




Kafka 是消息队列中间件的代表产品,它与 RocketMQ 和 RabbitMQ 最大的区别在于:在某些场景,可以弃用 Flink、Spark 这样的计算引擎,借助 Kafka Stream 轻松实现数据处理。也即,Kafka 不仅是消息引擎系统,也是分布式流处理平台。
优点 以下是Kafka的几个好处
可靠性 - Kafka是分布式,分区式,复制型和容错型。
可扩展性 - Kafka消息系统轻松扩展,无需停机时间。
耐用性 - Kafka使用分布式提交日志,这意味着邮件尽可能快地依然存在于磁盘上,因此它是耐用的。
性能 - Kafka对于发布和订阅消息都具有高吞吐量。它保持稳定的性能,即使存储了许多TB的消息。
用例
Kafka可用于许多用例。其中有些列在下面
指标 - Kafka经常用于运行监控数据。这涉及从分布式应用程序聚合统计信息,以产生操作数据的集中式提要。
日志聚合解决方案 - Kafka可以在整个组织中使用,从多个服务收集日志,并以标准格式提供给多个服务器。
流处理 - 流行框架(如Storm和Spark Streaming)从主题读取数据,处理它,并将处理后的数据写入可用于用户和应用程序的新主题。Kafka的强大耐用性在流处理方面也非常有用。
Kafka需要
Kafka是处理所有实时数据源的统一平台。Kafka支持低延迟消息传递,并在存在机器故障的情况下保证容错。它具有处理大量不同消费者的能力。Kafka非常快,执行200万次写/秒。Kafka将所有数据保留到磁盘,这实质上意味着所有的写入都将转到操作系统(RAM)的页面缓存。这将数据从页面缓存传输到网络套接字非常有效。

最新版本 3.0 的发布,使得 Kafka 这一定位得到了进一步加强。突出的一点体现在对 KRaft 元数据和 API 进行了诸多突破性的改进:
“KRaft Controllers 和KRaft Brokers,能够为元数据主题 __cluster_metadata 的分区生成、复制和加载快照”
此外,Kafka3.0 在很多方面都进行了改善和升级,例如:Kafka 主题/分区偏移量的能力、Kafka Consumer 的配置属性、弃用对 Java 8 和 Scala 2.12 的支持…
当然,比起这些,有一个更直观的理由能让我们从 Kafka2 换到 Kafka3:Kafka3 的速度与性能起码是 Kafka2 的 10 多倍!
第一部分 基础升级
1)弃用Kafka中对Java8的支持
早期版本(3.x以下):Kafka支持java8,11和15(即将为16)
Kafka3.x版本:弃用java8,依然可用,官方建议更新至java11,未来将支持jdk11,jdk16,jdk16,jdk17(非LTS版本)
展望Kafka4.0:完全放弃java8
2)弃用Kafka中对scala2.12的支持
早期版本(3.x以下):Kafka支持scala2.11(kafka2.5及后续版本不支持),2.12,2.13版本
Kafka3.x版本:弃用scala2.12版本,依然可用,官方建议推荐使用scala2.13,后续会推出基于scala3的版本
展望Kafka4.0:完全放弃scala2.12
第二部分 Kafka 代理、生产者、消费者和管理客户端
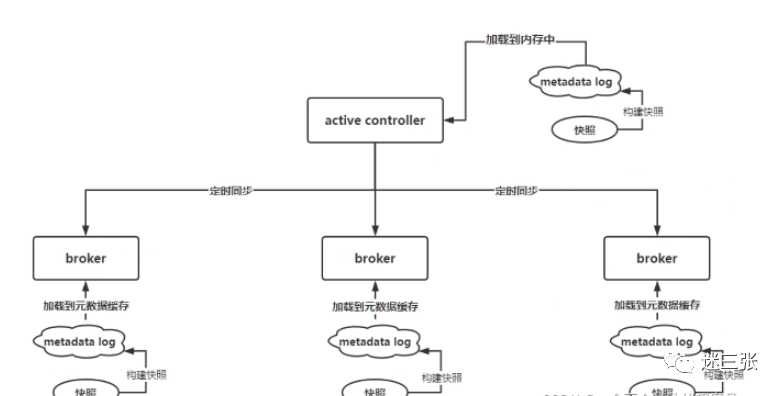
KIP-630:Kafka Raft 快照
我们在 3.0 中引入的一个主要功能是 KRaft 控制器和 KRaft 代理能够为名为 __cluster_metadata 的元数据主题分区生成、复制和加载快照。Kafka 集群使用此主题来存储和复制有关集群的元数据信息,如代理配置、主题分区分配、领导等。随着此状态的增长,Kafka Raft Snapshot 提供了一种有效的方式来存储、加载和复制此信息 .
KIP-746:修改 KRaft 元数据记录
自第一版 Kafka Raft 控制器以来的经验和持续开发表明,需要修改一些元数据记录类型,当 Kafka 被配置为在没有 ZooKeeper ( ZK ) 的情况下运行时使用这些记录类型。
KIP-730:KRaft 模式下的生产者 ID 生成
在 3.0 和 KIP-730 中,Kafka 控制器现在完全接管了生成 Kafka 生产者 ID 的责任。控制器在 ZK 和 KRaft 模式下都这样做。这让我们更接近桥接版本,这将允许用户从使用 ZK 的 Kafka 部署过渡到使用 KRaft 的新部署。
KIP-679:Producer 将默认启用最强的交付保证
从 3.0 开始,Kafka 生产者默认开启幂等性和所有副本的交付确认。这使得默认情况下记录交付保证更强。
KIP-735:增加默认消费者会话超时
Kafka Consumer 的配置属性的默认值 session.timeout.ms 从 10 秒增加到 45 秒。这将允许消费者在默认情况下更好地适应暂时的网络故障,并在消费者似乎只是暂时离开组时避免连续重新平衡。
KIP-709:扩展 OffsetFetch 请求以接受多个组 ID
请求 Kafka 消费者组的当前偏移量已经有一段时间了。但是获取多个消费者组的偏移量需要对每个组进行单独的请求。在 3.0 和 KIP-709 中,fetch 和 AdminClient API 被扩展为支持在单个请求 响应中同时读取多个消费者组的偏移量。
KIP-699:更新 FindCoordinator 以一次解析多个 Coordinator
支持可以以有效方式同时应用于多个消费者组的操作在很大程度上取决于客户端有效发现这些组的协调者的能力。这通过 KIP-699 成为可能,它增加了对通过一个请求发现多个组的协调器的支持。Kafka 客户端已更新为在与支持此请求的新 Kafka 代理交谈时使用此优化。
KIP-724:删除对消息格式 v0 和 v1 的支持
自 2017 年 6 月随 Kafka 0.11.0 推出四年以来,消息格式 v2 一直是默认消息格式。因此,在桥下流过足够多的水(或溪流)后,3.0 的主要版本为我们提供了弃用旧消息格式(即 v0 和 v1)的好机会。这些格式今天很少使用。在 3.0 中,如果用户将代理配置为使用消息格式 v0 或 v1,他们将收到警告。此选项将在 Kafka 4.0 中删除(有关详细信息和弃用 v0 和 v1 消息格式的影响,请参阅 KIP-724)。
KIP-707:KafkaFuture 的未来
当 KafkaFuture 引入该类型以促进 Kafka AdminClient 的实现时,Java 8 之前的版本仍在广泛使用,并且 Kafka 正式支持 Java 7。快进几年后,现在 Kafka 运行在支持 CompletionStage 和 CompletableFuture 类类型的 Java 版本上。使用 KIP-707,KafkaFuture 添加了一种返回 CompletionStage 对象的方法,并以 KafkaFuture 向后兼容的方式增强了可用性。
KIP-466:添加对 List<T> 序列化和反序列化的支持
KIP-466 为泛型列表的序列化和反序列化添加了新的类和方法——这一特性对 Kafka 客户端和 Kafka Streams 都非常有用。
KIP-734:改进 AdminClient.listOffsets 以返回时间戳和具有最大时间戳的记录的偏移量
用户列出 Kafka 主题 分区偏移量的功能已得到扩展。使用 KIP-734,用户现在可以要求 AdminClient 返回主题 分区中具有最高时间戳的记录的偏移量和时间戳。(这是不是与什么的 AdminClient 收益已经为最新的偏移,这是下一个记录的偏移,在主题 分区写入混淆。)这个扩展现有 ListOffsets API 允许用户探测生动活泼的通过询问哪个是最近写入的记录的偏移量以及它的时间戳是什么来分区
Kafka Connect

KIP-745:连接 API 以重新启动连接器和任务
在 Kafka Connect 中,连接器在运行时表示为一组 Connector 类实例和一个或多个 Task 类实例,并且通过 Connect REST API 可用的连接器上的大多数操作都可以应用于整个组。从一开始,一个值得注意的例外 restart 是 Connector 和 Task 实例的端点。要重新启动整个连接器,用户必须单独调用以重新启动连接器实例和任务实例。在 3.0 中,KIP-745 使用户能够通过一次调用重新启动所有或仅失败的连接器 Connector 和 Task 实例。此功能是附加功能,restartREST API 的先前行为保持不变。
KIP-738:删除 Connect 的内部转换器属性
在之前的主版本 ( Apache Kafka 2.0 ) 中弃用它们之后,internal.key.converter 并 internal.value.converter 在 Connect 工作器的配置中作为配置属性和前缀被删除。展望未来,内部 Connect 主题将专门使用 JsonConverter 来存储没有嵌入模式的记录。任何使用不同转换器的现有 Connect 集群都必须将其内部主题移植到新格式(有关升级路径的详细信息,请参阅 KIP-738)。
KIP-722:默认启用连接器客户端覆盖
从 Apache Kafka 2.3.0 开始,可以配置连接器工作器以允许连接器配置覆盖连接器使用的 Kafka 客户端属性。这是一个广泛使用的功能,现在有机会发布一个主要版本,默认启用覆盖连接器客户端属性的功能(默认 connector.client.config.override.policy 设置为 All)。
KIP-721:在连接 Log4j 配置中启用连接器日志上下文
另一个在 2.3.0 中引入但到目前为止尚未默认启用的功能是连接器日志上下文。这在 3.0 中发生了变化,连接器上下文默认添加 log4j 到 Connect 工作器的日志模式中。从以前的版本升级到 3.0 将 log4j 通过在适当的情况下添加连接器上下文来更改导出的日志行的格式。
Kafka Streams
KIP-695:进一步改进 Kafka Streams 时间戳同步
KIP-695 增强了 Streams 任务如何选择获取记录的语义,并扩展了配置属性的含义和可用值 max.task.idle.ms。此更改需要 Kafka 消费者 API 中的一种新方法,currentLag 如果本地已知且无需联系 Kafka Broker,则能够返回特定分区的消费者滞后。
KIP-715:在流中公开提交的偏移量
在使用kafka中,我们如果想要跟踪客户端的消息的进度,可以根据其返回的偏移量信息来判断,但是此操作在kafka的stream中并没有提供,因为stream的客户端中嵌入了多个kafka客户端(发送和消费)
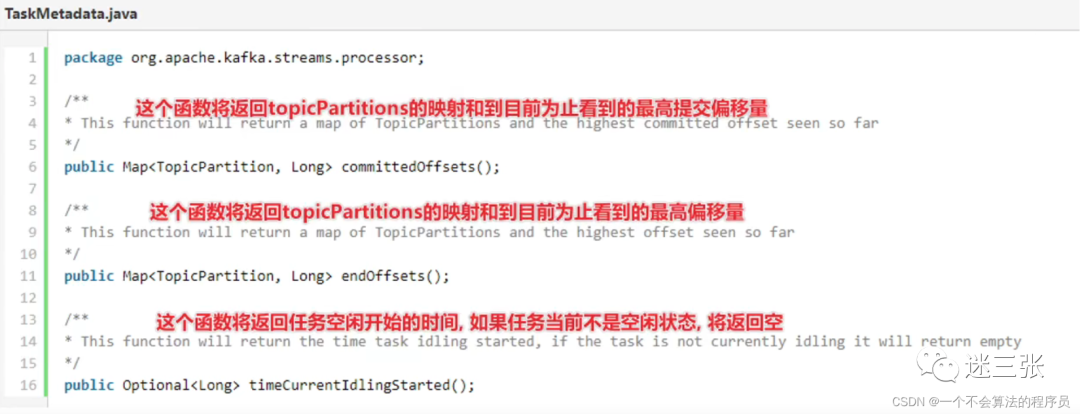
3.0 开始,三个新的方法添加到 TaskMetadata 接口:committedOffsets,endOffsets,和 timeCurrentIdlingStarted。这些方法可以允许 Streams 应用程序跟踪其任务的进度和运行状况。
KIP-740:清理公共 API TaskId
KIP-740 代表了 TaskId 该类的重大革新。有几种方法和所有内部字段已被弃用,新的 subtopology ( ) 和 partition ( ) 干将替换旧 topicGroupId 和 partition 字段(参见 KIP-744 的相关变化和修正 KIP-740)。
KIP-744:迁移 TaskMetadata,并 ThreadMetadata 与内部实现的接口
KIP-744 将 KIP-740 提出的更改更进一步,并将实现与许多类的公共 API 分开。为了实现这一点,引入了新的接口 TaskMetadata、ThreadMetadata 和 StreamsMetadata,而弃用了具有相同名称的现有类。
KIP-666:添加 Instant 基于方法到 ReadOnlySessionStore
交互式查询 API 扩展了 ReadOnlySessionStore 和 SessionStore 接口中的一组新方法,这些方法接受 Instant 数据类型的参数。此更改将影响需要实现新方法的任何自定义只读交互式查询会话存储实现。
KIP-622:添加 currentSystemTimeMs 和 currentStreamTimeMs 到 ProcessorContext
该 ProcessorContext 增加在 3.0 两个新的方法,currentSystemTimeMs 和 currentStreamTimeMs。新方法使用户能够分别查询缓存的系统时间和流时间,并且可以在生产和测试代码中以统一的方式使用它们。
KIP-743:删除 0.10.0-2.4Streams 内置指标版本配置的配置值
3.0 中取消了对 Streams 中内置指标的旧指标结构的支持。KIP-743 正在 0.10.0-2.4 从配置属性中删除该值 built.in.metrics.version。这 latest 是目前此属性的唯一有效值(自 2.5 以来一直是默认值)。
KIP-741:将默认 SerDe 更改为 null
删除了默认 SerDe 属性的先前默认值。流过去默认为 ByteArraySerde. 用 3.0 开始,没有缺省,和用户需要任一组其的 SerDes 根据需要在 API 中或通过设置默认 DEFAULT_KEY_SERDE_CLASS_CONFIG 和 DEFAULT_VALUE_SERDE_CLASS_CONFIG 在它们的流配置。先前的默认值几乎总是不适用于实际应用程序,并且造成的混乱多于方便。
KIP-733:更改 Kafka Streams 默认复制因子配置
有了主要版本的机会,Streams 配置属性的默认值 replication.factor 会从 1 更改为 -1。这将允许新的 Streams 应用程序使用在 Kafka 代理中定义的默认复制因子,因此在它们转移到生产时不需要设置此配置值。请注意,新的默认值需要 Kafka Brokers 2.5 或更高版本。
KIP-732:弃用 eos-alpha 并用 eos-v2 替换 eos-beta
在 3.0 中不推荐使用的另一个 Streams 配置值是 exactly_once 作为属性的值 processing.guarantee。该值 exactly_once 对应于 Exactly Once Semantics ( EOS ) 的原始实现,可用于连接到 Kafka 集群版本 0.11.0 或更高版本的任何 Streams 应用程序。此 EOS 的第一实现已经通过流第二实施 EOS 的,这是由值表示取代 exactly_once_beta 在 processing.guarantee 性质。展望未来,该名称 exactly_once_beta 也已弃用并替换为新名称 exactly_once_v2。在下一个主要版本 ( 4.0 ) 中,exactly_once 和 exactly_once_beta 都将被删除,exactly_once_v2 作为 EOS 交付保证的唯一选项。
KIP-725:优化 WindowedSerializer 和 WindowedDeserializer 的配置
配置属性 default.windowed.key.serde.inner 和 default.windowed.value.serde.inner 已弃用,取而代之的是 windowed.inner.class.serde 供消费者客户端使用的单个新属性。建议 Kafka Streams 用户通过将其传递到 SerDe 构造函数来配置他们的窗口化 SerDe,然后在拓扑中使用它的任何地方提供 SerDe。
KIP-633:弃用 Streams 中宽限期的 24 小时默认值
在 Kafka Streams 中,允许窗口操作根据称为宽限期的配置属性处理窗口外的记录。以前,这个配置是可选的,很容易错过,导致默认为 24 小时。这是 Suppression 运营商用户经常感到困惑的原因,因为它会缓冲记录直到宽限期结束,因此会增加 24 小时的延迟。在 3.0 中,Windows 类通过工厂方法得到增强,这些工厂方法要求它们使用自定义宽限期或根本没有宽限期来构造。已弃用默认宽限期为 24 小时的旧工厂方法,以及与 grace ( ) 已设置此配置的新工厂方法不兼容的相应 API。
KIP-623:internal-topics 为流应用程序重置工具添加 " " 选项
通过 kafka-streams-application-reset 添加新的命令行参数,应用程序重置工具的 Streams 使用变得更加灵活:--internal-topics. 新参数接受逗号分隔的主题名称列表,这些名称对应于可以使用此应用程序工具安排删除内部主题。将此新参数与现有参数相结合,--dry-run 允许用户在实际执行删除操作之前确认将删除哪些主题并在必要时指定它们的子集。
Kafka Kraft集群安装
1)下载Kafka的版本
./bin/kafka-storage.sh format --config config/kraft/server.properties -- cluster-id $(./bin/kafka-storage.sh random-uuid)Formatting /tmp/kraft-combined-logs复制
4)启动命令
执行命令:./bin/kafka-server-start.sh config/kraft/server.propertie后台启动命令:./kafka-server-start.sh -daemon ../config/server.properties
kafka常用命令:
1、查看当前服务器中的所有 topicbin/kafka-topics.sh --bootstrap-server localhost:9092 --list2、创建 first topicbin/kafka-topics.sh --bootstrap-server localhost:9092 --create --partitions 1 --replication-factor 3 --topic first3、查看 first 主题的详情bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic first4、修改分区数(注意:分区数只能增加,不能减少)bin/kafka-topics.sh --bootstrap-server localhost:9092 --alter --topic first --partitions 35、再次查看 first 主题的详情bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic first6、删除 topicbin/kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic first7、生产者命令bin/kafka-console-producer.sh -- bootstrap-server localhost:9092 --topic first>hello kafka8、消费者命令(1)消费 first 主题中的数据。bin/kafka-console-consumer.sh -- bootstrap-server localhost:9092 --topic first(2)把主题中所有的数据都读取出来(包括历史数据)。bin/kafka-console-consumer.sh -- bootstrap-server localhost:9092 --from-beginning --topic first复制
