




第一段代码主要导入各种pyod的包,初始化图表中文设置和pandas数据标准化展示。
from __future__ import division
from __future__ import print_function
import os
import sys
import time
import warnings
warnings.filterwarnings("ignore")
import numpy as np
from numpy import percentile
import matplotlib.pyplot as plt
import matplotlib.font_manager
import pandas as pd
from sklearn.preprocessing import StandardScaler
# Import all models
from pyod.models.abod import ABOD
# 基于角度的异常值检测器(ABOD)
from pyod.models.cblof import CBLOF
# 基于聚类的局部异常因子
from pyod.models.feature_bagging import FeatureBagging
# 特征装袋检测器
from pyod.models.hbos import HBOS
# 基于直方图的异常值检测(HBOS)
from pyod.models.iforest import IForest
# IsolationForest异常值检测器。在scikit学习库上实现。
from pyod.models.knn import KNN
# k-最近邻检测器
from pyod.models.lof import LOF
# 局部异常值因子(LOF)。在scikit学习库上实现。
from pyod.models.mcd import MCD
# 最小协方差行列式的异常值检测
from pyod.models.ocsvm import OCSVM
# 一类SVM检测器。在scikit学习库上实现。
from pyod.models.pca import PCA
# 主成分分析(PCA)异常检测器
from pyod.models.lscp import LSCP
# 并行异常集合的局部选择性组合(LSCP)。改编自最初的实施方式。
from pyod.models.inne import INNE
# 使用最近邻集合的基于隔离的异常检测。
from pyod.models.gmm import GMM
# 基于高斯混合模型(GMM)的异常点检测。
from pyod.models.kde import KDE
# 用于无监督异常值检测的核密度估计(KDE)
from pyod.models.lmdd import LMDD
# 线性模型偏差基础异常值检测(LMDD)。
from pyod.models.dif import DIF
# 用于异常检测的深度隔离林(DIF)
from pyod.models.copod import COPOD
# pyod.models.deep_svdd module
from pyod.models.ecod import ECOD
# 使用经验累积分布函数(ECOD)的无监督异常值检测
from pyod.models.suod import SUOD
# SUOD:SUOD(可伸缩无监督异常值检测)是一个用于大规模无监督异常点检测器训练和预测的加速框架。
from pyod.models.qmcd import QMCD
# 准蒙特卡罗差异异常值检测(QMCD)
from pyod.models.sampling import Sampling
# 基于采样的异常值检测(SP)
from pyod.models.kpca import KPCA
# 核主成分分析(KPCA)异常检测器
from pyod.models.lunar import LUNAR
# 设置matplotlib正常显示中文和负号
matplotlib.rcParams['font.family'] = 'SimHei' # 设置字体为黑体
matplotlib.rcParams['axes.unicode_minus'] = False # 正确显示负号
# ---------------------------------------对pandas显示进行格式化-----------------------------------------
pd.set_option('display.max_columns', None) # 显示所有列
pd.set_option('display.max_rows', None) # 显示所有行
pd.set_option('display.width', 1000) # 不换行显示
pd.set_option('display.unicode.ambiguous_as_wide', True) # 行列对齐显示,显示不混乱
pd.set_option('display.unicode.east_asian_width', True) # 行列对齐显示,显示不混乱
pd.set_option('display.precision', 4) # 显示精度
pd.get_option("display.precision") # 显示小数位数
# 在本节中,使用Python代码介绍了检测数据集中异常值的不同方法。为了演示不同方法的方法,使用了包含加速度计数据(在自行车活动期间捕获)的数据集。
# 所有CSV文件都包含索引、时间戳以及X、Y和Z轴的加速度。关于每个文件的信息可以在train.csv和test.csv中找到:记录的表面、智能手机的记录频率以及骑自行车的次数。
# 最新信息是相关的,因为所有自行车都有不同的悬架,因此加速度的幅度也不同。尽可能使用一致的记录设置,以确保数据具有可比性。
data_path = r'E:\JetBrains\PythonProject\DeepLearning\Accelerometer_Data.csv'
data = pd.read_csv(data_path, index_col=0)复制
第二段代码主要通过对pyod孤立树模型的使用,检验一下pyod库的用法。
# 初始化Isolation Forest模型
iforest = IForest(contamination=0.005)
scaler = StandardScaler()
df_scaled = pd.DataFrame(scaler.fit_transform(data), columns=data.columns)
# 训练模型
iforest.fit(df_scaled)
# 模型预测,并将异常值输出到新增的cluster列
data['cluster'] = iforest.predict(df_scaled)
# print(data.groupby('cluster').describe())
# time x y z
# count mean std min 25% 50% 75% max count mean std min 25% 50% 75% max count mean std min 25% 50% 75% max count mean std min 25% 50% 75% max
# cluster
# 0 6467.032.467718.75440.000516.245532.420548.715564.99056467.00.02031.7185 -6.8461 -1.0955 -0.03031.046720.42616467.00.37592.5788 -7.7641 -1.35750.36802.070317.67666467.0 -0.78202.7387 -15.7191 -2.6817 -0.9291 1.033510.4756
# 1 33.037.931720.37690.020528.640539.860558.800563.7605 33.06.79654.4283 -4.32644.32837.35478.729922.1790 33.04.57155.8012 -5.68600.22592.97538.971316.9318 33.09.48613.8874 4.38616.54119.260410.617520.2469
# time x y z cluster
# 00.00052.12924.14001.5651 0
# 10.01054.23032.17904.6071 0
# 20.02055.87400.22595.5304 1
# 30.03056.6837 -2.04433.2507 0
# 40.04056.6045 -4.15710.9183 0复制
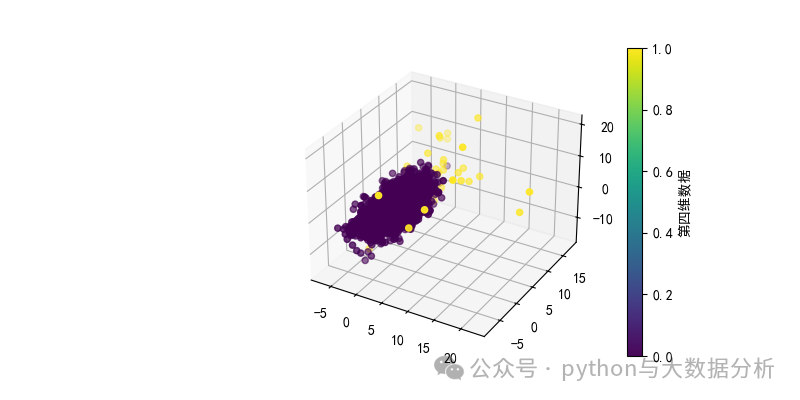
第三段代码是异常值可视化展示代码。
fig = plt.figure(figsize=(8, 4))
ax = fig.add_subplot(111, projection='3d')
sc = ax.scatter(data['x'], data['y'], data['z'], c=data['cluster'], cmap='viridis')
cbar = fig.colorbar(sc)
cbar.set_label('第四维数据')
plt.show()复制
可视化展示效果如下:
第四段代码是pyod的25种异常值检测的参数初始化
# 初始化Isolation Forest模型
# initialize a set of detectors for LSCP
detector_list = [LOF(n_neighbors=5), LOF(n_neighbors=10), LOF(n_neighbors=15),
LOF(n_neighbors=20), LOF(n_neighbors=25), LOF(n_neighbors=30),
LOF(n_neighbors=35), LOF(n_neighbors=40), LOF(n_neighbors=45),
LOF(n_neighbors=50)]
outliers_fraction = 0.01
clusters_separation = [0]
random_state = 42
# Define nine outlier detection tools to be compared
classifiers = {
'Angle-based Outlier Detector (ABOD)':ABOD(contamination=outliers_fraction),
'K Nearest Neighbors (KNN)': KNN(contamination=outliers_fraction),
'Average KNN': KNN(method='mean', contamination=outliers_fraction),
'Median KNN': KNN(method='median', contamination=outliers_fraction),
'Local Outlier Factor (LOF)':LOF(n_neighbors=35, contamination=outliers_fraction),
'Isolation Forest': IForest(contamination=outliers_fraction,random_state=random_state),
'Deep Isolation Forest (DIF)': DIF(contamination=outliers_fraction,random_state=random_state),
'INNE': INNE(max_samples=2, contamination=outliers_fraction,random_state=random_state,),
'Locally Selective Combination (LSCP)': LSCP(detector_list, contamination=outliers_fraction,random_state=random_state),
'Feature Bagging':FeatureBagging(LOF(n_neighbors=35),contamination=outliers_fraction,random_state=random_state),
'SUOD': SUOD(contamination=outliers_fraction),
'Minimum Covariance Determinant (MCD)': MCD(contamination=outliers_fraction, random_state=random_state),
'Principal Component Analysis (PCA)': PCA(contamination=outliers_fraction, random_state=random_state),
'KPCA': KPCA(contamination=outliers_fraction),
'Probabilistic Mixture Modeling (GMM)': GMM(contamination=outliers_fraction,random_state=random_state),
# 'LMDD': LMDD(contamination=outliers_fraction,random_state=random_state),
'Histogram-based Outlier Detection (HBOS)': HBOS(contamination=outliers_fraction),
'Copula-base Outlier Detection (COPOD)': COPOD(contamination=outliers_fraction),
'ECDF-baseD Outlier Detection (ECOD)': ECOD(contamination=outliers_fraction),
'Kernel Density Functions (KDE)': KDE(contamination=outliers_fraction),
'QMCD': QMCD(contamination=outliers_fraction),
'Sampling': Sampling(contamination=outliers_fraction),
'LUNAR': LUNAR(),
'Cluster-based Local Outlier Factor (CBLOF)':CBLOF(contamination=outliers_fraction,check_estimator=False, random_state=random_state),
'One-class SVM (OCSVM)': OCSVM(contamination=outliers_fraction),
}
fieldnames = {
'Angle-based Outlier Detector (ABOD)':'ABOD',
'K Nearest Neighbors (KNN)': 'KNN',
'Average KNN': 'AvgKNN',
'Median KNN': 'MedianKNN',
'Local Outlier Factor (LOF)':'LOF',
'Isolation Forest': 'IForest',
'Deep Isolation Forest (DIF)': 'DIF',
'INNE': 'INNE',
'Locally Selective Combination (LSCP)': 'LSCP',
'Feature Bagging':'FeatureBagging',
'SUOD': 'SUOD',
'Minimum Covariance Determinant (MCD)': 'MCD',
'Principal Component Analysis (PCA)': 'PCA',
'KPCA': 'KPCA',
'Probabilistic Mixture Modeling (GMM)': 'GMM',
'LMDD': 'LMDD',
'Histogram-based Outlier Detection (HBOS)': 'HBOS',
'Copula-base Outlier Detection (COPOD)': 'COPOD',
'ECDF-baseD Outlier Detection (ECOD)': 'ECOD',
'Kernel Density Functions (KDE)': 'KDE',
'QMCD': 'QMCD',
'Sampling': 'Sampling',
'LUNAR': 'LUNAR',
'Cluster-based Local Outlier Factor (CBLOF)':'CBLOF',
'One-class SVM (OCSVM)': 'OCSVM',
}
# Fit the models with the generated data and
# compare model performances
np.random.seed(42)
X = data[['x','y','z']]
classifierscost={}复制
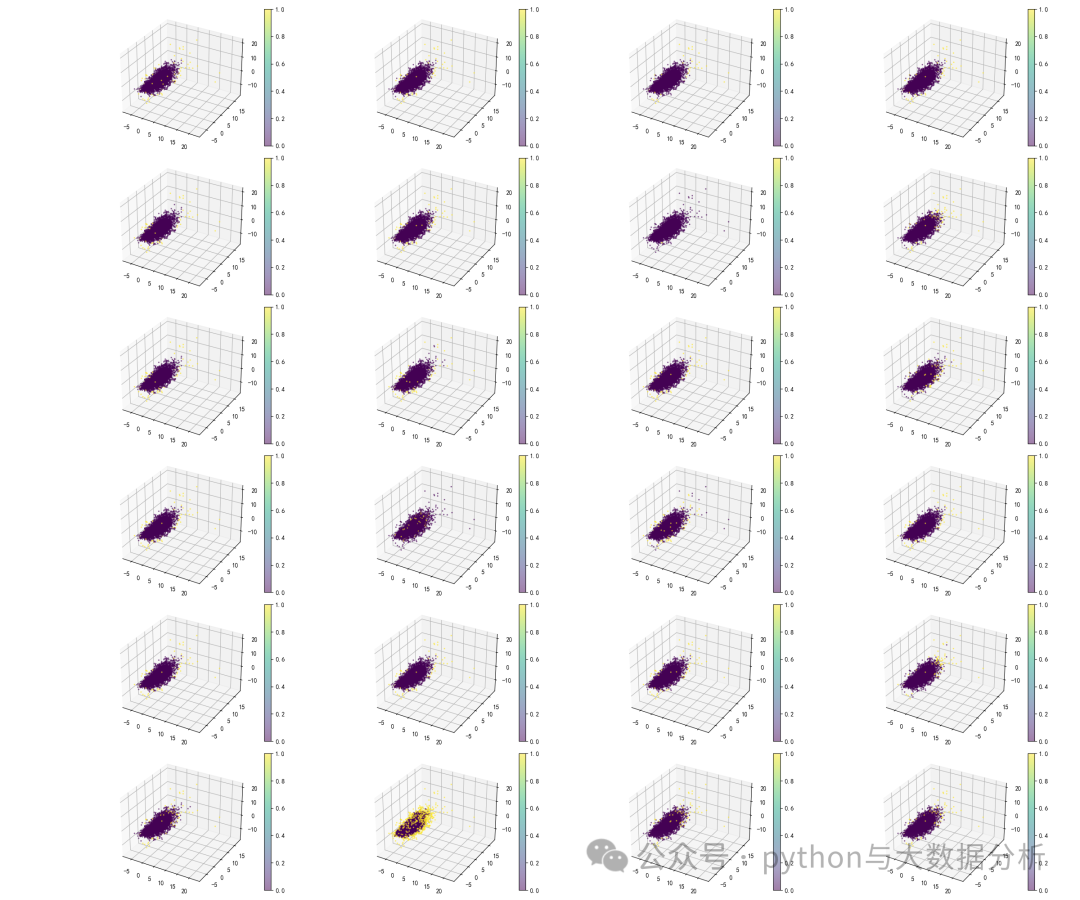
第五段代码,一遍迭代pyod异常值算法包,一遍进行异常值预测,同时计算各种算法的消耗时间。
plt.figure(figsize=(24, 20))
for i, (clf_name, clf) in enumerate(classifiers.items()):
start_time = time.time()
clf.fit(X)
X[fieldnames[clf_name]]=clf.predict(X)
end_time=time.time()
classifierscost[clf_name]=end_time-start_time
subplot = plt.subplot(6,4,i+1,projection='3d')
sc = subplot.scatter(X['x'], X['y'], X['z'], c=X[fieldnames[clf_name]], cmap='viridis',s=2,alpha=0.5)
cbar = fig.colorbar(sc)
plt.tight_layout()
plt.show()
X.to_csv('dataoutliers.csv', index=False, header=True, encoding='utf-8')复制
可视化展示效果如下:
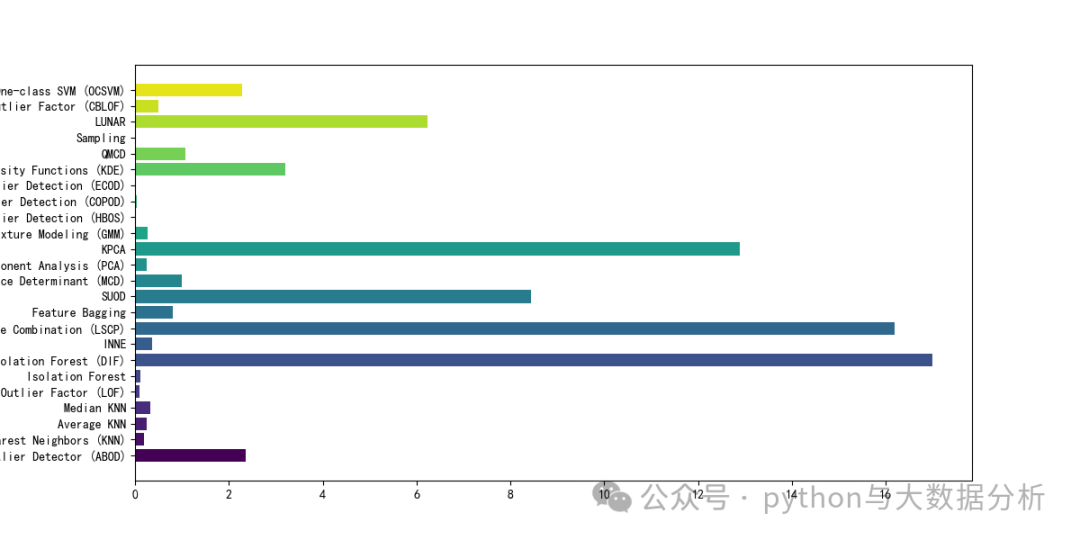
第六段代码,主要是对pyod各种算法的消耗时间进行可视化展示。
plt.figure(figsize=(12, 6))
cmap = plt.cm.viridis # 使用viridis色图
colors = [cmap(i len(classifierscost)) for i in range(len(classifierscost))] # 为每个条形生成颜色
plt.barh(classifierscost.keys() , classifierscost.values() , color=colors)
plt.show()复制
可视化展示效果如下:

文章转载自追梦IT人,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。



