




首先TiDB 深度兼容 MySQL 5.7
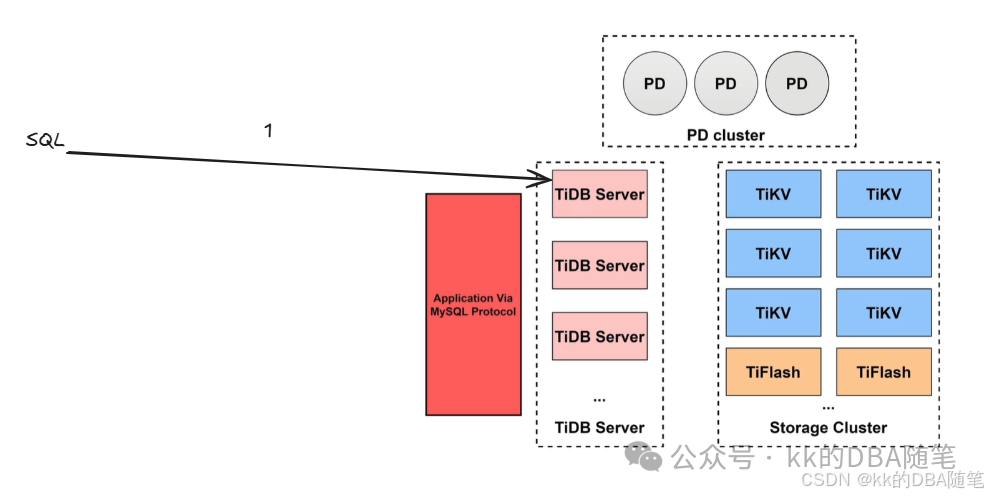
1. TiDB Server
SQL 语句的解析与编译:首先一条 SQL 语句最先到达的地方是 TiDB Server 集群,TiDB Server 是无状态的,不存储数据,SQL 发过来之后 TiDB Server 负责 解析,优化,编译 这条 SQL 语句,并生成执行计划。
处理客户端的连接:TiDB Server 还有一个特点是可以横向扩展,当并发很高,会话数很多,TiDB Server 可以横向扩展增加节点,分走一部分会话。
关系数据与 KV 的转化:由于 TiDB 存储的数据不是行数据,是键值对 KV,所以当 insert 的时候还会做 行数据变成 KV 类型数据的转化。 所以 region 由一个个的键值对组成。
OnlineDDL:DDL 语句不会阻塞线上的业务。
垃圾回收:一行数据修改频繁,经历了多次修改,之前修改的版本会保留下来。久而久之就会给数据库带来压力,TiDB Server 会进行自动垃圾回收(我们叫它 GC)
智能选择:通过预测 SQL,来确定是访问列存版本还是行存版本。
2. 数据存储节点 - TiKV
TiKV 里面存储的数据并不是建的表,当写数据的时候,会经过 TiDB Server 把数据分成一个个的 region (每个 region 在 96M-144M 之间)。并且为 region 创建副本,默认是三副本。
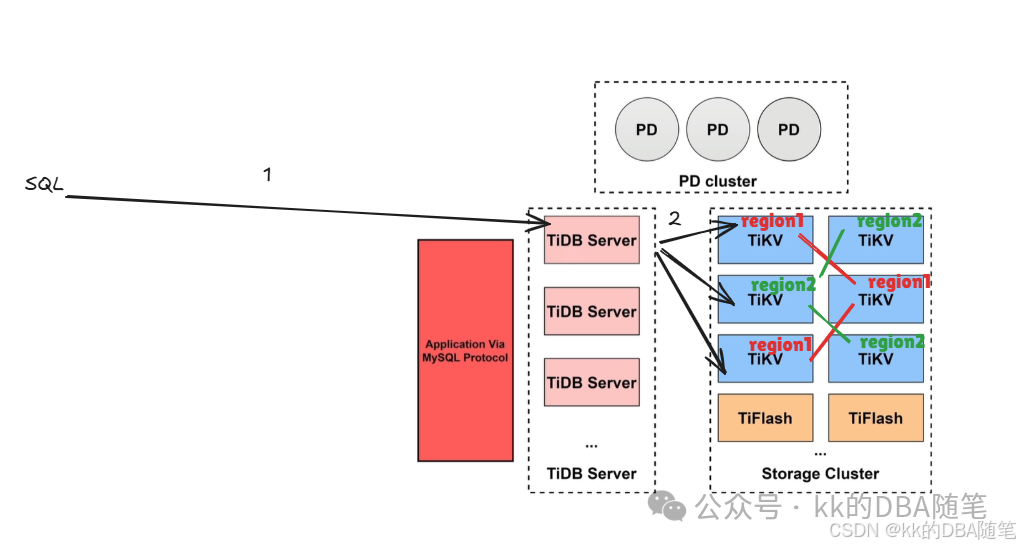
所以 TiKV 的作用就是存储打散的数据 ,并创建多副本保证高可用。所以如果空间不够的时候可以通过添加 TiKV 的方式来解决。
持久化:
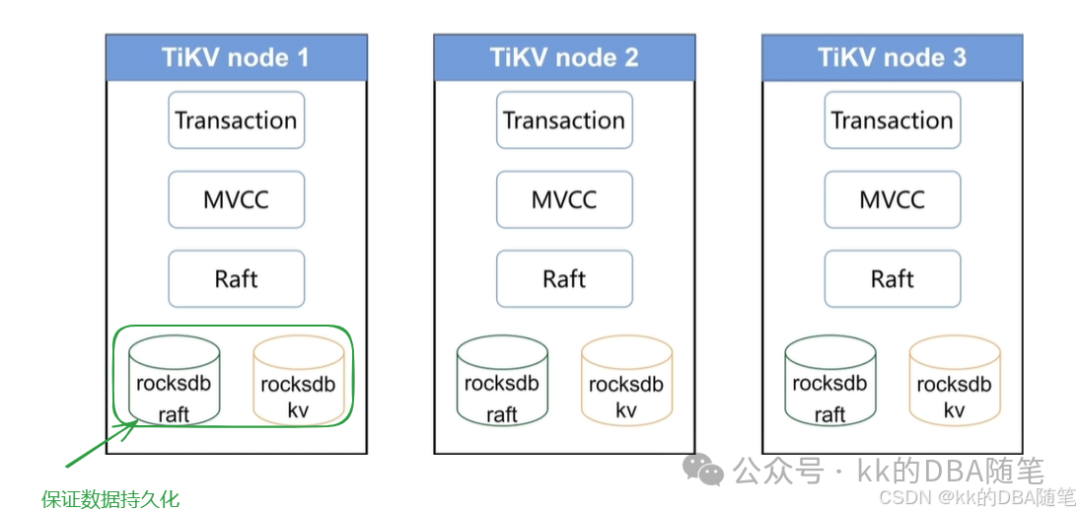
TiKV 中运行着 rocksdb 这个单机的 KV 存储引擎。 rocksdb 有两个实例
一个是 rocksdb kv:存储 KV 类型的数据。
一个是 rocksdb raft: 存储指令,对表的 DML 操作,都先存在 rocksdb raft 中,再由 rocksdb kv 进行应用。
强一致性和高可用性:
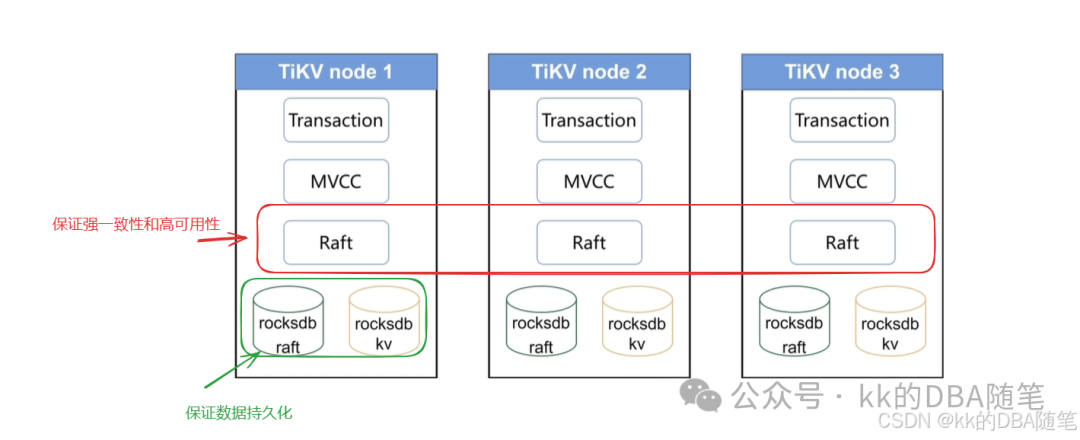
通过 Raft 协议,保证 region 在另外的 TiKV 中也有副本 。在三个副本中,只有一个副本负责读写,成为 leader 副本。其它的副本不能读写,复制同步 leader 副本。
MVCC:
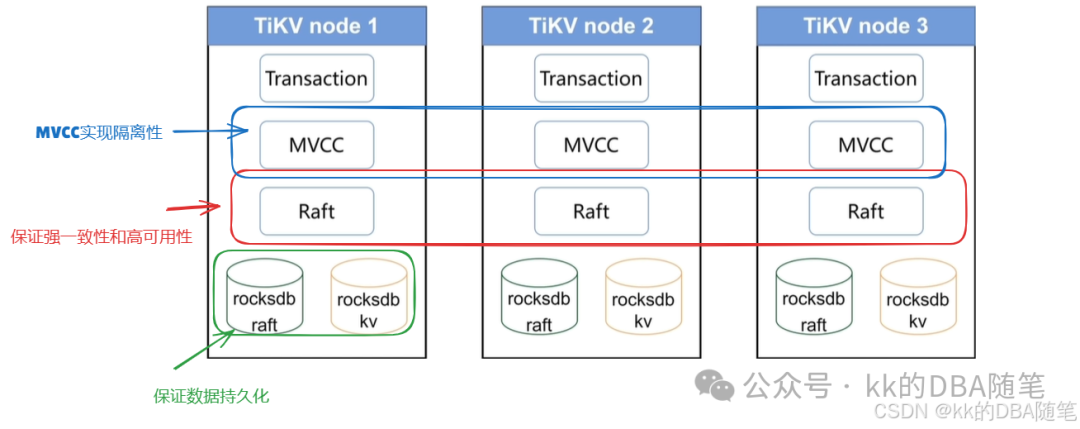
MVCC 实现数据库隔离性。
支持事务:
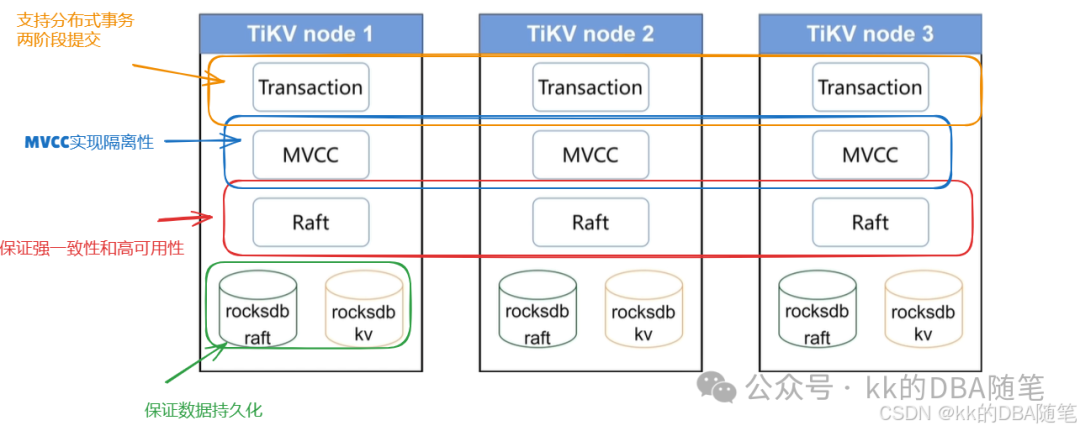
算子下推:
分布式数据库的优势,虽然数据存在多个节点中,会有一定的网络延迟,但每个节点都有 CPU,每个节点可以处理一部分计算功能。
3. 列存组件 - TiFlash
TiFlash 存的数据和 TiKV 里面的 region 是一样的,不过 TiKV 是行存储,TiFlash 是列存储。
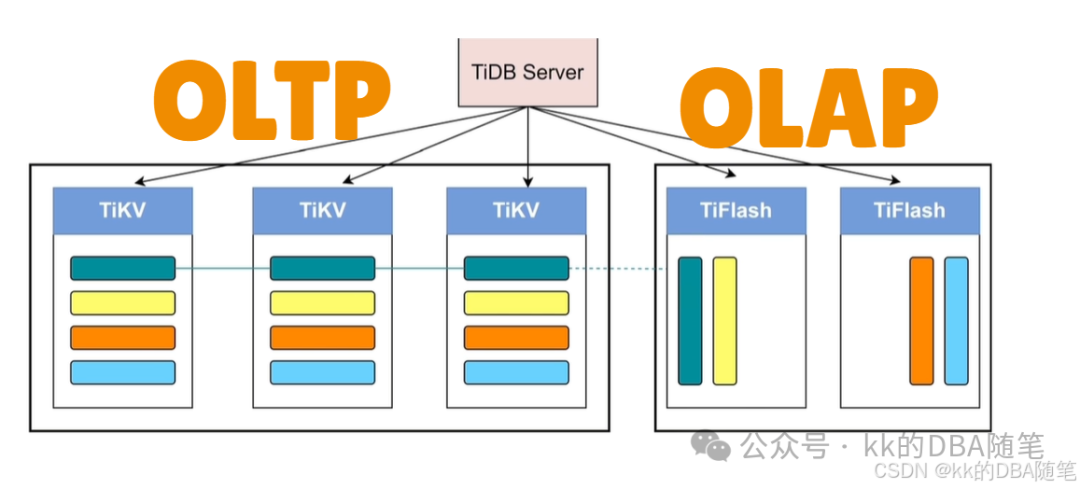
TiFlash 也参与复制,TiFlash 的数据和 TiKV 是一样的,引入 TiFlash 是为了分析型业务 的性能。
4. 集群大脑 PD
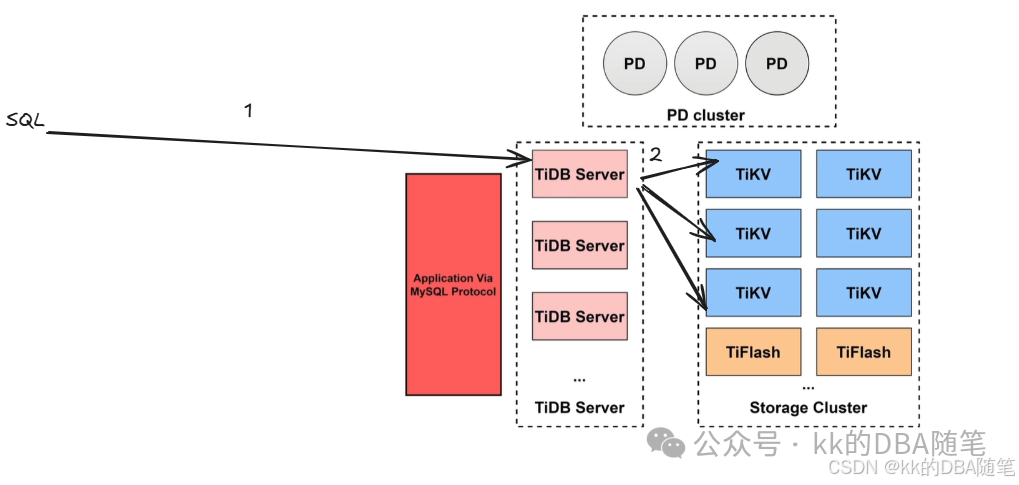
当访问数据的时候,比如一条 SQL 要进行全表扫描,经过 TiDB Server 后生成了执行计划,现在去找这张表组成的 region 在个 TiKV 或哪几个 TiKV 上面? 这就需要 region 和 TiKV 的映射关系(我们叫他元数据),元数据就存储在 PD 节点上。
并且每个 SQL 都有一个开始时间,也存储在 PD 上,我们叫它 (TSO)
如果是事务提交,也会记录事务开始时间和事务结束时间。
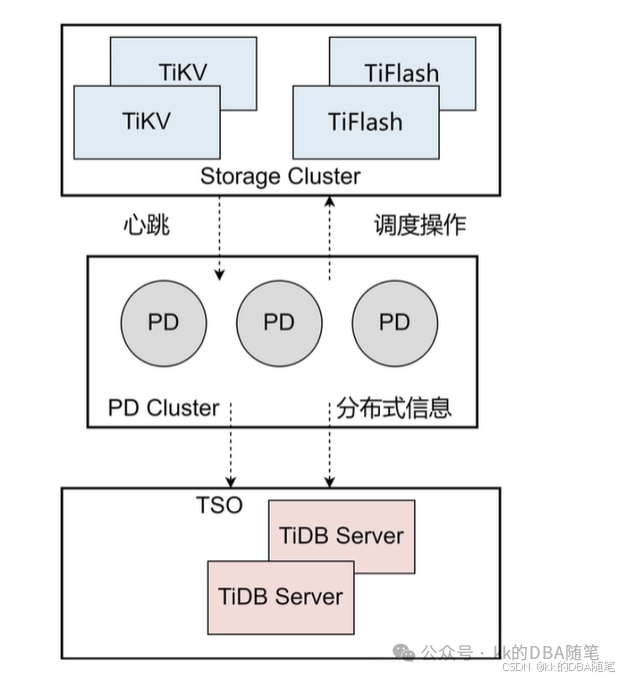
当一张表存储在 TiKV 中,经过长期的运行,这张表越来越大, 这张表过分的集中在某个 TiKV 中,这时候 DML 会集中到某个 TiKV 中,所以 region 和 TiKV 会以一定的时间间隔向 PD 汇报自己的状况,读写压力等。PD 会根据信息进行调度。



