❝物联网时代,海量数据如潮水般涌来,随着物联网设备在各个工业领域越来越普遍的应用,所产生的数据量也快速增长。如何在资源有限的边缘端,高效存储、分析这些数据,已成为工业场景一大挑战?本文深入探讨了边缘计算场景下时序数据库构建的技术难点与解决方案,首发于选自《工业 AI》杂志 2025 年 1 月刊。
随着物联网设备在各个工业领域越来越普遍的应用,这些设备所产生的数据量也快速增长。例如传感器、执行器和连接的机器,实时收集关于环境、工业设备和工业过程的数据。这些数据往往基于固定的时间间隔产生,通常带有一个时间戳标识数据产生的时间,因此称为时间序列数据(在下文中简称时序数据)。
时序数据在工业环境中尤为重要。它提供了变量随时间变化的历史视角,使得趋势分析、异常检测和预测分析成为可能。各行业可以利用这些数据来监控绩效、检测模式、识别低效,并预测未来事件。
然而,超大体量的数据对传统的集中式的云计算范式带来了挑战,将物联网设备采集到的数据全部传输到云端再进行存储和分析的方案无论是延迟、成本还是可扩展性方面都无法满足需求,因此在数据来源之处对这些数据进行分析和存储势在必行。
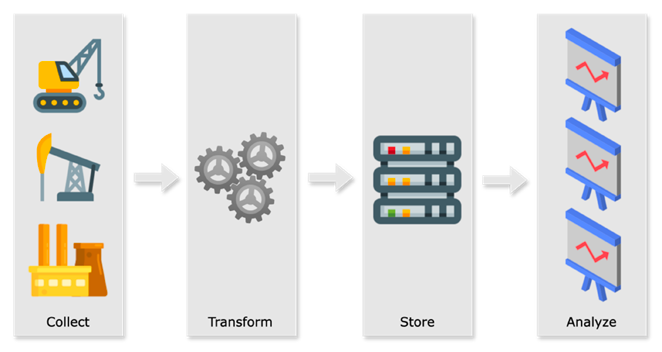
本文将介绍如何通过在边缘端部署时序数据库应对这些挑战,以及边缘端时序数据库的技术难点和解决方案。
数据量和资源限制的冲突
现有挑战
即使在边缘端场景中,接入的设备量也是不可小觑的,例如在一条现代化的水泥生产流水线上,会有上千个传感器用于检测产线各个流程的温度、压力、液位、流量等参数;此外随着工艺要求的提高,这些传感器采集的频率也越来越高,在有的行业中,甚至需要微秒级的数据采集频率。这两者叠加就带来了超大规模的数据写入需求。而边缘端场景不具备集中式云计算服务所能提供的近乎无限扩展的算力,并且往往有着较为严苛的功耗和资源限制,这是边缘数据库的的关键挑战之一。
解决方案
应对方法就是采用针对高吞吐写入优化的存储架构设计,例如 LSM 树。
主流的 OLTP 数据库(如 MySQL 和 PostgreSQL 等)通常采用 B 树(及其变体),其为了保证查询性能需要保持树的平衡,从而在每次数据写入的时候都有可能导致叶节点分裂影响写入性能,因此比较适合对读性能(尤其是点查性能)要求较高的场景。
而 LSM 树是一种采用写入优化策略的数据结构,主要由两部分组成:内存中的写入缓冲区(称为 Memtable 或 Write Buffer)和磁盘上的多个层(Level)。数据首先写入内存中的结构,然后通过后台进程以合并和重写的方式周期性地将其刷新到磁盘。尽管 LSM 树也需要 WAL(Write-Ahead Log)来保证数据可靠性,但 WAL 的写入基本都是顺序 IO,对高吞吐写入的场景更为友好。
即使采用了 LSM 树,其各个组件的设计也需要精心设计才能满足边缘计算的需求。边缘端设备的可用内存通常不大,即使是高端的工控主机的内存也往往在 2~16GB 之间,和服务器所搭载的动辄上百 GB 的内存不可同日而语。因此 LSM 树的写入缓冲的数据结构对于降低数据库整体内存开销极为重要。通常写入缓冲使用的数据结构为 BTree 或者 SkipList,而这两者在面对高基数的数据写入时,会出现由于 Key 的数量过多导致内存膨胀严重的问题。
此外,其数据结构自身的开销也不可忽略,从而导致出现真实内存占用远远超过用户所设定的阈值的情况。因此针对边缘端的场景需要设计一种更加紧凑的内存数据表示,例如下图所示,采用 Apache Arrow 这一类的列式内存数据结构,并且通过字典编码、时间线合并等手段进一步降低 Key 部分的内存开销。

除了内存方面的优化,为了适配嵌入式环境有限的计算资源,在 CPU 资源占用方面也有大量的优化工作需要完成。LSM 树这样的数据结构往往需要借助 compaction 任务对写入的数据进行整理,从而获得更好的查询性能。当数据量较大的时候,并发执行的 compaction 任务会占用大量的 CPU 和 IO 资源,从而影响其他任务的运行,因此需要一套合理的任务调度框架来管理这些后台任务。
数据的压缩和存储优化
现有挑战
采集海量物联网数据时,边缘端设备的存储空间往往会成为瓶颈,而无限提高设备的存储空间往往会带来难以承受的成本,因此需要使用特定的压缩算法对采集到的数据进行压缩。
传统的面向行的存储格式,如 JSON/CSV 等,往往只能采用一些通用的压缩算法,如 Gzip 和 Zstandard。虽然这些压缩算法的压缩率较高,但其带来的额外的 CPU开销也较大,并且其无法识别数据的类型和格式从而针对性的进行压缩。
解决方案
在这种场景下往往列式存储格式能够获得更好的压缩效果。
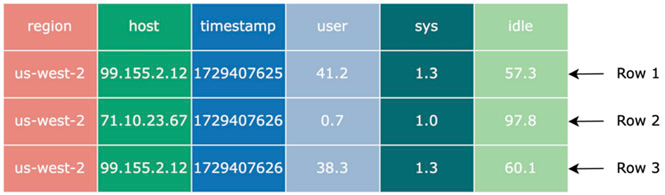

上图给出了同样一组数据在行式和列式格式中的存储方式。在面向行的文件格式中,相同一行的不同列的数据被存储在一起;而在面向列的文件格式中,不同行的相同列的数据被存储在一起。
由于不同行中相同列的数据往往具备较强的相关性,因此可以采用一些特殊的手段进行编码从而降低数据大小。
比如对于上图的中 region 这一列,我们可以采用字典编码,在文件头部的元数据字典中将 us-west-2
编码为 0x00
,这样 region 的数据就从 ["us-west-2", "us-west-2","us-west-2"]
变成了[0x00,0x00,0x00]
, 从而降低了占用空间。对于 timestamp,由于其基本上是单调递增的,我们可以采用 delta 编码,只记录第一行的 1729407625
,而其余行则记录其与第一行的差值即可,从而可以编码成 [1729407625, +01, +01]
即可。而对于浮点数(float 和 double 类型),则可以使用 Gorilla 编码获得针对浮点数的
更优的压缩效果。
在针对这些不同类型的编码之后,我们还可以进一步进行 Gzip 或者 Zstandard 压缩从而进一步降低文件大小,从而利用边缘端有限的存储能力应对海量的数据采集需求。
与云端湖仓的联动与同步
现有挑战
数据在边缘端采集之后,最终还需要汇总到云端进行分析并产生最终的报表或决策动作。在传统的解决方案中,需要边缘端设备将采集到的数据编码成传输格式(如 Protocol Buffer 等)再上传到云端。云端往往会部署一个集群来解析边缘端上传的数据再存入数据仓库或者数据湖中进行 BI 分析。而当数据量极速膨胀时,边缘端编码和云端解析的开销都会变得难以承受,而且云端解析带来的数据延迟也会越来越大,从而影响数据的实时性。
解决方案
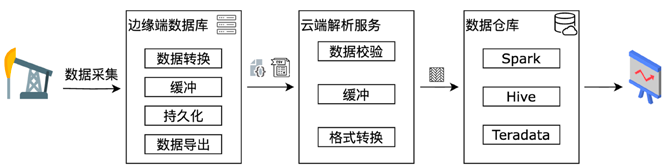
因此更为高效的解决方案则是在边缘端和云端使用相同的文件格式,从而无需文件解析,让云端的数据分析工具能够直接使用边缘端采集到的数据文件。这就对边缘端数据库的选型提出要求,其必须能够支持主流的数仓所使用的数据格式。目前的 GreptimeDB
和 IOTDB
均能实现类似的无解析、零拷贝的边云数据同步。
而在某些特定环境中的边缘场景,其由于地理位置限制并不具备有线网络接入的条件(如海上风力发电厂等),因此依赖移动网络流量上传。在这种场景下即使有各类压缩算法的支持,上传明细数据的代价也会变得难以承受,因此需要能够在边缘端做一些过滤和聚合操作,甚至需要能够将云端的查询下发到边缘端执行。
比如在云端执行如下的查询语句:
SELECT * FROM sensor_data
ORDER BY BY temperature DESC LIMIT复制
在原来的查询模式中,需要将所有边缘端的设备数据全部上传到云端数据仓库中之后才能获取最终的结果。而在边云联合查询中,可以将 ORDER BY ... LIMIT 1
下发到边缘端,由每个边缘端的时序数据库计算出局部的结果,再将这一行结果返回给云端服务器。在这种方案下,从边缘端上传到云端的数据量将会从全量数据降低到常数级,从而在不影响云端分析结果准确性的前提下大大节约上传数据的流量成本。当然要实现这样的效果必须要求边缘端数据和和云端数据库具备一定的联动分析能力。

Greptime 边云一体方案
Greptime 边云一体化解决方案立足于 GreptimeDB 的原生架构,针对物联网场景下的边缘存储与计算需求进行优化设计,成功应对物联网企业在数据量呈几何增长下的业务挑战。通过将多模态边缘数据库与云端 GreptimeDB 企业版的紧密结合,该方案显著降低了企业在数据传输、计算和存储上的总体成本。同时,它还增强了数据处理的实时性和业务洞察能力,为物联网企业提供了更为敏捷和高效的数据管理方式,推动了从数据到决策的快速闭环。
更多信息欢迎前往官网下载边云一体方案白皮书(点击文末阅读原文了解更多):www.greptime.cn
总结
本文介绍了海量物联网数据采集和分析场景对边缘端时序数据库所造成的挑战,包括计算存储资源的限制、海量数据的压缩、边缘端和云端联动查询等方面,以及如何通过合理的数据结构和存储架构设计、灵活高效的压缩算法、零解析的数据同步机制和边云一体联合查询来解决这些问题。随着新场景和新需求的涌现,物联网数据采集、同步和分析的技术和架构也需要持续迭代,从而充分发掘和利用埋藏在海量物联网数据中的价值。
❝关于 Greptime
Greptime 格睿科技专注于为可观测、物联网及车联网等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前基于云原生的时序数据库 GreptimeDB 已经衍生出多款适合不同用户的解决方案,更多信息或 demo 展示请联系下方小助手(微信号:greptime)。
欢迎对开源感兴趣的朋友们参与贡献和讨论,从带有 good first issue 标签的 issue 开始你的开源之旅吧~期待在开源社群里遇见你!添加小助手微信即可加入“技术交流群”与志同道合的朋友们面对面交流哦~
Star us on GitHub Now: https://github.com/GreptimeTeam/greptimedb
官网:https://greptime.cn/
文档:https://docs.greptime.cn/Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime/
往期精彩文章:
点击「阅读原文」,下载白皮书了解更多车云一体方案功能和性能参数~