




1. 查看执行计划

id:操作表顺序。
id 不同,执行顺序从大到小,id 相同,执行顺序从上到下。
select_type:select 类型
Simple:简单查询,不包含子查询或 union
Primary:最外层的查询
Subquery:子查询
Union:union 之后的查询
Dependent subquery:依赖于外查询的子查询
table:操作的表名
type:找到对应行的扫描方式
ALL:全表扫描
index:遍历所有树
range:对索引树进行范围扫描
ref:使用非唯一索引或唯一索引前缀进行查询
eq_ref:多表连接中,使用主键或唯一索引进行查询
const/system:根据主键或唯一索引进行查询
NULL:不需要访问表结构或索引直接得到结果
key:实际使用到的索引
ref:使用哪些列或常量来查找数据
rows:扫描行的数量
Extra:其它关键信息
Using filesort:在没有索引的列上进行排序
Using index:不需要回表
Using where:部分条件不在索引中
Using temporary:使用临时表来存储结果集,常用于分组
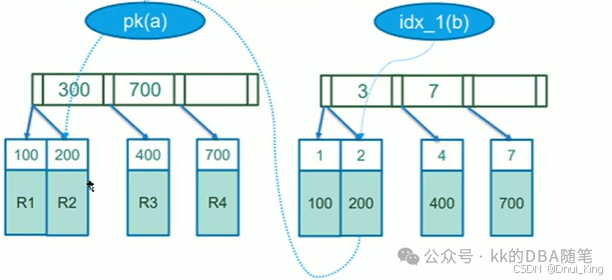
2. 聚簇索引与非聚簇索引
mysql 中索引的分类:
聚簇索引:索引的数据和基表的数据放在一块,叶子节点存放的是完整的行数据,类似与 Oracle 的 IOT 表。
非聚簇索引:索引的数据和基表的数据分开存放
示例:

建议使用聚簇索引访问表,且不回表扫描:
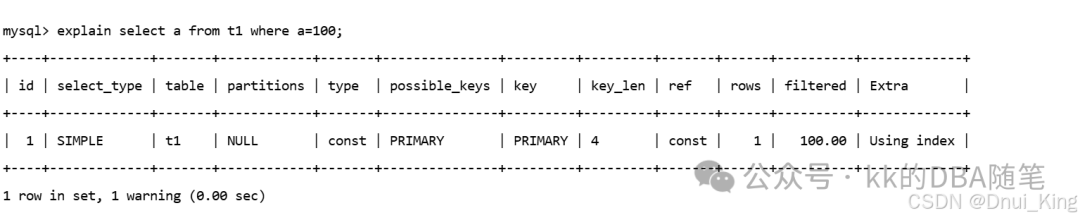
如果条件访问的是 a,条件是 b(覆盖索引),但使用的是非聚簇索引:

这种方式其实比前一种代价要大
如果是 select *, 则使用非聚簇索引扫描,且回表扫描:

3. 多个等值条件查询如何调优:
sql 调优方面之前写过一篇有实例可以参考,虽然是 PG 但是 sql 调优都是通用的。
PG sql 调优案例学习_pg 库的多表联查如何优化 - CSDN 博客
另外建复合索引需要关注前缀性和可选性:
例如:
select ...... where A=100 and B =100;
select ...... where A=100 and C = 100;
则建复合索引的时候应该 A 放在前面 例如 A,B
如果建立的是 B,A,C,那么第一条会走索引,第二条不会走索引。
即 复合索引的第一个索引字段,必须出现在 where 条件当中。
4.like 语句条件查询如何进行调优
非前缀模糊会使用索引: like ’dba%‘
前缀模糊无法使用索引: like ’%dba‘
5. 多表连接查询调优
mysql 连接顺序只有 nl 和 hash join 不支持 merge 。
首先还是老规矩了,大表驱动小表。
之前 PG 有写过,sql 调优是通用的。
PG sql 调优案例学习_pg 库的多表联查如何优化 - CSDN 博客



