





引 言
Q1
什么是LLM?
LLM是大型语言模型(Large Language Model)的缩写,它是一种基于深度学习的人工智能模型,主要通过学习海量的文本数据来理解和生成人类语言。这些模型通常包含数百亿(或更多)参数,通过层叠的神经网络结构,学习并模拟人类语言的复杂规律,达到接近人类水平的文本生成能力。
Q2
什么是RAG?
RAG是检索增强生成(Retrieval Augmented Generation)的缩写,它是一种结合了信息检索与自然语言生成技术的方法,旨在通过引入外部知识库来增强生成模型的能力,从而提高生成内容的质量和准确性。
Q3
有了LLM为什么还需要RAG?
Ø LLM知识局限:LLM模型自身的知识源于其训练数据,而现有的主流大模型的训练集基本都是构建的数据集,对于一些实时性的、非公开的或离线的数据是无法获取到的,这部分知识也就无从具备。
Ø LLM幻觉局限:LLM底层原理都是基于数学概率,其模型输出实质上是一系列数值运算,因此LLM有时候会一本正经地胡说八道,尤其是在LLM自身不具备某一方面的知识或不擅长的场景。
Ø LLM数据安全:当前人工智能时代,数据安全至关重要,没有企业愿意承担数据泄露的风险,不可能将自身的私域数据上传第三方平台进行训练。这也导致完全依赖通用大模型自身能力的应用方案不得不在数据安全和效果方面进行取舍。
为什么选择GBase 8c V6 + DeepSeek?
Ø性能强劲,稳定高效:GBase 8c作为国产分布式数据库佼佼者,性能优异且更加安全稳定,V6版本集成了自研的分布式向量引擎,数据库优化器和执行器相对V5版本做了全面优化,性能大幅提升。DeepSeek的RAG模型更能精准理解用户需求。
Ø 灵活定制,无限可能:本地部署意味着用户可以根据自身需求,自由定制知识库内容和功能,打造更懂用户的AI助手。
Ø 数据安全,隐私保障:敏感数据本地存储,杜绝信息泄露风险,安心使用无顾虑。
Ø 离线可用,稳定可靠:无需依赖网络,随时随地访问自己的知识库,稳定流畅不卡顿。
Ø 成本可控,长期受益:一次部署,长期使用,无需持续支付高昂的云服务费用。
搭建基础环境
本试验所采用的操作系统为 centos7(x86_64),开发环境使用 python3.11。
安装python3.11
若采用源码安装,源码包下载地址为https://www.python.org/ftp/python/3.11.11/
如果系统openssl版本比较低,需要升级至openssl1.1.1。
configuer 时需要指定--with-openssl,然后 make,make install即可。
运行如下命令测试是否安装成功
$ python3 --versionPython 3.11.11
安装ollama服务
首先,我们需要下载 ollama 的 pypi 包,以便后续通过python程序访问 ollama 服务:
[gbase@gbase8c-5-155 ~]$ pip3 install ollama
然后安装ommama服务(参考https://github.com/ollama/ollama/blob/main/docs/linux.md),可以通过一键安装命令:
curl -fsSL https://ollama.com/install.sh | sh
或者手动安装:
curl -L https://ollama.com/download/ollama-linux-amd64.tgz -o ollama-linux-amd64.tgzsudo tar -C usr -xzf ollama-linux-amd64.tgz
启动ollama服务:
ollama serve
在另一个终端查看是否启动成功:
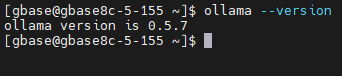
获取文本嵌入模型
我们选取的是nomic-embed-text。
nomic-embed-text是一个开源的文本嵌入模型,在处理短文和长文本任务方面有很大的优势,使用该模型将我们输入的文本转换为768维的向量数据,然后通过psycopg2将向量数据存入GBase 8c数据库,为后续的检索和匹配提供了强有力的支持。使用如下命令获取:
$ ollama pull nomic-embed-text
获取文本生成模型:
我们选取的是DeepSeek-r1。
DeepSeek-r1 模型是基于先进的深度学习技术开发的,它具有独特的架构和训练方式,能够更好地捕捉文本中的语义信息,从而为文本生成带来更出色的效果。使用如下命令获取:
ollama pull deepseek-r1
安装GBase 8c数据库
通过GBase 8c分布式向量数据库将私域知识存储在本地,在快速检索的同时提供更加稳定、更加安全的数据防护。
获取GBase 8c安装包,参考《GBase 8c V6_1.0.0_安装部署手册》手册进行数据库搭建。
部署成功后查看集群运行情况:

安装psycopg2
pip3 install psycopg2
通过psycopg2连接GBase 8c查看版本信息:
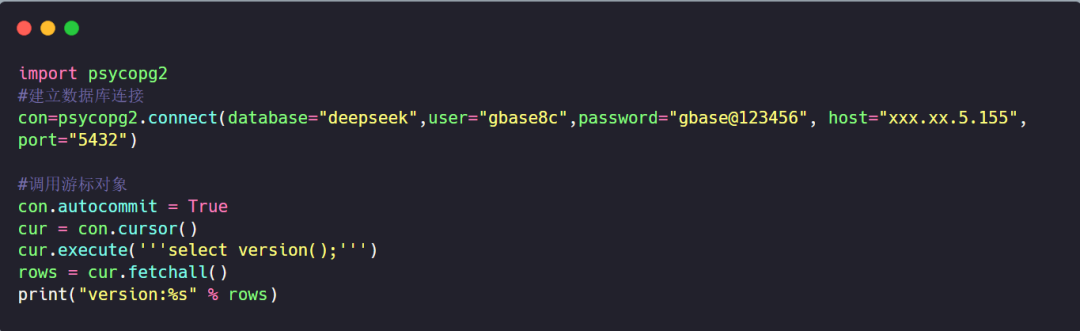
输出如下:

构建RAG实例:实现知识的高效检索与生成
准备语料数据
以 GBase 部分语料数据作为私域知识,部分内容如下:

语料处理、嵌入、导入
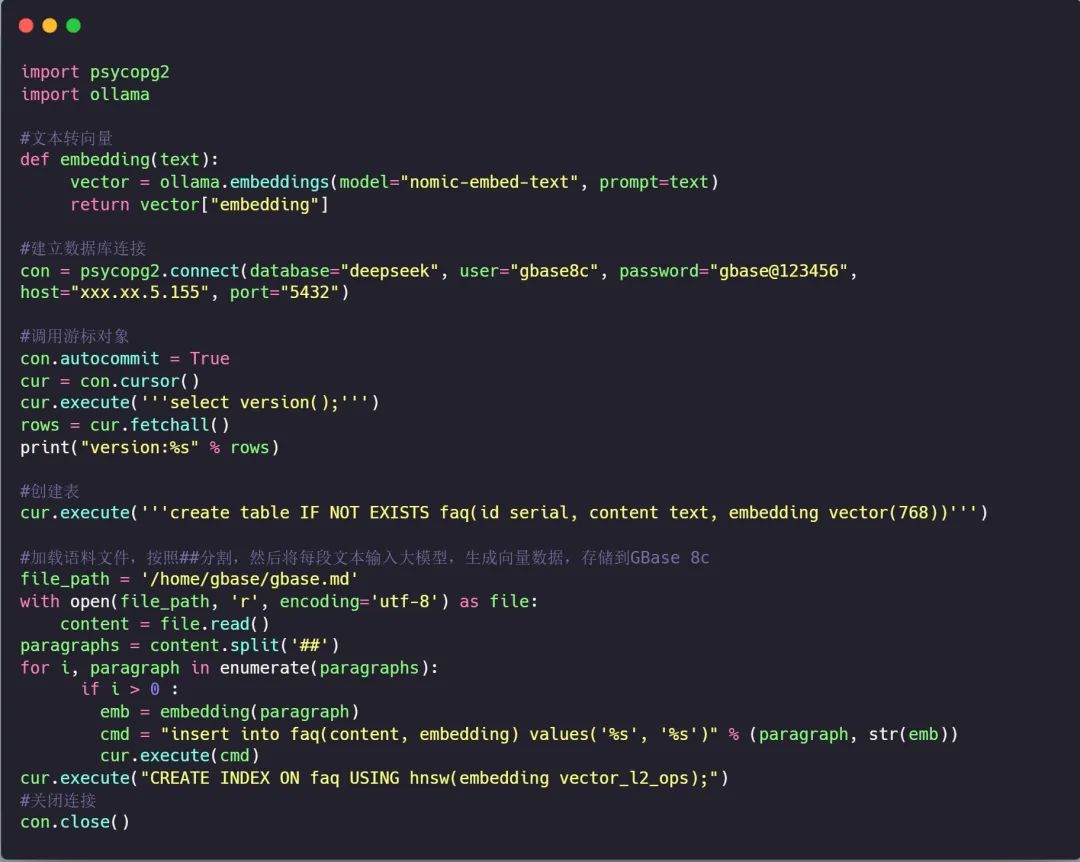
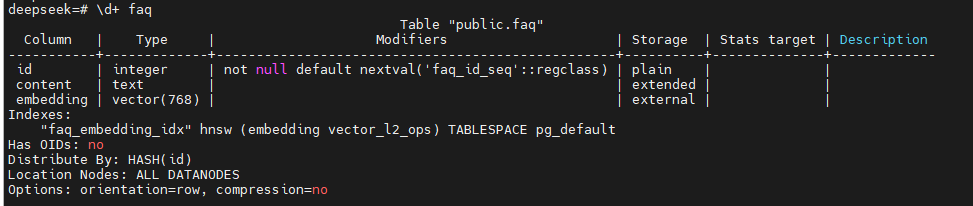
执行完成后,GBase 8c数据库中表结构及数据如下:
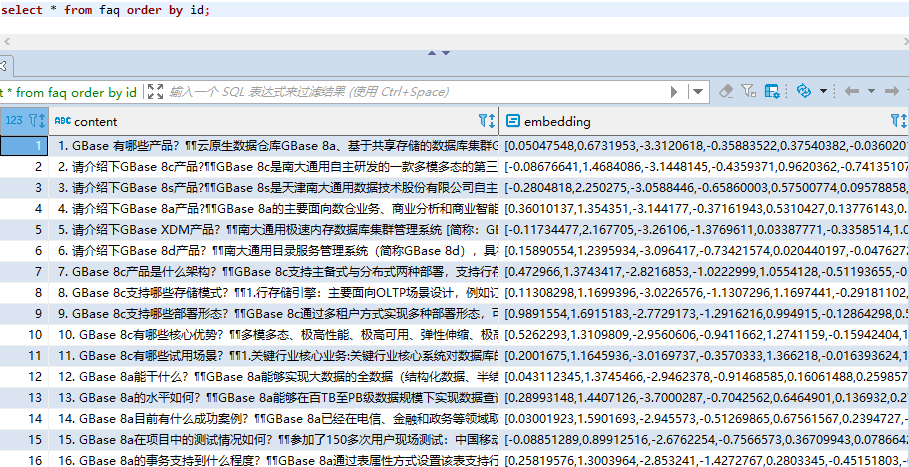
查询检索
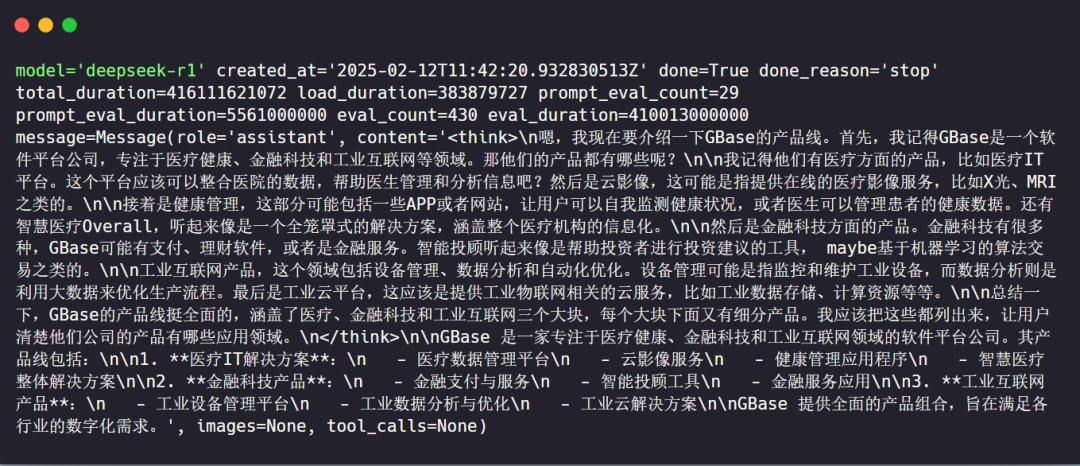
仅使用DeepSeek进行检索:

回答内容如下:
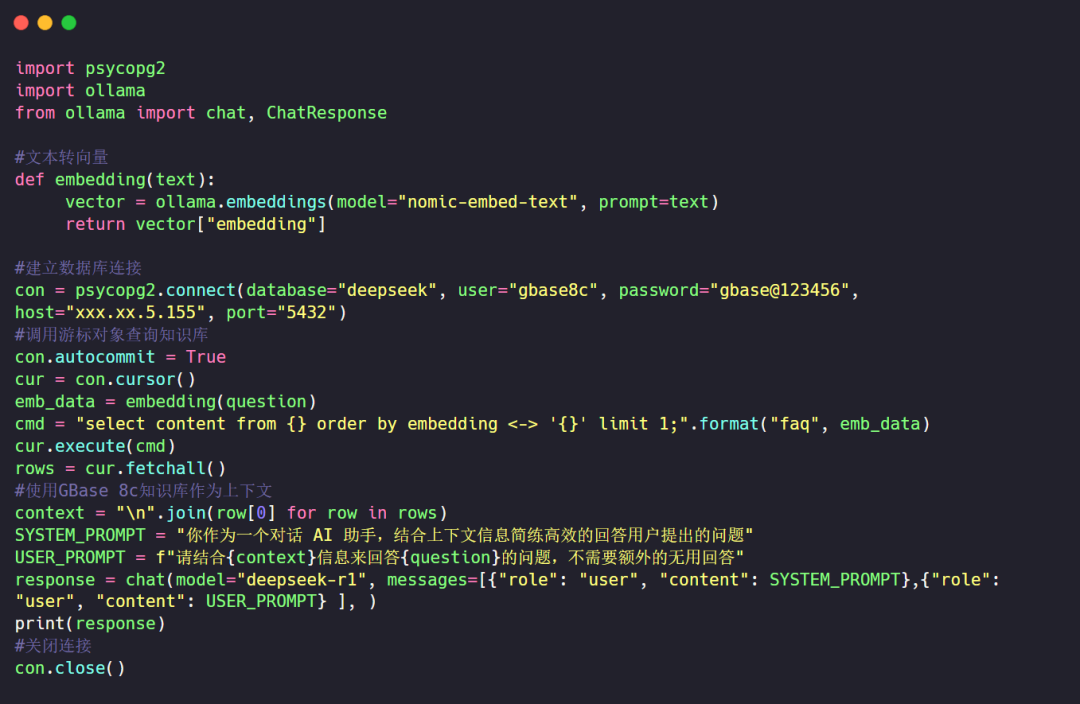
使用GBase 8c V6 + DeepSeek进行检索:
首先将问题转换为向量,然后在GBase 8c向量知识库中进行检索,将检索的结果作为上下文,并为大模型制定PROMPT,最后进行提问:
回答内容如下:
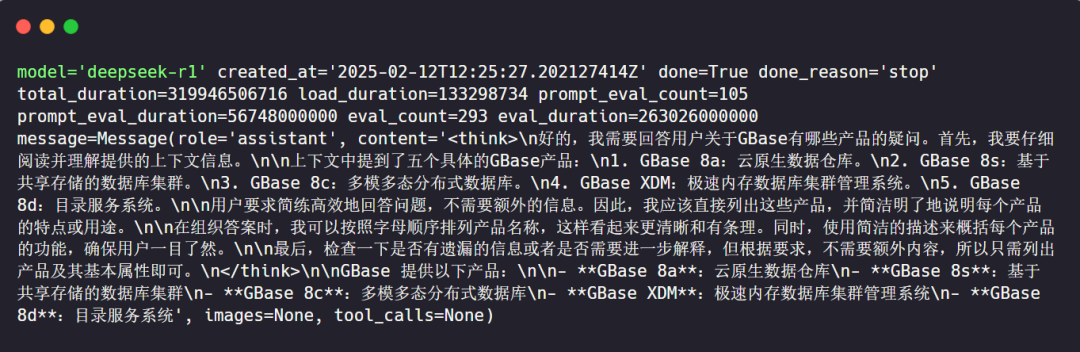
可见,使用 DeepSeek 结合 GBase 8c 搭建的RAG 应用,不仅能借助 DeepSeek 强大的文本生成能力和精准的文本嵌入功能,还能依GBase 8c 出色的向量数据库高效存储和快速检索向量数据,从而显著提升答案的准确性、可靠性,有效避免大语言模型的幻觉问题,为企业提供更优质的本地化知识服务。
总 结
基于ollama,我们成功利用GBase 8c和DeepSeek从零搭建起了简易的 RAG 应用,获取到了所需的知识数据。在这个过程中,我们对 RAG 技术和GBase 8c向量数据库有了更深入的理解,也切实体会到了它们在解决 LLM 实际应用问题上的作用。这个简易应用只是一个开端,读者可以依据自身需求对相关环节进行灵活调整和优化,以更好地满足不同场景的需要。
本期供稿 | 分布式事务产品经营部
本期排版 | Suse
内容审核 | 生态发展部





