2024-07-11 20:00:16', 'dc1', 'host1', 3000.0),
('2024-07-11 20:00:17', 'dc1', 'host1', 320.0),
('2024-07-11 20:00:18', 'dc1', 'host1', 3500.0),
('2024-07-11 20:00:19', 'dc1', 'host1', 100.0),
('2024-07-11 20:00:20', 'dc1', 'host1', 2500.0),
('2024-07-11 20:00:21', 'dc1', 'host1', 1100.0),
('2024-07-11 20:00:22', 'dc1', 'host1', 2950.0),
('2024-07-11 20:00:23', 'dc1', 'host1', 75.0),
('2024-07-11 20:00:24', 'dc1', 'host1', 1550.0),
('2024-07-11 20:00:25', 'dc1', 'host1', 2800.0);
--- 异常 log 数据开始出现
INSERT INTO app_logs (ts, dc, host, path, error) VALUES
('2024-07-11 20:00:10', 'dc1', 'host1', '/api/v1/resource', 'Error: Connection timeout'),
('2024-07-11 20:00:11', 'dc1', 'host1', '/api/v1/resource', 'Error: Database unavailable'),
('2024-07-11 20:00:12', 'dc1', 'host1', '/api/v1/resource', 'Error: Service overload'),
('2024-07-11 20:00:13', 'dc1', 'host1', '/api/v1/resource', 'Error: Connection reset'),
('2024-07-11 20:00:14', 'dc1', 'host1', '/api/v1/resource', 'Error: Timeout'),
('2024-07-11 20:00:15', 'dc1', 'host1', '/api/v1/resource', 'Error: Disk full'),
('2024-07-11 20:00:16', 'dc1', 'host1', '/api/v1/resource', 'Error: Network issue');
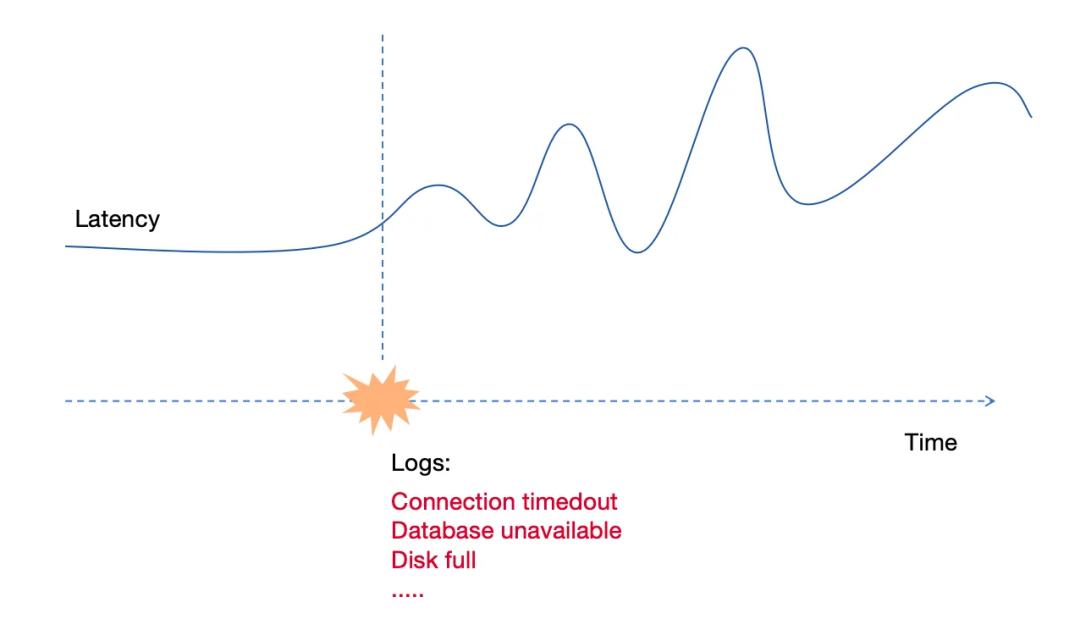
自 2024-7-11 20:00:10
以来,RPC 请求的延迟变得异常,延迟从大约 100 毫秒增加到 1000 毫秒或更高。此外,还收集到了一些错误日志。
这里,我们使用 INSERT
语句仅为演示目的,在实际系统中,用户可以使用 Prometheus、Vector 或 OTEL 来收集指标和日志。
现在我们已经有了应用程序的日志和指标,接下来,我们将通过关联分析快速地找到故障的时间点和可能的错误日志。
步骤 4:执行关联分析以查找故障和错误日志
我们已经拥有了应用程序的指标和日志数据。接下来,我们将使用 GreptimeDB 内置的 SQL 语言能力,结合指标和日志数据,快速定位故障时间点和相关的错误日志。
计算指标的 p95 延迟
首先,我们从指标开始,计算请求的 p95 延迟,使用 5 秒的时间窗口:
SELECT
ts,
host,
approx_percentile_cont(latency, 0.95) RANGE '5s' AS p95_latency
FROM
app_metrics
ALIGN '5s' FILL PREV;
使用 range query 进行数据聚合分析, range query 具体使用方法可见文档:https://docs.greptime.com/zh/reference/sql/range/
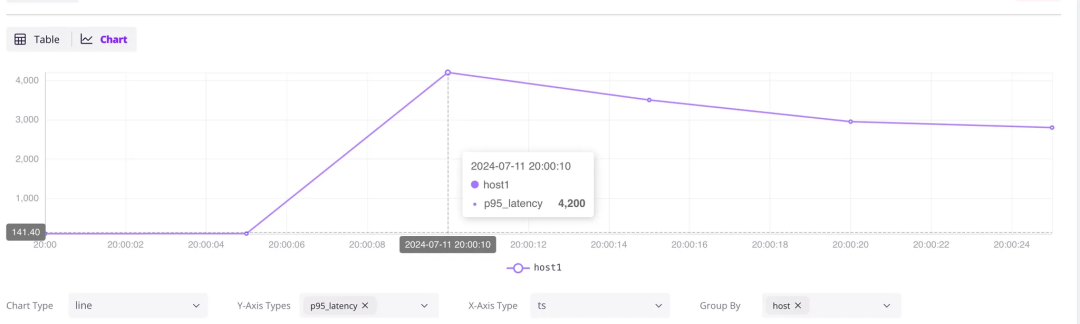
+---------------------+-------+-------------+
| ts | host | p95_latency |
+---------------------+-------+-------------+
| 2024-07-11 20:00:00 | host1 | 102 |
| 2024-07-11 20:00:05 | host1 | 104.5 |
| 2024-07-11 20:00:10 | host1 | 4200 |
| 2024-07-11 20:00:15 | host1 | 3500 |
| 2024-07-11 20:00:20 | host1 | 2950 |
| 2024-07-11 20:00:25 | host1 | 2800 |
+---------------------+-------+-------------+
延迟问题始于 2024-07-11 20:00:10
,将这些数据展示在像 Grafana 这样的可视化仪表盘上,可以清晰地显示出趋势,从而便于周期性地检测异常。当然,GreptimeDB 也提供内置的 dashboard 便于用户直接查看数据趋势并使用 SQL 或 PromQL 进行简单的数据分析。
分析日志错误
接下来,我们应类似地分析日志,并使用 5 秒的时间窗口计算总的错误日志计数。
SELECT
ts,
count(error) RANGE '5s' AS num_errors,
first_value(error) RANGE '5s' AS first_error,
last_value(error) RANGE '5s' AS last_error,
host
FROM
app_logs
WHERE
matches(path, 'api/v1')
ALIGN '5s';
这里我们只关注 API,因此使用日志搜索 matches(path, 'api/v1')
来筛选 API 日志。
除了错误计数 num_errors
,我们还选择性地获取时间窗口的第一条和最后一条日志来尝试查看,结果如下:
+---------------------+------------+---------------------------+----------------------+-------+
| ts | num_errors | first_error | last_error | host |
+---------------------+------------+---------------------------+----------------------+-------+
| 2024-07-11 20:00:10 | 5 | Error: Connection timeout | Error: Timeout | host1 |
| 2024-07-11 20:00:15 | 2 | Error: Disk full | Error: Network issue | host1 |
+---------------------+------------+---------------------------+----------------------+-------+
可以看出,应用程序在 2024-07-11 20:00:10
之前运行正常,直到发生了“连接超时”错误出现 Error: Connection timeout
。在 2024-07-11 20:00:10
至 2024-07-11 20:00:15
之间,共有 5 条错误日志。
实际场景中,你可以查询出所有这 5 秒钟的错误日志进行查看和分析,可以使用 GreptimeDB v0.10 引入的 Log 视图查看。
从工程师的角度来看,我们可以通过上述查询分别定位到故障时间和相关日志。但如果能将不同类型的所有数据整合在一起,就能更加高效和快速地找出问题,并更好地找到数据之间的关联。
指标和日志数据联合分析
为了在一个查询中关联指标和日志,我们使用公共表表达式(CTE)分别处理指标和日志,然后对它们进行 LEFT JOIN
操作:
WITH
metrics AS (
SELECT
ts,
host,
approx_percentile_cont(latency, 0.95) RANGE '5s' AS p95_latency
FROM
app_metrics
ALIGN '5s' FILL PREV
),
logs AS (
SELECT
ts,
host,
first_value(error) RANGE '5s' AS first_error,
last_value(error) RANGE '5s' AS last_error,
count(error) RANGE '5s' AS num_errors,
FROM
app_logs
WHERE
matches(path, 'api/v1')
ALIGN '5s'
)
--- 分析指标和日志数据间的关联性---
SELECT
metrics.ts,
p95_latency,
coalesce(num_errors, 0) as num_errors,
logs.first_error,
logs.last_error,
metrics.host
FROM
metrics
LEFT JOIN logs ON metrics.host = logs.host
AND metrics.ts = logs.ts
ORDER BY
metrics.ts;
它通过使用 WITH
子句(即公共表表达式,CTE)来引用之前的两个查询,并通过在相同的主机(host
)和时间戳(ts
)上进行 LEFT JOIN
,将指标和日志数据关联起来进行分析。
查询结果如下:
+---------------------+-------------+------------+---------------------------+----------------------+-------+
| ts | p95_latency | num_errors | first_error | last_error | host |
+---------------------+-------------+------------+---------------------------+----------------------+-------+
| 2024-07-11 20:00:00 | 102 | 0 | NULL | NULL | host1 |
| 2024-07-11 20:00:05 | 104.5 | 0 | NULL | NULL | host1 |
| 2024-07-11 20:00:10 | 4200 | 5 | Error: Connection timeout | Error: Timeout | host1 |
| 2024-07-11 20:00:15 | 3500 | 2 | Error: Disk full | Error: Network issue | host1 |
| 2024-07-11 20:00:20 | 2950 | 0 | NULL | NULL | host1 |
| 2024-07-11 20:00:25 | 2800 | 0 | NULL | NULL | host1 |
+---------------------+-------------+------------+---------------------------+----------------------+-------+
它显示,在 2024-07-11 20:00:10
,p95 延迟从 100 毫秒骤升至 4200 毫秒。此时,在 5 秒内记录到 5 条错误日志,其中第一条是 Error: Connection timeout
,最后一条是 Error: Timeout
。
通过这样的关联查询,我们只需要一条 SQL 语句,就能快速定位故障发生的时间和相关日志!无需整合不同的系统、使用不同的查询语言,也不需要编写复杂的应用程序代码。
将这条 SQL 语句添加到实时运行的业务监控仪表板中,我们就可以实时发现故障,确保快速响应。
下载最新 GreptimeDB 体验日志指标联合分析
希望你在阅读过程中收获启发。借助 GreptimeDB 强大的 SQL 语言能力,我们能够轻松地将日志与指标关联,快速定位故障,减少监控的复杂性与时间成本。这使得实时监控和调试应用变得更加简单,所有操作都能直接在仪表板中完成。
目前,基于 Rust 开发,完全开源的 GreptimeDB 时序数据库已升级至 v0.11.3,引入了更多日志分析的功能并带来更优的存储和查询性能。
欢迎前往 GitHub 下载使用:https://github.com/GreptimeTeam/greptimedb/releases/tag/v0.11.3
❝关于 Greptime
Greptime 格睿科技专注于为可观测、物联网及车联网等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前基于云原生的时序数据库 GreptimeDB 已经衍生出多款适合不同用户的解决方案,更多信息或 demo 展示请联系下方小助手(微信号:greptime)。
欢迎对开源感兴趣的朋友们参与贡献和讨论,从带有 good first issue 标签的 issue 开始你的开源之旅吧~期待在开源社群里遇见你!添加小助手微信即可加入“技术交流群”与志同道合的朋友们面对面交流哦~
Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb
官网:https://greptime.cn/
文档:https://docs.greptime.cn/Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime/
往期精彩文章:
点击「阅读原文」,立即体验 GreptimeDB!